
Přidělování zdrojů je důležitým aspektem při provádění jakékoli úlohy Spark. Pokud není správně nakonfigurována, může úloha Spark spotřebovat celé zdroje clusteru a způsobit, že ostatní aplikace budou hladovět po zdrojích.
Tento blog pomáhá pochopit základní tok v aplikaci Spark a poté jak nakonfigurovat počet vykonavatelů, nastavení paměti jednotlivých vykonavatelů a počet jader pro úlohu Spark. Existuje několik faktorů, které musíme vzít v úvahu při rozhodování o optimálních počtech pro výše uvedené tři, jako např:
- Objem dat
- Čas, za který musí být úloha dokončena
- Statické nebo dynamické přidělování zdrojů
- Přídavná nebo následná aplikace
Úvod
Začněme několika základními definicemi pojmů používaných při zpracování aplikací Spark.
Díly : Oddíl je malý kousek velké distribuované množiny dat. Spark spravuje data pomocí oddílů, což pomáhá paralelizovat zpracování dat s minimálním promícháváním dat mezi vykonavateli.
Úloha : Úloha je jednotka práce, kterou lze spustit na oddílu distribuované sady dat a která se vykonává na jednom vykonavateli. Jednotka paralelního provádění je na úrovni úlohy. všechny úlohy s-v jedné fázi mohou být prováděny paralelně
Executor : Executor je jeden proces JVM, který je spuštěn pro aplikaci na pracovním uzlu. Executor spouští úlohy a uchovává data v paměti nebo v diskovém úložišti napříč nimi. Každá aplikace má své vlastní executory. Na jednom uzlu může být spuštěno více executorů a executory pro aplikaci mohou pokrývat více pracovních uzlů. Exekutor zůstává v provozu po dobu
trvání aplikace Spark a spouští úlohy ve více vláknech. Počet exekutorů pro aplikaci Spark lze zadat uvnitř SparkConf nebo pomocí příznaku -num-executors z příkazového řádku.
Správce clusteru : Externí služba pro získávání zdrojů na clusteru (např. samostatný správce, Mesos, YARN). Spark je agnostický vůči správci clusteru, pokud může získávat procesy executorů a ty mohou mezi sebou komunikovat. nás zajímá především Yarn jako správce clusteru. Spark cluster může běžet buď v režimu yarn cluster, nebo yarn-client:
režim yarn-client – Ovladač běží v klientském procesu, Application Master se používá pouze pro vyžádání zdrojů z YARN.
režim yarn-cluster – Ovladač běží uvnitř procesu Application Master, klient odchází, jakmile je aplikace inicializována
Jádra : Jádro je základní výpočetní jednotka procesoru a procesor může mít jedno nebo více jader pro provádění úloh v daném čase. Čím více jader máme, tím více práce můžeme vykonat. Ve Sparku se tím řídí počet paralelních úloh, které může vykonavatel spustit.
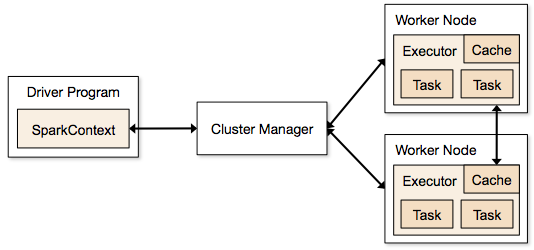
Kroky zapojené do režimu clusteru pro úlohu Spark
- Z kódu ovladače se SparkContext připojí ke správci clusteru (standalone/Mesos/YARN).
- Správce clusteru přiděluje prostředky ostatním aplikacím. Lze použít libovolného správce clusteru, pokud jsou spuštěny procesy vykonavatelů a pokud spolu komunikují.
- Spark získává vykonavatele na uzlech v clusteru. Zde každá aplikace získá své vlastní procesy executor.
- Kód aplikace (soubory jar/python/python egg) je odeslán executorům
- Úlohy jsou odeslány SparkContextem executorům.
Z výše uvedených kroků je zřejmé, že počet executorů a nastavení jejich paměti hraje hlavní roli v úloze Spark. Spuštění executorů s příliš velkým množstvím paměti často vede k nadměrnému zpoždění garbage collection
Nyní se pokusíme pochopit, jak nastavit nejlepší sadu hodnot pro optimalizaci úlohy Spark.
Existují dva způsoby, jak nastavit executory a detaily jádra k úloze Spark. Jsou to:
- Statická alokace – Hodnoty jsou zadány jako součást příkazu spark-submit
- Dynamická alokace – Hodnoty jsou vybrány na základě požadavku (velikost dat, množství potřebných výpočtů) a po použití uvolněny. To pomáhá prostředky znovu použít pro jiné aplikace.
Statické přidělování
Probírají se různé případy, kdy se mění různé parametry a dochází se k různým kombinacím podle požadavků uživatele/dat.
Případ 1 Hardware – 6 uzlů a každý uzel má 16 jader, 64 GB RAM
Nejprve je na každém uzlu potřeba 1 jádro a 1 GB pro operační systém a démony Hadoop, takže máme 15 jader, 63 GB RAM pro každý uzel
Začneme tím, jak zvolit počet jader:
Počet jader = souběžné úlohy, které může vykonavatel spustit
Můžeme si tedy myslet, že více souběžných úloh pro každý vykonavatel poskytne lepší výkon. Ale výzkumy ukazují, že každá aplikace s více než 5 souběžnými úlohami by vedla ke špatnému výkonu. Optimální hodnota je tedy 5.
Toto číslo vychází ze schopnosti vykonavatele spouštět paralelní úlohy, a ne z toho, kolik má systém jader. Takže číslo 5 zůstává stejné, i když máme v CPU dvojnásobek (32) jader
Počet vykonavatelů:
Přejdeme-li k dalšímu kroku, s 5 jako jádry na vykonavatele a 15 jako celkovými dostupnými jádry v jednom uzlu (CPU) – dojdeme ke 3 vykonavatelům na uzel, což je 15/5. Musíme vypočítat počet vykonavatelů v každém uzlu a pak získat celkový počet pro úlohu.
Takže při 6 uzlech a 3 vykonavatelích na uzel – dostaneme celkem 18 vykonavatelů. Z 18 potřebujeme 1 vykonavatele (java proces) pro Application Master v YARN. Takže konečné číslo je 17 exekutorů
Těchto 17 je číslo, které zadáme Sparku pomocí -num-executors při spouštění z příkazu shellu spark-submit
Paměť pro každý exekutor:
Z výše uvedeného kroku máme 3 exekutory na uzel. A dostupná paměť RAM v každém uzlu je 63 GB
Takže paměť pro každý exekutor v každém uzlu je 63/3 = 21 GB.
Malá režijní paměť je však také potřeba k určení požadavku na plnou paměť pro YARN pro každý exekutor.
Vzorec pro tuto režii je max(384, .07 * spark.executor.memory)
Výpočet této režie: .07 * 21 (Zde 21 je počítáno jako výše uvedených 63/3) = 1,47
Protože 1,47 GB > 384 MB, režie je 1.47
Vezměte výše uvedené od každého 21 výše => 21 – 1,47 ~ 19 GB
Takže paměť exekutorů – 19 GB
Konečná čísla – exekutoři – 17, jader 5, paměť exekutorů – 19 GB
Případ 2 Hardware – 6 uzlů a každý uzel má 32 jader, 64 GB
Počet jader 5 je stejný pro dobrou souběžnost, jak je vysvětleno výše.
Počet vykonavatelů pro každý uzel = 32/5 ~ 6
Takže celkový počet vykonavatelů = 6 * 6 uzlů = 36. Pak je konečný počet 36 – 1 (pro AM) = 35
Paměť pro vykonavatele:
6 vykonavatelů pro každý uzel. 63/6 ~ 10. Režie je 0,07 * 10 = 700 MB. Takže po zaokrouhlení na 1 GB jako režie dostaneme 10-1 = 9 GB
Konečná čísla – Exekutivy – 35, jader 5, paměť pro exekutory – 9 GB
Případ 3 – Když pro exekutory není potřeba více paměti
Výše uvedené scénáře začínají přijetím počtu jader jako pevného a přecházejí k počtu exekutorů a paměti.
Nyní pro první případ, pokud si myslíme, že nepotřebujeme 19 GB a stačí nám 10 GB na základě velikosti dat a zahrnutých výpočtů, pak jsou následující čísla:
Jádra:
Počet vykonavatelů pro každý uzel = 3. Stále 15/5, jak bylo vypočteno výše.
V této fázi by to vedlo k 21 GB, a pak 19 podle našeho prvního výpočtu. Ale protože jsme si mysleli, že 10 je v pořádku (předpokládáme malou režii), pak nemůžeme přepnout počet vykonavatelů na uzel na 6 (jako 63/10). Protože s 6 vykonavateli na uzel a 5 jádry to vychází na 30 jader na uzel, když máme jen 16 jader. Takže musíme také změnit počet jader pro každý exekutor.
Takže opět počítáme,
magické číslo 5 vychází 3 (libovolné číslo menší nebo rovno 5). Takže s 3 jádry a 15 dostupnými jádry – dostaneme 5 vykonavatelů na uzel, 29 vykonavatelů ( což je (5*6 -1)) a paměť je 63/5 ~ 12.
Převýšení je 12*.07=.84. Takže paměť exekutorů je 12 – 1 GB = 11 GB
Konečná čísla jsou 29 exekutorů, 3 jádra, paměť exekutorů je 11 GB
Souhrnná tabulka
Dynamické přidělování
Poznámka: Horní hranice počtu exekutorů, pokud je dynamické přidělování povoleno, je nekonečno. To tedy říká, že aplikace spark může v případě potřeby sežrat všechny prostředky. V clusteru, kde máme spuštěné další aplikace, které také potřebují jádra pro spouštění úloh, musíme zajistit, abychom jádra přidělovali na úrovni clusteru.
To znamená, že můžeme přidělit konkrétní počet jader pro aplikace založené na YARN na základě přístupu uživatelů. Můžeme tedy vytvořit uživatele spark_user a poté tomuto uživateli přidělit jádra (min/max). Tyto limity slouží ke sdílení mezi sparkem a ostatními aplikacemi, které běží na YARN.
Pro pochopení dynamické alokace potřebujeme znát následující vlastnosti:
spark.dynamicAllocation.enabled – pokud je tato hodnota nastavena na true, nemusíme zmiňovat executory. Důvod je uveden níže:
Čísla statických parametrů, která uvádíme při spark-submit, jsou pro celou dobu trvání úlohy. Pokud by však přišla ke slovu dynamická alokace, nastaly by různé fáze jako následující:
Jaký je počet pro exekutory na začátku:
Inicialní počet exekutorů (spark.dynamicAllocation.initialExecutors) na začátku
Řízení počtu exekutorů dynamicky:
Poté na základě zatížení (čekající úlohy), kolik exekutorů požadovat. Nakonec by to byl počet, který staticky zadáme při spark-submit. Takže po nastavení počátečního počtu exekutorů přejdeme na min (spark.dynamicAllocation.minExecutors) a max (spark.dynamicAllocation.maxExecutors) počet:
Kdy požádat o nové exekutory nebo dát pryč stávající exekutory:
Kdy požádat o nové exekutory (spark.dynamicAllocation.schedulerBacklogTimeout) – To znamená, že po tuto dobu byly nevyřízené úlohy. Takže požadavek na počet vykonavatelů požadovaných v každém kole exponenciálně roste oproti předchozímu kolu. Například aplikace přidá v prvním kole 1 vykonavatel a v dalších kolech pak 2, 4, 8 atd. vykonavatelů. V určitém okamžiku přichází ke slovu výše uvedená vlastnost max.
Kdy odevzdáme exekutora se nastavuje pomocí spark.dynamicAllocation.executorIdleTimeout.
Na závěr, pokud potřebujeme větší kontrolu nad dobou provádění úlohy, pomůže sledování úlohy pro neočekávaný objem dat statická čísla. Přechodem na dynamické by se prostředky využívaly na pozadí a úlohy zahrnující neočekávané objemy by mohly ovlivnit ostatní aplikace.