
Face to face er den måde, vi oftest genkender og kommunikerer med hinanden på. Genkendelse af individuelle ansigter er kun mulig, fordi det menneskelige ansigt er så enormt variabelt. Den ekstreme lighed i ansigtet hos enæggede tvillinger, som arver de samme versioner af hvert gen fra hver af deres forældre og dermed har identiske genotyper, viser, at de forskellige ansigtstræk, som vi kan genkende mennesker på, er arvelige. Det betyder, at de for det meste er bestemt af de særlige kombinationer af genetiske varianter, der er nedarvet fra deres forældre. Ved genetisk variant forstås en version af et bestemt gen, som adskiller sig fra andre versioner af det samme gen på en given position i DNA’et. Det forhold, at ansigtstræk hos enæggede tvillinger, der er opvokset hver for sig, er lige så ens som hos enæggede tvillinger, der er opvokset sammen, støtter kraftigt det synspunkt, at miljømæssige virkninger på ansigtstræk normalt er meget begrænsede.
Forsynstræk som f.eks. næseformen, en tilbagestrøget hage eller “Habsburg-læben” går ofte i arv i familier fra generation til generation. Vores mål har været at identificere specifikke genetiske varianter, der bestemmer bestemte ansigtstræk. Vores succes med at kunne gøre dette, hvilket ikke er blevet gjort før, har været afhængig af, at vi har brugt komplicerede statistiske procedurer til at analysere ansigtsbilleder af frivillige mennesker.
Vores udgangspunkt var en stor samling af 3-dimensionale ansigtsbilleder taget med et højteknologisk kommercielt kamera. Disse billeder gav os efter en vis manipulation en definition af hvert ansigt som 30 000 punkter på ansigtsoverfladen, effektivt et 3-dimensionelt kort over ansigtet. For at kunne sammenligne træk på forskellige ansigter overlejrede vi alle ansigtsbillederne i forhold til hinanden. Dette gøres ved først at overlejre billederne i forhold til en række landmærkepunkter, f.eks. i spidsen af næsen eller i øjen- eller mundvinklerne. Denne fremgangsmåde minder lidt om den, der blev anvendt af Francis Galton, en pioner inden for undersøgelser af ansigter og tvillinger, for næsten 150 år siden, men nu har vi sofistikerede computerværktøjer og højteknologiske kameraer, der forbedrer den grad, i hvilken vi kan overlejre alle billederne med hinanden, enormt.
Vi har brugt frivillige fra tre kilder: a) 1832 unikke frivillige fra vores meget velkarakteriserede undersøgelse People of the British Isles (PoBI), b) 1567 unikke tvillinger fra TwinsUK-kohorten, ca. lige mange enæggede og ikke-identiske tvillinger, og c) 33 billeder af østasiater, hovedsagelig kinesere.
Da vi havde ansigtsbillederne af tvillingerne, blev vores næste vigtige skridt i analysen muligt, nemlig at identificere de ansigtstræk, der sandsynligvis har en høj arvelighed. To personer, der er enæggede tvillinger, har det samme sæt af genetiske varianter (DNA-sekvenser). Det er disse varianter, der bestemmer deres ansigtstræk og resulterer i meget ensartede ansigter. Ansigtstræk er defineret ved tilknyttede grupper af punkter i ansigtet, lidt ligesom bakker og dale på et
3-dimensionelt kort.
Positionen af et punkt på et ansigtsbillede af det ene medlem af et enægget tvillingepar bør være meget lig positionen af det tilsvarende punkt på billedet af den anden tvilling. I hvor høj grad det er forskelligt, vil være et mål for de ikke-genetiske miljømæssige påvirkninger af dette punkts position i ansigtet. I modsætning hertil kan to personer, der er ikke-identiske tvillinger, have forskellige genetiske varianter, der bestemmer i det mindste nogle af deres ansigtstræk. Placeringen af det samme punkt på et ansigtsbillede af en af de enkelte ikke-identiske tvillinger vil derfor have en tendens til ikke at ligge så tæt på placeringen af det tilsvarende punkt på et billede af den anden tvilling, som hvis de var enæggede tvillinger. I hvor høj grad punkterne ligger længere fra hinanden for de ikke-identiske tvillinger end for de enæggede tvillinger er et mål for den genetiske påvirkning af dette punkt, som genetikere kalder arvelighed. Ved hjælp af yderligere komplekse statistiske procedurer kan vi vægte hvert punkt i ansigtet med dets arvelighed målt på denne måde.
Effekten af denne vægtning kan ses i figur 1, hvor vi har plottet hyppigheden af punkter på ansigtsprofilen, der har forskellige arveligheder. Graden af arvelighed for en given position varierer fra 1, hvis målingen altid er nøjagtig ens hos enæggede tvillinger, men forskellig hos
ikke-identiske tvillinger, til 0, hvis forskellene mellem enæggede tvillinger er de samme som mellem ikke-identiske tvillinger, og således reelt alle
ikke-genetiske, primært miljøbestemte, er bestemt. De røde søjler er for de vægtede værdier, de blå for de oprindelige værdier og de lilla for overlapningen. Den røde profil er klart i gennemsnit højere og meget smallere end den blå, hvilket viser den gavnlige effekt af vægtningen.
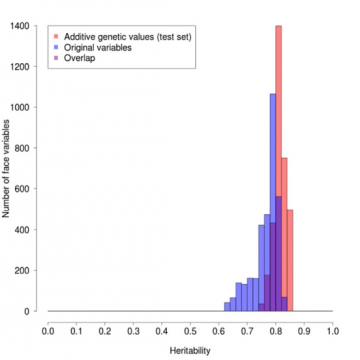
Figur 1: Sammenligning af profilens arvelighed for originale versus arvelighedsvægtede værdier.
Den næste udfordring er at definere de ansigtstræk, der skal bruges til den genetiske analyse, baseret på grupper af tilknyttede punkter. Til dette formål anvender vi de arvelighedsvægtede punkter ud fra den antagelse, at dette vil give et træk, der samlet set sandsynligvis vil være mere arveligt end det, der opnås ved hjælp af de uvægtede punkter. De vægtede punkter blev anvendt til det, som statistikere kalder en PCA, der står for Principal Components Analysis (hovedkomponentanalyse). Det er en måde at udtrække de træk, der er mest variable, af dataene. Hver PCA, og der kan være op til 50 eller flere for komplekse data som ansigtsbillederne, er i sig selv et mål for et ansigtstræk, analogt med afstanden mellem øjnene, men som effektivt kombinerer forskellige målinger baseret på en gruppe af punkter til en enkelt værdi.
Så vidt vi har defineret ansigtstræk, har vi ikke gjort brug af specifikke genetiske oplysninger ved definitionen af ansigtstræk. Vi har DNA-baserede genetiske oplysninger om ca. 500.000 varianter for hver af ca. 1500 personer fra vores PoBI-frivillige, som vi har billeder af, og for et tilsvarende antal af de frivillige fra TwinsUK, som har billeder. Det næste skridt var derfor at lede efter specifikke genetiske varianter, der var forbundet signifikant med vores PCA-baserede ansigtstræk.
Vores tilgang til den genetiske analyse er baseret på den idé, at forskelle i ansigtstræk bør analyseres som diskrete, individuelt identificerbare karakteristika og ikke som et kvantitativt mål, som f.eks. en persons højde. Vi kan ikke genkende en person alene ud fra dens højde eller ud fra et enkelt kvantitativt ansigtstræk, som f.eks. afstanden mellem øjnene eller forholdet mellem ansigtshøjde og -bredde. Vi håndterer dette ved at fokusere på de personer, der befinder sig i de ekstreme øverste eller nederste 10 % af hver af de værdier, som PCA’en giver, og spørge, om de deler en eller flere af de 500.000 genetiske markører mere end de personer, der ikke befinder sig i disse ekstremer. Vi brugte People of the British Isles-frivillige til at udvælge kandidatgenvarianter ud af de 500.000 testede til yderligere analyse baseret på betydningen af forskellen mellem de ekstreme og de ikke-ekstreme og på størrelsen af denne forskel. Vi spurgte derefter, om nogen af disse kandidatvirkninger blev gentaget hos de ca. 1.500 frivillige fra TwinsUK. På denne måde har vi identificeret tre specifikke og replikerede genetiske varianter med relativt store virkninger, to for træk ved ansigtsprofiler og en for området omkring øjnene. Hver af disse tre varianter har
en partner med en anden DNA-sekvens på den samme kritiske position, og i hvert tilfælde har den positivt associerede variant en PoBI-populationsfrekvens på ca. 10 %, mens partneren har den højere frekvens på ca. 90 %. Vi kalder den associerede variant a og dens partner A, og da gener kommer parvis, er der således tre kombinationer af disse varianter, aa, Aa og AA.
Den første af disse varianter, der findes i et gen kaldet PCDH15, øgede chancen for at have de kvindelige træk, der er vist i figur 2C, med en faktor på mere end 7 hos de britiske kvinder, der bar begge kopier af varianten (aa), sammenlignet med dem, der kun havde den ene (Aa) eller ingen kopier (AA) af varianten. Denne variant er også forbundet med træk, der adskiller sig mellem de britiske og de østasiatiske frivillige kvinder. Bemærk den opadvendte ende af næsen og overlæben og den tilbagetrukne hage i figur 2A, som er gennemsnittet af de kinesiske ansigter, og i figur 2B, som er den mere kinesiske gruppe af PoBI-individerne, og sæt dette i kontrast til figur 2C. Produktet af PCDH15-genet findes i olfaktoriske celler og brusk i næsen hos mus under udvikling, hvilket er i overensstemmelse med
en mulig virkning på næsen af den variant, vi har fundet hos mennesker.
Den anden variant, i genet kaldet MBTPS1, er forbundet med den ansigtsforskel, der er vist i figur 3. Denne forskel blev observeret hos hunner, og den karakteristiske delmængde af ansigter bar begge kopier af varianten (aa). I dette tilfælde er den genetiske variant, der er forbundet med den øverste ekstreme fænotype (figur 3A), til stede (formodentlig som aa) hos den afrikanske grønne abe, makak og olivenbaboon, mens dens partner, den almindelige variant, er til stede (formodentlig som AA) hos orangutang, gorilla, chimpanse og marmoset, hvilket tyder på, at denne variantforskel kan være forbundet med ansigtsforskellene mellem disse primatgrupper.
Den tredje variant, i genet kaldet TMEM163, er hos begge køn forbundet med en forskel i øjnene, som vist i figur 4. En defekt version af dette gen har en potentiel rolle i en sygdom kaldet mucolipidose type IV, en tilstand, der lejlighedsvis er ledsaget af ansigtsanormaliteter, især omkring øjenlågene. I vores undersøgelser er det den delmængde af individer, der bærer begge kopier af varianten (aa), der er forbundet med den øverste ekstremitet, vist i figur 4A. Bemærk, at øjenbredden og øjenhøjden (fra bunden af øjenbrynet til toppen af øjenlåget) begge er større i den øvre ekstrem end i den nedre ekstrem.
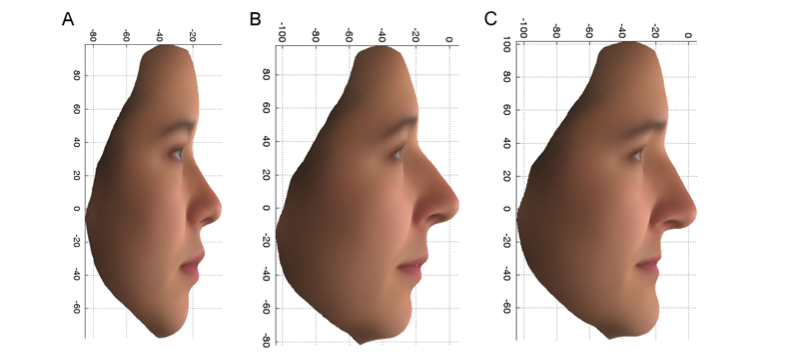
Figur 2: PC2-profil: Gennemsnitlige ansigter ved hjælp af de oprindelige variabler for 14 østasiatiske kvinder (A) og de øverste 10 % (mere østasiatiske) (B) og de nederste 10 % (mere europæiske) (C) ekstremer af PoBI-kvinderne.
Hver af de tre genetiske varianter, som vi har været i stand til at knytte til et specifikt ansigtstræk, øger chancen for at have det specifikke træk med
en faktor på mere end 7 hos de britiske frivillige, der bærer begge kopier (aa) af varianten, sammenlignet med dem, der kun har én (Aa) eller ingen (AA) kopier af varianten.

Figur 3: PC7-profil: Gennemsnitlige profiler af kvindelige ansigter ved hjælp af de oprindelige variabler for de øverste 10 % (A) og de nederste 10 % (C) af de tilknyttede varianter samt det samlede gennemsnit (B).

Figur 4: PC1-øjne: Gennemsnitlige øjenfænotyper ved hjælp af de oprindelige variabler for de øverste 10% (A), de nederste 10% (C) ekstremer og det samlede gennemsnit (B).
Vores succes med at finde disse genetiske varianter afhænger i høj grad af vores evne til at identificere ansigtstræk, der har en høj arvelighed baseret på tvillingedataene, og af valget af ekstremer til undersøgelse af de genetiske variantforbindelser. Det forekommer sandsynligt, at mange flere specifikke og relativt store genetiske varianteffekter på menneskelige ansigtstræk vil blive fundet i fremtiden ved hjælp af fremgangsmåder som dem, vi har beskrevet. Dette baner vejen for en opklaring af de molekylære mekanismer, hvormed genetiske varianter bestemmer den ekstraordinære variabilitet i menneskers ansigtsudseende.