
- Ein schneller Überblick über die besten Papers zur Bildklassifizierung in einem Jahrzehnt, um Ihr Lernen von Computer Vision
- 1998: LeNet
- 2012: AlexNet
- 2014: VGG
- 2014: GoogLeNet
- 2015: Batch Normalization
- 2015: ResNet
- 2016: Xception
- 2017: MobileNet
- 2017: NASNet
- 2019: EfficientNet
- 2014: SPPNet
- 2016: DenseNet
- 2017: SENet
- 2017: ShuffleNet
- 2018: Bag of Tricks
- Schlussfolgerung
Ein schneller Überblick über die besten Papers zur Bildklassifizierung in einem Jahrzehnt, um Ihr Lernen von Computer Vision

Computer Vision ist ein Fach, das Bilder und Videos in maschinen-verständliche Signale. Mit diesen Signalen können Programmierer das Verhalten der Maschine auf der Grundlage dieses hochgradigen Verständnisses weiter steuern. Unter den vielen Aufgaben der Computer Vision ist die Bildklassifizierung eine der grundlegendsten. Sie kann nicht nur in vielen realen Produkten wie der Verschlagwortung von Google Photo und der KI-Inhaltsmoderation eingesetzt werden, sondern öffnet auch die Tür für viele fortgeschrittenere Bildverarbeitungsaufgaben wie die Objekterkennung und das Videoverständnis. Aufgrund der rasanten Veränderungen in diesem Bereich seit dem Durchbruch von Deep Learning sind Anfänger oft überfordert, wenn es darum geht, etwas zu lernen. Im Gegensatz zu typischen Software-Engineering-Themen gibt es nicht viele gute Bücher über die Bildklassifizierung mit DCNN, und der beste Weg, dieses Gebiet zu verstehen, ist die Lektüre akademischer Arbeiten. Aber welche Arbeiten soll ich lesen? Wo soll ich anfangen? In diesem Artikel stelle ich Ihnen die 10 besten Arbeiten für Anfänger vor, die Sie lesen sollten. Anhand dieser Arbeiten können wir sehen, wie sich dieses Gebiet weiterentwickelt und wie Forscher auf der Grundlage früherer Forschungsergebnisse neue Ideen entwickelt haben. Dennoch ist es für Sie hilfreich, sich einen Überblick zu verschaffen, auch wenn Sie bereits eine Weile in diesem Bereich gearbeitet haben. Also, fangen wir an.
1998: LeNet
Gradient-based Learning Applied to Document Recognition

Eingeführt im Jahr 1998, LeNet legt den Grundstein für die künftige Forschung im Bereich der Bildklassifizierung unter Verwendung des Convolution Neural Network. Viele klassische CNN-Techniken wie Pooling-Schichten, vollständig verbundene Schichten, Auffüllungen und Aktivierungsschichten werden verwendet, um Merkmale zu extrahieren und eine Klassifizierung vorzunehmen. Mit einer Verlustfunktion des mittleren quadratischen Fehlers (Mean Square Error) und 20 Trainingsepochen kann dieses Netzwerk eine Genauigkeit von 99,05 % auf dem MNIST-Testsatz erreichen. Auch nach 20 Jahren folgen viele moderne Klassifizierungsnetzwerke im Allgemeinen immer noch diesem Muster.
2012: AlexNet
ImageNet Classification with Deep Convolutional Neural Networks

Obwohl LeNet ein großartiges Ergebnis erzielte und das Potenzial von CNN zeigte, stagnierte die Entwicklung in diesem Bereich ein Jahrzehnt lang aufgrund der begrenzten Rechenleistung und der Datenmenge. Es sah so aus, als könne CNN nur einfache Aufgaben wie die Erkennung von Zahlen lösen, aber für komplexere Merkmale wie Gesichter und Objekte war ein HarrCascade- oder SIFT-Merkmalsextraktor mit einem SVM-Klassifikator der bevorzugte Ansatz.
Allerdings schlug Alex Krizhevsky 2012 bei der ImageNet Large Scale Visual Recognition Challenge eine CNN-basierte Lösung für diese Herausforderung vor und steigerte die Top-5-Genauigkeit des ImageNet-Testsets drastisch von 73,8 % auf 84,7 %. Ihr Ansatz übernimmt die Idee des mehrschichtigen CNN von LeNet, hat aber die Größe des CNN stark erhöht. Wie Sie aus dem obigen Diagramm ersehen können, ist die Eingabe nun 224×224 im Vergleich zu LeNet’s 32×32, auch haben viele Faltungskerne 192 Kanäle im Vergleich zu LeNet’s 6. Obwohl das Design nicht viel verändert wurde, hat sich die Fähigkeit des Netzwerks, komplexe Merkmale zu erfassen und darzustellen, durch die hundertfache Anzahl von Parametern ebenfalls um ein Vielfaches verbessert. Um ein so großes Modell zu trainieren, verwendete Alex zwei GTX 580-Grafikprozessoren mit jeweils 3 GB RAM, was einen neuen Trend zum GPU-Training einleitete. Auch die Verwendung der ReLU-Nichtlinearität trug dazu bei, die Berechnungskosten zu senken.
Zusätzlich zu den vielen weiteren Parametern für das Netzwerk wurde auch das Problem der Überanpassung, das ein größeres Netzwerk mit sich bringt, durch die Verwendung einer Dropout-Schicht untersucht. Seine Local Response Normalization-Methode wurde später nicht sehr populär, inspirierte aber andere wichtige Normalisierungstechniken wie BatchNorm zur Bekämpfung des Problems der Gradientensättigung. Zusammenfassend lässt sich sagen, dass AlexNet das De-facto-Klassifizierungsnetz-Framework für die nächsten 10 Jahre definiert hat: eine Kombination aus Faltung, nichtlinearer ReLu-Aktivierung, MaxPooling und dichter Schicht.
2014: VGG
Very Deep Convolutional Networks for Large-Scale Image Recognition
Mit einem so großen Erfolg der Verwendung von CNN für die visuelle Erkennung, ist die gesamte Forschungsgemeinschaft aufgeblüht und hat begonnen zu untersuchen, warum dieses neuronale Netzwerk so gut funktioniert. In „Visualizing and Understanding Convolutional Networks“ (Visualisierung und Verständnis von Faltungsnetzwerken) aus dem Jahr 2013 erörterte Matthew Zeiler beispielsweise, wie CNN Merkmale aufnimmt und die Zwischendarstellungen visualisiert. Und plötzlich begann jeder zu erkennen, dass CNN seit 2014 die Zukunft der Computer Vision ist. Unter all diesen unmittelbaren Nachfolgern ist das VGG-Netzwerk der Visual Geometry Group das auffälligste. Es erzielte ein bemerkenswertes Ergebnis von 93,2 % Top-5-Genauigkeit und 76,3 % Top-1-Genauigkeit auf dem ImageNet-Testsatz.
Nach dem Design von AlexNet hat das VGG-Netzwerk zwei wichtige Updates: 1) VGG verwendet nicht nur ein breiteres Netzwerk als AlexNet, sondern auch ein tieferes. VGG-19 hat 19 Faltungsschichten, verglichen mit 5 von AlexNet. 2) VGG hat auch gezeigt, dass ein paar kleine 3×3-Faltungsfilter einen einzelnen 7×7- oder sogar 11×11-Filter von AlexNet ersetzen können, eine bessere Leistung erzielen und gleichzeitig die Rechenkosten senken. Aufgrund dieses eleganten Designs wurde VGG auch zum Backbone-Netzwerk vieler bahnbrechender Netzwerke für andere Computer-Vision-Aufgaben, wie z.B. FCN für semantische Segmentierung und Faster R-CNN für die Objekterkennung.
Mit einem tieferen Netzwerk wird das Verschwinden des Gradienten aus der mehrschichtigen Backpropagation zu einem größeren Problem. Um damit umzugehen, hat die VGG auch die Bedeutung des Pre-Trainings und der Gewichtsinitialisierung diskutiert. Dieses Problem zwingt die Forscher dazu, immer mehr Schichten hinzuzufügen, da das Netz sonst nur schwer konvergieren kann. Aber wir werden in zwei Jahren eine bessere Lösung für dieses Problem sehen.
2014: GoogLeNet
Going Deeper with Convolutions

VGG hat eine gut aussehende und leicht verständliche Struktur, aber seine Leistung ist nicht die beste unter allen Finalisten des ImageNet-Wettbewerbs 2014. GoogLeNet, auch bekannt als InceptionV1, hat den letzten Preis gewonnen. Genau wie VGG besteht einer der Hauptbeiträge von GoogLeNet darin, die Grenzen der Netzwerktiefe mit einer Struktur von 22 Schichten zu erweitern. Im Gegensatz zu VGG hat GoogLeNet versucht, die Probleme der Berechnung und der Verringerung des Gradienten direkt anzugehen, anstatt eine Umgehung mit einem besseren vortrainierten Schema und der Initialisierung der Gewichte vorzuschlagen.

Zunächst wurde die Idee des asymmetrischen Netzwerkdesigns mit Hilfe eines Moduls namens Inception (siehe Diagramm oben) untersucht. Idealerweise würden sie gerne spärliche Faltungsschichten oder dichte Schichten verfolgen, um die Effizienz der Funktionen zu verbessern, aber das moderne Hardware-Design war nicht auf diesen Fall zugeschnitten. Daher glaubten sie, dass eine dünne Schicht auf der Ebene der Netzwerktopologie auch bei der Fusion von Merkmalen helfen könnte, während die vorhandenen Hardwarekapazitäten genutzt werden.
Zweitens wird das Problem der hohen Rechenkosten angegangen, indem eine Idee aus einem Papier namens „Network in Network“ übernommen wird. Im Grunde genommen wird ein 1×1-Faltungsfilter eingeführt, um die Dimensionen der Merkmale zu reduzieren, bevor ein rechenintensiver Vorgang wie ein 5×5-Faltungskernel durchgeführt wird. Diese Struktur wird später „Bottleneck“ genannt und in vielen folgenden Netzwerken verwendet. Ähnlich wie bei „Network in Network“ wurde auch hier eine durchschnittliche Pooling-Schicht verwendet, um die letzte voll verknüpfte Schicht zu ersetzen und so die Kosten weiter zu senken.
Drittes, um den Gradienten zu helfen, zu tieferen Schichten zu fließen, verwendete GoogLeNet auch die Überwachung einiger Zwischenschichtausgaben oder Hilfsausgaben. Dieses Design ist später im Bildklassifizierungsnetzwerk wegen der Komplexität nicht sehr beliebt, wird aber in anderen Bereichen der Computer Vision immer beliebter, wie z.B. das Sanduhr-Netzwerk bei der Posenschätzung.
Als Nachbereitung schrieb das Google-Team weitere Arbeiten für diese Inception-Serie. „Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift“ steht für InceptionV2. „Rethinking the Inception Architecture for Computer Vision“ von 2015 steht für InceptionV3. Und „Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning“ aus dem Jahr 2015 steht für InceptionV4. Jede Arbeit brachte weitere Verbesserungen gegenüber dem ursprünglichen Inception-Netzwerk und erzielte bessere Ergebnisse.
2015: Batch Normalization
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Das Inception-Netzwerk half den Forschern, eine übermenschliche Genauigkeit auf dem ImageNet-Datensatz zu erreichen. Als statistische Lernmethode ist CNN jedoch sehr stark an die statistische Natur eines bestimmten Trainingsdatensatzes gebunden. Um eine bessere Genauigkeit zu erreichen, müssen wir daher in der Regel den Mittelwert und die Standardabweichung des gesamten Datensatzes im Voraus berechnen und diese zur Normalisierung unserer Eingaben verwenden, um sicherzustellen, dass die meisten Eingaben der Schichten im Netzwerk nahe beieinander liegen, was sich in einer besseren Reaktionsfähigkeit bei der Aktivierung niederschlägt. Dieser ungefähre Ansatz ist sehr mühsam und funktioniert manchmal bei einer neuen Netzwerkstruktur oder einem neuen Datensatz überhaupt nicht, so dass das Deep-Learning-Modell immer noch als schwierig zu trainieren gilt. Um dieses Problem anzugehen, haben Sergey Ioffe und Chritian Szegedy, der Erfinder von GoogLeNet, beschlossen, etwas Intelligenteres zu erfinden, das sie Batch Normalization nennen.

Die Idee der Batch-Normalisierung ist nicht schwer: Wir können die Statistiken einer Reihe von Mini-Batches verwenden, um die Statistiken des gesamten Datensatzes zu approximieren, solange wir lange genug trainieren. Anstatt die Statistiken manuell zu berechnen, können wir auch zwei weitere lernbare Parameter „scale“ und „shift“ einführen, damit das Netzwerk lernt, wie es jede Schicht selbst normalisieren kann.
Das obige Diagramm zeigt den Prozess der Berechnung von Batch-Normalisierungswerten. Wie wir sehen können, nehmen wir den Mittelwert des gesamten Mini-Batch und berechnen auch die Varianz. Anschließend können wir die Eingabe mit diesem Mittelwert und der Varianz der Minicharge normalisieren. Mit einem Skalierungs- und einem Verschiebungsparameter lernt das Netz schließlich, das stapelweise normalisierte Ergebnis so anzupassen, dass es am besten zu den folgenden Schichten passt, in der Regel zu ReLU. Eine Einschränkung besteht darin, dass wir während der Inferenz keine Mini-Chargen-Informationen haben. Eine Umgehung besteht daher darin, während des Trainings einen gleitenden Mittelwert und eine gleitende Varianz zu berechnen und diese gleitenden Mittelwerte dann im Inferenzpfad zu verwenden. Diese kleine Neuerung ist so wirkungsvoll, dass alle späteren Netze sofort damit beginnen, sie zu verwenden.
2015: ResNet
Deep Residual Learning for Image Recognition
2015 könnte das beste Jahr für Computer Vision seit einem Jahrzehnt sein, wir haben so viele großartige Ideen gesehen, die nicht nur in der Bildklassifizierung, sondern in allen Arten von Computer Vision Aufgaben wie Objekterkennung, semantische Segmentierung usw. auftauchen. Der größte Fortschritt des Jahres 2015 ist ein neues Netzwerk namens ResNet (Residual Networks), das von einer Gruppe chinesischer Forscher von Microsoft Research Asia vorgeschlagen wurde.

Wie wir bereits für das VGG-Netz besprochen haben, ist die größte Hürde, noch tiefer zu gehen, das Problem des Verschwindens des Gradienten, d. h..d. h., die Ableitungen werden immer kleiner, wenn sie durch tiefere Schichten zurückverfolgt werden, und erreichen schließlich einen Punkt, den die moderne Computerarchitektur nicht mehr sinnvoll darstellen kann. GoogLeNet hat versucht, dieses Problem durch den Einsatz von Hilfsüberwachungen und asymmetrischen Inception-Modulen zu lösen, aber es lindert das Problem nur zu einem kleinen Teil. Wenn wir 50 oder sogar 100 Schichten verwenden wollen, gibt es dann einen besseren Weg für den Fluss des Gradienten durch das Netz? Die Antwort von ResNet lautet, ein Restmodul zu verwenden.

ResNet fügte eine Identitätsverknüpfung zur Ausgabe hinzu, so dass jedes Residualmodul zumindest vorhersagen kann, was die Eingabe ist, ohne sich in der Wildnis zu verlieren. Noch wichtiger ist, dass das Residualmodul versucht, den Unterschied zwischen Output und Input zu lernen, anstatt zu hoffen, dass jede Schicht direkt auf die gewünschte Merkmalszuordnung passt, was die Aufgabe viel einfacher macht, weil der erforderliche Informationsgewinn geringer ist. Stellen Sie sich vor, Sie lernen Mathematik. Für jedes neue Problem erhalten Sie die Lösung eines ähnlichen Problems, und alles, was Sie tun müssen, ist, diese Lösung zu erweitern und zu versuchen, dass sie funktioniert. Das ist viel einfacher, als für jedes Problem, auf das man stößt, eine ganz neue Lösung zu finden. Oder wie Newton sagte: Wir können auf den Schultern von Riesen stehen, und die Identitätseingabe ist dieser Riese für das ResNet-Modul.
Neben der Identitätszuordnung hat ResNet auch den Engpass und die Batch-Normalisierung von Inception-Netzwerken übernommen. Schließlich gelang es, ein Netzwerk mit 152 Faltungsschichten aufzubauen und eine Top-1-Genauigkeit von 80,72 % im ImageNet zu erreichen. Der Residualansatz wurde später auch zur Standardoption für viele andere Netzwerke, wie Xception, Darknet usw. Dank seines einfachen und schönen Designs wird es auch heute noch in vielen visuellen Erkennungssystemen eingesetzt.
Durch den Hype um das Residualnetzwerk sind viele weitere Invarianten entstanden. In „Identity Mappings in Deep Residual Networks“ hat der ursprüngliche Autor von ResNet versucht, die Aktivierung vor das Residualmodul zu setzen und ein besseres Ergebnis zu erzielen, und dieses Design wird danach ResNetV2 genannt. In einem Papier aus dem Jahr 2016 mit dem Titel „Aggregated Residual Transformations for Deep Neural Networks“ schlugen die Forscher ResNeXt vor, das parallele Verzweigungen für Residualmodule hinzufügte, um die Ausgaben verschiedener Transformationen zu aggregieren.
2016: Xception
Xception: Deep Learning with Depthwise Separable Convolutions

Mit der Veröffentlichung von ResNet sah es so aus, als ob die meisten der niedrig hängenden Früchte im Bereich der Bildklassifizierung bereits gepflückt wurden. Die Forscher begannen darüber nachzudenken, was der interne Mechanismus der Magie von CNN ist. Da die kanalübergreifende Faltung in der Regel eine Vielzahl von Parametern erfordert, entschied sich das Xception-Netzwerk für die Untersuchung dieses Vorgangs, um ein vollständiges Bild seiner Wirkung zu erhalten.
Wie der Name schon sagt, stammt Xception aus dem Inception-Netzwerk. Im Inception-Modul werden mehrere Zweige verschiedener Transformationen zusammengeführt, um eine spärliche Topologie zu erreichen. Aber warum funktioniert diese Sparsamkeit? Der Autor von Xception, der auch der Autor des Keras-Frameworks ist, hat diese Idee auf einen Extremfall ausgedehnt, bei dem eine 3×3-Faltungsdatei einem Ausgangskanal vor der endgültigen Verkettung entspricht. In diesem Fall bilden diese parallelen Faltungskerne tatsächlich eine neue Operation, die als tiefenweise Faltung bezeichnet wird.

Wie im obigen Diagramm dargestellt, Im Gegensatz zur herkömmlichen Faltung, bei der alle Kanäle in eine Berechnung einbezogen werden, wird bei der tiefenmäßigen Faltung die Faltung für jeden Kanal einzeln berechnet und die Ergebnisse dann zusammengefügt. Dadurch wird der Austausch von Merkmalen zwischen den Kanälen reduziert, aber auch eine Menge von Verbindungen, was zu einer Schicht mit weniger Parametern führt. Bei diesem Vorgang wird jedoch die gleiche Anzahl von Kanälen wie bei der Eingabe ausgegeben (oder eine geringere Anzahl von Kanälen, wenn Sie zwei oder mehr Kanäle zusammenfassen). Daher brauchen wir nach der Zusammenführung der Kanalausgänge einen weiteren regulären 1×1-Filter oder eine punktweise Faltung, um die Anzahl der Kanäle zu erhöhen oder zu verringern, genau wie bei der regulären Faltung.
Diese Idee stammt ursprünglich nicht von Xception. Sie wird in einem Papier mit dem Titel „Learning visual representations at scale“ beschrieben und gelegentlich auch in InceptionV2 verwendet. Xception ist einen Schritt weiter gegangen und hat fast alle Faltungen durch diesen neuen Typ ersetzt. Und das Ergebnis des Experiments ist ziemlich gut geworden. Es übertrifft ResNet und InceptionV3 und wurde zu einer neuen SOTA-Methode für die Bildklassifizierung. Damit wurde auch bewiesen, dass die Abbildung von kanalübergreifenden Korrelationen und räumlichen Korrelationen in CNN vollständig entkoppelt werden kann. Darüber hinaus hat Xception die gleichen Vorzüge wie ResNet und verfügt über ein einfaches und schönes Design, so dass seine Idee in vielen anderen nachfolgenden Forschungsprojekten wie MobileNet, DeepLabV3 usw. verwendet wird.
2017: MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
Xception erreichte 79 % Top-1-Genauigkeit und 94,5 % Top-5-Genauigkeit auf ImageNet, aber das sind nur 0,8 % bzw. 0,4 % Verbesserung im Vergleich zum vorherigen SOTA InceptionV3. Der marginale Gewinn eines neuen Bildklassifizierungsnetzes wird immer geringer, so dass die Forscher beginnen, ihren Schwerpunkt auf andere Bereiche zu verlagern. Und MobileNet hat die Bildklassifizierung in einer ressourcenbeschränkten Umgebung erheblich vorangetrieben.

Ähnlich wie Xception verwendete MobileNet ein gleiches, in der Tiefe separierbares Faltungsmodul wie oben gezeigt und legte den Schwerpunkt auf hohe Effizienz und weniger Parameter.
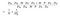
Der Zähler in der obigen Formel ist die Gesamtzahl der Parameter, die für eine tiefenweise separierbare Faltung erforderlich sind. Und der Nenner ist die Gesamtzahl der Parameter einer ähnlichen regulären Faltung. Dabei ist D die Größe des Faltungs-Kerns, D die Größe der Merkmalskarte, M die Anzahl der Eingangskanäle, N die Anzahl der Ausgangskanäle. Da wir die Berechnung des Kanals und des räumlichen Merkmals getrennt haben, können wir die Multiplikation in eine Addition umwandeln, die um eine Größenordnung kleiner ist. Je größer die Anzahl der Ausgangskanäle ist, desto mehr Berechnungen können wir mit dieser neuen Faltung einsparen.
Ein weiterer Beitrag von MobileNet ist der Multiplikator für Breite und Auflösung. Das MobileNet-Team wollte einen kanonischen Weg finden, um die Modellgröße für mobile Geräte zu verringern, und der intuitivste Weg ist, die Anzahl der Eingangs- und Ausgangskanäle sowie die Auflösung des Eingangsbildes zu reduzieren. Um dieses Verhalten zu steuern, wird das Verhältnis alpha mit den Kanälen und das Verhältnis rho mit der Eingabeauflösung multipliziert (was sich auch auf die Größe der Merkmalskarte auswirkt). Die Gesamtzahl der Parameter kann also in folgender Formel dargestellt werden:

Obwohl diese Änderung in Bezug auf Innovation naiv erscheint, hat sie einen großen technischen Wert, da die Forscher zum ersten Mal zu dem Schluss kommen, dass ein kanonischer Ansatz zur Anpassung des Netzes an verschiedene Ressourcenbeschränkungen erforderlich ist. Außerdem fasst es die ultimative Lösung zur Verbesserung des neuronalen Netzwerks zusammen: breiterer und hochauflösender Input führt zu besserer Genauigkeit, dünnerer und niedrigauflösender Input führt zu schlechterer Genauigkeit.
Später in 2018 und 2019 veröffentlichte das MobiletNet-Team auch „MobileNetV2″: Inverted Residuals and Linear Bottlenecks“ und „Searching for MobileNetV3“. In MobileNetV2 wird eine invertierte Residual Bottleneck-Struktur verwendet. Und in MobileNetV3 wurde damit begonnen, die optimale Architekturkombination mit Hilfe der Technologie der neuronalen Architektursuche zu suchen, die wir als nächstes behandeln werden.
2017: NASNet
Learning Transferable Architectures for Scalable Image Recognition
Genauso wie die Bildklassifizierung für eine ressourcenbeschränkte Umgebung ist die neuronale Architektursuche ein weiteres Feld, das 2017 entstanden ist. Mit ResNet, Inception und Xception scheinen wir eine optimale Netzwerktopologie erreicht zu haben, die Menschen verstehen und entwerfen können, aber was ist, wenn es eine bessere und viel komplexere Kombination gibt, die die menschliche Vorstellungskraft weit übersteigt? In einer Veröffentlichung aus dem Jahr 2016 mit dem Titel „Neural Architecture Search with Reinforcement Learning“ wurde eine Idee vorgeschlagen, die optimale Kombination innerhalb eines vordefinierten Suchraums mit Hilfe von Verstärkungslernen zu suchen. Wie wir wissen, ist das Verstärkungslernen eine Methode, um die beste Lösung mit einem klaren Ziel und einer Belohnung für den Suchagenten zu finden. Aufgrund der begrenzten Rechenleistung wurde in diesem Papier jedoch nur die Anwendung in einem kleinen CIFAR-Datensatz erörtert.

Mit dem Ziel, eine optimale Struktur für einen großen Datensatz wie ImageNet zu finden, hat NASNet einen Suchraum erstellt, der auf ImageNet zugeschnitten ist. Es hofft, einen speziellen Suchraum zu entwerfen, so dass das Suchergebnis auf CIFAR auch auf ImageNet gut funktionieren kann. Erstens geht NASNet davon aus, dass die üblichen handgefertigten Module in guten Netzwerken wie ResNet und Xception bei der Suche immer noch nützlich sind. Anstatt also nach zufälligen Verbindungen und Operationen zu suchen, sucht NASNet nach der Kombination dieser Module, die sich bereits in ImageNet als nützlich erwiesen haben. Zweitens wird die eigentliche Suche immer noch auf dem CIFAR-Datensatz mit 32×32-Auflösung durchgeführt, so dass NASNet nur nach Modulen sucht, die von der Eingabegröße nicht beeinflusst werden. Damit der zweite Punkt funktioniert, hat NASNet zwei Arten von Modulvorlagen vordefiniert: Reduktion und Normal. Die Reduktionszelle könnte eine reduzierte Feature-Map im Vergleich zur Eingabe haben, und für die normale Zelle wäre es das Gleiche.

Obwohl NASNet bessere Metriken als manuell entworfene Netzwerke aufweist, leidet es auch unter einigen Nachteilen. Die Kosten für die Suche nach einer optimalen Struktur sind sehr hoch, was sich nur große Unternehmen wie Google und Facebook leisten können. Außerdem macht die endgültige Struktur für Menschen nicht viel Sinn und ist daher in einer Produktionsumgebung schwieriger zu pflegen und zu verbessern. Später im Jahr 2018 wird „MnasNet: Platform-Aware Neural Architecture Search for Mobile“ diese NASNet-Idee weiter aus, indem der Suchschritt durch eine vordefinierte verkettete Blockstruktur begrenzt wird. Durch die Definition eines Gewichtungsfaktors bietet mNASNet außerdem eine systematischere Möglichkeit, ein Modell unter bestimmten Ressourcenbeschränkungen zu suchen, anstatt es nur auf der Grundlage von FLOPs zu bewerten.
2019: EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Im Jahr 2019 sieht es so aus, als gäbe es keine spannenden Ideen mehr für überwachte Bildklassifikation mit CNN. Eine drastische Änderung der Netzwerkstruktur bringt in der Regel nur eine geringe Verbesserung der Genauigkeit. Noch schlimmer ist, dass bei der Anwendung desselben Netzwerks auf verschiedene Datensätze und Aufgaben die zuvor behaupteten Tricks nicht zu funktionieren scheinen, was zu der Kritik führte, dass diese Verbesserungen auf dem ImageNet-Datensatz nur eine Überanpassung darstellen. Auf der anderen Seite gibt es einen Trick, der immer funktioniert: die Verwendung von höher aufgelöstem Input, das Hinzufügen von mehr Kanälen für Faltungsschichten und das Hinzufügen weiterer Schichten. Obwohl dies sehr brutal ist, scheint es einen prinzipiellen Weg zu geben, das Netzwerk bei Bedarf zu skalieren. MobileNetV1 schlug dies 2017 in gewisser Weise vor, aber der Fokus wurde später auf ein besseres Netzwerkdesign verlagert.

Nach NASNet und mNASNet wurde den Forschern klar, dass eine Änderung der Architektur selbst mit Hilfe eines Computers keinen großen Nutzen bringt. Also greifen sie auf die Skalierung des Netzwerks zurück. EfficientNet baut genau auf dieser Annahme auf. Einerseits verwendet es den optimalen Baustein von mNASNet, um eine gute Grundlage für den Start zu schaffen. Andererseits definiert es drei Parameter alpha, beta und rho, um die Tiefe, Breite und Auflösung des Netzwerks entsprechend zu steuern. Auf diese Weise können sich Ingenieure auch ohne einen großen GPU-Pool für die Suche nach einer optimalen Struktur auf diese prinzipiellen Parameter stützen, um das Netz auf ihre unterschiedlichen Anforderungen abzustimmen. Am Ende lieferte EfficientNet 8 verschiedene Varianten mit unterschiedlichen Breiten-, Tiefen- und Auflösungsverhältnissen und erzielte sowohl für kleine als auch für große Modelle eine gute Leistung. Mit anderen Worten: Wenn Sie eine hohe Genauigkeit wünschen, wählen Sie ein EfficientNet-B7 mit 600×600 und 66M Parametern. Wenn Sie eine niedrige Latenz und ein kleineres Modell wünschen, wählen Sie ein EfficientNet-B0 mit 224×224 und 5,3M Parametern. Problem gelöst.
Wenn Sie die obigen 10 Arbeiten gelesen haben, sollten Sie einen ziemlich guten Überblick über die Geschichte der Bildklassifizierung mit CNN haben. Wenn Sie sich in diesem Bereich weiterbilden möchten, habe ich auch einige andere interessante Arbeiten aufgelistet. Obwohl sie nicht in der Top-10-Liste enthalten sind, sind diese Arbeiten alle in ihrem Bereich berühmt und haben viele andere Forscher in der Welt inspiriert.
2014: SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPPNet leiht sich die Idee der Merkmalspyramide aus der traditionellen Computer Vision Merkmalsextraktion. Diese Pyramide bildet eine Tasche von Wörtern mit Merkmalen in verschiedenen Maßstäben, so dass sie sich an verschiedene Eingabegrößen anpassen kann und die voll verbundene Schicht mit fester Größe überflüssig macht. Diese Idee inspirierte auch das ASPP-Modul von DeepLab und FPN für die Objekterkennung.
2016: DenseNet
Densely Connected Convolutional Networks
DenseNet von Cornell erweitert die Idee von ResNet weiter. Es bietet nicht nur Sprungverbindungen zwischen den Schichten, sondern hat auch Sprungverbindungen von allen vorherigen Schichten.
2017: SENet
Squeeze-and-Excitation Networks
Das Xception-Netzwerk zeigte, dass kanalübergreifende Korrelation nicht viel mit räumlicher Korrelation zu tun hat. SENet, der Sieger des letzten ImageNet-Wettbewerbs, hat jedoch einen Squeeze-and-Excitation-Block entwickelt und eine andere Geschichte erzählt. Der SE-Block komprimiert zunächst alle Kanäle durch globales Pooling auf eine geringere Anzahl von Kanälen, wendet dann eine voll verknüpfte Transformation an und „erregt“ sie anschließend durch eine weitere voll verknüpfte Schicht wieder auf die ursprüngliche Anzahl von Kanälen. Im Wesentlichen half die FC-Schicht dem Netzwerk also dabei, die Aufmerksamkeit auf die Eingabe-Merkmalskarte zu lenken.
2017: ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Aufgebaut auf dem Inverted Bottleneck-Modul von MobileNetV2, ist ShuffleNet der Ansicht, dass die punktweise Faltung in der tiefenweise trennbaren Faltung Genauigkeit im Austausch für weniger Berechnungen opfert. Um dies zu kompensieren, fügte ShuffleNet eine zusätzliche Kanalverschiebungsoperation hinzu, um sicherzustellen, dass die punktweise Faltung nicht immer auf denselben „Punkt“ angewendet wird. Und in ShuffleNetV2 wird dieser Channel-Shuffling-Mechanismus auch auf einen ResNet-Identitäts-Mapping-Zweig ausgeweitet, so dass ein Teil des Identitätsmerkmals auch zum Shuffle verwendet wird.
2018: Bag of Tricks
Bag of Tricks for Image Classification with Convolutional Neural Networks
Bag of Tricks konzentriert sich auf gängige Tricks, die im Bereich der Bildklassifikation verwendet werden. Sie dient als gutes Nachschlagewerk für Ingenieure, wenn sie die Leistung von Benchmarks verbessern müssen. Interessanterweise können diese Tricks, wie z.B. Mixup-Augmentation und Cosinus-Lernrate, manchmal eine weitaus bessere Verbesserung erzielen als eine neue Netzwerkarchitektur.
Schlussfolgerung
Mit der Veröffentlichung von EfficientNet sieht es so aus, als ob der ImageNet-Klassifizierungsbenchmark zu einem Ende kommt. Mit dem bestehenden Deep-Learning-Ansatz werden wir niemals 99,999 % Genauigkeit im ImageNet erreichen, es sei denn, es findet ein weiterer Paradigmenwechsel statt. Daher befassen sich Forscher aktiv mit neuen Bereichen wie dem selbstüberwachten oder halbüberwachten Lernen für die visuelle Erkennung in großem Maßstab. In der Zwischenzeit ist es mit den bestehenden Methoden eher eine Frage für Ingenieure und Unternehmer, die reale Anwendung dieser nicht perfekten Technologie zu finden. In Zukunft werde ich auch einen Überblick über die realen Bildverarbeitungsanwendungen auf der Grundlage der Bildklassifizierung verfassen, bleiben Sie also dran! Wenn Sie denken, dass es auch andere wichtige Arbeiten zur Bildklassifizierung gibt, hinterlassen Sie bitte einen Kommentar und lassen Sie es uns wissen.
Ursprünglich veröffentlicht unter http://yanjia.li am 31. Juli 2020
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based Learning Applied to Document Recognition
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
- Sergey Ioffe, Christian Szegedy, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition
- François Chollet, Xception: Deep Learning with Depthwise Separable Convolutions
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
- Mingxing Tan, Quoc V. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Connected Convolutional Networks
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Bag of Tricks for Image Classification with Convolutional Neural Networks