
Den første ting vi skal forstå er karakteren af variabler, og hvordan variabler bruges i et undersøgelsesdesign til at besvare undersøgelsesspørgsmålene. I dette kapitel lærer du:
- forskellige typer variabler i kvantitative undersøgelser,
- problemer omkring analyseenhedsspørgsmålet.
Forståelse af kvantitative variabler
Roden af ordet variabel er beslægtet med ordet “variere”, hvilket bør hjælpe os til at forstå, hvad variabler kan være. Variabler er elementer, enheder eller faktorer, der kan ændre sig (variere); f.eks. er den udendørs temperatur, prisen på benzin pr. gallon, en persons vægt og humøret hos personer i din udvidede familie alle variabler. Med andre ord kan de have forskellige værdier under forskellige forhold eller for forskellige personer.
Vi bruger variabler til at beskrive træk eller faktorer af interesse. Eksempler kan være antallet af medlemmer i forskellige husstande, afstanden til sunde fødevarekilder i forskellige kvarterer, forholdet mellem lærere og studerende på et BSW- eller MSW-program for socialt arbejde, andelen af personer fra forskellige race-/etniske grupper, der er fængslet, transportomkostningerne for at modtage tjenester fra et socialt arbejdsprogram eller spædbørnsdødeligheden i forskellige amter. I forskning i interventioner inden for socialt arbejde kan variabler omfatte karakteristika ved interventionen (intensitet, hyppighed, varighed) og resultater i forbindelse med interventionen.
Demografiske variabler. Socialarbejdere er ofte interesserede i det, vi kalder demografiske variabler. Demografiske variabler bruges til at beskrive karakteristika ved en population, en gruppe eller en stikprøve af populationen. Eksempler på hyppigt anvendte demografiske variabler er
- alder,
- etnicitet,
- national oprindelse,
- religiøst tilhørsforhold,
- køn,
- seksuel orientering,
- ægteskabelig status/forholdstilstand,
- beskæftigelsesstatus,
- politisk tilhørsforhold,
- geografisk beliggenhed,
- uddannelsesniveau og
- indkomst.
På et mere makroplan omfatter et samfunds eller en organisations demografi ofte dens størrelse; organisationer måles ofte i forhold til deres samlede budget.
Uafhængige og afhængige variabler. En måde, hvorpå undersøgerne tænker på undersøgelsesvariabler, har vigtige konsekvenser for et undersøgelsesdesign. Undersøgerne træffer beslutninger om at lade dem tjene som enten uafhængige variabler eller som afhængige variabler. Denne skelnen er ikke noget, der er indbygget i en variabel, men er baseret på, hvordan undersøgeren vælger at definere hver variabel. Uafhængige variabler er dem, man kan tænke på som de manipulerede “input”-variabler, mens de afhængige variabler er dem, hvor virkningen eller “output” af denne inputvariation vil blive observeret.
Der er ikke altid tale om bevidst manipulation af den “input”-variabel (uafhængige). Tag eksemplet med en undersøgelse, der blev gennemført i Sverige, og som undersøgte forholdet mellem at have været offer for børnemishandling og senere fravær fra gymnasiet: Ingen manipulerede bevidst med, om børnene ville blive ofre for børnemishandling (Hagborg, Berglund, & Fahlke, 2017). Forskerne opstillede den hypotese, at naturligt forekommende forskelle i inputvariablen (historie om børnemishandling) ville være forbundet med systematisk variation i en specifik resultatvariabel (skolefravær). I dette tilfælde var den uafhængige variabel en historie med at være offer for børnemishandling, og den afhængige variabel var resultatet af skolefraværet. Med andre ord er det undersøgerens hypotese, at den uafhængige variabel forårsager variation eller ændring i den afhængige variabel. Sådan kan det se ud i et diagram, hvor “x” er den uafhængige variabel og “y” er den afhængige variabel (bemærk: du så denne betegnelse tidligere, i kapitel 3, da vi diskuterede logik med årsag og virkning):

For et andet eksempel kan du overveje forskning, der indikerer, at det at være offer for børnemishandling er forbundet med en højere risiko for stofmisbrug i ungdomsårene (Yoon, Kobulsky, Yoon, & Kim, 2017). Den uafhængige variabel i denne model ville være at have en historie med mishandling af børn. Den afhængige variabel ville være risikoen for stofbrug i ungdomsårene. Dette eksempel er endnu mere udførligt, fordi det specificerer den vej, ad hvilken den uafhængige variabel (mishandling af børn) kan pålægge sine virkninger på den afhængige variabel (stofbrug i ungdommen). Forfatterne til undersøgelsen viste, at posttraumatisk stress (PTS) var en forbindelse mellem misbrug i barndommen (fysisk og seksuel) og stofbrug i ungdomsårene.

Tag et øjeblik til at gennemføre følgende aktivitet.
Typer af kvantitative variabler
Der er også andre meningsfulde måder at tænke over variabler af interesse på. Lad os overveje forskellige egenskaber ved variabler, der anvendes i kvantitative forskningsundersøgelser. Her undersøger vi kvantitative variabler som værende kategoriske, ordinale eller intervalvariable af natur. Disse egenskaber har betydning for både måling og dataanalyse.
Kategoriske variabler. Nogle variabler kan antage værdier, der varierer, men ikke på en meningsfuld numerisk måde. I stedet kan de defineres i form af de kategorier, der er mulige. Logisk set kaldes disse for kategoriske variabler. Statistisk software og lærebøger henviser undertiden til variabler med kategorier som nominelle variabler. Nominel kan tænkes på den latinske rod “nom”, som betyder “navn”, og bør ikke forveksles med tal. Nominel betyder det samme som kategorisk i beskrivelsen af variabler. Med andre ord identificeres kategoriske eller nominelle variabler ved hjælp af navnene eller etiketterne på de repræsenterede kategorier. F.eks. ville farven på den sidste bil, du kørte i, være en kategorisk variabel: blå, sort, sølv, hvid, rød, grøn, gul eller andet er kategorier af den variabel, vi kan kalde bilfarve.
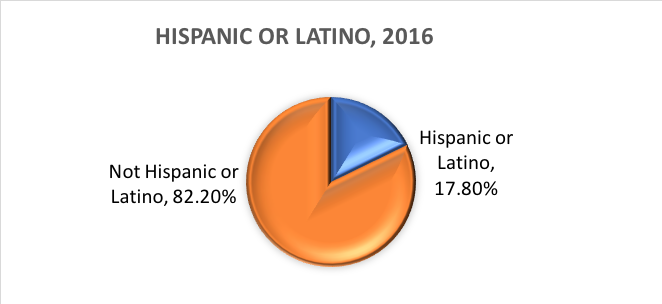
Det vigtige ved kategoriske variabler er, at disse kategorier ikke har nogen relevant numerisk rækkefølge eller orden. Der er ingen numerisk forskel mellem de forskellige bilfarver eller forskel mellem “ja” eller “nej” som kategorierne i forbindelse med at svare på, om du kørte i en blå bil. Der er ingen implicit orden eller hierarki i kategorierne “Hispanic or Latino” og “Not Hispanic or Latino” i en etnicitetsvariabel; der er heller ingen relevant orden i kategorier af variabler som køn, den stat eller geografiske region, hvor en person er bosat, eller om en persons bolig er ejet eller lejet.
Hvis en forsker besluttede at bruge tal som symboler i forbindelse med kategorier i en sådan variabel, er tallene vilkårlige – hvert tal er i bund og grund bare et andet, kortere navn for hver kategori. F.eks. kunne variablen køn blive kodet på følgende måder, og det ville ikke gøre nogen forskel, så længe koden blev anvendt konsekvent.
| Kodningsmulighed A | Variabelkategorier | Kodningsmulighed B |
|---|---|---|
| 1 | mand | 2 |
| 2 | kvinde | 1 |
| 3 | andre end mand eller kvinde alene | 4 |
| 4 | foretrækker ikke at svare | 3 |
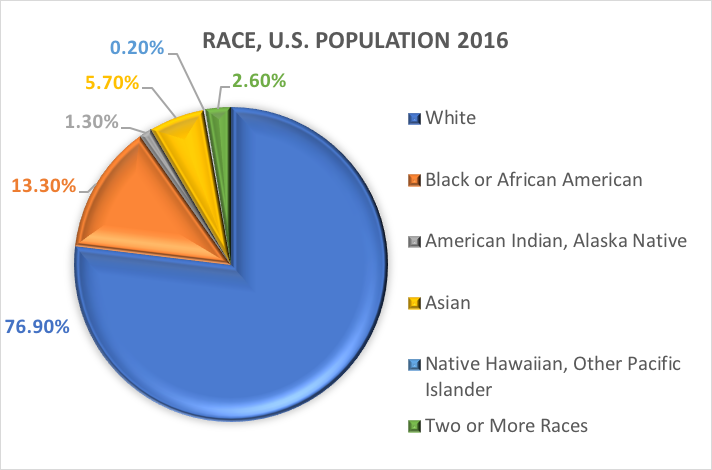
Race og etnisk tilhørsforhold.En af de mest almindeligt udforskede kategoriske variabler i socialt arbejde og socialvidenskabelig forskning er de demografiske variabler, der henviser til en persons racemæssige og/eller etniske baggrund. Mange undersøgelser anvender de kategorier, der er angivet i tidligere rapporter fra U.S. Census Bureau. Her er, hvad U.S. Census Bureau har at sige om de to forskellige demografiske variabler, race og etnicitet (https://www.census.gov/mso/www/training/pdf/race-ethnicity-onepager.pdf):
Hvad er race? Census Bureau definerer race som en persons selvidentifikation med en eller flere sociale grupper. En person kan angive sig som hvid, sort eller afroamerikaner, asiat, indianer og indfødte fra Alaska, indfødte fra Hawaii og andre Stillehavsøer eller en anden race. Respondenterne i undersøgelsen kan angive flere racer.
Hvad er etnicitet? Etnicitet afgør, om en person er af latinamerikansk oprindelse eller ej. Af denne grund er etnicitet opdelt i to kategorier: Hispanic eller Latino og Not Hispanic or Latino (ikke Hispanic eller Latino). Hispanics kan oplyse, at de er af enhver race.
Med andre ord definerer Census Bureau to kategorier for den variabel, der kaldes etnicitet (Hispanic or Latino og Not Hispanic or Latino), og syv kategorier for den variabel, der kaldes race. Selv om disse variabler og kategorier ofte anvendes i samfundsvidenskabelig forskning og forskning i socialt arbejde, er de ikke uden kritik.
Baseret på disse kategorier er her, hvad der skønnes at gælde for den amerikanske befolkning i 2016:
Dichotomiske variabler: Der findes en særlig kategori af kategoriske variabler med konsekvenser for visse statistiske analyser. Kategoriske variabler, der består af præcis to muligheder, ikke flere og ikke færre, kaldes dikotome variabler. Et eksempel herpå er U.S. Census Bureau’s dikotomi af latinamerikansk/latino- og ikke-hispanisk/ikke-latinamerikansk etnisk tilhørsforhold. Et andet eksempel er, at undersøgere måske ønsker at sammenligne personer, der gennemfører behandlingen, med personer, der falder fra, inden behandlingen afsluttes. Med de to kategorier, fuldført eller ikke fuldført, er denne variabel for fuldførelse af behandlingen ikke blot kategorisk, men også dikotomisk. Variabler, hvor enkeltpersoner svarer “ja” eller “nej”, er også dikotome i deres natur.
Den tidligere tradition for at behandle køn som enten mand eller kvinde er et andet eksempel på en dikotom variabel. Der findes imidlertid meget stærke argumenter for ikke længere at behandle køn på denne dikotomiske måde: en større variation af kønsidentiteter er påviseligt relevant i socialt arbejde for personer, hvis identitet ikke stemmer overens med de dikotomiske (også kaldet binære) kategorier mand/kvinde eller mand/kvinde. Disse omfatter kategorier som agender, androgynous, bigender, cisgender, gender expansive, gender fluid, gender questioning, queer, transgender og andre.
Ordinale variabler. I modsætning til disse kategoriske variabler har en variabels kategorier undertiden en logisk numerisk rækkefølge eller orden. Ordinal refererer pr. definition til en position i en række. Variabler med numerisk relevante kategorier kaldes ordinale variabler. F.eks. er der en implicit rækkefølge af kategorierne fra mindst til størst med variablen uddannelsesniveau. Den amerikanske Census-datakategorier for denne ordinale variabel er:
- ingen
- 1st-4thgrade
- 5th-6thgrade
- 7th-8thgrade
- 9thgrade
- 10thgrade
- 11thgrade
- high school graduate
- some college, ingen eksamen
- med en videregående uddannelse, erhverv
- associate’s degree academic
- bachelor’s degree
- master’s degree
- professional degree
- professional degree
- doctoral degree
Ved at se på Census Bureau’s estimatdata fra 2016 for denne variabel kan vi se, at der er flere kvinder end mænd i kategorien, der har opnået en bachelor’s degree: af de 47 718 000 personer i denne kategori var 22 485 000 mænd og 25 234 000 kvinder. Mens dette kønsbestemte mønster var gældende for dem, der opnåede en kandidatgrad, var mønsteret omvendt for dem, der opnåede en doktorgrad: flere mænd end kvinder opnåede dette højeste uddannelsesniveau. Det er også interessant at bemærke, at der var flere kvinder end mænd i den lave ende af spektret: 441 000 kvinder angav ingen uddannelse sammenlignet med 374 000 mænd.
Her er endnu et eksempel på anvendelse af ordinale variabler i forskning i socialt arbejde: Når personer søger behandling for et problem med alkoholmisbrug, ønsker socialarbejdere måske at vide, om det er deres første, andet, tredje eller hvad der er deres første, andet, tredje eller hvad der er nummereret som et seriøst forsøg på at ændre deres drikkeadfærd. Deltagere, der deltog i en undersøgelse, som sammenlignede behandlingsmetoder for alkoholforstyrrelser, rapporterede, at interventionsundersøgelsen var et sted mellem deres første og ellevte forsøg på en væsentlig ændring (Begun, Berger, Salm-Ward, 2011). Denne variabel for ændringsforsøg har konsekvenser for, hvordan socialarbejdere kan fortolke data, der evaluerer en intervention, som ikke var det første forsøg for alle involverede.
Ratingskalaer. Overvej en anden, men almindeligt anvendt type ordinale variabler: vurderingsskalaer. Social-, adfærds- og socialarbejdsforskere beder ofte undersøgelsens deltagere om at anvende en vurderingsskala til at beskrive deres viden, holdninger, overbevisninger, meninger, færdigheder eller adfærd. Fordi kategorierne på en sådan skala er ordnede (fra mest til mindst eller fra mindst til mest), kalder vi dem ordinale variabler.

Eksempler omfatter at lade deltagerne vurdere:
- hvor enige eller uenige de er i visse udsagn (slet ikke til ekstremt meget);
- hvor ofte de udøver visse former for adfærd (aldrig til altid);
- hvor ofte de udøver visse former for adfærd (hver time, dag, uge, måned, årligt eller mindre ofte);
- kvaliteten af en persons præstation (dårlig til fremragende);
- hvor tilfreds de var med deres behandling (meget utilfreds til meget tilfreds)
- deres tillidsniveau (meget lavt til meget højt).
Intervalvariabler. Endnu andre variabler antager værdier, der varierer på en meningsfuld numerisk måde. Fra vores liste over demografiske variabler er alder et almindeligt eksempel. Den numeriske værdi, der tildeles en individuel person, angiver antallet af år siden en person blev født (for spædbørn kan den numeriske værdi angive dage, uger eller måneder siden fødslen). Her er de mulige værdier for variablen ordnet ligesom ordinale variabler, men der er indført en stor forskel: arten af intervallerne mellem de mulige værdier. Med intervalvariabler er “afstanden” mellem tilstødende mulige værdier lige stor. Nogle statistiske softwarepakker og lærebøger bruger udtrykket skalavariabel: det er præcis det samme som det, vi kalder en intervalvariabel.
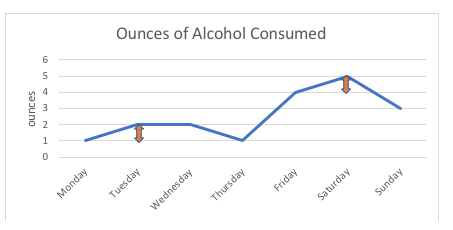
For eksempel er forskellen på 1 ounce mellem denne person, der indtager 1 ounce eller 2 ounces alkohol (mandag, tirsdag), i nedenstående graf præcis den samme som forskellen på 1 ounce mellem at indtage 4 ounces eller 5 ounces (fredag, lørdag). Hvis vi tegnede et diagram over de mulige punkter på skalaen, ville de alle være lige langt fra hinanden; intervallet mellem to punkter er målt i standardenheder (ounces i dette eksempel).
Med ordinale variabler, som f.eks. en vurderingsskala, kan ingen med sikkerhed sige, at “afstanden” mellem svarmulighederne “aldrig” og “nogle gange” er den samme som “afstanden” mellem “nogle gange” og “ofte”, selv om vi brugte tal til at sekventere disse svarmuligheder. Derfor forbliver vurderingsskalaen ordinal, ikke interval.
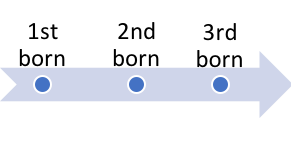
Det, der kan blive en smule forvirrende, er, at visse statistiske softwareprogrammer, såsom SPSS, henviser til en intervalvariabel som en “skala”-variabel. Mange variabler, der anvendes i forskning i socialt arbejde, er både ordnede og har lige store afstande mellem punkterne. Tænk f.eks. på variablen fødselsrækkefølge. Denne variabel er intervalvariabel, fordi:
- de mulige værdier er ordnede (f.eks. kom det tredjefødte barn efter det første- og andetfødte og før det fjerdefødte), og
- “afstandene” eller intervallerne måles i tilsvarende enheder for én person.
Kontinuerlige variabler. Der findes en særlig type numeriske intervalvariable, som vi kalder kontinuerte variabler. En variabel som f.eks. alder kan behandles som en kontinuert variabel. Alder er ordinal i sin natur, da højere tal betyder noget i forhold til mindre tal. Alder opfylder også vores kriterier for at være en intervalvariabel, hvis vi måler den i år (eller måneder, uger eller dage), fordi den er ordinal, og der er den samme “afstand” mellem at være 15 og 30 år gammel som mellem at være 40 og 55 år gammel (15 kalenderår). Det, der gør det til en kontinuert variabel, er, at der også er mulige, meningsfulde “brøkpunkter” mellem to intervaller. En person kan f.eks. være 20½ (20,5) eller 20¼ (20,25) eller 20¾ (20,75) år gammel; vi er ikke begrænset til kun at bruge hele tal for alder. I modsætning hertil kan vi, da vi så på fødselsrækkefølge, ikke have en meningsfuld brøkdel af en person mellem to positioner på skalaen.
Det særlige tilfælde med indkomst. En af de mest misbrugte variabler i samfundsvidenskabelig forskning og forskning i socialt arbejde er den variabel, der vedrører indkomst. Overvej et eksempel om husstandsindkomst (uanset hvor mange personer der er i husstanden). Denne variabel kan være kategorisk (nominel), ordinal eller interval (skala) afhængigt af, hvordan den håndteres.
Kategorisk eksempel: Afhængigt af forskningsspørgsmålenes art kan en undersøger blot vælge at anvende de dikotome kategorier “tilstrækkeligt ressourcestærke” og “utilstrækkeligt ressourcestærke” til klassificering af husstande på grundlag af en eller anden standardberegningsmetode. Disse kan kaldes “fattige” og “ikke fattige”, hvis der anvendes en fattigdomsgrænse til at kategorisere husholdningerne. Disse forskellige kategorier af indkomstvariable er ikke meningsfuldt sekventeret på en numerisk måde, så der er tale om en kategorisk variabel.
Ordinalt eksempel: Kategorier til klassificering af husstande kan være ordnet fra lav til høj. For eksempel er disse kategorier for årsindkomst almindelige i markedsundersøgelser:
- Mindre end 25 000 $.
- 25 000 $ til 34 999 $.
- 35 000 $ til 49 999 $.
- 50 000 $ til 74 999 $.
- 75 000 $ til 99 999 $.
- $100.000 til $149.999.
- $150.000 til $199.999.
- $200.000 eller mere.
Bemærk, at kategorierne ikke er lige store – “afstanden” mellem par af kategorier er ikke altid den samme. De starter i intervaller på ca. 10.000 $, går over til intervaller på 25.000 $ og ender i intervaller på ca. 50.000 $.
Interval Eksempel. Hvis en undersøger bad deltagerne i undersøgelsen om at angive et faktisk dollarbeløb for husstandsindkomsten, ville vi se en intervalvariabel. De mulige værdier er ordnet, og intervallet mellem alle mulige tilstødende enheder er 1 USD (så længe der ikke anvendes dollarbrøker eller cents). En indkomst på 10 452 USD er således den samme afstand på et kontinuum fra 9 452 USD og 11 452 USD – 1 000 USD i hver retning.

Det særlige tilfælde af alder. Ligesom indkomst kan “alder” betyde forskellige ting i forskellige undersøgelser. Alder er normalt en indikator for “tid siden fødslen”. Vi kan beregne en persons alder ved at trække en variabel for fødselsdato fra måletidspunktet (dags dato minus fødselsdato). For voksne måles alderen typisk i år, hvor de tilstødende mulige værdier er fordelt i 1-års enheder: 18, 19, 20, 21, 22 osv. Aldersvariablen kan således være en kontinuerlig type intervalvariabel.
En undersøger kan imidlertid ønske at sammenfatte aldersdata i ordnede kategorier eller aldersgrupper. Disse ville stadig være ordinale, men ville måske ikke længere være intervalvariable, hvis trinene mellem de mulige værdier ikke er ækvivalente enheder. Hvis vi f.eks. er mere interesserede i alder, der repræsenterer specifikke menneskelige udviklingsperioder, er aldersintervallerne måske ikke lige store i spændvidde mellem alderskriterierne. Muligvis kan de være det:
- Spædbarn (fødsel til 18 måneder)
- Vuggestue (18 måneder til 2 ½ år)
- Forskole (2 ½ til 5 år)
- Skolealder (6 til 11 år)
- Adolescens (12 til 17 år)
- Emerging Adulthood (18 til 25 år)
- Adulthood (26 til 45 år)
- Middle Adulthood (46 til 60 år)
- Young-Old Adulthood (60 til 74 år)
- Middle-Old Adulthood (75 til 84 år)
- Old-Old Adulthood (85 år eller derover)
Alderen kan endda behandles som en strengt kategorisk (ikke-ordinal) variabel. Hvis den interessante variabel f.eks. er, om en person har den lovlige alkoholalder (21 år eller derover) eller ikke. Vi har to kategorier – opfylder eller ikke opfylder kriterierne for lovlig alkoholalder i USA – og den ene kategori kan kodes med et “1” og den anden med enten “0” eller “2” uden nogen forskel i betydning.
Hvad er det “rigtige” svar på, hvordan man måler alder (eller indkomst)? Svaret er “det kommer an på”. Det afhænger af forskningsspørgsmålets karakter: Hvilken konceptualisering af alder (eller indkomst) er mest relevant for den undersøgelse, der er ved at blive udformet.
Alfanumeriske variabler. Endelig er der data, som ikke passer ind i nogen af disse klassifikationer. Nogle gange er de oplysninger, vi kender, i form af en adresse eller et telefonnummer, et for- eller efternavn, et postnummer eller andre sætninger. Disse former for oplysninger kaldes undertiden alfanumeriske variabler. Tag f.eks. variablen “adresse”: En persons adresse kan bestå af numeriske tegn (husnummeret) og bogstavtegn (som staver gade-, by- og statsnavne), f.eks. 1600 Pennsylvania Ave. NW, Washington, DC, 20500.

I virkeligheden har vi flere variabler til stede i dette adresseeksempel:
- gadeadressen: 1600 Pennsylvania Ave.
- Byen (og “stat”): Washington, DC
- postnummer: 20500.
Denne type oplysninger repræsenterer ikke specifikke kvantitative kategorier eller værdier med systematisk betydning i dataene. Disse variabler kaldes også nogle gange “string”-variabler i visse softwarepakker, fordi de består af en række symboler. For at være nyttig for en undersøger vil en sådan variabel skulle konverteres eller omkodes til meningsfulde værdier.
En bemærkning om analyseenhed
En vigtig ting at huske på, når man tænker på variabler, er, at data kan indsamles på mange forskellige observationsniveauer. De elementer, der undersøges, kan være individuelle celler, organsystemer eller personer. Eller observationsniveauet kan være par af individer, f.eks. par, brødre og søstre eller forældre-barn-dyader. I dette tilfælde kan undersøgeren indsamle oplysninger om parret fra hvert enkelt individ, men ser på hvert pars data. Vi vil således sige, at analyseenheden er parret eller dyaden og ikke hver enkelt person. Analyseenheden kan også være en større gruppe: Der kan f.eks. indsamles data fra hver enkelt elev i hele klasseværelser, hvor analyseenheden er klasseværelser i en skole eller et skolesystem. Eller analyseenheden kan være på niveauet for kvarterer, programmer, organisationer, amter, stater eller endog nationer. For eksempel er mange af de variabler, der anvendes som indikatorer for fødevaresikkerhed på samfundsniveau, såsom overkommelighed og tilgængelighed, baseret på data indsamlet fra individuelle husstande (Kaiser, 2017). Analyseenheden i undersøgelser, der anvender disse indikatorer, vil være de samfund, der sammenlignes. Denne sondring har vigtige konsekvenser for måling og dataanalyse.
En påmindelse om variabler versus variabelniveauer
En undersøgelse kan beskrives i form af antallet af variablekategorier eller niveauer, der sammenlignes. Du kan f.eks. se en undersøgelse beskrevet som et 2 X 2-design – udtalt som et to gange to-design. Det betyder, at der er 2 mulige kategorier for den første variabel og 2 mulige kategorier for den anden variabel – de er begge dikotome variabler. En undersøgelse, der sammenligner 2 kategorier af variablen “alkoholforstyrrelse” (kategorier for opfylder kriterierne, ja eller nej) med 2 kategorier af variablen “forstyrrelse ved brug af illegale stoffer” (kategorier for opfylder kriterierne, ja eller nej), ville have 4 mulige resultater (matematisk set ville 2 x 2=4) og kunne være skematiseret på denne måde (data baseret på proportioner fra NSDUH-undersøgelsen fra 2016, præsenteret i SAMHSA, 2017):
| Illicit Substance Use Disorder (SUD) | |||
|---|---|---|---|
|
Alcohol Use Disorder (AUD) |
No | Yes | |
| Nej | 500 | 10 | |
| Ja | 26 | 4 | |
Læsning af de 4 celler i denne 2 X 2 tabel fortæller os, at i denne (hypotetiske) undersøgelse med 540 personer, 500 ikke opfyldte kriterierne for hverken en alkohol- eller stofmisbrugsforstyrrelse (Nej, Nej); 26 opfyldte kun kriterierne for en alkoholforstyrrelse (Ja, Nej), 10 opfyldte kun kriterierne for en forstyrrelse ved brug af illegale stoffer (Nej, Ja), og 4 opfyldte kriterierne for både en alkoholforstyrrelse og en forstyrrelse ved brug af illegale stoffer (Ja, Ja). Med lidt matematik kan vi desuden se, at i alt 30 personer havde en alkoholforstyrrelse (26 + 4) og 14 personer havde en forstyrrelse ved brug af illegale stoffer (10 + 4). Og vi kan se, at 40 havde en eller anden form for stofbrugsforstyrrelse (26 + 10 + 4).
 For at gøre denne skelnen mellem variabler og variabelniveauer eller -kategorier krystalklar, lad os overveje endnu et eksempel: et 2 X 3 undersøgelsesdesign. Hvis vi først regner på det, bør vi se 6 mulige resultater (celler). For det andet ved vi, at den første variabel (aldersgruppe) har 2 kategorier (under 30 år, 30 år eller derover), og at den anden variabel (beskæftigelsesstatus) har 3 kategorier (fuldt beskæftiget, delvist beskæftiget, arbejdsløs). Denne gang er de 6 celler i vores design tomme, fordi vi venter på dataene.
For at gøre denne skelnen mellem variabler og variabelniveauer eller -kategorier krystalklar, lad os overveje endnu et eksempel: et 2 X 3 undersøgelsesdesign. Hvis vi først regner på det, bør vi se 6 mulige resultater (celler). For det andet ved vi, at den første variabel (aldersgruppe) har 2 kategorier (under 30 år, 30 år eller derover), og at den anden variabel (beskæftigelsesstatus) har 3 kategorier (fuldt beskæftiget, delvist beskæftiget, arbejdsløs). Denne gang er de 6 celler i vores design tomme, fordi vi venter på dataene.
| Beskæftigelsesstatus | |||||
|---|---|---|---|---|---|
|
Aldersgruppe |
Fuldt beskæftiget | Partielt beskæftiget Beskæftiget | Ubeskæftiget | ||
| <30 | |||||
| ≥30 | |||||
Sådan, når du ser en beskrivelse af undersøgelsesdesignet, der ligner to tal, der multipliceres, fortæller det dig i bund og grund, hvor mange kategorier eller niveauer af hver variabel der er, og det får dig til at forstå, hvor mange celler eller mulige resultater der findes. Et 3 X 3-design har 9 celler, et 3 X 4-design har 12 celler og så videre. Dette spørgsmål bliver vigtigt igen, når vi diskuterer stikprøvestørrelse i kapitel 6.
Udfør følgende arbejdsbogs-aktivitet:
- SWK 3401.3-4.1 Begyndende dataindtastning
Kapitelresumé
Sammenfattende designer undersøgere mange af deres kvantitative undersøgelser for at teste hypoteser om sammenhænge mellem variabler. Forståelse af karakteren af de involverede variabler hjælper med at forstå og evaluere den udførte forskning. Forståelse af forskellene mellem forskellige typer af variabler samt mellem variabler og kategorier har vigtige konsekvenser for undersøgelsesdesign, måling og stikprøver. I næste kapitel undersøges bl.a. krydsfeltet mellem karakteren af de variabler, der undersøges i kvantitativ forskning, og hvordan forskerne går i gang med at måle disse variabler.
Tag et øjeblik til at gennemføre følgende aktivitet.