
- Krátký přehled nejlepších článků o klasifikaci obrazu za posledních deset let, abyste se mohli začít učit. Počítačové vidění
- 1998: LeNet
- 2012: AlexNet
- 2014: VGG
- 2014: GoogLeNet
- 2015: Dávková normalizace
- 2015: ResNet
- 2016: Xception
- 2017: MobileNet
- 2017: NASNet
- 2019: EfficientNet
- 2014: SPPNet
- 2016: DenseNet
- 2017: SENet
- 2017: ShuffleNet
- 2018: Pytel triků
- Závěr
Krátký přehled nejlepších článků o klasifikaci obrazu za posledních deset let, abyste se mohli začít učit. Počítačové vidění

Počítačové vidění je předmět, který převádí obrázky a videa do strojověsrozumitelné signály. Pomocí těchto signálů mohou programátoři dále řídit chování stroje na základě tohoto porozumění na vysoké úrovni. Mezi mnoha úlohami počítačového vidění je klasifikace obrazu jednou z nejzákladnějších. Nejenže ji lze využít v mnoha reálných produktech, jako je označování fotografií Google a moderování obsahu umělou inteligencí, ale otevírá také dveře pro spoustu pokročilejších úloh vidění, jako je detekce objektů a porozumění videu. Vzhledem k rychlým změnám v této oblasti od průlomu hlubokého učení je pro začátečníky často příliš náročné se ji naučit. Na rozdíl od typických předmětů softwarového inženýrství neexistuje mnoho skvělých knih o klasifikaci obrazu pomocí DCNN a nejlepším způsobem, jak tomuto oboru porozumět, je četba akademických článků. Ale jaké články číst? Kde začít? V tomto článku vám představím 10 nejlepších článků pro začátečníky, které si můžete přečíst. Díky těmto článkům můžeme vidět, jak se tento obor vyvíjí a jak vědci přišli s novými myšlenkami na základě výsledků předchozího výzkumu. Přesto je pro vás užitečné utřídit si celkový obraz, i když už v této oblasti nějakou dobu pracujete. Začněme tedy.
1998: LeNet
Učení založené na gradientu aplikované na rozpoznávání dokumentů

Zaveden v roce 1998, LeNet položila základ pro budoucí výzkum klasifikace obrazů pomocí konvoluční neuronové sítě. K extrakci rysů a klasifikaci se používá mnoho klasických technik CNN, jako jsou vrstvy sdružování, plně propojené vrstvy, vycpávky a aktivační vrstvy. Se ztrátovou funkcí Mean Square Error a 20 epochami trénování může tato síť dosáhnout 99,05% přesnosti na testovací sadě MNIST. I po 20 letech se mnoho nejmodernějších klasifikačních sítí obecně stále řídí tímto vzorem.
2012: AlexNet
Klasifikace obrazové sítě pomocí hlubokých konvolučních neuronových sítí

.
Přestože LeNet dosáhl skvělého výsledku a ukázal potenciál CNN, vývoj v této oblasti po desetiletí stagnoval kvůli omezenému výpočetnímu výkonu a množství dat. Vypadalo to, že CNN dokáže řešit pouze některé snadné úlohy, jako je rozpoznávání číslic, ale pro složitější rysy, jako jsou obličeje a objekty, byl preferovanějším přístupem HarrCascade nebo extraktor rysů SIFT s klasifikátorem SVM.
V roce 2012 však v soutěži ImageNet Large Scale Visual Recognition Challenge Alex Krizhevsky navrhl pro tuto výzvu řešení založené na CNN a drasticky zvýšil přesnost testovací sady ImageNet top-5 ze 73,8 % na 84,7 %. Jejich přístup zdědil myšlenku vícevrstvé sítě CNN od sítě LeNet, ale značně zvětšil velikost sítě CNN. Jak je vidět z výše uvedeného diagramu, vstup má nyní rozměry 224×224 oproti 32×32 u sítě LeNet, také mnohá konvoluční jádra mají 192 kanálů oproti 6 u sítě LeNet. Přestože se konstrukce příliš nezměnila, se stokrát větším počtem parametrů se stokrát zlepšila i schopnost sítě zachytit a reprezentovat složité rysy. K trénování tak velkého modelu Alex použil dva grafické procesory GTX 580 s 3 GB RAM pro každý z nich, čímž se stal průkopníkem trendu trénování na GPU. Také použití nelinearity ReLU pomohlo snížit náklady na výpočet.
Kromě toho, že přinesl mnohem více parametrů pro síť, zkoumal také problém s přiléhavostí, který přináší větší síť, pomocí vrstvy Dropout. Jeho metoda Local Response Normalization si později nezískala příliš velkou popularitu, ale inspirovala další důležité normalizační techniky, jako je BatchNorm, které bojují s problémem nasycení gradientu. Shrnuto a podtrženo, síť AlexNet de facto definovala rámec klasifikační sítě na dalších 10 let: kombinace Konvoluce, nelineární aktivace ReLu, MaxPoolingu a Husté vrstvy.
2014: VGG
Velmi hluboké konvoluční sítě pro velko-Scale Image Recognition
S tak velkým úspěchem použití CNN pro vizuální rozpoznávání, celá výzkumná komunita vybuchla a všichni začali zkoumat, proč tato neuronová síť tak dobře funguje. Například v článku „Visualizing and Understanding Convolutional Networks“ (Vizualizace a porozumění konvolučním sítím) z roku 2013 se Matthew Zeiler zabýval tím, jak CNN vybírá rysy a vizualizuje mezilehlé reprezentace. A najednou si všichni začali uvědomovat, že CNN je budoucností počítačového vidění od roku 2014. Ze všech těchto bezprostředních následovníků nejvíce upoutala síť VGG od společnosti Visual Geometry Group. Získala pozoruhodný výsledek 93,2% přesnosti top-5 a 76,3% přesnosti top-1 na testovací sadě ImageNet.
Po vzoru sítě AlexNet má síť VGG dvě hlavní aktualizace: VGG používá nejen širší síť jako AlexNet, ale také hlubší. VGG-19 má 19 konvolučních vrstev ve srovnání s 5 vrstvami sítě AlexNet. 2) VGG také ukázala, že několik malých konvolučních filtrů 3×3 může nahradit jeden filtr 7×7 nebo dokonce 11×11 z AlexNet, dosáhnout lepšího výkonu a zároveň snížit výpočetní náklady. Díky této elegantní konstrukci se VGG stala také páteřní sítí mnoha průkopnických sítí v dalších úlohách počítačového vidění, jako je FCN pro sémantickou segmentaci a Faster R-CNN pro detekci objektů.
S hlubší sítí se mizení gradientu z vícevrstvé zpětné propagace stává větším problémem. Aby se s ním VGG vypořádala, diskutovala také důležitost předtrénování a inicializace vah. Tento problém omezuje výzkumníky, aby neustále přidávali další vrstvy, jinak bude síť opravdu těžko konvergovat. Lepšího řešení se však dočkáme až za dva roky.
2014: GoogLeNet
Going Deeper with Convolutions

VGG má dobře vypadající a snadno pochopitelnou strukturu, ale jeho výkon není nejlepší ze všech finalistů soutěže ImageNet 2014. Finálovou cenu získal GoogLeNet alias InceptionV1. Stejně jako u VGG je jedním z hlavních přínosů sítě GoogLeNet posunutí hranice hloubky sítě se strukturou 22 vrstev. Tím se opět ukázalo, že jít do hloubky a do šířky je skutečně správný směr ke zlepšení přesnosti.
Na rozdíl od VGG se GoogLeNet pokusil řešit problémy s výpočtem a zmenšováním gradientu přímo, místo aby navrhl řešení pomocí lepšího předtrénovaného schématu a inicializace vah.

Nejprve zkoumal myšlenku asymetrického návrhu sítě pomocí modulu nazvaného Inception (viz schéma výše). V ideálním případě by chtěli sledovat řídké konvoluce nebo husté vrstvy pro zlepšení účinnosti funkcí, ale moderní návrh hardwaru nebyl pro tento případ přizpůsoben. Domnívali se tedy, že řídkost na úrovni topologie sítě by také mohla pomoci fúzi funkcí při využití stávajících možností hardwaru.
Druhé, útočí na problém vysokých výpočetních nákladů tím, že si vypůjčili myšlenku z článku nazvaného „Síť v síti“. V podstatě se zavádí konvoluční filtr 1×1, aby se zmenšily rozměry rysů předtím, než se projde těžkou výpočetní operací, jako je konvoluční jádro 5×5. Tato struktura se později nazývá „Bottleneck“ a široce se používá v mnoha následujících sítích. Podobně jako „Síť v síti“ použila také vrstvu průměrného sdružování, která nahradila konečnou plně propojenou vrstvu, aby dále snížila náklady.
Zatřetí, aby pomohla gradientům proudit do hlubších vrstev, použila síť GoogLeNet také dohled na některých výstupech mezivrstvy nebo pomocný výstup. Tato konstrukce není později v síti pro klasifikaci obrazu kvůli složitosti zcela populární, ale stává se populárnější v jiných oblastech počítačového vidění, například v síti přesýpacích hodin při odhadu polohy.
V návaznosti na to napsal tento tým společnosti Google další dokumenty pro tuto sérii Inception. „Dávková normalizace: InceptionV2: „Accelerating Deep Network Training by Reducing Internal Covariate Shift“. „Rethinking the Inception Architecture for Computer Vision“ z roku 2015 znamená InceptionV3. A „Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning“ z roku 2015 znamená InceptionV4. Každý článek přidal další vylepšení oproti původní síti Inception a dosáhl lepšího výsledku.
2015: Dávková normalizace
Dávková normalizace: Zrychlení tréninku hlubokých sítí snížením vnitřního posunu kovariát
Síť Inception pomohla výzkumníkům dosáhnout nadlidské přesnosti na datové sadě ImageNet. Jako statistická metoda učení je však CNN velmi omezena statistickou povahou konkrétní trénovací sady dat. Proto k dosažení lepší přesnosti obvykle potřebujeme předem vypočítat průměr a směrodatnou odchylku celé datové sady a použít je k normalizaci našich vstupů jako první, abychom zajistili, že většina vstupů vrstev v síti si bude blízká, což se projeví v lepší reaktivitě aktivace. Tento přibližný přístup je velmi těžkopádný a někdy pro novou strukturu sítě nebo nový soubor dat vůbec nefunguje, takže model hlubokého učení je stále považován za obtížně trénovatelný. Aby tento problém vyřešili, rozhodli se Sergej Ioffe a Chritian Szegedy, člověk, který vytvořil GoogLeNet, vymyslet něco chytřejšího, co se nazývá dávková normalizace.

Myšlenka dávkové normalizace není těžká: můžeme použít statistiku řady minidávek k aproximaci statistiky celého souboru dat, pokud trénujeme dostatečně dlouho. Také místo ručního výpočtu statistik můžeme zavést další dva naučitelné parametry „scale“ a „shift“, aby se síť sama naučila, jak normalizovat každou vrstvu.
Výše uvedený diagram ukázal postup výpočtu hodnot dávkové normalizace. Jak vidíme, vezmeme průměr celé minidávky a vypočítáme také rozptyl. Poté můžeme vstup normalizovat pomocí tohoto průměru a rozptylu minidávky. Nakonec se síť pomocí parametru měřítka a posunu naučí přizpůsobit výsledek normalizované dávky tak, aby co nejlépe vyhovoval následujícím vrstvám, obvykle ReLU. Jedním z upozornění je, že během inference nemáme k dispozici informace o minidávce, takže řešením je vypočítat během trénování klouzavý průměr a rozptyl a pak tyto klouzavé průměry použít v inferenční cestě. Tato malá inovace je tak působivá a všechny pozdější sítě ji začnou ihned používat.
2015: ResNet
Hluboké zbytkové učení pro rozpoznávání obrazu
2015 je možná nejlepší rok pro počítačové vidění za posledních deset let, viděli jsme tolik skvělých nápadů, které se objevily nejen v klasifikaci obrazu, ale ve všech možných úlohách počítačového vidění, jako je detekce objektů, sémantická segmentace atd. Největší pokrok roku 2015 patří nové síti zvané ResNet neboli zbytkové sítě, kterou navrhla skupina čínských výzkumníků ze společnosti Microsoft Research Asia.

Jak jsme již dříve uvedli u sítě VGG, největší překážkou ještě hlubšího rozšíření je problém mizení gradientu, tj.tj. derivace se při zpětném šíření hlubšími vrstvami stále zmenšují a nakonec dosáhnou bodu, který moderní počítačová architektura nedokáže smysluplně reprezentovat. GoogLeNet se na to pokusil zaútočit pomocí pomocného dohledu a asymetrického iniciačního modulu, ale problém zmírňuje jen v malé míře. Pokud budeme chtít použít 50 nebo dokonce 100 vrstev, bude existovat lepší způsob, jak gradient proudit sítí? Odpovědí sítě ResNet je použití reziduálního modulu.

ResNet přidal na výstup zkratku identity, takže každý reziduální modul nemůže alespoň předpovědět, co je na vstupu, aniž by se ztratil v divočině. Ještě důležitější věcí je, že namísto toho, aby každá vrstva doufala, že se přímo přizpůsobí požadovanému mapování příznaků, snaží se reziduální modul naučit rozdíl mezi výstupem a vstupem, což úlohu značně usnadňuje, protože potřebný informační zisk je menší. Představte si, že se učíte matematiku, pro každý nový problém je vám dáno řešení podobného problému, takže stačí toto řešení rozšířit a pokusit se, aby fungovalo. To je mnohem jednodušší než vymýšlet zcela nové řešení pro každý problém, na který narazíte. Aneb jak řekl Newton, můžeme stát na ramenou obrů, a identitní vstup je tím obrem pro reziduální modul.
Kromě identitního mapování si ResNet ze sítí Inception vypůjčil také úzké hrdlo a dávkovou normalizaci. Nakonec se podařilo vytvořit síť se 152 konvolučními vrstvami a dosáhnout 80,72% top-1 přesnosti na síti ImageNet. Reziduální přístup se později stal výchozí volbou i pro mnoho dalších sítí, například Xception, Darknet atd. Také díky svému jednoduchému a krásnému designu se dodnes hojně používá v mnoha produkčních systémech vizuálního rozpoznávání.
Po vzedmutí zájmu o reziduální síť vzniklo mnoho dalších invariantů. V knize „Identity Mappings in Deep Residual Networks“ se původní autor sítě ResNet pokusil umístit aktivaci před reziduální modul a dosáhl lepšího výsledku a tento návrh se poté nazývá ResNetV2. Také v článku „Aggregated Residual Transformations for Deep Neural Networks“ z roku 2016 výzkumníci navrhli ResNeXt, který přidal paralelní větve pro reziduální moduly, aby se agregovaly výstupy různých transformací.
2016: Xception
Xception: Hluboké učení s hloubkově oddělitelnými konvolucemi

S vydáním ResNetu to vypadalo, že většina nízko visících plodů v klasifikátoru obrazu již byla uchopena. Výzkumníci začali přemýšlet o tom, v čem spočívá vnitřní mechanismus kouzla CNN. Protože křížová konvoluce obvykle zavádí spoustu parametrů, rozhodli se tuto operaci prozkoumat, aby pochopili úplný obraz jejího účinku.
Síť Xception, stejně jako její název, vychází ze sítě Inception. V modulu Inception je více větví různých transformací agregováno dohromady, aby se dosáhlo řídké topologie. Proč ale tato řídkost funguje? Autor Xception, který je také autorem frameworku Keras, rozšířil tuto myšlenku na extrémní případ, kdy jeden konvoluční soubor 3×3 odpovídá jednomu výstupnímu kanálu před konečným spojením. V tomto případě tato paralelní konvoluční jádra vlastně tvoří novou operaci zvanou hloubková konvoluce.

Jak je znázorněno na výše uvedeném diagramu, na rozdíl od tradiční konvoluce, kde jsou všechny kanály zahrnuty do jednoho výpočtu, hloubkově oddělitelná konvoluce počítá konvoluci pouze pro každý kanál zvlášť a poté výstupy spojí dohromady. Tím se omezí výměna funkcí mezi kanály, ale také se sníží množství spojení, a tudíž vznikne vrstva s menším počtem parametrů. Výstupem této operace však bude stejný počet kanálů jako na vstupu (Nebo menší počet kanálů, pokud seskupíte dva nebo více kanálů dohromady). Proto po sloučení výstupů kanálů potřebujeme další běžný filtr 1×1 nebo bodovou konvoluci, abychom zvýšili nebo snížili počet kanálů, stejně jako to dělá běžná konvoluce.
Tato myšlenka původně nepochází z Xception. Je popsána v článku s názvem „Učení vizuálních reprezentací v měřítku“ a příležitostně se používá také v InceptionV2. Xception udělal další krok a téměř všechny konvoluce nahradil tímto novým typem. A výsledek experimentu se ukázal jako docela dobrý. Překonal ResNet i InceptionV3 a stal se novou metodou SOTA pro klasifikaci obrázků. Tím se také prokázalo, že mapování mezikanálových korelací a prostorových korelací v CNN lze zcela oddělit. Kromě toho, že sdílí stejnou přednost s ResNetem, má Xception také jednoduchý a krásný design, takže jeho myšlenka se používá v mnoha dalších následujících výzkumech, jako je MobileNet, DeepLabV3 atd.
2017: MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
Xception dosáhl 79% přesnosti top-1 a 94,5% přesnosti top-5 v síti ImageNet, což je však pouze 0,8%, resp. 0,4% zlepšení oproti předchozímu SOTA InceptionV3. Mezní zisk nové sítě pro klasifikaci obrazu je stále menší, takže výzkumníci začínají přesouvat svou pozornost do jiných oblastí. A MobileNet vedl k výraznému posunu klasifikace obrazu v prostředí s omezenými zdroji.

Podobně jako Xception používal MobileNet stejný hloubkově oddělitelný konvoluční modul, jak je uvedeno výše, a kladl důraz na vysokou účinnost a méně parametrů.
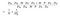
Čitatel ve výše uvedeném vzorci je celkový počet parametrů, které vyžaduje hloubkově oddělitelná konvoluce. A jmenovatel je celkový počet parametrů podobné pravidelné konvoluce. Zde D je velikost konvolučního jádra, D je velikost mapy příznaků, M je počet vstupních kanálů, N je počet výstupních kanálů. Protože jsme oddělili výpočet kanálového a prostorového rysu, můžeme násobení změnit na sčítání, které je o stupeň menší. A co víc, jak vidíme z tohoto poměru, čím větší je počet výstupních kanálů, tím více výpočtu jsme ušetřili použitím této nové konvoluce.
Dalším příspěvkem sítě MobileNet je násobič šířky a rozlišení. Tým MobileNet chtěl najít kanonický způsob, jak zmenšit velikost modelu pro mobilní zařízení, a nejintuitivnějším způsobem je snížit počet vstupních a výstupních kanálů a také rozlišení vstupního obrazu. Pro řízení tohoto chování se násobí poměr alfa s kanály a poměr rho se násobí se vstupním rozlišením (což také ovlivňuje velikost mapy prvků). Celkový počet parametrů lze tedy znázornit následujícím vzorcem:

Ačkoli se tato změna zdá být z hlediska inovace naivní, má velkou inženýrskou hodnotu, protože je to poprvé, kdy výzkumníci uzavírají kanonický přístup k přizpůsobení sítě pro různá omezení zdrojů. Také to tak trochu shrnuje konečné řešení zlepšování neuronové sítě: širší vstup s vysokým rozlišením vede k lepší přesnosti, tenčí vstup s nízkým rozlišením vede k horší přesnosti.
Později v roce 2018 a 2019 tým MobiletNet také vydal „MobileNetV2: Inverted Residuals and Linear Bottlenecks“ a „Searching for MobileNetV3“. V MobileNetV2 se používá struktura invertovaných reziduálních úzkých míst. A v MobileNetV3 se začala hledat optimální kombinace architektur pomocí technologie Neural Architecture Search, které se budeme věnovat příště.
2017: NASNet
Learning Transferable Architectures for Scalable Image Recognition
Stejně jako klasifikace obrazu pro prostředí s omezenými zdroji je vyhledávání neuronových architektur další oblastí, která se objevila kolem roku 2017. Díky sítím ResNet, Inception a Xception se zdá, že jsme dosáhli optimální topologie sítě, kterou člověk dokáže pochopit a navrhnout, ale co když existuje lepší a mnohem složitější kombinace, která dalece přesahuje lidskou představivost? V článku z roku 2016 nazvaném „Neural Architecture Search with Reinforcement Learning“ byla navržena myšlenka hledání optimální kombinace v předem definovaném prohledávacím prostoru pomocí posilovacího učení. Jak víme, posilovací učení je metoda hledání nejlepšího řešení s jasným cílem a odměnou pro hledajícího agenta. Vzhledem k omezení výpočetního výkonu se však tento článek zabýval pouze aplikací v malém souboru dat CIFAR.

S cílem najít optimální strukturu pro velký soubor dat, jako je ImageNet, vytvořil NASNet vyhledávací prostor, který je přizpůsoben pro ImageNet. Doufá, že se jí podaří navrhnout speciální vyhledávací prostor tak, aby výsledek hledání v CIFAR mohl dobře fungovat i v síti ImageNet. Za prvé, NASNet předpokládá, že běžný ručně vytvořený modul v dobrých sítích, jako jsou ResNet a Xception, je při vyhledávání stále užitečný. Místo hledání náhodných spojení a operací tedy NASNet prohledává kombinaci těchto modulů, které se ukázaly jako užitečné již na síti ImageNet. Za druhé, vlastní vyhledávání se stále provádí na datové sadě CIFAR s rozlišením 32×32, takže síť NASNet vyhledává pouze moduly, které nejsou ovlivněny velikostí vstupu. Aby druhý bod fungoval, NASNet předdefinoval dva typy šablon modulů: Redukce a Normální. Buňka Reduction by mohla mít zmenšenou mapu prvků ve srovnání se vstupem a pro buňku Normal by byla stejná.

Ačkoli síť NASNet má lepší metriky než ručně navržené sítě, trpí také několika nevýhodami. Náklady na hledání optimální struktury jsou velmi vysoké, což si mohou dovolit pouze velké společnosti jako Google a Facebook. Také výsledná struktura nedává lidem příliš velký smysl, a proto je obtížnější ji udržovat a vylepšovat v produkčním prostředí. Později, v roce 2018, se v rámci projektu „MnasNet: Platform-Aware Neural Architecture Search for Mobile“ dále rozšiřuje tuto myšlenku sítě NASNet tím, že omezuje krok vyhledávání pomocí předem definované struktury zřetězených bloků. Také definováním váhového faktoru poskytl mNASNet systematičtější způsob vyhledávání modelu vzhledem ke konkrétním omezením zdrojů, namísto pouhého vyhodnocování na základě FLOPs.
2019: EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
V roce 2019 to vypadá, že už neexistují žádné zajímavé nápady pro klasifikaci obrazu pod dohledem pomocí CNN. Drastická změna struktury sítě obvykle nabízí jen malé zlepšení přesnosti. A co hůř, když se stejná síť aplikuje na různé datové sady a úlohy, zdá se, že dříve proklamované triky nefungují, což vedlo ke kritice, zda tato zlepšení nejsou jen nadměrným přizpůsobením se datové sadě ImageNet. Na druhou stranu existuje jeden trik, který nikdy nezklamal naše očekávání: použití vstupu s vyšším rozlišením, přidání více kanálů pro konvoluční vrstvy a přidání více vrstev. I když je to velmi brutální síla, zdá se, že existuje principiální způsob, jak škálovat síť podle potřeby. MobileNetV1 to v roce 2017 tak trochu naznačoval, ale později se pozornost přesunula na lepší návrh sítě.

Po NASNet a mNASNet si vědci uvědomili, že ani s pomocí počítače nepřináší změna architektury takový přínos. Začali se tedy vracet ke škálování sítě. Síť EfficientNet je právě postavena na tomto předpokladu. Na jedné straně využívá optimální stavební kámen ze sítě mNASNet, aby se ujistil o dobrém základu pro začátek. Na druhé straně definuje tři parametry alpha, beta a rho, kterými řídí odpovídající hloubku, šířku a rozlišení sítě. Díky tomu se mohou inženýři i bez velkého fondu GPU pro hledání optimální struktury spolehnout na tyto principiální parametry a vyladit síť na základě svých různých požadavků. Nakonec síť EfficientNet poskytla 8 různých variant s různými poměry šířky, hloubky a rozlišení a získala dobrý výkon pro malé i velké modely. Jinými slovy, pokud chcete vysokou přesnost, sáhněte po síti EfficientNet-B7 s rozlišením 600 × 600 a 66M parametry. Pokud chcete nízkou latenci a menší model, zvolte variantu s rozměry 224×224 a parametry 5,3M EfficientNet-B0. Problém vyřešen.
Pokud dočtete výše uvedených 10 článků, měli byste mít docela dobrý přehled o historii klasifikace obrazu pomocí CNN. Pokud se chcete v této oblasti dále vzdělávat, uvádím také několik dalších zajímavých článků k přečtení. Ačkoli tyto práce nejsou zahrnuty v seznamu 10 nejlepších, všechny jsou ve své oblasti slavné a inspirovaly mnoho dalších výzkumníků ve světě.
2014: SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPPNet si vypůjčuje myšlenku pyramidy prvků z tradiční extrakce prvků počítačového vidění. Tato pyramida tvoří pytel slov rysů s různými měřítky, takže se může přizpůsobit různým velikostem vstupů a zbavit se plně připojené vrstvy s pevnou velikostí. Tato myšlenka také dále inspirovala modul ASPP systému DeepLab a také FPN pro detekci objektů.
2016: DenseNet
Hustě zapojené konvoluční sítě
DenseNet z Cornellu dále rozšiřuje myšlenku z ResNet. Poskytuje nejen přeskokové spojení mezi vrstvami, ale má také přeskokové spojení ze všech předchozích vrstev.
2017: SENet
Síť s přerušením a excitací
Síť Xception ukázala, že mezikanálová korelace nemá mnoho společného s prostorovou korelací. SENet však jako vítěz poslední soutěže ImageNet vymyslela blok Squeeze-and-Excitation a vyprávěla jiný příběh. Blok SE nejprve stlačí všechny kanály do menšího počtu kanálů pomocí globálního sdružování, aplikuje plně propojenou transformaci a poté je „excituje“ zpět na původní počet kanálů pomocí další plně propojené vrstvy. Vrstva FC tedy v podstatě pomohla síti naučit se pozornost na mapě vstupních funkcí.
2017: ShuffleNet
ShuffleNet: ShuffleNet je postaven na modulu MobileNetV2 s obráceným úzkým hrdlem a věří, že bodová konvoluce v hloubkově oddělitelné konvoluci obětuje přesnost výměnou za méně výpočtů. Aby to ShuffleNet kompenzoval, přidal dodatečnou operaci promíchání kanálů, která zajistí, že point-wise konvoluce nebude vždy aplikována na stejný „bod“. A v ShuffleNetV2 je tento mechanismus míchání kanálů dále rozšířen i na větev mapování identity ResNet, takže k míchání bude použita i část funkce identity.
2018: Pytel triků
Pytel triků pro klasifikaci obrazu pomocí konvolučních neuronových sítí
Pytel triků se zaměřuje na běžné triky používané v oblasti klasifikace obrazu. Slouží jako dobrá reference pro inženýry, když potřebují zlepšit srovnávací výkon. Zajímavé je, že těmito triky, jako je rozšíření mixup a kosinová míra učení, lze někdy dosáhnout mnohem lepšího zlepšení než novou architekturou sítě.
Závěr
S vydáním databáze EfficientNet se zdá, že klasifikační benchmark ImageNet končí. Se stávajícím přístupem hlubokého učení nikdy nenastane den, kdy bychom mohli dosáhnout 99,999% přesnosti v síti ImageNet, pokud nedojde k další změně paradigmatu. Proto se výzkumníci aktivně zabývají některými novými oblastmi, jako je samoučené nebo poloučené učení pro rozsáhlé vizuální rozpoznávání. Mezitím se s existujícími metodami stalo spíše otázkou pro inženýry a podnikatele, jak najít reálné využití této nedokonalé technologie. V budoucnu také napíšu přehled, který bude analyzovat tyto reálné aplikace počítačového vidění poháněné klasifikací obrazu, takže prosím zůstaňte naladěni! Pokud si myslíte, že existují i další důležité články pro klasifikaci obrázků, zanechte nám prosím komentář níže a dejte nám vědět.
Původně publikováno na http://yanjia.li dne 31. července 2020
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based Learning Applied to Document Recognition
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
- Sergey Ioffe, Christian Szegedy, Batch Normalization:
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition
- François Chollet, Xception: Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
- Mingxing Tan, Quoc V. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Connected Convolutional Networks
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Bag of Tricks for Image Classification with Convolutional Neural Networks