
Resourceallokering er et vigtigt aspekt under udførelsen af ethvert Spark-job. Hvis det ikke er konfigureret korrekt, kan et spark job forbruge hele klyngeressourcer og få andre applikationer til at sulte efter ressourcer.
Denne blog hjælper med at forstå det grundlæggende flow i en Spark-applikation og derefter hvordan man konfigurerer antallet af eksekutorer, hukommelsesindstillinger for hver eksekutor og antallet af kerner til et Spark Job. Der er et par faktorer, som vi skal overveje for at beslutte de optimale tal for de ovennævnte tre, som f.eks:
- Mængden af data
- Den tid, som et job skal være færdig
- Statisk eller dynamisk allokering af ressourcer
- Opstrøms eller nedstrøms applikation
- Indledning
- Strækninger, der er involveret i klyngemode for et Spark Job
- Statisk allokering
- Fælde 1 Hardware – 6 knudepunkter og hver knudepunkt har 16 kerner, 64 GB RAM
- Case 2 Hardware – 6 knudepunkter og hver knude har 32 kerner, 64 GB
- Fælde 3 – Når der ikke kræves mere hukommelse til eksekutorer
- Summarisk tabel
- Dynamisk allokering
Indledning
Lad os starte med nogle grundlæggende definitioner af de termer, der bruges i håndteringen af Spark-applikationer.
Partitioner : En partition er en lille klump af et stort distribueret datasæt. Spark håndterer data ved hjælp af partitioner, der hjælper med at parallelisere databehandlingen med minimal datamix på tværs af eksekutorerne.
Task : En opgave er en arbejdsenhed, der kan køres på en partition af et distribueret datasæt og bliver udført på en enkelt eksekutor. Enheden for parallel udførelse er på opgaveniveau.Alle opgaver inden for en enkelt fase kan udføres parallelt
Executor : En executor er en enkelt JVM-proces, der startes for et program på en arbejderknude. Executor kører opgaver og opbevarer data i hukommelsen eller på disklager på tværs af dem. Hver applikation har sine egne eksekutorer. En enkelt knude kan køre flere eksekutorer, og eksekutorer for et program kan strække sig over flere arbejdsknudepunkter. En eksekutor forbliver oppe i Spark-applikationens
varighed og kører opgaverne i flere tråde. Antallet af eksekutorer for en Spark-applikation kan angives inde i SparkConf eller via flaget -num-executors fra kommandolinjen.
Cluster Manager : En ekstern tjeneste til erhvervelse af ressourcer på klyngen (f.eks. standalone manager, Mesos, YARN). Spark er agnostisk over for en cluster manager, så længe den kan erhverve eksekutorprocesser, og disse kan kommunikere med hinanden. vi er primært interesseret i Yarn som cluster manager. En spark cluster kan køre i enten yarn cluster eller yarn-client mode:
yarn-client mode – En driver kører på klientprocessen, Application Master bruges kun til at anmode om ressourcer fra YARN.
yarn-cluster mode – En driver kører inde i application master processen, klienten forsvinder når applikationen er initialiseret
Cores : En kerne er en grundlæggende beregningsenhed i CPU’en, og en CPU kan have en eller flere kerner til at udføre opgaver på et givet tidspunkt. Jo flere kerner vi har, jo mere arbejde kan vi udføre. I Spark styrer dette antallet af parallelle opgaver, som en eksekutor kan køre.
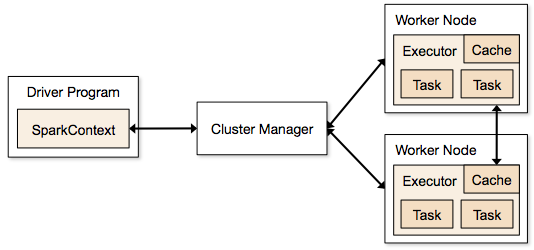
Strækninger, der er involveret i klyngemode for et Spark Job
- Fra driverkoden opretter SparkContext forbindelse til cluster manager (standalone/Mesos/YARN).
- Cluster Manager tildeler ressourcer på tværs af de andre applikationer. Enhver cluster manager kan bruges, så længe eksekutorprocesserne kører, og de kommunikerer med hinanden.
- Spark erhverver eksekutorer på noder i klyngen. Her får hver applikation sine egne eksekutorprocesser.
- Applikationskoden (jar/python-filer/python-æg-filer) sendes til eksekutorer
- Opgaver sendes af SparkContext til eksekutorerne.
Fra ovenstående trin er det klart, at antallet af eksekutorer og deres hukommelsesindstilling spiller en stor rolle i et sparkjob. Kørsel af eksekutorer med for meget hukommelse resulterer ofte i overdrevne garbage collection forsinkelser
Nu forsøger vi at forstå, hvordan vi konfigurerer det bedste sæt værdier for at optimere et spark job.
Der er to måder, hvorpå vi konfigurerer eksekutor- og kernedetaljer til Spark jobbet. De er:
- Statisk allokering – Værdierne er givet som en del af spark-submit
- Dynamisk allokering – Værdierne hentes baseret på kravet (datastørrelse, mængden af beregninger, der er nødvendige) og frigives efter brug. Dette hjælper ressourcerne med at blive genbrugt til andre applikationer.
Statisk allokering
Differente tilfælde diskuteres ved at variere forskellige parametre og nå frem til forskellige kombinationer som følge af brugerens/dataens krav.
Fælde 1 Hardware – 6 knudepunkter og hver knudepunkt har 16 kerner, 64 GB RAM
Først på hver knudepunkt er der brug for 1 kerne og 1 GB til operativsystemet og Hadoop-dæmoner, så vi har 15 kerner, 63 GB RAM til hver knudepunkt
Vi starter med at vælge antallet af kerner:
Antal kerner = samtidige opgaver, som en eksekutor kan køre
Så vi kan tænke, at flere samtidige opgaver for hver eksekutor vil give bedre ydeevne. Men forskning viser, at enhver applikation med mere end 5 samtidige opgaver vil føre til et dårligt resultat. Så den optimale værdi er 5.
Dette tal kommer fra en eksekutors evne til at køre parallelle opgaver og ikke fra hvor mange kerner et system har. Så tallet 5 forbliver det samme, selv om vi har dobbelt så mange (32) kerner i CPU’en
Antal eksekutorer:
Med 5 som kerner pr. eksekutor og 15 som de samlede tilgængelige kerner i en knude (CPU) – kommer vi til 3 eksekutorer pr. knude, hvilket er 15/5. Vi skal beregne antallet af eksekutorer på hver knude og derefter få det samlede antal for jobbet.
Så med 6 knudepunkter og 3 eksekutorer pr. knude – får vi et samlet antal på 18 eksekutorer. Ud af de 18 har vi brug for 1 eksekutor (java-proces) til Application Master i YARN. Så det endelige antal er 17 eksekutorer
Dette 17 er det antal, vi giver til spark ved hjælp af -num-executors, mens vi kører fra shell-kommandoen spark-submit
Hukommelse for hver eksekutor:
Fra ovenstående trin har vi 3 eksekutorer pr. knude. Og tilgængelig RAM på hver knude er 63 GB
Så hukommelse for hver eksekutor i hver knude er 63/3 = 21 GB.
Der er dog også brug for lille overheadhukommelse for at bestemme den fulde hukommelsesanmodning til YARN for hver eksekutor.
Formlen for dette overhead er max(384, .07 * spark.executor.memory)
Beregning af dette overhead: .07 * 21 (Her er 21 beregnet som ovenfor 63/3) = 1,47
Da 1,47 GB > 384 MB, er overheadet 1.47
Tag ovenstående fra hver 21 ovenfor => 21 – 1,47 ~ 19 GB
Så eksekutorhukommelse – 19 GB
Sluttelige tal – eksekutorer – 17, kerner 5, eksekutorhukommelse – 19 GB
Case 2 Hardware – 6 knudepunkter og hver knude har 32 kerner, 64 GB
Antal af kerner på 5 er det samme for god samtidighed som forklaret ovenfor.
Antal eksekutorer for hver knude = 32/5 ~ 6
Så total eksekutorer = 6 * 6 knudepunkter = 36. Så er det endelige antal 36 – 1(for AM) = 35
Hukommelse for eksekutorer:
6 eksekutorer for hver knude. 63/6 ~ 10. Overhead er 0,07 * 10 = 700 MB. Så ved at afrunde til 1 GB som overhead får vi 10-1 = 9 GB
Sluttelige tal – eksekutorer – 35, kerner 5, eksekutorhukommelse – 9 GB
Fælde 3 – Når der ikke kræves mere hukommelse til eksekutorer
De ovenstående scenarier starter med at acceptere antallet af kerner som fast og går over til antallet af eksekutorer og hukommelse.
Nu for det første tilfælde, hvis vi mener, at vi ikke har brug for 19 GB, og at blot 10 GB er tilstrækkeligt baseret på datastørrelsen og de involverede beregninger, så er følgende tal:
Kerner: 5
Antal eksekutorer for hver knude = 3. Stadig 15/5 som beregnet ovenfor.
På dette tidspunkt ville dette føre til 21 GB, og derefter 19 som i vores første beregning. Men da vi mente, at 10 er ok (antager lidt overhead), kan vi ikke ændre antallet af eksekutorer pr. knude til 6 (som 63/10). For med 6 eksekutorer pr. node og 5 kerner kommer det ned på 30 kerner pr. node, når vi kun har 16 kerner. Så vi er også nødt til at ændre antallet af kerner for hver eksekutor.
Så beregner vi igen,
Det magiske tal 5 kommer til 3 (ethvert tal mindre end eller lig med 5). Så med 3 kerner og 15 tilgængelige kerner – får vi 5 eksekutorer pr. knude, 29 eksekutorer ( hvilket er (5*6 -1))) og hukommelsen er 63/5 ~ 12.
Overhead er 12*.07=.84. Så eksekutorhukommelse er 12 – 1 GB = 11 GB
De endelige tal er 29 eksekutorer, 3 kerner, eksekutorhukommelse er 11 GB
Summarisk tabel
Dynamisk allokering
Note: Øvre grænse for antallet af eksekutorer, hvis dynamisk allokering er aktiveret, er uendelig. Dette siger altså, at gnistprogrammet kan æde alle ressourcerne op, hvis det er nødvendigt. I en klynge, hvor vi har andre applikationer kørende, og de har også brug for kerner til at udføre opgaverne, skal vi sikre os, at vi tildeler kernerne på klyngeniveau.
Det betyder, at vi kan tildele et bestemt antal kerner til YARN-baserede applikationer baseret på brugeradgang. Så vi kan oprette en spark_user og derefter give kerner (min/max) til denne bruger. Disse grænser er til deling mellem spark og andre programmer, der kører på YARN.
For at forstå dynamisk allokering skal vi have kendskab til følgende egenskaber:
spark.dynamicAllocation.enabled – når dette er sat til true, behøver vi ikke at nævne eksekutorer. Årsagen er nedenfor:
De statiske parameternumre, vi angiver ved spark-submit, gælder for hele jobbets varighed. Men hvis dynamisk allokering kommer ind i billedet, ville der være forskellige faser som følgende:
Hvad er antallet af eksekutorer til at starte med:
Initialt antal eksekutorer (spark.dynamicAllocation.initialExecutors) til at starte med
Styring af antallet af eksekutorer dynamisk:
Dernæst baseret på belastning (opgaver i vente), hvor mange eksekutorer der skal anmodes om. Dette ville i sidste ende være det antal, som vi giver på spark-submit på statisk måde. Så når det oprindelige antal eksekutorer er indstillet, går vi til min (spark.dynamicAllocation.minExecutors) og max (spark.dynamicAllocation.maxExecutors) antal.
Hvornår skal vi bede om nye eksekutorer eller give nuværende eksekutorer væk:
Hvornår anmoder vi om nye eksekutorer (spark.dynamicAllocation.schedulerBacklogTimeout) – Dette betyder, at der har været ventende opgaver i så lang tid. Så anmodningen om antallet af eksekutorer, der anmodes om i hver runde, stiger eksponentielt i forhold til den foregående runde. Et program vil f.eks. tilføje 1 eksekutor i den første runde og derefter 2, 4, 8 osv. eksekutorer i de efterfølgende runder. På et bestemt tidspunkt kommer ovenstående egenskab max ind i billedet.
Hvornår giver vi en eksekutor væk er indstillet ved hjælp af spark.dynamicAllocation.executorIdleTimeout.
For at konkludere, hvis vi har brug for mere kontrol over jobudførelsestiden, skal vi overvåge jobbet for uventet datamængde de statiske tal ville hjælpe. Ved at gå over til dynamisk ville ressourcerne blive brugt i baggrunden, og de job, der involverer uventede mængder, kan påvirke andre programmer.