
- Un rápido recorrido por los mejores papers de clasificación de imágenes en una década para que inicies tu aprendizaje de visión por computador
- 1998: LeNet
- 2012: AlexNet
- 2014: VGG
- 2014: GoogLeNet
- 2015: Batch Normalization
- 2015: ResNet
- 2016: Xception
- 2017: MobileNet
- 2017: NASNet
- 2019: EfficientNet
- 2014: SPPNet
- 2016: DenseNet
- 2017: SENet
- 2017: ShuffleNet
- 2018: Bag of Tricks
- Conclusión
Un rápido recorrido por los mejores papers de clasificación de imágenes en una década para que inicies tu aprendizaje de visión por computador

La visión por computador es un tema para convertir imágenes y vídeos en señales comprensibles por la máquina.comprensibles para la máquina. Con estas señales, los programadores pueden controlar el comportamiento de la máquina basándose en esta comprensión de alto nivel. Entre las muchas tareas de visión por ordenador, la clasificación de imágenes es una de las más fundamentales. No sólo puede utilizarse en muchos productos reales, como el etiquetado de Google Photo y la moderación de contenidos con IA, sino que también abre una puerta a muchas tareas de visión más avanzadas, como la detección de objetos y la comprensión de vídeos. Debido a los rápidos cambios en este campo desde la irrupción del aprendizaje profundo, los principiantes suelen encontrarlo demasiado abrumador para aprender. A diferencia de los temas típicos de la ingeniería de software, no hay muchos grandes libros sobre la clasificación de imágenes utilizando DCNN, y la mejor manera de entender este campo es a través de la lectura de artículos académicos. ¿Pero qué artículos leer? ¿Por dónde empiezo? En este artículo, voy a presentar los 10 mejores artículos para principiantes. Con estos artículos, podemos ver cómo evoluciona este campo y cómo los investigadores aportan nuevas ideas basadas en los resultados de investigaciones anteriores. Sin embargo, sigue siendo útil para usted para ordenar el panorama general, incluso si usted ya ha trabajado en esta área por un tiempo. Así pues, empecemos.
1998: LeNet
Aprendizaje basado en gradientes aplicado al reconocimiento de documentos

Introducido en 1998, LeNet establece una base para la futura investigación de clasificación de imágenes utilizando la red neuronal de convolución. Muchas técnicas clásicas de las CNN, como las capas de agrupación, las capas totalmente conectadas, el relleno y las capas de activación, se utilizan para extraer características y realizar una clasificación. Con una función de pérdida de error cuadrático medio y 20 épocas de entrenamiento, esta red puede alcanzar una precisión del 99,05% en el conjunto de pruebas MNIST. Incluso después de 20 años, muchas redes de clasificación del estado de la técnica siguen este patrón en general.
2012: AlexNet
Clasificación de imágenes con redes neuronales convolucionales profundas

.
Aunque LeNet logró un gran resultado y mostró el potencial de las CNN, el desarrollo en esta área se estancó durante una década debido a la limitada potencia de cálculo y a la cantidad de datos. Parecía que la CNN sólo podía resolver algunas tareas fáciles, como el reconocimiento de dígitos, pero para características más complejas, como rostros y objetos, un extractor de características HarrCascade o SIFT con un clasificador SVM era un enfoque más preferido.
Sin embargo, en el Desafío de Reconocimiento Visual a Gran Escala de ImageNet de 2012, Alex Krizhevsky propuso una solución basada en CNN para este desafío y aumentó drásticamente la precisión del conjunto de pruebas de ImageNet del 73,8% al 84,7%. Su enfoque hereda la idea de CNN multicapa de LeNet, pero aumentó mucho el tamaño de la CNN. Como se puede ver en el diagrama de arriba, la entrada es ahora de 224×224 en comparación con los 32×32 de LeNet, también muchos núcleos de convolución tienen 192 canales en comparación con los 6 de LeNet. Aunque el diseño no ha cambiado mucho, con cientos de veces más de parámetros, la capacidad de la red para capturar y representar características complejas mejoró cientos de veces también. Para entrenar un modelo tan grande, Alex utilizó dos GPU GTX 580 con 3 GB de RAM para cada una, lo que supuso una tendencia pionera en el entrenamiento con GPU. Además, el uso de la no linealidad de ReLU también ayudó a reducir el coste de cálculo.
Además de aportar muchos más parámetros para la red, también exploró el problema de sobreajuste que conlleva una red más grande utilizando una capa Dropout. Su método de normalización de la respuesta local no obtuvo demasiada popularidad después, pero inspiró otras técnicas de normalización importantes, como BatchNorm, para combatir el problema de la saturación del gradiente. En resumen, AlexNet definió el marco de la red de clasificación de facto para los próximos 10 años: una combinación de convolución, activación no lineal ReLu, MaxPooling y capa densa.
2014: VGG
Redes convolucionales muy profundas para el reconocimiento de imágenes a granScale Image Recognition
Con el éxito tan grande de usar CNN para el reconocimiento visual, toda la comunidad de investigación estalló y todos empezaron a investigar por qué esta red neuronal funciona tan bien. Por ejemplo, en «Visualizing and Understanding Convolutional Networks» de 2013, Matthew Zeiler hablaba de cómo la CNN recogía características y visualizaba las representaciones intermedias. Y de repente todo el mundo empezó a darse cuenta de que la CNN es el futuro de la visión por ordenador desde 2014. Entre todos esos seguidores inmediatos, la red VGG de Visual Geometry Group es la que más llama la atención. Obtuvo un resultado notable de 93,2% de precisión en el top-5, y 76,3% de precisión en el top-1 en el conjunto de pruebas de ImageNet.
Siguiendo el diseño de AlexNet, la red VGG tiene dos actualizaciones importantes: 1) VGG no sólo utiliza una red más amplia como AlexNet, sino también más profunda. VGG-19 tiene 19 capas de convolución, frente a las 5 de AlexNet. 2) VGG también ha demostrado que unos pocos filtros de convolución pequeños de 3×3 pueden sustituir a un único filtro de 7×7 o incluso de 11×11 de AlexNet, consiguiendo un mejor rendimiento y reduciendo el coste de computación. Debido a este elegante diseño, VGG también se convirtió en la red base de muchas redes pioneras en otras tareas de visión por ordenador, como FCN para la segmentación semántica, y Faster R-CNN para la detección de objetos.
Con una red más profunda, la desaparición del gradiente de la retropropagación multicapa se convierte en un problema mayor. Para solucionarlo, el VGG también discutió la importancia del preentrenamiento y la inicialización de pesos. Este problema limita a los investigadores a seguir añadiendo más capas, de lo contrario, la red será realmente difícil de converger. Pero veremos una mejor solución para esto después de dos años.
2014: GoogLeNet
Cómo profundizar con las convoluciones

VGG tiene una estructura atractiva y fácil de entender, pero su rendimiento no es el mejor entre todos los finalistas de las competiciones de ImageNet 2014. GoogLeNet, también conocido como InceptionV1, ganó el premio final. Al igual que VGG, una de las principales aportaciones de GoogLeNet es llevar al límite la profundidad de la red con una estructura de 22 capas. Esto demostró una vez más que ir más profundo y más amplio es, de hecho, la dirección correcta para mejorar la precisión.
A diferencia de VGG, GoogLeNet trató de abordar los problemas de cálculo y disminución de gradiente de frente, en lugar de proponer una solución con un mejor esquema pre-entrenado y la inicialización de los pesos.

En primer lugar, exploró la idea del diseño de redes asimétricas mediante un módulo llamado Inception (ver diagrama anterior). Lo ideal sería perseguir la convolución dispersa o las capas densas para mejorar la eficiencia de las funciones, pero el diseño de hardware moderno no estaba adaptado a este caso. Así que creyeron que una sparsity a nivel de topología de red también podría ayudar a la fusión de características aprovechando las capacidades de hardware existentes.
En segundo lugar, ataca el problema del alto coste computacional tomando prestada una idea de un artículo llamado «Red en Red». Básicamente, se introduce un filtro de convolución 1×1 para reducir las dimensiones de las características antes de pasar por una operación de computación pesada como un núcleo de convolución 5×5. Esta estructura se denomina posteriormente «Cuello de botella» y se utiliza ampliamente en muchas redes siguientes. Al igual que la «Red en la Red», también utilizó una capa de agrupación media para reemplazar la capa final totalmente conectada para reducir aún más el coste.
Tercero, para ayudar a los gradientes a fluir a las capas más profundas, GoogLeNet también utilizó la supervisión en algunas salidas de las capas intermedias o la salida auxiliar. Este diseño no es muy popular más tarde en la red de clasificación de imágenes debido a la complejidad, pero cada vez más popular en otras áreas de la visión por ordenador, como la red de reloj de arena en la estimación de la pose.
Como seguimiento, este equipo de Google escribió más documentos para esta serie Inception. «Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift» es de InceptionV2. «Rethinking the Inception Architecture for Computer Vision», de 2015, corresponde a InceptionV3. Y «Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning» en 2015 significa InceptionV4. Cada artículo añadió más mejoras sobre la red Inception original y logró un mejor resultado.
2015: Batch Normalization
Batch Normalization: Aceleración del entrenamiento de redes profundas mediante la reducción del desplazamiento interno de las covariables
La red Inception ayudó a los investigadores a alcanzar una precisión sobrehumana en el conjunto de datos ImageNet. Sin embargo, como método de aprendizaje estadístico, la CNN está muy limitada a la naturaleza estadística de un conjunto de datos de entrenamiento específico. Por lo tanto, para conseguir una mayor precisión, normalmente tenemos que calcular previamente la media y la desviación estándar de todo el conjunto de datos y utilizarlas para normalizar nuestra entrada primero y asegurarnos de que la mayoría de las entradas de las capas de la red están cerca, lo que se traduce en una mejor respuesta de la activación. Este enfoque aproximado es muy engorroso, y a veces no funciona en absoluto para una nueva estructura de red o un nuevo conjunto de datos, por lo que el modelo de aprendizaje profundo sigue considerándose difícil de entrenar. Para solucionar este problema, Sergey Ioffe y Chritian Szegedy, el tipo que creó GoogLeNet, decidieron inventar algo más inteligente llamado Batch Normalization.

La idea de la normalización por lotes no es difícil: podemos utilizar las estadísticas de una serie de minilotes para aproximar las estadísticas de todo el conjunto de datos, siempre que entrenemos durante el tiempo suficiente. Además, en lugar de calcular manualmente las estadísticas, podemos introducir dos parámetros más aprendibles «scale» y «shift» para que la red aprenda a normalizar cada capa por sí misma.
El diagrama anterior muestra el proceso de cálculo de los valores de normalización por lotes. Como podemos ver, tomamos la media de todo el mini lote y calculamos también la varianza. A continuación, podemos normalizar la entrada con esta media y varianza del minilote. Finalmente, con un parámetro de escala y un parámetro de desplazamiento, la red aprenderá a adaptar el resultado normalizado del lote para que se ajuste mejor a las siguientes capas, normalmente ReLU. Una advertencia es que no tenemos información de minilotes durante la inferencia, por lo que una solución es calcular una media y una varianza móviles durante el entrenamiento, y luego utilizar estas medias móviles en la ruta de inferencia. Esta pequeña innovación es muy impactante, y todas las redes posteriores comienzan a utilizarla de inmediato.
2015: ResNet
Aprendizaje Residual Profundo para el Reconocimiento de Imágenes
2015 puede ser el mejor año para la visión por computador en una década, hemos visto tantas grandes ideas surgiendo no sólo en la clasificación de imágenes sino en todo tipo de tareas de visión por computador como la detección de objetos, la segmentación semántica, etc. El mayor avance del año 2015 pertenece a una nueva red llamada ResNet, o redes residuales, propuesta por un grupo de investigadores chinos de Microsoft Research Asia.

Como ya comentamos anteriormente para la red VGG, el mayor obstáculo para profundizar aún más es el problema de la desaparición del gradiente, es decir.Es decir, las derivadas se vuelven cada vez más pequeñas cuando se propagan hacia atrás a través de capas más profundas, y finalmente llega a un punto que la arquitectura de los ordenadores modernos no puede representar de manera significativa. GoogLeNet trató de atacar esto utilizando la supervisión auxiliar y el módulo de inicio asimétrico, pero sólo alivia el problema en una pequeña medida. Si queremos utilizar 50 o incluso 100 capas, ¿habrá una forma mejor de que el gradiente fluya por la red? La respuesta de ResNet es utilizar un módulo residual.

Módulo residual de «Deep Residual Learning for Image Recognition»
ResNet añadió un atajo de identidad a la salida, para que cada módulo residual no pueda predecir al menos lo que es la entrada, sin perderse en la naturaleza. Lo más importante es que, en lugar de esperar que cada capa se ajuste directamente al mapeo de características deseado, el módulo residual intenta aprender la diferencia entre la salida y la entrada, lo que facilita mucho la tarea porque la ganancia de información necesaria es menor. Imagina que estás aprendiendo matemáticas, para cada nuevo problema, se te da una solución de un problema similar, así que todo lo que necesitas hacer es extender esta solución y tratar de hacerla funcionar. Esto es mucho más fácil que pensar en una solución nueva para cada problema que te encuentres. O como dijo Newton, podemos subirnos a hombros de gigantes, y la entrada de identidad es ese gigante para el módulo residual.
Además del mapeo de identidad, ResNet también tomó prestados el cuello de botella y la normalización por lotes de las redes Inception. Finalmente, consiguió construir una red con 152 capas de convolución y logró un 80,72% de precisión en el top-1 de ImageNet. El enfoque residual también se convierte en una opción por defecto para muchas otras redes posteriormente, como Xception, Darknet, etc. Además, gracias a su diseño simple y hermoso, sigue siendo ampliamente utilizado en muchos sistemas de reconocimiento visual de producción hoy en día.
Hay muchos más invariantes que surgieron siguiendo el bombo de la red residual. En «Identity Mappings in Deep Residual Networks», el autor original de ResNet trató de poner la activación antes del módulo residual y logró un mejor resultado, y este diseño se llama ResNetV2 después. Asimismo, en un artículo de 2016 «Aggregated Residual Transformations for Deep Neural Networks», los investigadores propusieron ResNeXt, que añadía ramas paralelas para que los módulos residuales agregaran las salidas de diferentes transformaciones.
2016: Xception
Xception: Deep Learning with Depthwise Separable Convolutions

Con el lanzamiento de ResNet, parecía que la mayoría de las frutas que cuelgan en el clasificador de imágenes ya estaban cogidas. Los investigadores empezaron a pensar en cuál es el mecanismo interno de la magia de la CNN. Dado que la convolución de canales cruzados suele introducir una tonelada de parámetros, la red Xception optó por investigar esta operación para comprender una imagen completa de su efecto.
Como su nombre, Xception se origina en la red Inception. En el módulo Inception, se agregan múltiples ramas de diferentes transformaciones para conseguir una topología sparsity. Pero, ¿por qué ha funcionado esta dispersión? El autor de Xception, también autor del marco Keras, extendió esta idea a un caso extremo en el que un archivo de convolución 3×3 corresponde a un canal de salida antes de una concatenación final. En este caso, estos núcleos de convolución paralelos forman en realidad una nueva operación llamada convolución en profundidad.

Como se muestra en el diagrama anterior, a diferencia de la convolución tradicional, en la que todos los canales se incluyen en un solo cálculo, la convolución en profundidad sólo calcula la convolución de cada canal por separado y luego concatena la salida. Esto reduce el intercambio de características entre los canales, pero también reduce una gran cantidad de conexiones, por lo que resulta en una capa con menos parámetros. Sin embargo, esta operación dará como salida el mismo número de canales que la entrada (o un número menor de canales si se agrupan dos o más canales). Por lo tanto, una vez que las salidas de los canales se fusionan, necesitamos otro filtro regular de 1×1, o la convolución puntual, para aumentar o reducir el número de canales, al igual que lo hace la convolución regular.
Esta idea no es de Xception originalmente. Se describe en un artículo llamado «Learning visual representations at scale» y también se utiliza ocasionalmente en InceptionV2. Xception dio un paso más y sustituyó casi todas las circunvoluciones por este nuevo tipo. Y el resultado del experimento resultó ser bastante bueno. Superó a ResNet e InceptionV3 y se convirtió en un nuevo método SOTA para la clasificación de imágenes. Esto también demostró que el mapeo de las correlaciones entre canales y las correlaciones espaciales en la CNN se puede desacoplar por completo. Además, al compartir la misma virtud con ResNet, Xception también tiene un diseño sencillo y bonito, por lo que su idea se utiliza en muchas otras investigaciones siguientes, como MobileNet, DeepLabV3, etc.
2017: MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
Xception logró un 79% de precisión en el top-1 y un 94,5% de precisión en el top-5 en ImageNet, pero eso es solo un 0,8% y un 0,4% de mejora respectivamente en comparación con el anterior SOTA InceptionV3. La ganancia marginal de una nueva red de clasificación de imágenes es cada vez menor, por lo que los investigadores empiezan a centrarse en otras áreas. Y MobileNet lideró un importante impulso de la clasificación de imágenes en un entorno de recursos limitados.

Similar a Xception, MobileNet utilizó un mismo módulo de convolución separable en profundidad como el mostrado anteriormente y tuvo un énfasis en la alta eficiencia y menos parámetros.
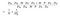
Relación de parámetros de «MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application»
El numerador en la fórmula anterior es el número total de parámetros requeridos por una convolución separable en profundidad. Y el denominador es el número total de parámetros de una convolución regular similar. Aquí D es el tamaño del núcleo de convolución, D es el tamaño del mapa de características, M es el número de canales de entrada, N es el número de canales de salida. Dado que separamos el cálculo del canal y de la característica espacial, podemos convertir la multiplicación en una suma, que es una magnitud menor. Incluso mejor, como podemos ver en esta relación, cuanto mayor es el número de canales de salida, más cálculo nos ahorramos al utilizar esta nueva convolución.
Otra contribución de MobileNet es el multiplicador de anchura y resolución. El equipo de MobileNet quería encontrar una forma canónica de reducir el tamaño del modelo para los dispositivos móviles, y la forma más intuitiva es reducir el número de canales de entrada y salida, así como la resolución de la imagen de entrada. Para controlar este comportamiento, se multiplica un ratio alpha con los canales, y un ratio rho con la resolución de entrada (que también afecta al tamaño del mapa de características). Así, el número total de parámetros puede representarse con la siguiente fórmula:

Aunque este cambio parece ingenuo en términos de innovación, tiene un gran valor de ingeniería porque es la primera vez que los investigadores concluyen un enfoque canónico para ajustar la red para diferentes limitaciones de recursos. Además, en cierto modo resumió la solución definitiva de la mejora de la red neuronal: una entrada más amplia y de alta resolución conduce a una mayor precisión, una entrada más fina y de baja resolución conduce a una menor precisión.
Más tarde, en 2018 y 2019, el equipo de MobiletNet también publicó «MobileNetV2: Residuos invertidos y cuellos de botella lineales» y «Búsqueda de MobileNetV3». En MobileNetV2, se utiliza una estructura de cuello de botella residual invertida. Y en MobileNetV3, se empezó a buscar la combinación óptima de arquitecturas utilizando la tecnología de búsqueda de arquitecturas neuronales, que trataremos a continuación.
2017: NASNet
Aprendizaje de arquitecturas transferibles para el reconocimiento escalable de imágenes
Al igual que la clasificación de imágenes para un entorno con recursos limitados, la búsqueda de arquitecturas neuronales es otro campo que surgió en torno a 2017. Con ResNet, Inception y Xception, parece que hemos alcanzado una topología de red óptima que los humanos pueden entender y diseñar, pero ¿y si hay una combinación mejor y mucho más compleja que supera con creces la imaginación humana? Un artículo de 2016 llamado «Neural Architecture Search with Reinforcement Learning» propuso una idea para buscar la combinación óptima dentro de un espacio de búsqueda predefinido utilizando el aprendizaje por refuerzo. Como sabemos, el aprendizaje por refuerzo es un método para encontrar la mejor solución con un objetivo claro y una recompensa para el agente de búsqueda. Sin embargo, limitados por la potencia de cálculo, este trabajo sólo discutió la aplicación en un pequeño conjunto de datos CIFAR.

Con el objetivo de encontrar una estructura óptima para un gran conjunto de datos como ImageNet, NASNet hizo un espacio de búsqueda que se adapta a ImageNet. Espera diseñar un espacio de búsqueda especial para que el resultado de la búsqueda en CIFAR también pueda funcionar bien en ImageNet. En primer lugar, NASNet parte de la base de que los módulos comunes creados a mano en redes buenas como ResNet y Xception siguen siendo útiles a la hora de buscar. Así, en lugar de buscar conexiones y operaciones al azar, NASNet busca la combinación de estos módulos que ya han demostrado su utilidad en ImageNet. En segundo lugar, la búsqueda real se sigue realizando en el conjunto de datos CIFAR con una resolución de 32×32, por lo que NASNet sólo busca módulos que no se vean afectados por el tamaño de la entrada. Para que el segundo punto funcione, NASNet predefinió dos tipos de plantillas de módulos: Reducción y Normal. La celda de Reducción podría tener un mapa de características reducido en comparación con la entrada, y para la celda Normal sería lo mismo.

Aunque NASNet tiene mejores métricas que las redes diseñadas manualmente, también sufre algunos inconvenientes. El coste de la búsqueda de una estructura óptima es muy elevado, lo que sólo está al alcance de grandes empresas como Google y Facebook. Además, la estructura final no tiene demasiado sentido para los humanos, por lo que es más difícil de mantener y mejorar en un entorno de producción. Más adelante, en 2018, «MnasNet: Platform-Aware Neural Architecture Search for Mobile» amplía aún más esta idea de NASNet al limitar el paso de búsqueda con una estructura predefinida de bloques encadenados. Además, mediante la definición de un factor de peso, mNASNet proporcionó una forma más sistemática de buscar el modelo dadas las restricciones de recursos específicos, en lugar de sólo evaluar en base a FLOPs.
2019: EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
En 2019, parece que ya no hay ideas emocionantes para la clasificación supervisada de imágenes con CNN. Un cambio drástico en la estructura de la red normalmente solo ofrece una pequeña mejora de la precisión. Y lo que es peor, cuando la misma red se aplica a diferentes conjuntos de datos y tareas, los trucos reivindicados anteriormente no parecen funcionar, lo que ha llevado a criticar si esas mejoras son solo un exceso de ajuste en el conjunto de datos ImageNet. Por otro lado, hay un truco que nunca falla a nuestras expectativas: utilizar una entrada de mayor resolución, añadir más canales para las capas de convolución y añadir más capas. Aunque es una fuerza muy brutal, parece que hay una forma de principio para escalar la red bajo demanda. MobileNetV1 más o menos sugirió esto en 2017, pero el enfoque se cambió a un mejor diseño de red más tarde.

Después de NASNet y mNASNet, los investigadores se dieron cuenta de que, incluso con la ayuda de un ordenador, un cambio de arquitectura no produce tantos beneficios. Así que empezaron a recurrir al escalado de la red. EfficientNet se basa en este supuesto. Por un lado, utiliza el bloque de construcción óptimo de mNASNet para asegurarse una buena base con la que empezar. Por otro lado, define tres parámetros alfa, beta y rho para controlar la profundidad, la anchura y la resolución de la red de forma correspondiente. De este modo, incluso sin una gran reserva de GPU para buscar una estructura óptima, los ingenieros pueden confiar en estos parámetros de principio para ajustar la red en función de sus diferentes requisitos. Al final, EfficientNet ofreció 8 variantes diferentes con distintos ratios de anchura, profundidad y resolución y obtuvo un buen rendimiento tanto para modelos pequeños como grandes. En otras palabras, si quieres una gran precisión, opta por una EfficientNet-B7 de 600×600 y 66M parámetros. Si quieres baja latencia y un modelo más pequeño, ve a por un EfficientNet-B0 de 224×224 y 5,3M parámetros. Problema resuelto.
Si terminas de leer los 10 artículos anteriores, deberías tener un buen conocimiento de la historia de la clasificación de imágenes con CNN. Si quieres seguir aprendiendo en esta área, también he hecho una lista de otros artículos interesantes para leer. Aunque no están incluidos en la lista de los 10 mejores, estos documentos son todos famosos en su propia área e inspiraron a muchos otros investigadores en el mundo.
2014: SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPPNet toma prestada la idea de pirámide de características de la extracción tradicional de características de visión por ordenador. Esta pirámide forma una bolsa de palabras de características con diferentes escalas, por lo que se puede adaptar a diferentes tamaños de entrada y deshacerse de la capa totalmente conectada de tamaño fijo. Esta idea también inspiró el módulo ASPP de DeepLab, y también FPN para la detección de objetos.
2016: DenseNet
Redes convolucionales densamente conectadas
DenseNet de Cornell amplía la idea de ResNet. No sólo proporciona conexión de salto entre capas, sino que también tiene conexiones de salto de todas las capas anteriores.
2017: SENet
Redes de apriete y excitación
La red Xception demostró que la correlación entre canales no tiene mucho que ver con la correlación espacial. Sin embargo, como campeón del último concurso de ImageNet, SENet ideó un bloque Squeeze-and-Excitation y contó una historia diferente. El bloque SE primero exprime todos los canales en menos canales utilizando la agrupación global, aplica una transformación totalmente conectada y luego los «excita» de nuevo al número original de canales utilizando otra capa totalmente conectada. Así que, esencialmente, la capa de FC ayudó a la red a aprender atenciones en el mapa de características de entrada.
2017: ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Construida sobre el módulo de cuello de botella invertido de MobileNetV2, ShuffleNet considera que la convolución puntual en la convolución separable en profundidad sacrifica la precisión a cambio de menos computación. Para compensar esto, ShuffleNet ha añadido una operación adicional de barajado de canales para asegurarse de que la convolución puntual no se aplique siempre al mismo «punto». Y en ShuffleNetV2, este mecanismo de barajado de canales se extiende además a una rama de mapeo de identidad de ResNet, de modo que parte de la característica de identidad también se utilizará para barajar.
2018: Bag of Tricks
Bag of Tricks for Image Classification with Convolutional Neural Networks
Bag of Tricks se centra en trucos comunes utilizados en el área de clasificación de imágenes. Sirve como una buena referencia para los ingenieros cuando necesitan mejorar el rendimiento de la clasificación. Curiosamente, estos trucos, como el aumento de la mezcla y la tasa de aprendizaje del coseno, a veces pueden lograr una mejora mucho mejor que una nueva arquitectura de red.
Conclusión
Con el lanzamiento de EfficientNet, parece que el benchmark de clasificación ImageNet llega a su fin. Con el enfoque de aprendizaje profundo existente, nunca habrá un día en que podamos alcanzar el 99,999% de precisión en la ImageNet, a menos que se produzca otro cambio de paradigma. Por ello, los investigadores están buscando activamente algunas áreas novedosas como el aprendizaje autosupervisado o semisupervisado para el reconocimiento visual a gran escala. Mientras tanto, con los métodos existentes, es más una cuestión de ingenieros y empresarios encontrar la aplicación en el mundo real de esta tecnología no perfecta. En el futuro, también escribiré un estudio para analizar esas aplicaciones de visión por ordenador en el mundo real impulsadas por la clasificación de imágenes, así que ¡estén atentos! Si crees que también hay otros documentos importantes para leer para la clasificación de imágenes, por favor deja un comentario abajo y haznos saber.
Publicado originalmente en http://yanjia.li el 31 de julio de 2020
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Aprendizaje basado en gradientes aplicado al reconocimiento de documentos
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
- Sergey Ioffe, Christian Szegedy, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition
- François Chollet, Xception: Deep Learning with Depthwise Separable Convolutions
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
- Mingxing Tan, Quoc V. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Connected Convolutional Networks
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Bag of Tricks for Image Classification with Convolutional Neural Networks