
Die Ressourcenzuweisung ist ein wichtiger Aspekt bei der Ausführung eines Spark-Jobs. Wenn ein Spark-Job nicht richtig konfiguriert ist, kann er die gesamten Cluster-Ressourcen verbrauchen und andere Anwendungen in einen Ressourcenmangel stürzen.
Dieser Blog hilft, den grundlegenden Ablauf in einer Spark-Anwendung zu verstehen und dann die Anzahl der Executors, die Speichereinstellungen der einzelnen Executors und die Anzahl der Kerne für einen Spark-Job zu konfigurieren. Es gibt einige Faktoren, die wir berücksichtigen müssen, um die optimalen Zahlen für die oben genannten drei zu bestimmen, wie:
- Die Datenmenge
- Die Zeit, in der ein Job abgeschlossen werden muss
- Statische oder dynamische Ressourcenzuweisung
- Upstream- oder Downstream-Anwendung
- Einführung
- Schritte im Clustermodus für einen Spark-Job
- Statische Zuweisung
- Fall 1 Hardware – 6 Knoten und jeder Knoten hat 16 Kerne, 64 GB RAM
- Fall 2 Hardware – 6 Nodes und jeder Node haben 32 Cores, 64 GB
- Fall 3 – Wenn mehr Speicher für die Executors nicht erforderlich ist
- Zusammenfassungstabelle
- Dynamische Zuweisung
Einführung
Fangen wir mit einigen grundlegenden Definitionen der Begriffe an, die bei der Handhabung von Spark-Anwendungen verwendet werden.
Partitionen : Eine Partition ist ein kleiner Teil eines großen verteilten Datensatzes. Spark verwaltet Daten mit Hilfe von Partitionen, die die Parallelisierung der Datenverarbeitung mit minimaler Datenverschiebung zwischen den Executors unterstützen.
Task : Eine Aufgabe ist eine Arbeitseinheit, die auf einer Partition eines verteilten Datensatzes ausgeführt werden kann und auf einem einzelnen Executor ausgeführt wird. Alle Aufgaben innerhalb einer einzelnen Stufe können parallel ausgeführt werden.
Executor : Ein Executor ist ein einzelner JVM-Prozess, der für eine Anwendung auf einem Worker-Knoten gestartet wird. Executor führt Aufgaben aus und hält Daten im Speicher oder auf der Festplatte über sie. Jede Anwendung hat ihre eigenen Executors. Ein einzelner Knoten kann mehrere Executors ausführen und Executors für eine Anwendung können sich über mehrere Worker Nodes erstrecken. Ein Executor bleibt für die
Dauer der Spark-Anwendung aktiv und führt die Aufgaben in mehreren Threads aus. Die Anzahl der Executors für eine Spark-Anwendung kann in der SparkConf oder über das Flag -num-executors in der Befehlszeile angegeben werden.
Cluster-Manager : Ein externer Dienst für den Erwerb von Ressourcen im Cluster (z. B. eigenständiger Manager, Mesos, YARN). Spark ist unabhängig von einem Cluster-Manager, solange es Executor-Prozesse erwerben kann und diese miteinander kommunizieren können.Wir sind in erster Linie an Yarn als Cluster-Manager interessiert. Ein Spark-Cluster kann entweder im Yarn-Cluster- oder im Yarn-Client-Modus laufen:
Yarn-Client-Modus – Ein Treiber läuft auf einem Client-Prozess, der Application Master wird nur für die Anforderung von Ressourcen von YARN verwendet.
Yarn-Cluster-Modus – Ein Treiber läuft innerhalb des Application Master-Prozesses, der Client verschwindet, sobald die Anwendung initialisiert ist
Cores : Ein Kern ist eine grundlegende Recheneinheit der CPU und eine CPU kann einen oder mehrere Kerne haben, um Aufgaben zu einem bestimmten Zeitpunkt auszuführen. Je mehr Kerne wir haben, desto mehr Arbeit können wir erledigen. In Spark steuert dies die Anzahl der parallelen Aufgaben, die ein Executor ausführen kann.
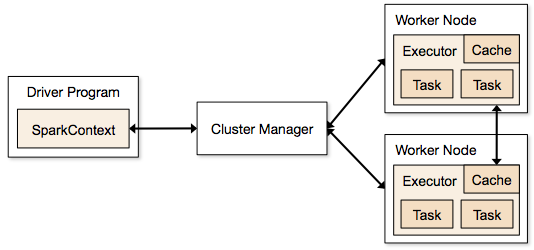
Schritte im Clustermodus für einen Spark-Job
- Vom Treibercode aus verbindet sich SparkContext mit dem Clustermanager (Standalone/Mesos/YARN).
- Der Clustermanager weist den anderen Anwendungen Ressourcen zu. Jeder Clustermanager kann verwendet werden, solange die Executor-Prozesse laufen und miteinander kommunizieren.
- Spark erwirbt Executors auf Knoten im Cluster. Hier erhält jede Anwendung ihre eigenen Executor-Prozesse.
- Anwendungscode (jar/python-Dateien/python egg-Dateien) wird an Executors gesendet
- Aufgaben werden von SparkContext an die Executors gesendet.
Aus den obigen Schritten wird deutlich, dass die Anzahl der Executors und deren Speichereinstellung eine große Rolle bei einem Spark-Job spielen. Die Ausführung von Executors mit zu viel Speicher führt oft zu übermäßigen Verzögerungen bei der Garbage Collection
Nun versuchen wir zu verstehen, wie man den besten Satz von Werten konfiguriert, um einen Spark-Job zu optimieren.
Es gibt zwei Möglichkeiten, wie wir die Executor- und Core-Details für den Spark-Job konfigurieren. Diese sind:
- Statische Zuweisung – Die Werte werden als Teil von spark-submit angegeben
- Dynamische Zuweisung – Die Werte werden je nach Anforderung (Größe der Daten, Menge der benötigten Berechnungen) ausgewählt und nach der Verwendung freigegeben. Auf diese Weise können die Ressourcen für andere Anwendungen wiederverwendet werden.
Statische Zuweisung
Es werden verschiedene Fälle erörtert, in denen unterschiedliche Parameter variiert werden und je nach Benutzer-/Datenanforderungen unterschiedliche Kombinationen erzielt werden.
Fall 1 Hardware – 6 Knoten und jeder Knoten hat 16 Kerne, 64 GB RAM
Zunächst wird auf jedem Knoten 1 Kern und 1 GB für das Betriebssystem und die Hadoop-Dämonen benötigt, also haben wir 15 Kerne, 63 GB RAM für jeden Knoten
Wir beginnen damit, wie wir die Anzahl der Kerne auswählen:
Anzahl der Kerne = Gleichzeitige Aufgaben, die ein Executor ausführen kann
Man könnte also denken, dass mehr gleichzeitige Aufgaben für jeden Executor eine bessere Leistung bringen. Untersuchungen zeigen jedoch, dass jede Anwendung mit mehr als 5 gleichzeitigen Aufgaben zu einer schlechten Leistung führt. Der optimale Wert ist also 5.
Diese Zahl ergibt sich aus der Fähigkeit eines Executors, parallele Aufgaben auszuführen, und nicht daraus, wie viele Kerne ein System hat. Die Zahl 5 bleibt also gleich, auch wenn wir die doppelte Anzahl (32) von Kernen in der CPU haben
Anzahl der Executors:
Wir kommen zum nächsten Schritt, mit 5 als Kernen pro Executor und 15 als insgesamt verfügbare Kerne in einem Knoten (CPU) – wir kommen zu 3 Executors pro Knoten, was 15/5 entspricht. Wir müssen die Anzahl der Executors auf jedem Knoten berechnen und erhalten dann die Gesamtzahl für den Job.
Bei 6 Knoten und 3 Executors pro Knoten erhalten wir also insgesamt 18 Executors. Von den 18 benötigen wir 1 Executor (Java-Prozess) für Application Master in YARN. Die endgültige Zahl ist also 17 Executors
Diese 17 ist die Zahl, die wir Spark mit -num-executors beim Ausführen des Shell-Befehls spark-submit geben
Speicher für jeden Executor:
Aus dem obigen Schritt ergeben sich 3 Executors pro Knoten. Und der verfügbare RAM auf jedem Knoten beträgt 63 GB
Der Speicher für jeden Executor in jedem Knoten beträgt also 63/3 = 21 GB.
Ein kleiner Overhead-Speicher wird jedoch auch benötigt, um die vollständige Speicheranforderung an YARN für jeden Executor zu bestimmen.
Die Formel für diesen Overhead ist max(384, .07 * spark.executor.memory)
Berechnen Sie diesen Overhead: .07 * 21 (Hier wird 21 wie oben 63/3 berechnet) = 1.47
Da 1.47 GB > 384 MB, ist der Overhead 1.47
Nehmen Sie die oben von jeder 21 oben => 21 – 1.47 ~ 19 GB
So Executor-Speicher – 19 GB
Endgültige Zahlen – Executors – 17, Cores 5, Executor-Speicher – 19 GB
Fall 2 Hardware – 6 Nodes und jeder Node haben 32 Cores, 64 GB
Anzahl der Cores von 5 ist gleich für gute Gleichzeitigkeit wie oben erklärt.
Anzahl der Executors für jeden Knoten = 32/5 ~ 6
So insgesamt Executors = 6 * 6 Knoten = 36. Dann ist die endgültige Zahl 36 – 1 (für AM) = 35
Executor-Speicher:
6 Executors für jeden Knoten. 63/6 ~ 10. Der Overhead beträgt 0,07 * 10 = 700 MB. Aufgerundet auf 1 GB als Overhead erhalten wir 10-1 = 9 GB
Endgültige Zahlen – Executors – 35, Cores 5, Executor-Speicher – 9 GB
Fall 3 – Wenn mehr Speicher für die Executors nicht erforderlich ist
Die obigen Szenarien beginnen damit, dass die Anzahl der Cores als feststehend angenommen wird, und gehen dann zur Anzahl der Executors und des Speichers über.
Wenn wir nun für den ersten Fall annehmen, dass wir keine 19 GB benötigen und 10 GB aufgrund der Datengröße und der beteiligten Berechnungen ausreichen, dann lauten die Zahlen wie folgt:
Kerne: 5
Anzahl der Executors für jeden Knoten = 3. Immer noch 15/5 wie oben berechnet.
In diesem Stadium würde dies zu 21 GB führen, und dann zu 19 wie in unserer ersten Berechnung. Aber da wir dachten, dass 10 in Ordnung ist (wir gehen von einem geringen Overhead aus), können wir die Anzahl der Executors pro Knoten nicht auf 6 (wie 63/10) ändern. Denn mit 6 Executors pro Knoten und 5 Kernen kommen wir auf 30 Kerne pro Knoten, obwohl wir nur 16 Kerne haben. Wir müssen also auch die Anzahl der Kerne für jeden Executor ändern.
Wir rechnen also erneut,
Die magische Zahl 5 ergibt 3 (jede Zahl kleiner oder gleich 5). Mit 3 Kernen und 15 verfügbaren Kernen erhalten wir also 5 Executors pro Knoten, 29 Executors (das ist (5*6 -1)) und Speicher ist 63/5 ~ 12.
Overhead ist 12*.07=.84. Also ist der Executor-Speicher 12 – 1 GB = 11 GB
Endgültige Zahlen sind 29 Executors, 3 Cores, Executor-Speicher ist 11 GB
Zusammenfassungstabelle
Dynamische Zuweisung
Anmerkung: Obere Grenze für die Anzahl der Executors, wenn dynamische Zuweisung aktiviert ist, ist unendlich. Dies bedeutet, dass eine Funkenanwendung bei Bedarf alle Ressourcen verbrauchen kann. In einem Cluster, in dem andere Anwendungen laufen, die ebenfalls Kerne zur Ausführung der Aufgaben benötigen, müssen wir sicherstellen, dass wir die Kerne auf Clusterebene zuweisen.
Das bedeutet, dass wir eine bestimmte Anzahl von Kernen für YARN-basierte Anwendungen basierend auf dem Benutzerzugriff zuweisen können. Wir können also einen spark_user erstellen und dann Cores (min/max) für diesen Benutzer zuweisen. Diese Grenzen sind für die gemeinsame Nutzung von spark und anderen Anwendungen, die auf YARN laufen.
Um die dynamische Zuweisung zu verstehen, müssen wir die folgenden Eigenschaften kennen:
spark.dynamicAllocation.enabled – wenn dies auf true gesetzt ist, müssen wir keine Executors erwähnen. Der Grund ist folgender:
Die statischen Parameterzahlen, die wir bei spark-submit angeben, gelten für die gesamte Auftragsdauer. Wenn jedoch eine dynamische Zuweisung ins Spiel kommt, gäbe es verschiedene Stufen wie die folgenden:
Welche Anzahl von Executors soll zu Beginn verwendet werden:
Anfangsanzahl von Executors (spark.dynamicAllocation.initialExecutors) zu Beginn
Die Anzahl der Executors wird dynamisch gesteuert:
Dann wird auf der Grundlage der Last (ausstehende Aufgaben) festgelegt, wie viele Executors angefordert werden sollen. Dies wäre letztendlich die Anzahl, die wir bei spark-submit statisch angeben. Sobald also die anfängliche Anzahl der Executors festgelegt ist, gehen wir zu den Minimal- (spark.dynamicAllocation.minExecutors) und Maximalzahlen (spark.dynamicAllocation.maxExecutors) über.
Wann werden neue Executors angefordert oder die aktuellen Executors verschenkt:
Wann werden neue Executors angefordert (spark.dynamicAllocation.schedulerBacklogTimeout) – Dies bedeutet, dass für diese Dauer Aufgaben anstehen. Daher steigt die Anzahl der in jeder Runde angeforderten Executors exponentiell zur vorherigen Runde. Eine Anwendung fügt beispielsweise in der ersten Runde 1 Executor hinzu und dann 2, 4, 8 usw. Executors in den folgenden Runden. An einem bestimmten Punkt kommt die oben genannte Eigenschaft max ins Spiel.
Wann geben wir einen Executor weg, indem wir spark.dynamicAllocation.executorIdleTimeout verwenden.
Zum Schluss: Wenn wir mehr Kontrolle über die Ausführungszeit des Auftrags benötigen, würden die statischen Zahlen helfen, den Auftrag auf unerwartetes Datenvolumen zu überwachen. Bei der Umstellung auf dynamisch würden die Ressourcen im Hintergrund verwendet, und die Aufträge mit unerwartetem Datenvolumen könnten andere Anwendungen beeinträchtigen.