
La Asignación de Recursos es un aspecto importante durante la ejecución de cualquier trabajo Spark. Si no se configura correctamente, un trabajo de spark puede consumir recursos enteros del clúster y hacer que otras aplicaciones se queden sin recursos.
Este blog ayuda a entender el flujo básico en una aplicación de Spark y luego cómo configurar el número de ejecutores, la configuración de la memoria de cada uno de ellos y el número de núcleos para un trabajo de Spark. Hay algunos factores que debemos considerar para decidir los números óptimos para los tres anteriores, como:
- La cantidad de datos
- El tiempo en el que un trabajo debe completarse
- Asignación estática o dinámica de recursos
- Aplicación ascendente o descendente
- Introducción
- Pasos implicados en el modo cluster para un Spark Job
- Asignación estática
- Caso 1 Hardware – 6 Nodos y cada nodo tiene 16 núcleos, 64 GB de RAM
- Hardware del caso 2 – 6 Nodos y Cada nodo tiene 32 Núcleos, 64 GB
- Caso 3 – Cuando no se requiere más memoria para los ejecutores
- Tabla resumen
- Asignación dinámica
Introducción
Comencemos con algunas definiciones básicas de los términos utilizados en el manejo de aplicaciones Spark.
Particiones : Una partición es un pequeño trozo de un gran conjunto de datos distribuidos. Spark gestiona los datos utilizando particiones que ayudan a paralelizar el procesamiento de datos con un mínimo de barrido de datos a través de los ejecutores.
Task : Una tarea es una unidad de trabajo que se puede ejecutar en una partición de un conjunto de datos distribuidos y se ejecuta en un solo ejecutor. La unidad de ejecución paralela está en el nivel de la tarea.Todas las tareas dentro de una sola etapa se pueden ejecutar en paralelo
Ejecutor : Un ejecutor es un único proceso JVM que se lanza para una aplicación en un nodo trabajador. Ejecutor ejecuta tareas y mantiene los datos en la memoria o el almacenamiento en disco a través de ellos. Cada aplicación tiene sus propios ejecutores. Un único nodo puede ejecutar varios ejecutores y los ejecutores de una aplicación pueden abarcar varios nodos trabajadores. Un ejecutor permanece durante la
duración de la aplicación Spark y ejecuta las tareas en múltiples hilos. El número de ejecutores para una aplicación Spark se puede especificar dentro de SparkConf o a través de la bandera -num-executors desde la línea de comandos.
Gestor de clúster : Un servicio externo para adquirir recursos en el clúster (por ejemplo, gestor independiente, Mesos, YARN). Spark es agnóstico a un gestor de cluster mientras pueda adquirir procesos ejecutores y estos puedan comunicarse entre sí.Nos interesa principalmente Yarn como gestor de cluster. Un cluster de Spark puede ejecutarse en modo yarn cluster o yarn-client:
Modo yarn-client – Un driver se ejecuta en el proceso cliente, el Application Master sólo se utiliza para solicitar recursos a YARN.
Modo yarn-cluster – Un driver se ejecuta dentro del proceso application master, el cliente desaparece una vez que la aplicación se inicializa
Cores : Un núcleo es una unidad básica de cálculo de la CPU y una CPU puede tener uno o más núcleos para realizar tareas en un momento dado. Cuantos más núcleos tengamos, más trabajo podremos hacer. En spark, esto controla el número de tareas paralelas que puede ejecutar un ejecutor.
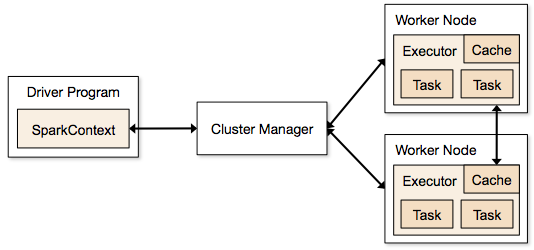
Pasos implicados en el modo cluster para un Spark Job
- Desde el código del driver, SparkContext se conecta al cluster manager (standalone/Mesos/YARN).
- El cluster manager asigna los recursos entre las demás aplicaciones. Se puede utilizar cualquier gestor de clúster siempre que los procesos de los ejecutores estén en marcha y se comuniquen entre sí.
- Spark adquiere ejecutores en los nodos del clúster. Aquí cada aplicación obtendrá sus propios procesos ejecutores.
- El código de la aplicación (archivos jar/python/python egg) se envía a los ejecutores
- Las tareas son enviadas por SparkContext a los ejecutores.
De los pasos anteriores, está claro que el número de ejecutores y su configuración de memoria juegan un papel importante en un trabajo de spark. Ejecutar ejecutores con demasiada memoria a menudo resulta en retrasos excesivos de recolección de basura
Ahora tratamos de entender, cómo configurar el mejor conjunto de valores para optimizar un trabajo de spark.
Hay dos formas en las que configuramos el ejecutor y los detalles del núcleo al trabajo de Spark. Son:
- Asignación estática – Los valores se dan como parte de spark-submit
- Asignación dinámica – Los valores se recogen en base a los requerimientos (tamaño de los datos, cantidad de cálculos necesarios) y se liberan después de su uso. Esto ayuda a reutilizar los recursos para otras aplicaciones.
Asignación estática
Se discuten diferentes casos variando diferentes parámetros y llegando a diferentes combinaciones según los requerimientos del usuario/datos.
Caso 1 Hardware – 6 Nodos y cada nodo tiene 16 núcleos, 64 GB de RAM
Primero en cada nodo, se necesita 1 núcleo y 1 GB para el Sistema Operativo y los Daemons de Hadoop, por lo que tenemos 15 núcleos, 63 GB de RAM para cada nodo
Comenzamos con cómo elegir el número de núcleos:
Número de núcleos = Tareas concurrentes que puede ejecutar un ejecutor
Así que podríamos pensar, que más tareas concurrentes para cada ejecutor darán mejor rendimiento. Pero la investigación muestra que cualquier aplicación con más de 5 tareas concurrentes, llevaría a un mal espectáculo. Así que el valor óptimo es 5.
Este número proviene de la capacidad de un ejecutor para ejecutar tareas paralelas y no de cuántos núcleos tiene un sistema. Así que el número 5 sigue siendo el mismo aunque tengamos el doble (32) de núcleos en la CPU
Número de ejecutores:
Pasando al siguiente paso, con 5 como núcleos por ejecutor, y 15 como total de núcleos disponibles en un nodo (CPU) – llegamos a 3 ejecutores por nodo que es 15/5. Tenemos que calcular el número de ejecutores en cada nodo y luego obtener el número total para el trabajo.
Así que con 6 nodos, y 3 ejecutores por nodo – tenemos un total de 18 ejecutores. De los 18 necesitamos 1 ejecutor (proceso java) para el Application Master en YARN. Así que el número final es 17 ejecutores
Este 17 es el número que le damos a spark usando -num-executors mientras se ejecuta desde el comando shell spark-submit
Memoria para cada ejecutor:
Desde el paso anterior, tenemos 3 ejecutores por nodo. Y la RAM disponible en cada nodo es de 63 GB
Así que la memoria para cada ejecutor en cada nodo es de 63/3 = 21GB.
Sin embargo, también se necesita una pequeña memoria de sobrecarga para determinar la solicitud de memoria completa a YARN para cada ejecutor.
La fórmula para esa sobrecarga es max(384, .07 * spark.executor.memory)
Calculando esa sobrecarga: .07 * 21 (Aquí 21 se calcula como arriba 63/3) = 1.47
Dado que 1.47 GB > 384 MB, la sobrecarga es 1.47
Toma lo anterior de cada 21 arriba => 21 – 1.47 ~ 19 GB
Así que la memoria del ejecutor – 19 GB
Números finales – Ejecutores – 17, Núcleos 5, Memoria del Ejecutor – 19 GB
Hardware del caso 2 – 6 Nodos y Cada nodo tiene 32 Núcleos, 64 GB
El número de núcleos de 5 es el mismo para una buena concurrencia como se explicó anteriormente.
Número de ejecutores para cada nodo = 32/5 ~ 6
Así que el total de ejecutores = 6 * 6 Nodos = 36. Entonces el número final es 36 – 1(para AM) = 35
Memoria de ejecutores:
6 ejecutores para cada nodo. 63/6 ~ 10. La sobrecarga es de 0,07 * 10 = 700 MB. Así que redondeando a 1 GB como sobrecarga, obtenemos 10-1 = 9 GB
Números finales – Ejecutores – 35, Núcleos 5, Memoria de Ejecutores – 9 GB
Caso 3 – Cuando no se requiere más memoria para los ejecutores
Los escenarios anteriores comienzan aceptando el número de núcleos como fijo y pasando al número de ejecutores y memoria.
Ahora para el primer caso, si pensamos que no necesitamos 19 GB, y sólo 10 GB es suficiente basado en el tamaño de los datos y los cálculos involucrados, entonces los siguientes son los números:
Núcleos: 5
Número de ejecutores para cada nodo = 3. Todavía 15/5 como se calculó anteriormente.
En esta etapa, esto llevaría a 21 GB, y luego 19 según nuestro primer cálculo. Pero como pensamos que 10 está bien (asumiendo poca sobrecarga), entonces no podemos cambiar el número de ejecutores por nodo a 6 (como 63/10). Porque con 6 ejecutores por nodo y 5 núcleos se reduce a 30 núcleos por nodo, cuando sólo tenemos 16 núcleos. Así que también tenemos que cambiar el número de núcleos para cada ejecutor.
Así que calculando de nuevo,
El número mágico 5 viene a ser 3 (cualquier número menor o igual a 5). Así que con 3 núcleos, y 15 núcleos disponibles – tenemos 5 ejecutores por nodo, 29 ejecutores ( que es (5*6 -1)) y la memoria es 63/5 ~ 12.
La sobrecarga es 12*.07=.84. Así que la memoria del ejecutor es 12 – 1 GB = 11 GB
Los números finales son 29 ejecutores, 3 núcleos, la memoria del ejecutor es 11 GB
Tabla resumen
Asignación dinámica
Nota: El límite superior para el número de ejecutores si la asignación dinámica está habilitada es infinito. Así que esto dice que la aplicación spark puede consumir todos los recursos si es necesario. En un clúster donde tenemos otras aplicaciones en ejecución y también necesitan núcleos para ejecutar las tareas, tenemos que asegurarnos de asignar los núcleos a nivel de clúster.
Esto significa que podemos asignar un número específico de núcleos para las aplicaciones basadas en YARN en función del acceso del usuario. Así que podemos crear un spark_user y luego dar núcleos (min/max) para ese usuario. Estos límites son para compartir entre spark y otras aplicaciones que se ejecutan en YARN.
Para entender la asignación dinámica, necesitamos tener conocimiento de las siguientes propiedades:
spark.dynamicAllocation.enabled – cuando esto se establece en true no necesitamos mencionar los ejecutores. La razón es la siguiente:
Los números de parámetros estáticos que damos en spark-submit son para toda la duración del trabajo. Sin embargo, si la asignación dinámica entra en escena, habría diferentes etapas como las siguientes:
Cuál es el número de ejecutores para empezar:
Número inicial de ejecutores (spark.dynamicAllocation.initialExecutors) para empezar
Controlar el número de ejecutores dinámicamente:
En función de la carga (tareas pendientes) cuántos ejecutores solicitar. Este sería finalmente el número que damos en spark-submit de forma estática. Así que una vez establecidos los números iniciales de ejecutores, pasamos a los números mínimos (spark.dynamicAllocation.minExecutors) y máximos (spark.dynamicAllocation.maxExecutors).
Cuándo pedir nuevos ejecutores o regalar los actuales:
Cuándo solicitamos nuevos ejecutores (spark.dynamicAllocation.schedulerBacklogTimeout) – Esto significa que ha habido tareas pendientes durante este tiempo. Así que la solicitud del número de ejecutores solicitados en cada ronda aumenta exponencialmente desde la ronda anterior. Por ejemplo, una aplicación añadirá 1 ejecutor en la primera ronda, y luego 2, 4, 8 y así sucesivamente ejecutores en las rondas siguientes. En un punto específico, la propiedad max anterior entra en escena.
Cuándo entregamos un ejecutor se establece usando spark.dynamicAllocation.executorIdleTimeout.
Para concluir, si necesitamos más control sobre el tiempo de ejecución del trabajo, monitorear el trabajo para el volumen de datos inesperados los números estáticos ayudarían. Al pasar a dinámico, los recursos se utilizarían en segundo plano y los trabajos que impliquen volúmenes inesperados podrían afectar a otras aplicaciones.