
- En hurtig gennemgang af de bedste artikler om billedklassifikation i et årti for at sætte gang i din læring af computer vision
- 1998: LeNet
- 2012: AlexNet
- 2014: VGG
- 2014: GoogLeNet
- 2015: Batch Normalization
- 2015: ResNet
- 2016: Xception
- 2017: MobileNet
- 2017: NASNet
- 2019: EfficientNet
- 2014: SPPNet
- 2016: DenseNet
- 2017: SENet
- 2017: ShuffleNet
- 2018: Bag of Tricks
- Slutning
En hurtig gennemgang af de bedste artikler om billedklassifikation i et årti for at sætte gang i din læring af computer vision

Computer vision er et fag til at konvertere billeder og videoer til maskin-forståelige signaler. Med disse signaler kan programmører yderligere styre maskinens adfærd på baggrund af denne forståelse på højt niveau. Blandt mange computer vision-opgaver er billedklassificering en af de mest grundlæggende opgaver. Den kan ikke blot bruges i masser af virkelige produkter som Google Photos tagging og AI-indholdsmoderation, men åbner også en dør for masser af mere avancerede vision-opgaver som f.eks. objektdetektion og video-forståelse. På grund af de hurtige ændringer på dette område siden gennembruddet af Deep Learning finder begyndere det ofte for overvældende at lære det. I modsætning til typiske softwaretekniske emner findes der ikke mange gode bøger om billedklassifikation ved hjælp af DCNN, og den bedste måde at forstå dette område på er ved at læse akademiske artikler. Men hvilke artikler skal man læse? Hvor skal jeg begynde? I denne artikel vil jeg introducere 10 bedste artikler for begyndere at læse. Med disse artikler kan vi se, hvordan dette felt udvikler sig, og hvordan forskerne kom med nye idéer baseret på tidligere forskningsresultater. Ikke desto mindre er det stadig nyttigt for dig at få styr på det store billede, selv om du allerede har arbejdet inden for dette område i et stykke tid. Så lad os komme i gang.
1998: LeNet
Gradient-based Learning Applied to Document Recognition

Indført i 1998, LeNet danner grundlaget for fremtidig forskning i billedklassificering ved hjælp af det konvolutionelle neurale netværk. Mange klassiske CNN-teknikker, som f.eks. pooling-lag, fuldt forbundne lag, polstring og aktiveringslag, anvendes til at udtrække funktioner og foretage en klassificering. Med en tabsfunktion for gennemsnitlige kvadratfejl og 20 træningsepocher kan dette netværk opnå en nøjagtighed på 99,05 % på MNIST-testsættet. Selv efter 20 år følger mange af de mest avancerede klassificeringsnetværk generelt stadig dette mønster.
2012: AlexNet
ImageNet Classification with Deep Convolutional Neural Networks

Og selv om LeNet opnåede et godt resultat og viste CNN’s potentiale, stagnerede udviklingen på dette område i et årti på grund af begrænset regnekraft og mængden af data. Det så ud til, at CNN kun kan løse nogle lette opgaver som f.eks. talgenkendelse, men for mere komplekse funktioner som ansigter og objekter var en HarrCascade- eller SIFT-funktionsekstraktor med en SVM-klassifikator en mere foretrukken tilgang.
Men i 2012 ImageNet Large Scale Visual Recognition Challenge foreslog Alex Krizhevsky en CNN-baseret løsning til denne udfordring og øgede drastisk ImageNet-testsættets top-5-nøjagtighed fra 73,8 % til 84,7 %. Deres tilgang arver CNN-idéen med flere lag fra LeNet, men øger CNN’s størrelse betydeligt. Som du kan se i diagrammet ovenfor, er input nu 224×224 sammenlignet med LeNets 32×32, og mange konvolutionskerner har 192 kanaler sammenlignet med LeNets 6. Selv om designet ikke er ændret meget, er netværkets evne til at indfange og repræsentere komplekse funktioner også forbedret hundredvis af gange med flere parametre, hvilket også er hundredvis af gange. For at træne så stor en model som denne brugte Alex to GTX 580 GPU’er med 3 GB RAM til hver, hvilket var banebrydende for en trend med GPU-træning. Også brugen af ReLU-ikke-linearitet bidrog også til at reducere beregningsomkostningerne.
Ud over at bringe mange flere parametre til netværket udforskede den også det overfittingproblem, som et større netværk medfører, ved at bruge et Dropout-lag. Dens Local Response Normalization-metode fik ikke alt for meget popularitet efterfølgende, men inspirerede andre vigtige normaliseringsteknikker såsom BatchNorm til at bekæmpe problemet med gradientmætning. Sammenfattende definerede AlexNet de facto rammen for klassifikationsnetværk i de næste 10 år: en kombination af konvolution, ReLu ikke-lineær aktivering, MaxPooling og Tæt lag.
2014: VGG
Very Deep Convolutional Networks for Large-Scale Image Recognition
Med en så stor succes med at bruge CNN til visuel genkendelse, blæste hele forskningsmiljøet op og alle begyndte at undersøge, hvorfor dette neurale netværk fungerer så godt. For eksempel diskuterede Matthew Zeiler i “Visualizing and Understanding Convolutional Networks” fra 2013, hvordan CNN opsamler funktioner og visualiserede de mellemliggende repræsentationer. Og pludselig begyndte alle at indse, at CNN er fremtiden inden for computervision siden 2014. Blandt alle disse umiddelbare efterfølgere er VGG-netværket fra Visual Geometry Group det mest iøjnefaldende. Det fik et bemærkelsesværdigt resultat på 93,2 % top-5 nøjagtighed og 76,3 % top-1 nøjagtighed på ImageNet-testsættet.
I forlængelse af AlexNet’s design har VGG-netværket to store opdateringer: 1) VGG har ikke kun brugt et bredere netværk som AlexNet, men også dybere. VGG-19 har 19 konvolutionslag, sammenlignet med 5 fra AlexNet. 2) VGG viste også, at nogle få små 3×3 konvolutionsfiltre kan erstatte et enkelt 7×7- eller endog 11×11-filter fra AlexNet og opnå bedre ydeevne samtidig med, at beregningsomkostningerne reduceres. På grund af dette elegante design blev VGG også back-bone-netværket for mange banebrydende netværk inden for andre computer vision-opgaver, såsom FCN til semantisk segmentering og Faster R-CNN til objektdetektion.
Med et dybere netværk bliver gradienten forsvindende fra flerlags back-propagation et større problem. For at håndtere det diskuterede VGG også betydningen af præ-træning og vægtinitialisering. Dette problem begrænser forskerne til at blive ved med at tilføje flere lag, da netværket ellers vil være meget svært at konvergere. Men vi vil se en bedre løsning på dette efter to år.
2014: GoogLeNet
Going Deeper with Convolutions

VGG har en flot og letforståelig struktur, men dens ydeevne er ikke den bedste blandt alle finalisterne i ImageNet 2014-konkurrencerne. GoogLeNet, alias InceptionV1, vandt den endelige pris. Ligesom VGG er et af GoogLeNets vigtigste bidrag at skubbe grænsen for netværksdybden med en struktur med 22 lag. Dette viste igen, at det faktisk er den rigtige retning at gå dybere og bredere for at forbedre nøjagtigheden.
I modsætning til VGG forsøgte GoogLeNet at løse problemerne med beregning og gradientdæmpning direkte, i stedet for at foreslå en løsning med bedre forudtrænede skemaer og initialisering af vægte.

Først udforskede den ideen om asymmetrisk netværksdesign ved hjælp af et modul kaldet Inception (se diagrammet ovenfor). Ideelt set ville de gerne forfølge sparsom konvolution eller tætte lag for at forbedre funktionseffektiviteten, men moderne hardwaredesign var ikke skræddersyet til dette tilfælde. Så de mente, at en sparsomhed på netværkstopologiniveau også kunne hjælpe fusionen af funktioner, samtidig med at de udnytter de eksisterende hardwarekapaciteter.
For det andet angriber de problemet med de høje beregningsomkostninger ved at låne en idé fra et dokument kaldet “Network in Network”. Grundlæggende indføres et 1×1-foldningsfilter for at reducere dimensionerne af funktioner, før de gennemgår tunge beregningsoperationer som f.eks. en 5×5-foldningskerne. Denne struktur kaldes senere “Bottleneck” og anvendes i vid udstrækning i mange følgende netværk. I lighed med “Network in Network” blev der også anvendt et gennemsnitligt pooling-lag til at erstatte det sidste fuldt forbundne lag for at reducere omkostningerne yderligere.
For det tredje anvendte GoogLeNet også overvågning på nogle mellemliggende lagudgange eller hjælpeudgange for at hjælpe gradienterne til at strømme til dybere lag. Dette design er ikke helt populært senere i billedklassifikationsnetværket på grund af kompleksiteten, men bliver mere populært inden for andre områder af computer vision såsom Hourglass-netværk i poseskøn.
Som opfølgning skrev dette Google-team flere papirer til denne Inception-serie. “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift” står for InceptionV2. “Rethinking the Inception Architecture for Computer Vision” i 2015 står for InceptionV3. Og “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning” (Inception-v4, Inception-ResNet og virkningen af resterende forbindelser på læring) i 2015 står for InceptionV4. Hver artikel tilføjede flere forbedringer i forhold til det oprindelige Inception-netværk og opnåede et bedre resultat.
2015: Batch Normalization
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Inception-netværket hjalp forskerne til at nå en overmenneskelig nøjagtighed på ImageNet-datasættet. Som en statistisk læringsmetode er CNN imidlertid meget begrænset til den statistiske karakter af et specifikt træningsdatasæt. For at opnå en bedre nøjagtighed skal vi derfor normalt forudberegne middelværdien og standardafvigelsen for hele datasættet og bruge dem til at normalisere vores input først for at sikre, at de fleste laginput i netværket ligger tæt på hinanden, hvilket giver en bedre aktiveringsreaktivitet. Denne tilnærmelsesvise tilgang er meget besværlig, og nogle gange fungerer den slet ikke for en ny netværksstruktur eller et nyt datasæt, så deep learning-modellen betragtes stadig som vanskelig at træne. For at løse dette problem besluttede Sergey Ioffe og Chritian Szegedy, ham der skabte GoogLeNet, at opfinde noget smartere kaldet Batch Normalization.

Ideen om batch-normalisering er ikke svær: Vi kan bruge statistikkerne for en række mini-batches til at tilnærme os statistikkerne for hele datasættet, så længe vi træner i tilstrækkelig lang tid. I stedet for manuelt at beregne statistikkerne kan vi også indføre to yderligere lærbare parametre “scale” og “shift” for at få netværket til selv at lære, hvordan det skal normalisere hvert lag.
Overstående diagram viste processen for beregning af batch-normaliseringsværdier. Som vi kan se, tager vi gennemsnittet af hele minibatchen og beregner også variansen. Dernæst kan vi normalisere input med dette mini-batch middelværdi og varians. Endelig vil netværket med en skala- og en forskydningsparameter lære at tilpasse det batch-normaliserede resultat til at passe bedst muligt til de følgende lag, normalt ReLU. Et forbehold er, at vi ikke har mini-batch-informationer under inferencen, så en løsning er at beregne et glidende gennemsnit af middelværdi og varians under træningen og derefter bruge disse glidende gennemsnit i inferencestien. Denne lille nyskabelse har så stor betydning, og alle senere netværk begynder at bruge den med det samme.
2015: ResNet
Deep Residual Learning for Image Recognition
2015 er måske det bedste år for computer vision i et årti, vi har set så mange gode ideer poppe op, ikke kun inden for billedklassifikation, men alle mulige computer vision-opgaver som f.eks. objektdetektion, semantisk segmentering osv. Det største fremskridt i 2015 er et nyt netværk kaldet ResNet, eller residual networks, der blev foreslået af en gruppe kinesiske forskere fra Microsoft Research Asia.

Som vi diskuterede tidligere for VGG-netværk, er den største hurdle for at blive endnu dybere gradient forsvindende problem, i.Dvs. at afledningerne bliver mindre og mindre, når der back-propageres gennem dybere lag, og til sidst når et punkt, som moderne computerarkitektur ikke rigtig kan repræsentere meningsfuldt. GoogLeNet forsøgte at angribe dette ved at anvende ekstra overvågning og et asymmetrisk indgangsmodul, men det afhjælper kun problemet i ringe grad. Hvis vi ønsker at bruge 50 eller endog 100 lag, vil der så være en bedre måde, hvorpå gradienten kan strømme gennem netværket? Svaret fra ResNet er at bruge et residualmodul.

ResNet tilføjede en identitetsforkortelse til output, så hvert residual modul i det mindste kan forudsige, hvad input er, uden at fare vild i vildmarken. En endnu vigtigere ting er, at i stedet for at håbe på, at hvert lag passer direkte til den ønskede funktionstilknytning, forsøger restmodulet at lære forskellen mellem output og input, hvilket gør opgaven meget lettere, fordi den nødvendige informationsforøgelse er mindre. Forestil dig, at du lærer matematik, og for hvert nyt problem får du en løsning på et lignende problem, så det eneste, du skal gøre, er at udvide denne løsning og forsøge at få den til at fungere. Det er meget nemmere end at finde på en helt ny løsning for hvert problem, du støder på. Eller som Newton sagde, vi kan stå på skuldrene af giganter, og identitetsinput er denne gigant for residualmodulet.
Ud over identitetsafbildning har ResNet også lånt flaskehalsen og Batch Normalization fra Inception-netværk. I sidste ende lykkedes det at opbygge et netværk med 152 konvolutionslag og opnåede 80,72 % top-1 nøjagtighed på ImageNet. Reset-tilgangen bliver også en standardindstilling for mange andre netværk senere, såsom Xception, Darknet osv. Takket være det enkle og smukke design er det også stadig meget udbredt i mange visuelle genkendelsessystemer i produktion i dag.
Der er mange flere invarianter kommet frem ved at følge hypen om det residuelle netværk. I “Identity Mappings in Deep Residual Networks” forsøgte den oprindelige forfatter af ResNet at sætte aktivering før residualmodulet og opnåede et bedre resultat, og dette design kaldes ResNetV2 bagefter. I en artikel fra 2016 “Aggregated Residual Transformations for Deep Neural Networks” foreslog forskerne også ResNeXt, som tilføjede parallelle grene til residualmoduler for at aggregere output fra forskellige transformationer.
2016: Xception
Xception: Dybdeindlæring med dybdeadskillelige konvolutioner

Med udgivelsen af ResNet så det ud til, at de fleste af de lavt hængende frugter inden for billedklassificering allerede var blevet taget. Forskere begyndte at tænke over, hvad der er den interne mekanisme i CNN’s magi. Da tværgående konvolution normalt introducerer et ton af parametre, valgte Xception-netværket at undersøge denne operation for at forstå et fuldstændigt billede af dens virkning.
Som navnet antyder, stammer Xception fra Inception-netværket. I Inception-modulet aggregeres flere grene af forskellige transformationer sammen for at opnå en topologisk sparsomhed. Men hvorfor virkede denne sparsomhed? Forfatteren af Xception, som også er forfatteren af Keras-rammen, udvidede denne idé til et ekstremt tilfælde, hvor en 3×3-foldningsfil svarer til én udgangskanal før en endelig sammenkædning. I dette tilfælde danner disse parallelle konvolutionskerner faktisk en ny operation kaldet dybdevis konvolution.

Som vist i diagrammet ovenfor, I modsætning til traditionel konvolution, hvor alle kanaler indgår i én beregning, beregner dybdevis konvolution kun konvolution for hver kanal separat og sammenkæder derefter output sammen. Dette skærer ned på udvekslingen af funktioner mellem kanalerne, men reducerer også en masse forbindelser og resulterer derfor i et lag med færre parametre. Denne operation vil dog give det samme antal kanaler som input (eller et mindre antal kanaler, hvis du grupperer to eller flere kanaler sammen). Når kanaludgangene er slået sammen, har vi derfor brug for endnu et almindeligt 1×1-filter eller punktvis konvolution for at øge eller reducere antallet af kanaler, ligesom almindelig konvolution gør.
Denne idé er ikke oprindeligt fra Xception. Den er beskrevet i et papir kaldet “Learning visual representations at scale” og bruges også lejlighedsvis i InceptionV2. Xception tog et skridt videre og erstattede næsten alle convolutioner med denne nye type. Og resultatet af eksperimentet viste sig at være ret godt. Den overgår ResNet og InceptionV3 og blev en ny SOTA-metode til billedklassificering. Dette beviste også, at kortlægningen af korrelationer på tværs af kanalerne og rumlige korrelationer i CNN kan afkobles fuldstændigt. Derudover deler Xception den samme dyd med ResNet og har også et enkelt og smukt design, så dens idé bruges i mange andre efterfølgende undersøgelser såsom MobileNet, DeepLabV3 osv.
2017: MobileNet
MobileNets: Effektive Convolutional Neural Networks for Mobile Vision Application
Xception opnåede 79% top-1 nøjagtighed og 94,5% top-5 nøjagtighed på ImageNet, men det er kun 0,8% og 0,4% forbedring henholdsvis sammenlignet med tidligere SOTA InceptionV3. Den marginale gevinst ved et nyt billedklassifikationsnetværk bliver mindre og mindre, så forskerne begynder at flytte deres fokus til andre områder. Og MobileNet førte til et betydeligt skub i retning af billedklassificering i et ressourcebegrænset miljø.

I lighed med Xception anvendte MobileNet et samme dybdeadskillelige convolutionsmodul som vist ovenfor og havde fokus på høj effektivitet og færre parametre.
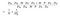
Tælleren i ovenstående formel er det samlede antal parametre, der kræves af en dybdeadskillelig konvolution. Og nævneren er det samlede antal parametre for en tilsvarende almindelig konvolution. Her er D størrelsen af konvolutionskernen, D er størrelsen af funktionskortet, M er antallet af indgangskanaler, N er antallet af udgangskanaler. Da vi har adskilt beregningen af kanal- og rumlige funktioner, kan vi omdanne multiplikationen til en addition, som er en del mindre. Endnu bedre, som vi kan se af dette forhold, er det, at jo større antallet af udgangskanaler er, jo mere beregning sparede vi ved at bruge denne nye konvolution.
Et andet bidrag fra MobileNet er bredde- og opløsningsmultiplikatoren. MobileNet-holdet ønskede at finde en kanonisk måde at skrumpe modelstørrelsen til mobile enheder på, og den mest intuitive måde er at reducere antallet af input- og outputkanaler samt inputbilledopløsningen. For at styre denne adfærd multipliceres et forhold alpha med kanalerne, og et forhold rho multipliceres med inputopløsningen (som også påvirker feature map-størrelsen). Så det samlede antal parametre kan repræsenteres i følgende formel:
Og selv om denne ændring virker naiv med hensyn til innovation, har den stor teknisk værdi, fordi det er første gang, at forskere konkluderer en kanonisk tilgang til at tilpasse netværket til forskellige ressourcebegrænsninger. Desuden opsummerede det på en måde den ultimative løsning til forbedring af neurale netværk: bredere og højopløst input fører til bedre nøjagtighed, tyndere og lavopløst input fører til dårligere nøjagtighed.
Sidst i 2018 og 2019 udgav MobiletNet-holdet også “MobileNetV2: Inverted Residuals and Linear Bottlenecks” og “Searching for MobileNetV3”. I MobileNetV2 anvendes en inverteret residual flaskehalsstruktur. Og i MobileNetV3 er man begyndt at søge efter den optimale arkitekturkombination ved hjælp af Neural Architecture Search-teknologi, som vi vil dække næste gang.
2017: NASNet
Learning Transferable Architectures for Scalable Image Recognition
Nøjagtig som billedklassificering til et ressourcebegrænset miljø er neuronal arkitektursøgning et andet område, der dukkede op omkring 2017. Med ResNet, Inception og Xception ser det ud til, at vi har nået en optimal netværkstopologi, som mennesker kan forstå og designe, men hvad nu hvis der findes en bedre og meget mere kompleks kombination, der langt overgår den menneskelige fantasi? En artikel fra 2016 kaldet “Neural Architecture Search with Reinforcement Learning” foreslog en idé om at søge den optimale kombination inden for et foruddefineret søgerum ved hjælp af forstærkningslæring. Som vi ved, er forstærkende læring en metode til at finde den bedste løsning med et klart mål og en belønning for søgeagenten. Da denne artikel imidlertid er begrænset af computerkraft, drøftede den kun anvendelsen i et lille CIFAR-datasæt.

Med det formål at finde en optimal struktur til et stort datasæt som ImageNet har NASNet lavet et søgerum, der er skræddersyet til ImageNet. Det håber at kunne designe et særligt søgerum, således at det søgte resultat på CIFAR også kan fungere godt på ImageNet. For det første antager NASNet, at almindelige håndlavede moduler i gode netværk som ResNet og Xception stadig er nyttige, når der søges. Så i stedet for at søge efter tilfældige forbindelser og operationer søger NASNet efter kombinationen af disse moduler, som allerede har vist sig at være nyttige på ImageNet. For det andet udføres den faktiske søgning stadig på CIFAR-datasættet med en opløsning på 32×32, så NASNet søger kun efter moduler, der ikke påvirkes af inputstørrelsen. For at få det andet punkt til at fungere, har NASNet på forhånd defineret to typer modulskabeloner: Reduktion og Normal. Reduktionscellen kan have et reduceret funktionskort i forhold til input, og for Normalcellen vil det være det samme.

Og selv om NASNet har bedre metrikker end manuelt designede netværk, lider det også af et par ulemper. Omkostningerne ved at søge efter en optimal struktur er meget høje, hvilket kun er overkommeligt for store virksomheder som Google og Facebook. Desuden giver den endelige struktur ikke alt for meget mening for mennesker, og derfor er den sværere at vedligeholde og forbedre i et produktionsmiljø. Senere i 2018 blev “MnasNet: Platform-Aware Neural Architecture Search for Mobile” udvider denne NASNet-idé yderligere ved at begrænse søgetrinnet med en foruddefineret kæde-blokke-struktur. Ved at definere en vægtfaktor gav mNASNet også en mere systematisk måde at søge modellen på i betragtning af specifikke ressourcebegrænsninger, i stedet for blot at evaluere baseret på FLOPs.
2019: EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
I 2019 ser det ud til, at der ikke længere er nogen spændende idéer til overvåget billedklassifikation med CNN. En drastisk ændring i netværksstrukturen giver normalt kun en lille forbedring af nøjagtigheden. Endnu værre er det, at når det samme netværk anvendes på forskellige datasæt og opgaver, synes tidligere påståede tricks ikke at virke, hvilket har ført til kritik af, om disse forbedringer blot er overfitting på ImageNet-datasættet. På den anden side er der ét trick, som aldrig svigter vores forventninger: anvendelse af input i højere opløsning, tilføjelse af flere kanaler til konvolutionslagene og tilføjelse af flere lag. Selv om det er en meget brutal kraft, ser det ud til, at der er en principiel måde at skalere netværket på efterspørgsel. MobileNetV1 foreslog på en måde dette i 2017, men fokus blev senere flyttet til et bedre netværksdesign.

Efter NASNet og mNASNet indså forskerne, at selv med hjælp fra en computer giver en ændring i arkitekturen ikke så mange fordele. Så de begynder at falde tilbage på skalering af netværket. EfficientNet er blot bygget oven på denne antagelse. På den ene side bruger det den optimale byggesten fra mNASNet for at sikre et godt fundament til at starte med. På den anden side definerede det tre parametre alpha, beta og rho til at styre dybden, bredden og opløsningen af netværket tilsvarende. På den måde kan ingeniører, selv uden en stor GPU-pool til at søge efter en optimal struktur, stadig stole på disse principielle parametre til at afstemme netværket ud fra deres forskellige krav. I sidste ende gav EfficientNet 8 forskellige varianter med forskellige bredde-, dybde- og opløsningsforhold og fik en god ydeevne for både små og store modeller. Med andre ord, hvis du ønsker høj nøjagtighed, skal du gå efter et EfficientNet-B7 med 600×600 og 66M parametre. Hvis du ønsker lav latenstid og en mindre model, skal du vælge et EfficientNet-B0 med 224×224 og 5,3M parametre. Problemet er løst.
Hvis du er færdig med at læse ovenstående 10 artikler, bør du have en ret god forståelse af historien om billedklassifikation med CNN. Hvis du kan lide at fortsætte med at lære dette område, har jeg også listet nogle andre interessante papirer at læse. Selv om de ikke er med på top-10-listen, er disse papirer alle berømte inden for deres eget område og har inspireret mange andre forskere i verden.
2014: SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPPNet låner idéen om funktionspyramide fra traditionel computer vision feature extraction. Denne pyramide danner en pose med ord af funktioner med forskellige skalaer, så den kan tilpasse sig til forskellige inputstørrelser og slippe for det fuldt forbundne lag med fast størrelse. Denne idé har også yderligere inspireret ASPP-modulet i DeepLab og også FPN til objektdetektion.
2016: DenseNet
Densely Connected Convolutional Networks
DenseNet fra Cornell udvider ideen fra ResNet yderligere. Det giver ikke kun springforbindelser mellem lagene, men har også springforbindelser fra alle tidligere lag.
2017: SENet
Squeeze-and-Excitation Networks
Xception-netværket viste, at korrelation på tværs af kanalerne ikke har meget med rumlig korrelation at gøre. Men SENet, som var mesteren i den sidste ImageNet-konkurrence, udtænkte en Squeeze-and-Excitation-blok og fortalte en anden historie. SE-blokken klemmer først alle kanalerne sammen til færre kanaler ved hjælp af global pooling, anvender en fuldt forbundet transformation og “exciterer” dem derefter tilbage til det oprindelige antal kanaler ved hjælp af et andet fuldt forbundet lag. Så i det væsentlige hjalp FC-laget netværket med at lære opmærksomheder på inputfunktionskortet.
2017: ShuffleNet
ShuffleNet: Et ekstremt effektivt konvolutionelt neuralt netværk til mobile enheder
ShuffleNet er bygget oven på MobileNetV2’s omvendte flaskehalsmodul og mener, at punktvis konvolution i dybdevis separerbar konvolution ofrer nøjagtigheden i bytte for mindre beregning. For at kompensere for dette har ShuffleNet tilføjet en ekstra kanalomblandingsoperation for at sikre, at punktvis konvolution ikke altid vil blive anvendt på det samme “punkt”. Og i ShuffleNetV2 er denne kanalomblandingsmekanisme yderligere udvidet til også at omfatte en ResNet-identitetskortlægningsgren, således at en del af identitetsfunktionen også vil blive brugt til omblanding.
2018: Bag of Tricks
Bag of Tricks for Image Classification with Convolutional Neural Networks
Bag of Tricks fokuserer på almindelige tricks, der anvendes inden for billedklassificering. Den tjener som en god reference for ingeniører, når de har brug for at forbedre benchmarkpræstationer. Interessant nok kan disse tricks såsom mixup-augmentering og cosinusindlæringshastighed nogle gange opnå langt bedre forbedringer end en ny netværksarkitektur.
Slutning
Med udgivelsen af EfficientNet ser det ud til, at ImageNet-klassifikationsbenchmark kommer til en ende. Med den eksisterende deep learning-tilgang vil der aldrig komme en dag, hvor vi kan nå 99,999 % nøjagtighed på ImageNet, medmindre der sker et andet paradigmeskift. Derfor undersøger forskerne aktivt nogle nye områder som f.eks. selvovervåget eller semiovervåget læring til visuel genkendelse i stor skala. I mellemtiden er det med de eksisterende metoder blevet mere et spørgsmål for ingeniører og iværksættere at finde den virkelige anvendelse af denne uperfekte teknologi i den virkelige verden. I fremtiden vil jeg også skrive en undersøgelse for at analysere disse virkelige computer vision-applikationer drevet af billedklassifikation, så bliv venligst opdateret! Hvis du mener, at der også er andre vigtige artikler om billedklassifikation, så skriv en kommentar nedenfor og fortæl os det.
Originalt offentliggjort på http://yanjia.li den 31. juli 2020
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based Learning Applied to Document Recognition
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
- Sergey Ioffe, Christian Szegedy, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition
- François Chollet, Xception: Deep Learning with Depthwise Separable Convolutions
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Effektive Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
- Mingxing Tan, Quoc V. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Connected Convolutional Networks
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Bag of Tricks for Image Classification with Convolutional Neural Networks