
První, co musíme pochopit, je podstata proměnných a jak se proměnné používají v designu studie k zodpovězení studijních otázek. V této kapitole se dozvíte:
- různé typy proměnných v kvantitativních studiích,
- otázky týkající se otázky jednotky analýzy.
Pochopení kvantitativních proměnných
Kořen slova proměnná souvisí se slovem „vary“, což by nám mělo pomoci pochopit, co mohou být proměnné. Proměnné jsou prvky, entity nebo faktory, které se mohou měnit (variovat); například venkovní teplota, cena benzinu za galon, váha člověka a nálada osob ve vaší širší rodině jsou proměnné. Jinými slovy, mohou mít různé hodnoty za různých podmínek nebo pro různé lidi.
Proměnné používáme k popisu prvků nebo faktorů, které nás zajímají. Příkladem může být počet členů v různých domácnostech, vzdálenost ke zdrojům zdravých potravin v různých čtvrtích, poměr počtu vyučujících sociální práce a studentů v programu BSW nebo MSW, podíl uvězněných osob z různých rasových/etnických skupin, náklady na dopravu za službami programu sociální práce nebo míra kojenecké úmrtnosti v různých okresech. Ve výzkumu intervencí v sociální práci mohou proměnné zahrnovat charakteristiky intervence (intenzitu, četnost, trvání) a výsledky spojené s intervencí.
Demografické proměnné. Sociální pracovníky často zajímá to, co nazýváme demografickými proměnnými. Demografické proměnné se používají k popisu charakteristik populace, skupiny nebo vzorku populace. Příklady často používaných demografických proměnných jsou
- věk,
- etnická příslušnost,
- národní původ,
- náboženská příslušnost,
- pohlaví,
- sexuální orientace,
- manželský/vztahový stav,
- zaměstnanecký stav,
- politická příslušnost,
- geografická poloha,
- úroveň vzdělání a
- příjem.
Na makroúrovni demografické charakteristiky komunity nebo organizace často zahrnují její velikost; organizace jsou často měřeny z hlediska jejich celkového rozpočtu.
Nezávislé a závislé proměnné. Způsob, jakým řešitelé uvažují o studijních proměnných, má důležité důsledky pro návrh studie. Vyšetřovatelé se rozhodují o tom, zda budou sloužit jako nezávislé proměnné, nebo jako závislé proměnné. Toto rozlišení není něčím, co je proměnné vlastní, ale vychází z toho, jak se zkoušející rozhodne každou proměnnou definovat. Nezávislé proměnné jsou ty, které si můžete představit jako manipulované „vstupní“ proměnné, zatímco závislé proměnné jsou ty, u nichž by se pozoroval dopad nebo „výstup“ této vstupní změny.
Ne vždy se jedná o záměrnou manipulaci se „vstupní“ (nezávislou) proměnnou. Uvažujme příklad studie provedené ve Švédsku, která zkoumala vztah mezi tím, že se děti staly obětí týrání, a pozdější absencí na střední škole: nikdo záměrně nemanipuloval s tím, zda se děti stanou obětí týrání (Hagborg, Berglund, & Fahlke, 2017). Badatelé předpokládali, že přirozeně se vyskytující rozdíly ve vstupní proměnné (historie špatného zacházení s dětmi) budou spojeny se systematickými rozdíly ve specifické výsledné proměnné (absence ve škole). V tomto případě byla nezávisle proměnnou historie, kdy se dítě stalo obětí špatného zacházení, a závisle proměnnou byl výsledek absence ve škole. Jinými slovy, zkoušející předpokládá, že nezávislá proměnná způsobuje variabilitu nebo změnu závislé proměnné. Takto může vypadat schéma, kde „x“ je nezávislá proměnná a „y“ je závislá proměnná (poznámka: toto označení jste viděli dříve, v kapitole 3, když jsme probírali logiku příčin a následků):

Pro další příklad uvažujme výzkum, který naznačuje, že být obětí špatného zacházení s dětmi je spojeno s vyšším rizikem užívání návykových látek během dospívání (Yoon, Kobulsky, Yoon, & Kim, 2017). Nezávislou proměnnou v tomto modelu by bylo mít v anamnéze špatné zacházení s dítětem. Závisle proměnnou by bylo riziko užívání návykových látek během dospívání. Tento příklad je ještě propracovanější, protože specifikuje cestu, kterou by nezávislá proměnná (špatné zacházení s dětmi) mohla uplatňovat své účinky na závislou proměnnou (užívání návykových látek v dospívání). Autoři studie prokázali, že posttraumatický stres (PTS) je spojovacím článkem mezi týráním v dětství (fyzickým a sexuálním) a užíváním návykových látek během dospívání.

Věnujte chvíli následující aktivitě.
Typy kvantitativních proměnných
Existují i další smysluplné způsoby, jak přemýšlet o proměnných, které vás zajímají. Uvažujme o různých vlastnostech proměnných používaných v kvantitativních výzkumných studiích. Zde zkoumáme kvantitativní proměnné jako kategoriální, ordinální nebo intervalové povahy. Tyto vlastnosti mají důsledky pro měření i analýzu dat.
Kategoriální proměnné. Některé proměnné mohou nabývat hodnot, které se liší, ale ne významným číselným způsobem. Místo toho mohou být definovány z hlediska kategorií, které jsou možné. Logicky se tyto proměnné nazývají kategoriální proměnné. Statistický software a učebnice někdy označují proměnné s kategoriemi jako nominální proměnné. Nominální lze chápat ve smyslu latinského kořene „nom“, který znamená „jméno“ a neměl by se zaměňovat s číslem. Nominální znamená při popisu proměnných totéž co kategoriální. Jinými slovy, kategoriální nebo nominální proměnné jsou identifikovány názvy nebo označeními reprezentovaných kategorií. Například barva posledního auta, ve kterém jste jeli, by byla kategoriální proměnnou: modrá, černá, stříbrná, bílá, červená, zelená, žlutá nebo jiná jsou kategorie proměnné, kterou můžeme nazvat barva auta.
U kategoriálních proměnných je důležité, že tyto kategorie nemají žádnou relevantní číselnou posloupnost nebo pořadí. Neexistuje žádný číselný rozdíl mezi různými barvami aut ani rozdíl mezi „ano“ nebo „ne“ jako kategoriemi při odpovědi, zda jste jeli modrým autem. Neexistuje žádné implicitní pořadí nebo hierarchie kategorií „Hispánec nebo Latinoameričan“ a „Není Hispánec nebo Latinoameričan“ v proměnné etnický původ; stejně tak neexistuje žádné relevantní pořadí kategorií proměnných, jako je pohlaví, stát nebo zeměpisná oblast, kde osoba bydlí, nebo zda je bydliště osoby ve vlastnictví nebo v nájmu.
Pokud se výzkumník rozhodne použít čísla jako symboly vztahující se ke kategoriím v takové proměnné, jsou čísla libovolná – každé číslo je v podstatě jen jiný, kratší název pro každou kategorii. Například proměnná pohlaví může být kódována následujícími způsoby a nebude v tom žádný rozdíl, pokud bude kód důsledně aplikován.
| Varianta kódování A | Kategorie proměnných | Varianta kódování B |
|---|---|---|
| 1 | muž | 2 |
| 2 | žena | 1 |
| 3 | jiné než samotný muž nebo žena | 4 |
| 4 | radši neodpovídám | 3 |
Rasa a etnický původ.Jednou z nejčastěji zkoumaných kategoriálních proměnných v sociální práci a sociálněvědním výzkumu je demografická proměnná odkazující na rasový a/nebo etnický původ osoby. Mnoho studií využívá kategorie uvedené v minulých zprávách Úřadu pro sčítání lidu USA. Zde je uvedeno, co o dvou odlišných demografických proměnných, rase a etnicitě, říká U.S. Census Bureau (https://www.census.gov/mso/www/training/pdf/race-ethnicity-onepager.pdf):
Co je to rasa? Úřad pro sčítání lidu definuje rasu jako sebeidentifikaci osoby s jednou nebo více sociálními skupinami. Jednotlivec se může hlásit k bělochům, černochům nebo Afroameričanům, Asiatům, americkým indiánům a původním obyvatelům Aljašky, původním obyvatelům Havaje a ostatních tichomořských ostrovů nebo k některé jiné rase. Respondenti průzkumu mohou uvést více ras.
Co je to etnická příslušnost? Etnická příslušnost určuje, zda je osoba hispánského původu či nikoli. Z tohoto důvodu je etnická příslušnost rozdělena do dvou kategorií: Hispánci nebo Latinoameričané a Ne Hispánci nebo Latinoameričané. Hispánci se mohou hlásit k jakékoli rase.
Jinými slovy, Census Bureau definuje dvě kategorie pro proměnnou zvanou etnická příslušnost (Hispánci nebo Latinoameričané a Ne Hispánci nebo Latinoameričané) a sedm kategorií pro proměnnou zvanou rasa. Ačkoli se tyto proměnné a kategorie často používají ve výzkumu v oblasti sociálních věd a sociální práce, nejsou bez kritiky.
Na základě těchto kategorií uvádíme, co se odhaduje o populaci USA v roce 2016:
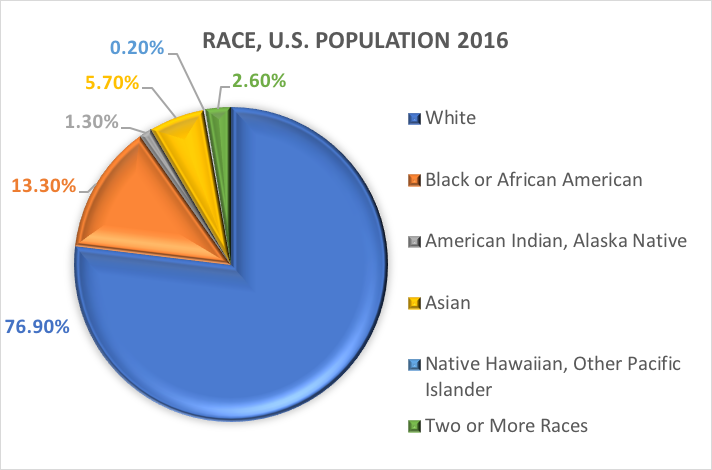
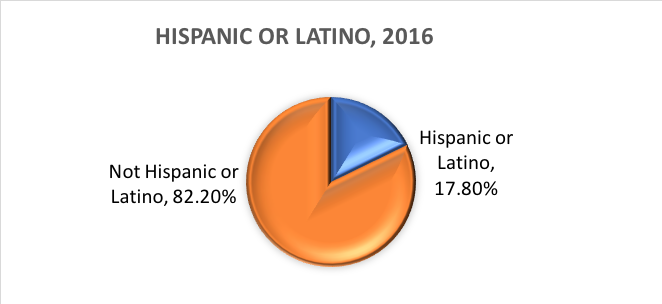
Dichotomické proměnné: Existuje zvláštní kategorie kategoriálních proměnných s důsledky pro určité statistické analýzy. Kategoriální proměnné, které se skládají přesně ze dvou možností, ne více a ne méně, se nazývají dichotomické proměnné. Jedním z příkladů je dichotomická proměnná Úřadu pro sčítání lidu Spojených států amerických (U.S. Census Bureau): Hispánská/latinoamerická a neispánská/nelatinská etnická příslušnost. Jiným příkladem může být, že vyšetřovatelé chtějí porovnat osoby, které dokončí léčbu, s těmi, které ji před dokončením přeruší. Se dvěma kategoriemi, dokončil nebo nedokončil, je tato proměnná dokončení léčby nejen kategoriální, ale i dichotomická. Proměnné, u nichž jednotlivci odpovídají „ano“ nebo „ne“, jsou rovněž dichotomické povahy.
Dalším příkladem dichotomické proměnné je dřívější tradice považovat pohlaví za mužské nebo ženské. Existují však velmi silné argumenty pro to, aby se s pohlavím již takto dichotomicky nezacházelo: v sociální práci je prokazatelně relevantní větší rozmanitost genderových identit osob, jejichž identita se neshoduje s dichotomickými (nazývanými také binárními) kategoriemi muž/žena nebo muž/žena. Patří sem kategorie jako agender, androgynní, bigender, cisgender, genderově expanzivní, genderově fluidní, genderově pochybující, queer, transgender a další.
Ordinální proměnné. Na rozdíl od těchto kategoriálních proměnných mají někdy kategorie proměnné logickou číselnou posloupnost nebo pořadí. Ordinální proměnná podle definice označuje pozici v řadě. Proměnné s číselně příslušnými kategoriemi se nazývají ordinální proměnné. Například u proměnné nazvané dosažené vzdělání existuje implicitní pořadí kategorií od nejmenšího k největšímu. Ve Spojených státech amerických se v tomto případě jedná o tzv. Census data kategorie pro tuto ordinální proměnnou jsou:
- žádná
- 1.-4. třída
- 5.-6. třída
- 7.-8. třída
- 9. třída
- 10. třída
- 11. třída
- absolvent střední školy
- nějaká vysoká škola, bez vzdělání
- družstevní vzdělání, profesní
- asociovaný akademický titul
- bakalářský titul
- magisterský titul
- profesní titul
- doktorský titul
Při pohledu na data odhadu Census Bureau z roku 2016 pro tuto proměnnou vidíme, že v kategorii dosažení bakalářského titulu převažují ženy nad muži: Z 47 718 000 osob v této kategorii bylo 22 485 000 mužů a 25 234 000 žen. Zatímco u osob s magisterským titulem tento genderový vzorec platil, u osob s doktorským titulem byl obrácený: tento nejvyšší stupeň vzdělání získalo více mužů než žen. Je také zajímavé, že ženy převažovaly nad muži na spodní hranici spektra: 441 000 žen uvedlo, že nemá žádné vzdělání, zatímco 374 000 mužů.
Je zde další příklad využití ordinálních proměnných ve výzkumu sociální práce: když jednotlivci vyhledají léčbu kvůli problému s nadužíváním alkoholu, sociální pracovníci mohou chtít vědět, zda se jedná o jejich první, druhý, třetí nebo jakýkoli číslovaný vážný pokus o změnu chování při pití. Účastníci zařazení do studie porovnávající přístupy k léčbě poruch způsobených užíváním alkoholu uváděli, že intervenční studie byla jejich prvním až jedenáctým pokusem o významnou změnu (Begun, Berger, Salm-Ward, 2011). Tato proměnná pokusu o změnu má důsledky pro to, jak mohou sociální pracovníci interpretovat údaje hodnotící intervenci, která nebyla pro všechny zúčastněné prvním pokusem.
Rating scales. Uvažujme jiný, ale běžně používaný typ ordinální proměnné: hodnotící škály. Výzkumníci v oblasti sociální, behaviorální a sociální práce často žádají účastníky studie, aby použili hodnotící škálu k popisu svých znalostí, postojů, přesvědčení, názorů, dovedností nebo chování. Protože kategorie na takové škále jsou řazeny za sebou (od nejvíce k nejméně nebo od nejméně k nejvíce), nazýváme je ordinálními proměnnými.

Mezi příklady patří zadání hodnocení účastníkům:
- jak moc souhlasí nebo nesouhlasí s určitými výroky (vůbec ne až extrémně moc);
- jak často se věnují určitému chování (nikdy až vždy);
- jak často se věnují určitému chování (každou hodinu, denně, týdně, měsíčně, ročně nebo méně často);
- kvalitu něčího jednání (špatná až vynikající);
- jak byli spokojeni s léčbou (velmi nespokojeni až velmi spokojeni)
- úroveň jejich důvěry (velmi nízká až velmi vysoká).
Intervalové proměnné. Ještě další proměnné nabývají hodnot, které se mění smysluplným číselným způsobem. Z našeho seznamu demografických proměnných je běžným příkladem věk. Číselná hodnota přiřazená jednotlivým osobám udává počet let od narození osoby (v případě kojenců může číselná hodnota udávat dny, týdny nebo měsíce od narození). Zde jsou možné hodnoty proměnné uspořádány podobně jako u ordinálních proměnných, ale je zde zaveden velký rozdíl: povaha intervalů mezi možnými hodnotami. U intervalových proměnných jsou „vzdálenosti“ mezi sousedními možnými hodnotami stejné. Některé statistické softwarové balíky a učebnice používají termín škálová proměnná: to je přesně totéž, čemu říkáme intervalová proměnná.
Například v níže uvedeném grafu je rozdíl 1 unce mezi tím, zda tato osoba vypije 1 unci nebo 2 unce alkoholu (pondělí, úterý), přesně stejný jako rozdíl 1 unce mezi tím, zda vypije 4 unce nebo 5 uncí (pátek, sobota). Pokud bychom na stupnici zakreslili možné body, byly by všechny stejně vzdálené; interval mezi libovolnými dvěma body se měří ve standardních jednotkách (v tomto příkladu v uncích).
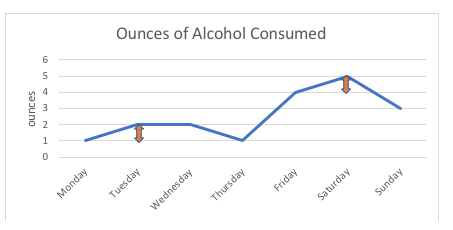
U ordinálních proměnných, jako jsou hodnotící škály, nelze s jistotou říci, že „vzdálenost“ mezi možnostmi odpovědí „nikdy“ a „někdy“ je stejná jako „vzdálenost“ mezi „někdy“ a „často“, i kdybychom použili čísla pro řazení těchto možností odpovědí. Hodnotící škála tedy zůstává ordinální, nikoli intervalová.
Co může být trochu matoucí, je to, že některé statistické programy, jako například SPSS, označují intervalovou proměnnou jako proměnnou „škálovou“. Mnoho proměnných používaných ve výzkumu sociální práce je jednak uspořádaných, jednak mají stejné vzdálenosti mezi body. Vezměme si například proměnnou pořadí narození. Tato proměnná je intervalová, protože:
- možné hodnoty jsou uspořádané (např. třetí narozené dítě přišlo po prvorozeném a druhorozeném a před čtvrtým narozeným) a
- „vzdálenosti“ nebo intervaly jsou měřeny v ekvivalentních jednotkách jedné osoby.
Kontinuální proměnné. Existuje zvláštní typ číselných intervalových proměnných, které nazýváme spojité proměnné. Proměnnou, jako je věk, můžeme považovat za spojitou proměnnou. Věk má ordinální charakter, protože vyšší čísla něco znamenají ve vztahu k menším číslům. Věk také splňuje naše kritéria pro to, aby byl intervalovou proměnnou, pokud ho měříme v letech (nebo měsících či týdnech nebo dnech), protože je ordinální a mezi věkem 15 a 30 let je stejná „vzdálenost“ jako mezi věkem 40 a 55 let (15 kalendářních let). To, co z ní dělá spojitou veličinu, je, že mezi libovolnými dvěma intervaly jsou také možné smysluplné „zlomkové“ body. Například člověku může být 20½ (20,5) nebo 20¼ (20,25) nebo 20¾ (20,75) let; nejsme omezeni pouze na celá čísla pro věk. Naproti tomu při pohledu na pořadí narození nemůžeme mít smysluplný zlomek osoby mezi dvěma pozicemi na stupnici.
Speciální případ příjmu. Jednou z nejvíce zneužívaných proměnných v sociálních vědách a ve výzkumu sociální práce je proměnná týkající se příjmu. Uvažujme příklad o příjmu domácnosti (bez ohledu na to, kolik osob je v domácnosti). Tato proměnná může být kategoriální (nominální), ordinální nebo intervalová (škálová) podle toho, jak se s ní zachází.
Kategoriální příklad: V závislosti na povaze výzkumných otázek se řešitel může jednoduše rozhodnout použít pro klasifikaci domácností dichotomické kategorie „dostatečně zajištěné“ a „nedostatečně zajištěné“ na základě nějaké standardní metody výpočtu. Pokud se pro kategorizaci domácností použije hranice chudoby, mohou být tyto domácnosti nazvány „chudé“ a „nechudé“. Tyto odlišné kategorie příjmové proměnné nejsou smysluplně číselně řazeny, takže se jedná o kategoriální proměnnou.
Ordinální příklad: Kategorie pro klasifikaci domácností mohou být seřazeny od nízké po vysokou. Například tyto kategorie ročního příjmu jsou běžné ve výzkumu trhu:
- Méně než 25 000 USD.
- 25 000 až 34 999 USD.
- 35 000 až 49 999 USD.
- 50 000 až 74 999 USD.
- 75 000 až 99 999 USD.
- 100 000 až 149 999 USD.
- 150 000 až 199 999 USD.
- 200 000 USD a více.
Všimněte si, že kategorie nejsou stejně velké – „vzdálenost“ mezi dvojicemi kategorií není vždy stejná. Začínají zhruba po 10 000 USD, přechází na 25 000 USD a končí zhruba po 50 000 USD.
Příklad intervalu. Pokud by řešitel požádal účastníky studie, aby uvedli skutečnou částku v dolarech pro příjem domácnosti, viděli bychom intervalovou proměnnou. Možné hodnoty jsou seřazeny a interval mezi všemi možnými sousedními jednotkami je 1 dolar (pokud nejsou použity dolarové zlomky nebo centy). Příjem 10 452 dolarů je tedy na kontinuu od 9 452 dolarů a 11 452 dolarů ve stejné vzdálenosti – 1 000 dolarů na obě strany.

Speciální případ věku. Stejně jako příjem může „věk“ v různých studiích znamenat různé věci. Věk je obvykle ukazatelem „doby od narození“. Věk osoby můžeme vypočítat odečtením proměnné datum narození od data měření (dnešní datum minus datum narození). U dospělých se věk obvykle měří v letech, přičemž sousední možné hodnoty jsou vzdáleny v jednotkách jednoho roku: 18, 19, 20, 21, 22 atd. Proměnná věku by tedy mohla být spojitým typem intervalové proměnné.
Třebaže si vyšetřovatel může přát rozdělit údaje o věku do uspořádaných kategorií nebo věkových skupin. Ty by stále byly pořadové, ale nemusely by již být intervalové, pokud by přírůstky mezi možnými hodnotami nebyly ekvivalentní jednotky. Například pokud nás zajímá spíše věk reprezentující konkrétní období vývoje člověka, věkové intervaly nemusí mít stejné rozpětí mezi věkovými kritérii. Případně by mohly být:
- Kojenecký věk (od narození do 18 měsíců)
- Dětský věk (od 18 měsíců do 2,5 let)
- Předškolní věk (od 2,5 do 5 let)
- Školní věk (od 6 do 11 let)
- Dospělý věk (12 až 17 let)
- Nastupující dospělost (18 až 25 let)
- Dospělost (26 až 45 let)
- Střední dospělost (46 až 60 let)
- Mladá-Starší dospělost (60 až 74 let)
- Střední dospělost (75 až 84 let)
- Starší dospělost (85 a více let)
Věk by mohl být dokonce považován za přísně kategoriální (neordinální) proměnnou. Například pokud je proměnnou zájmu to, zda je někdo plnoletý (21 let nebo starší), nebo ne. Máme dvě kategorie – splňuje nebo nesplňuje kritéria legálního věku pro konzumaci alkoholu ve Spojených státech – a každá z nich by mohla být kódována jako „1“ a druhá jako „0“ nebo „2“ bez rozdílu významu.
Jaká je „správná“ odpověď na otázku, jak měřit věk (nebo příjem)? Odpověď zní „záleží na tom“. Záleží na povaze výzkumné otázky: jaká konceptualizace věku (nebo příjmu) je pro navrhovanou studii nejrelevantnější.
Alfanumerické proměnné. A konečně existují údaje, které nezapadají do žádné z těchto klasifikací. Někdy jsou nám známé informace ve formě adresy nebo telefonního čísla, jména nebo příjmení, poštovního směrovacího čísla nebo jiných výrazů. Tyto druhy informací se někdy nazývají alfanumerické proměnné. Vezměme si například proměnnou „adresa“: adresa osoby se může skládat z číselných znaků (číslo domu) a písmenných znaků (hláskování názvu ulice, města a státu), například 1600 Pennsylvania Ave. NW, Washington, DC, 20500.

V tomto příkladu adresy máme ve skutečnosti přítomno několik proměnných:
- adresa ulice: 1600 Pennsylvania Ave.
- město (a „stát“): Washington, DC
- poštovní směrovací číslo:
Tento typ informací nepředstavuje specifické kvantitativní kategorie nebo hodnoty se systematickým významem v datech. V některých softwarových balících se jim někdy říká také „řetězcové“ proměnné, protože jsou tvořeny řetězcem symbolů. Aby byla taková proměnná pro řešitele užitečná, musela by být převedena nebo překódována na smysluplné hodnoty.
Poznámka k jednotce analýzy
Důležitou věcí, kterou je třeba mít při uvažování o proměnných na paměti, je, že údaje mohou být shromažďovány na mnoha různých úrovních pozorování. Studovanými prvky mohou být jednotlivé buňky, orgánové systémy nebo osoby. Nebo mohou být úrovní pozorování dvojice jedinců, například páry, sourozenci nebo dvojice rodič-dítě. V tomto případě může zkoušející shromažďovat informace o dvojici od každého jednotlivce, ale zkoumá údaje každé dvojice. Řekli bychom tedy, že jednotkou analýzy je dvojice nebo dyáda, nikoliv každá jednotlivá osoba. Jednotkou analýzy může být i větší skupina: například údaje mohou být shromažďovány od každého ze studentů v celých třídách, kde jednotkou analýzy jsou třídy ve škole nebo školském systému. Nebo může být jednotkou analýzy úroveň sousedství, programů, organizací, krajů, států nebo dokonce národů. Například mnoho proměnných používaných jako ukazatele potravinové bezpečnosti na úrovni obcí, jako je cenová dostupnost a přístupnost, vychází z údajů získaných od jednotlivých domácností (Kaiser, 2017). Jednotkou analýzy ve studiích využívajících tyto ukazatele by byly srovnávané komunity. Toto rozlišení má důležité důsledky pro měření a analýzu údajů.
Připomenutí proměnných versus úrovní proměnných
Studii lze popsat z hlediska počtu kategorií proměnných nebo úrovní, které jsou porovnávány. Například se můžete setkat se studií popsanou jako design 2 X 2 – vyslovuje se jako design dva po dvou. To znamená, že existují 2 možné kategorie pro první proměnnou a 2 možné kategorie pro druhou proměnnou – obě jsou dichotomické proměnné. Studie porovnávající 2 kategorie proměnné „porucha způsobená užíváním alkoholu“ (kategorie pro splnění kritérií, ano nebo ne) se 2 kategoriemi proměnné „porucha způsobená užíváním nelegálních návykových látek“ (kategorie pro splnění kritérií, ano nebo ne) by měla 4 možné výsledky (matematicky 2 x 2 = 4) a mohla by mít následující schéma (údaje založené na proporcích z průzkumu NSDUH 2016, uvedené v SAMHSA, 2017):
| Porucha způsobená užíváním nelegálních látek (SUD) | |||
|---|---|---|---|
|
Porucha způsobená užíváním alkoholu (AUD) |
Ne | Ano | |
| Ne | 500 | 10 | |
| Ano | 26 | 4 | |
Přečtením 4 políček v této tabulce 2 X 2 zjistíme, že v tomto (hypotetickém) průzkumu 540 osob, 500 nesplňovalo kritéria ani pro poruchu způsobenou užíváním alkoholu, ani pro poruchu způsobenou užíváním nelegálních látek (Ne, Ne); 26 splňovalo kritéria pouze pro poruchu způsobenou užíváním alkoholu (Ano, Ne); 10 splňovalo kritéria pouze pro poruchu způsobenou užíváním nelegálních látek (Ne, Ano) a 4 splňovali kritéria pro poruchu způsobenou užíváním alkoholu i nelegálních látek (Ano, Ano). S trochou použité matematiky navíc zjistíme, že celkem 30 osob mělo poruchu způsobenou užíváním alkoholu (26 + 4) a 14 osob mělo poruchu způsobenou užíváním nelegálních látek (10 + 4). A dále vidíme, že 40 osob mělo nějaký druh poruchy způsobené užíváním návykových látek (26 + 10 + 4).
 Aby bylo toto rozlišení mezi proměnnými a úrovněmi nebo kategoriemi proměnných naprosto jasné, uvažujme ještě jeden příklad: design studie 2 X 3. Když nejprve provedeme matematické výpočty, měli bychom vidět 6 možných výsledků (buněk). Za druhé víme, že první proměnná (věková skupina) má 2 kategorie (do 30 let, 30 let a více) a druhá proměnná (stav zaměstnání) má 3 kategorie (plně zaměstnaný, částečně zaměstnaný, nezaměstnaný). Tentokrát je 6 buněk našeho návrhu prázdných, protože čekáme na data.
Aby bylo toto rozlišení mezi proměnnými a úrovněmi nebo kategoriemi proměnných naprosto jasné, uvažujme ještě jeden příklad: design studie 2 X 3. Když nejprve provedeme matematické výpočty, měli bychom vidět 6 možných výsledků (buněk). Za druhé víme, že první proměnná (věková skupina) má 2 kategorie (do 30 let, 30 let a více) a druhá proměnná (stav zaměstnání) má 3 kategorie (plně zaměstnaný, částečně zaměstnaný, nezaměstnaný). Tentokrát je 6 buněk našeho návrhu prázdných, protože čekáme na data.
| Stav zaměstnání | ||||
|---|---|---|---|---|
|
Věková skupina |
Plně zaměstnaný | Částečně zaměstnaný. Zaměstnaní | Nezaměstnaní | |
| <30 | ||||
| ≥30 | ||||
Takže, když vidíte popis návrhu studie, který vypadá jako násobení dvou čísel, v podstatě vám říká, kolik kategorií nebo úrovní každé proměnné existuje, a vede vás k pochopení, kolik buněk nebo možných výsledků existuje. Design 3 X 3 má 9 buněk, design 3 X 4 má 12 buněk atd. Tato otázka se stane důležitou ještě jednou, až budeme v kapitole 6 diskutovat o velikosti vzorku.
Dokončete následující aktivitu v pracovním sešitě:
- SWK 3401.3-4.1 Počáteční zadávání dat
Shrnutí kapitoly
Shrnem lze říci, že výzkumníci navrhují mnoho svých kvantitativních studií, aby ověřili hypotézy o vztazích mezi proměnnými. Pochopení povahy příslušných proměnných pomáhá při pochopení a vyhodnocení prováděného výzkumu. Pochopení rozdílů mezi různými typy proměnných a také mezi proměnnými a kategoriemi má důležité důsledky pro návrh studie, měření a vzorky. Následující kapitola se mimo jiné zabývá průnikem mezi povahou proměnných studovaných v kvantitativním výzkumu a způsobem, jakým se řešitelé pustili do měření těchto proměnných.
Věnujte chvíli vyplnění následující aktivity.
.