
Das erste, was wir verstehen müssen, ist die Natur von Variablen und wie Variablen im Design einer Studie verwendet werden, um die Studienfragen zu beantworten. In diesem Kapitel lernen Sie:
- verschiedene Arten von Variablen in quantitativen Studien,
- Probleme im Zusammenhang mit der Frage nach der Analyseeinheit.
Verstehen quantitativer Variablen
Die Wurzel des Wortes Variable ist mit dem Wort „variieren“ verwandt, was uns helfen soll zu verstehen, was Variablen sein könnten. Variablen sind Elemente, Einheiten oder Faktoren, die sich ändern (variieren) können; zum Beispiel sind die Außentemperatur, der Benzinpreis pro Gallone, das Gewicht einer Person und die Stimmung der Personen in Ihrer Großfamilie allesamt Variablen. Mit anderen Worten, sie können unter verschiedenen Bedingungen oder für verschiedene Personen unterschiedliche Werte haben.
Wir verwenden Variablen, um Merkmale oder Faktoren von Interesse zu beschreiben. Beispiele hierfür sind die Anzahl der Mitglieder in verschiedenen Haushalten, die Entfernung zu gesunden Nahrungsquellen in verschiedenen Stadtteilen, das Verhältnis zwischen Lehrkräften der Sozialarbeit und Studenten in einem BSW- oder MSW-Programm, der Anteil von Personen aus verschiedenen rassischen/ethnischen Gruppen, die inhaftiert sind, die Transportkosten für die Inanspruchnahme von Dienstleistungen eines Sozialarbeitsprogramms oder die Säuglingssterblichkeitsrate in verschiedenen Bezirken. In der Interventionsforschung der Sozialarbeit können die Variablen die Merkmale der Intervention (Intensität, Häufigkeit, Dauer) und die mit der Intervention verbundenen Ergebnisse umfassen.
Demographische Variablen. Sozialarbeiter sind oft an den so genannten demografischen Variablen interessiert. Demografische Variablen werden zur Beschreibung von Merkmalen einer Population, einer Gruppe oder einer Stichprobe der Population verwendet. Beispiele für häufig verwendete demografische Variablen sind
- Alter,
- Ethnizität,
- nationale Herkunft,
- Religionszugehörigkeit,
- Geschlecht,
- sexuelle Orientierung,
- Ehe-/Beziehungsstatus,
- Beschäftigungsstatus,
- politische Zugehörigkeit,
- geografische Lage,
- Bildungsstand und
- Einkommen.
Auf einer eher makroökonomischen Ebene umfasst die Demografie einer Gemeinschaft oder Organisation oft auch ihre Größe; Organisationen werden oft anhand ihres Gesamtbudgets gemessen.
Unabhängige und abhängige Variablen. Die Art und Weise, wie Prüfer über Studienvariablen nachdenken, hat wichtige Auswirkungen auf das Studiendesign. Die Forscher treffen Entscheidungen darüber, ob die Variablen als unabhängige oder als abhängige Variablen dienen sollen. Diese Unterscheidung ist nicht etwas, das einer Variable inhärent ist, sondern beruht darauf, wie der Prüfer die einzelnen Variablen definiert. Unabhängige Variablen sind diejenigen, die man sich als manipulierte „Input“-Variablen vorstellen kann, während die abhängigen Variablen diejenigen sind, bei denen man die Auswirkungen oder den „Output“ dieser Input-Variation beobachten würde.
Eine absichtliche Manipulation der „Input“-Variablen (der unabhängigen Variablen) ist nicht immer erforderlich. Nehmen wir das Beispiel einer in Schweden durchgeführten Studie, in der der Zusammenhang zwischen der Tatsache, Opfer von Kindesmisshandlung gewesen zu sein, und dem späteren Fernbleiben von der Schule untersucht wurde: Niemand manipulierte absichtlich, ob die Kinder Opfer von Kindesmisshandlung werden würden (Hagborg, Berglund, & Fahlke, 2017). Die Forscher stellten die Hypothese auf, dass natürlich auftretende Unterschiede in der Inputvariable (Geschichte der Kindesmisshandlung) mit systematischen Variationen in einer spezifischen Ergebnisvariable (Schulabsentismus) verbunden sein würden. In diesem Fall war die unabhängige Variable die Geschichte als Opfer von Kindesmisshandlung, und die abhängige Variable war das Ergebnis der Schulabsentismus. Mit anderen Worten: Der Forscher geht davon aus, dass die unabhängige Variable eine Veränderung der abhängigen Variable verursacht. So könnte ein Diagramm aussehen, in dem „x“ die unabhängige Variable und „y“ die abhängige Variable ist (Hinweis: Sie haben diese Bezeichnung bereits in Kapitel 3 gesehen, als wir die Logik von Ursache und Wirkung besprochen haben):

Ein weiteres Beispiel: Die Forschung zeigt, dass das Opfer von Kindesmisshandlung mit einem höheren Risiko des Substanzkonsums im Jugendalter verbunden ist (Yoon, Kobulsky, Yoon, & Kim, 2017). Die unabhängige Variable in diesem Modell wäre das Vorliegen einer Geschichte von Kindesmisshandlung. Die abhängige Variable wäre das Risiko des Substanzkonsums in der Adoleszenz. Dieses Beispiel ist sogar noch ausgefeilter, weil es den Weg spezifiziert, über den die unabhängige Variable (Kindesmisshandlung) ihre Auswirkungen auf die abhängige Variable (jugendlicher Substanzkonsum) haben könnte. Die Autoren der Studie wiesen nach, dass posttraumatischer Stress (PTS) eine Verbindung zwischen (körperlichem und sexuellem) Missbrauch in der Kindheit und Substanzkonsum in der Jugend darstellt.

Nehmen Sie sich einen Moment Zeit, um die folgende Aufgabe zu erledigen.
Typen quantitativer Variablen
Es gibt auch andere sinnvolle Möglichkeiten, über Variablen von Interesse nachzudenken. Betrachten wir verschiedene Merkmale von Variablen, die in quantitativen Forschungsstudien verwendet werden. Hier untersuchen wir quantitative Variablen als kategoriale, ordinale oder Intervallvariablen. Diese Merkmale wirken sich sowohl auf die Messung als auch auf die Datenanalyse aus.
Kategorische Variablen. Einige Variablen können Werte annehmen, die variieren, aber nicht in einer sinnvollen numerischen Weise. Stattdessen können sie in Form von möglichen Kategorien definiert werden. Diese werden logischerweise kategorische Variablen genannt. In statistischer Software und Lehrbüchern werden Variablen mit Kategorien manchmal als nominale Variablen bezeichnet. Der Begriff „nominal“ geht auf die lateinische Wurzel „nom“ zurück, die „Name“ bedeutet und nicht mit „Zahl“ verwechselt werden sollte. Nominal bedeutet bei der Beschreibung von Variablen das Gleiche wie kategorisch. Mit anderen Worten: kategoriale oder nominale Variablen werden durch die Namen oder Bezeichnungen der dargestellten Kategorien identifiziert. Die Farbe des letzten Autos, mit dem Sie gefahren sind, wäre zum Beispiel eine kategoriale Variable: blau, schwarz, silber, weiß, rot, grün, gelb oder andere sind Kategorien der Variable, die wir als Autofarbe bezeichnen könnten.
Wichtig bei kategorialen Variablen ist, dass diese Kategorien keine relevante numerische Reihenfolge oder Ordnung haben. Es gibt keinen numerischen Unterschied zwischen den verschiedenen Autofarben oder einen Unterschied zwischen den Kategorien „ja“ oder „nein“ bei der Beantwortung der Frage, ob Sie in einem blauen Auto gefahren sind. Es gibt keine implizite Reihenfolge oder Hierarchie zwischen den Kategorien „hispanisch oder lateinamerikanisch“ und „nicht hispanisch oder lateinamerikanisch“ in einer Ethnizitätsvariable; ebenso wenig gibt es eine relevante Reihenfolge für Kategorien von Variablen wie Geschlecht, das Bundesland oder die geografische Region, in der eine Person wohnt, oder ob die Wohnung einer Person Eigentum oder gemietet ist.
Wenn ein Forscher beschließt, Zahlen als Symbole für Kategorien in einer solchen Variable zu verwenden, sind die Zahlen willkürlich – jede Zahl ist im Grunde nur ein anderer, kürzerer Name für jede Kategorie. Zum Beispiel könnte die Variable Geschlecht auf folgende Weise kodiert werden, und es würde keinen Unterschied machen, solange der Code einheitlich angewendet wird.
| Kodierungsoption A | Variable Kategorien | Kodierungsoption B |
|---|---|---|
| 1 | Mann | 2 |
| 2 | Frau | 1 |
| 3 | anders als nur männlich oder weiblich | 4 |
| 4 | keine Angabe | 3 |
Rasse und ethnische Herkunft.Eine der am häufigsten untersuchten kategorialen Variablen in der Sozialarbeit und in der sozialwissenschaftlichen Forschung ist die demografische Variable, die sich auf den rassischen und/oder ethnischen Hintergrund einer Person bezieht. In vielen Studien werden die Kategorien verwendet, die in früheren Berichten des U.S. Census Bureau festgelegt wurden. Hier ist, was das U.S. Census Bureau über die beiden unterschiedlichen demographischen Variablen Rasse und Ethnizität (https://www.census.gov/mso/www/training/pdf/race-ethnicity-onepager.pdf) zu sagen hat:
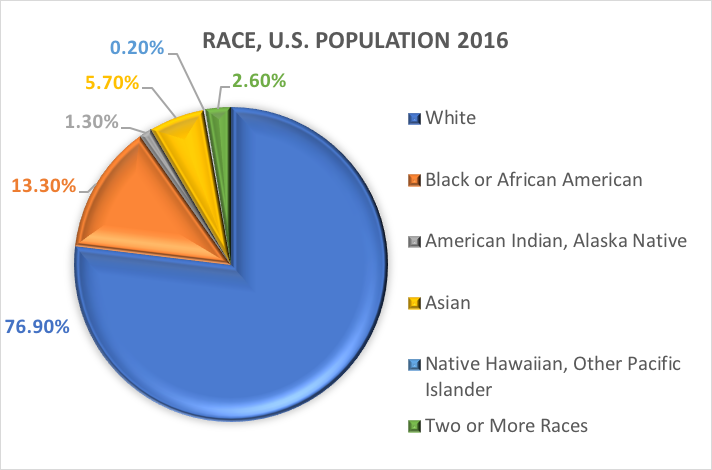
Was ist Rasse? Das Census Bureau definiert Rasse als die Selbstidentifikation einer Person mit einer oder mehreren sozialen Gruppen. Eine Person kann sich als Weißer, Schwarzer oder Afroamerikaner, Asiate, Indianer und Alaska-Ureinwohner, Ureinwohner Hawaiis und andere Pazifikinsulaner oder eine andere Rasse bezeichnen. Umfrageteilnehmer können mehrere Rassen angeben.
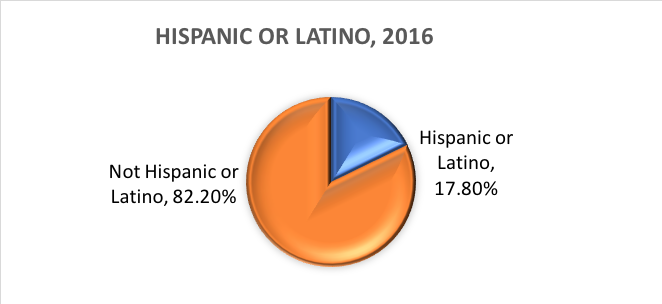
Was ist ethnische Zugehörigkeit? Die ethnische Zugehörigkeit bestimmt, ob eine Person hispanischer Herkunft ist oder nicht. Aus diesem Grund wird die ethnische Zugehörigkeit in zwei Kategorien unterteilt: Hispanisch oder Latino und Nicht-Hispanisch oder Latino. Hispanics können jede beliebige Rasse angeben.
Mit anderen Worten, das Census Bureau definiert zwei Kategorien für die Variable Ethnizität (Hispanic oder Latino und Nicht Hispanic oder Latino) und sieben Kategorien für die Variable Rasse. Diese Variablen und Kategorien werden in der sozialwissenschaftlichen und sozialarbeiterischen Forschung häufig verwendet, sind jedoch nicht unkritisch.
Auf der Grundlage dieser Kategorien wird die US-Bevölkerung im Jahr 2016 wie folgt eingeschätzt:
Dichotome Variablen.
Es gibt eine besondere Kategorie kategorischer Variablen, die Auswirkungen auf bestimmte statistische Analysen hat. Kategoriale Variablen, die aus genau zwei Möglichkeiten bestehen, nicht mehr und nicht weniger, werden als dichotome Variablen bezeichnet. Ein Beispiel dafür ist die vom U.S. Census Bureau vorgenommene Dichotomie von Hispanic/Latino und Non-Hispanic/Non-Latino Ethnizität. Ein anderes Beispiel ist der Vergleich von Personen, die eine Behandlung abschließen, mit Personen, die die Behandlung vorzeitig abbrechen. Mit den beiden Kategorien „abgeschlossen“ und „nicht abgeschlossen“ ist diese Variable zum Abschluss der Behandlung nicht nur kategorisch, sondern auch dichotomisch. Variablen, bei denen Personen mit „ja“ oder „nein“ antworten, sind ebenfalls dichotom.
Die bisherige Tradition, das Geschlecht entweder als männlich oder weiblich zu behandeln, ist ein weiteres Beispiel für eine dichotome Variable. Es gibt jedoch sehr starke Argumente dafür, Geschlecht nicht mehr in dieser dichotomen Weise zu behandeln: Eine größere Vielfalt von Geschlechtsidentitäten ist in der Sozialen Arbeit nachweislich für Personen relevant, deren Identität nicht mit den dichotomen (auch binären) Kategorien Mann/Frau oder männlich/weiblich übereinstimmt. Dazu gehören Kategorien wie agender, androgyn, bigender, cisgender, gender expansive, gender fluid, gender questioning, queer, transgender und andere.
Ordinale Variablen. Im Gegensatz zu diesen kategorialen Variablen haben die Kategorien einer Variable manchmal eine logische numerische Reihenfolge. Ordinal bezieht sich per Definition auf eine Position in einer Reihe. Variablen mit numerisch relevanten Kategorien werden als ordinale Variablen bezeichnet. Zum Beispiel gibt es eine implizite Reihenfolge der Kategorien vom geringsten bis zum höchsten bei der Variable mit der Bezeichnung Bildungsniveau. Die Kategorien der U.S. Census-Datenkategorien für diese ordinale Variable sind:
- keine
- 1. bis 4. Klasse
- 5. bis 6. Klasse
- 7. bis 8. Klasse
- 9. Klasse
- 10, kein Abschluss
- Absolventen mit Hochschulabschluss, Berufsabschluss
- Associate’s degree academic
- Bachelor’s degree
- Master’s degree
- professional degree
- doctoral degree
Bei der Betrachtung der Schätzdaten des Census Bureau für diese Variable aus dem Jahr 2016 können wir sehen, dass die Frauen in der Kategorie „Bachelor’s degree“ mehr als die Männer sind: Von den 47.718.000 Personen in dieser Kategorie waren 22.485.000 männlich und 25.234.000 weiblich. Während sich dieses geschlechtsspezifische Muster bei den Personen mit einem Master-Abschluss fortsetzte, kehrte sich das Muster bei den Personen mit einem Doktortitel um: mehr Männer als Frauen erwarben diesen höchsten Bildungsgrad. Interessant ist auch, dass es am unteren Ende des Spektrums mehr Frauen als Männer gab: 441.000 Frauen gaben an, keine Ausbildung zu haben, verglichen mit 374.000 Männern.
Hier ist ein weiteres Beispiel für die Verwendung von Ordinalvariablen in der Sozialarbeitsforschung: Wenn sich Personen wegen eines Problems mit Alkoholmissbrauch in Behandlung begeben, möchten die Sozialarbeiter vielleicht wissen, ob dies ihr erster, zweiter, dritter oder wie auch immer genannter ernsthafter Versuch ist, ihr Trinkverhalten zu ändern. Die Teilnehmer einer Studie zum Vergleich von Behandlungsansätzen für Alkoholkonsumstörungen gaben an, dass die Interventionsstudie ihr erster bis elfter ernsthafter Veränderungsversuch war (Begun, Berger, Salm-Ward, 2011). Diese Variable der Veränderungsversuche hat Auswirkungen darauf, wie Sozialarbeiter Daten zur Bewertung einer Intervention interpretieren können, die nicht für alle Beteiligten der erste Versuch war.
Bewertungsskalen. Betrachten wir eine andere, aber häufig verwendete Art von Ordinalvariablen: Ratingskalen. Forscher in den Bereichen Soziales, Verhalten und Sozialarbeit bitten die Studienteilnehmer häufig, eine Ratingskala anzuwenden, um ihr Wissen, ihre Einstellungen, Überzeugungen, Meinungen, Fähigkeiten oder ihr Verhalten zu beschreiben. Da die Kategorien auf einer solchen Skala in einer Reihenfolge angeordnet sind (am meisten bis am wenigsten oder am wenigsten bis am meisten), nennen wir diese Variablen Ordinalvariablen.

Beispiele sind die Bewertung der Teilnehmer:
- wie sehr sie bestimmten Aussagen zustimmen oder nicht zustimmen (überhaupt nicht bis extrem viel);
- wie oft sie bestimmte Verhaltensweisen ausüben (nie bis immer);
- wie oft sie bestimmte Verhaltensweisen ausüben (stündlich, täglich, wöchentlich, monatlich, jährlich oder seltener);
- die Qualität der Leistung einer Person (schlecht bis ausgezeichnet);
- wie zufrieden sie mit ihrer Behandlung waren (sehr unzufrieden bis sehr zufrieden)
- ihr Vertrauensniveau (sehr gering bis sehr hoch).
Intervallvariablen. Andere Variablen nehmen Werte an, die in sinnvoller numerischer Weise variieren. Aus unserer Liste der demografischen Variablen ist das Alter ein gängiges Beispiel. Der numerische Wert, der einer einzelnen Person zugewiesen wird, gibt die Anzahl der Jahre seit ihrer Geburt an (bei Kleinkindern kann der numerische Wert Tage, Wochen oder Monate seit der Geburt angeben). Hier sind die möglichen Werte für die Variable geordnet, wie bei den Ordinalvariablen, aber es wird ein großer Unterschied eingeführt: die Art der Intervalle zwischen den möglichen Werten. Bei Intervallvariablen ist der „Abstand“ zwischen benachbarten möglichen Werten gleich. In einigen statistischen Softwarepaketen und Lehrbüchern wird der Begriff „Skalenvariable“ verwendet: Dies ist genau das Gleiche wie das, was wir als Intervallvariable bezeichnen.
In der nachstehenden Grafik ist beispielsweise der Unterschied von 1 Unze zwischen dem Konsum von 1 Unze oder 2 Unzen Alkohol (Montag, Dienstag) bei dieser Person genau so groß wie der Unterschied von 1 Unze zwischen dem Konsum von 4 Unzen oder 5 Unzen (Freitag, Samstag). Wenn wir die möglichen Punkte auf der Skala grafisch darstellen würden, wären sie alle gleich weit voneinander entfernt; der Abstand zwischen zwei Punkten wird in Standardeinheiten (in diesem Beispiel Unzen) gemessen.
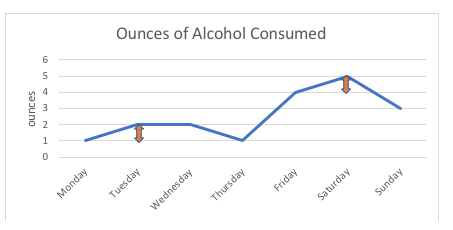
Bei Ordinalvariablen, wie z. B. einer Ratingskala, kann niemand mit Sicherheit sagen, dass der „Abstand“ zwischen den Antwortmöglichkeiten „nie“ und „manchmal“ derselbe ist wie der „Abstand“ zwischen „manchmal“ und „oft“, selbst wenn wir Zahlen für die Reihenfolge dieser Antwortmöglichkeiten verwenden. Die Ratingskala bleibt also ordinal und nicht intervallorientiert.
Was ein wenig verwirrend sein könnte, ist die Tatsache, dass bestimmte statistische Softwareprogramme wie SPSS eine Intervallvariable als „Skalenvariable“ bezeichnen. Viele Variablen, die in der Sozialforschung verwendet werden, sind sowohl geordnet als auch haben gleiche Abstände zwischen den Punkten. Nehmen wir zum Beispiel die Variable der Geburtsreihenfolge. Diese Variable ist eine Intervallvariable, weil:
- die möglichen Werte geordnet sind (z.B. das drittgeborene Kind kam nach dem erst- und zweitgeborenen und vor dem viertgeborenen), und
- die „Abstände“ oder Intervalle in äquivalenten Ein-Personen-Einheiten gemessen werden.
Kontinuierliche Variablen. Es gibt eine besondere Art von numerischen Intervallvariablen, die wir kontinuierliche Variablen nennen. Eine Variable wie das Alter kann als eine kontinuierliche Variable behandelt werden. Das Alter ist eine ordinale Variable, da höhere Zahlen im Verhältnis zu kleineren Zahlen etwas bedeuten. Das Alter erfüllt auch unsere Kriterien für eine Intervallvariable, wenn wir es in Jahren (oder Monaten oder Wochen oder Tagen) messen, da es ordinal ist und zwischen einem Alter von 15 und 30 Jahren der gleiche „Abstand“ besteht wie zwischen einem Alter von 40 und 55 Jahren (15 Kalenderjahre). Was diese Variable zu einer kontinuierlichen Variable macht, ist die Tatsache, dass es auch mögliche, sinnvolle „Bruchteile“ zwischen zwei beliebigen Intervallen gibt. Eine Person kann zum Beispiel 20½ (20,5) oder 20¼ (20,25) oder 20¾ (20,75) Jahre alt sein; wir sind nicht nur auf die ganzen Zahlen für das Alter beschränkt. Im Gegensatz dazu können wir bei der Betrachtung der Geburtsreihenfolge keinen sinnvollen Anteil einer Person zwischen zwei Positionen auf der Skala haben.
Der Sonderfall des Einkommens. Eine der am meisten missbrauchten Variablen in der sozialwissenschaftlichen und sozialarbeiterischen Forschung ist die Variable, die sich auf das Einkommen bezieht. Nehmen wir ein Beispiel über das Haushaltseinkommen (unabhängig davon, wie viele Personen im Haushalt leben). Diese Variable kann kategorisch (nominal), ordinal oder intervallartig (Skala) sein, je nachdem, wie sie behandelt wird.
Kategorisches Beispiel: Je nach Art der Forschungsfragen könnte sich ein Forscher einfach dafür entscheiden, die dichotomen Kategorien „ausreichende Mittel“ und „unzureichende Mittel“ für die Klassifizierung der Haushalte zu verwenden, die auf einer Standardberechnungsmethode basieren. Diese könnten als „arm“ und „nicht arm“ bezeichnet werden, wenn eine Armutsgrenze zur Einstufung der Haushalte verwendet wird. Diese unterschiedlichen Kategorien der Einkommensvariablen sind nicht sinnvoll numerisch geordnet, daher handelt es sich um eine kategoriale Variable.
Ordinales Beispiel: Die Kategorien zur Klassifizierung der Haushalte können von niedrig bis hoch geordnet sein. Zum Beispiel sind diese Kategorien für das Jahreseinkommen in der Marktforschung üblich:
- Weniger als 25.000 $.
- $25.000 bis $34.999.
- $35.000 bis $49.999.
- $50.000 bis $74.999.
- $75.000 bis $99.999.
- $100.000 bis $149.999.
- $150.000 bis $199.999.
- $200.000 oder mehr.
Beachten Sie, dass die Kategorien nicht gleich groß sind – der „Abstand“ zwischen den Kategoriepaaren ist nicht immer gleich. Sie beginnen in 10.000-Dollar-Schritten, gehen über in 25.000-Dollar-Schritte und enden in 50.000-Dollar-Schritten.
Intervall Beispiel. Wenn ein Untersucher die Studienteilnehmer bittet, einen tatsächlichen Dollarbetrag für das Haushaltseinkommen anzugeben, würde eine Intervallvariable entstehen. Die möglichen Werte sind geordnet, und das Intervall zwischen den möglichen benachbarten Einheiten beträgt 1 $ (sofern keine Dollarbruchteile oder Cent verwendet werden). So ist ein Einkommen von 10.452 $ auf einem Kontinuum von 9.452 $ und 11.452 $ in beiden Richtungen gleich weit entfernt.

Der Sonderfall des Alters. Wie das Einkommen kann auch das „Alter“ in verschiedenen Studien unterschiedliche Bedeutungen haben. Das Alter ist normalerweise ein Indikator für die „Zeit seit der Geburt“. Wir können das Alter einer Person berechnen, indem wir eine Variable des Geburtsdatums vom Datum der Messung abziehen (heutiges Datum minus Geburtsdatum). Bei Erwachsenen wird das Alter in der Regel in Jahren gemessen, wobei die benachbarten möglichen Werte in 1-Jahres-Einheiten voneinander entfernt sind: 18, 19, 20, 21, 22 usw. Die Altersvariable könnte also eine kontinuierliche Intervallvariable sein.
Es kann aber auch sein, dass ein Untersucher die Altersdaten in geordnete Kategorien oder Altersgruppen einteilen möchte. Diese wären zwar immer noch ordinal, aber möglicherweise nicht mehr intervallförmig, wenn die Abstufungen zwischen den möglichen Werten nicht gleichwertige Einheiten sind. Wenn wir uns zum Beispiel mehr für das Alter interessieren, das bestimmte menschliche Entwicklungsperioden repräsentiert, könnten die Altersintervalle nicht die gleiche Spannweite zwischen den Alterskriterien haben. Möglicherweise könnten sie lauten:
- Säuglingsalter (Geburt bis 18 Monate)
- Kleinkindalter (18 Monate bis 2 ½ Jahre)
- Vorschule (2 ½ bis 5 Jahre)
- Schulalter (6 bis 11 Jahre)
- Jugendalter (12 bis 17 Jahre)
- Aufstrebendes Erwachsenenalter (18 bis 25 Jahre)
- Erwachsenenalter (26 bis 45 Jahre)
- Mittleres Erwachsenenalter (46 bis 60 Jahre)
- Jung-.Alter (60 bis 74 Jahre)
- Mittleres Alter (75 bis 84 Jahre)
- Altes Alter (85 oder mehr Jahre)
Das Alter kann sogar als streng kategoriale (nicht-ordinale) Variable behandelt werden. Zum Beispiel, wenn die Variable von Interesse ist, ob jemand das gesetzliche Trinkalter (21 Jahre oder älter) erreicht hat oder nicht. Es gibt zwei Kategorien – erfüllt oder nicht erfüllt das gesetzliche Mindestalter für Alkoholkonsum in den Vereinigten Staaten – und jede von ihnen könnte mit einer „1“ und die andere entweder mit einer „0“ oder „2“ ohne Bedeutungsunterschied kodiert werden.
Was ist die „richtige“ Antwort auf die Frage, wie man das Alter (oder das Einkommen) messen kann? Die Antwort lautet: „Es kommt darauf an.“ Es kommt auf die Art der Forschungsfrage an: welche Konzeptualisierung von Alter (oder Einkommen) ist für die geplante Studie am relevantesten.
Alphanumerische Variablen. Schließlich gibt es Daten, die in keine dieser Klassifizierungen passen. Manchmal haben die uns bekannten Informationen die Form einer Adresse oder Telefonnummer, eines Vor- oder Nachnamens, einer Postleitzahl oder anderer Ausdrücke. Diese Arten von Informationen werden manchmal als alphanumerische Variablen bezeichnet. Nehmen wir zum Beispiel die Variable „Adresse“: Die Adresse einer Person kann aus numerischen Zeichen (die Hausnummer) und Buchstaben (Straße, Stadt und Bundesstaat) bestehen, z. B. 1600 Pennsylvania Ave. NW, Washington, DC, 20500.

Eigentlich sind in diesem Adressbeispiel mehrere Variablen vorhanden:
- die Straßenadresse: 1600 Pennsylvania Ave.
- die Stadt (und „Staat“): Washington, DC
- die Postleitzahl: 20500.
Diese Art von Informationen stellt keine spezifischen quantitativen Kategorien oder Werte mit systematischer Bedeutung in den Daten dar. In bestimmten Softwarepaketen werden sie manchmal auch als „String“-Variablen bezeichnet, da sie aus einer Reihe von Symbolen bestehen. Um für einen Forscher von Nutzen zu sein, müsste eine solche Variable in sinnvolle Werte umgewandelt oder umcodiert werden.
Ein Hinweis zu Analyseeinheiten
Eine wichtige Sache, die man bei der Betrachtung von Variablen im Auge behalten sollte, ist, dass Daten auf vielen verschiedenen Beobachtungsebenen gesammelt werden können. Bei den untersuchten Elementen kann es sich um einzelne Zellen, Organsysteme oder Personen handeln. Oder die Beobachtungsebene sind Paare von Individuen, z. B. Paare, Brüder und Schwestern oder Eltern-Kind-Doppel. In diesem Fall kann der Forscher Informationen über das Paar von jedem einzelnen Individuum sammeln, aber er betrachtet die Daten jedes Paares. Wir würden also sagen, dass die Analyseeinheit das Paar oder die Dyade ist, nicht jede einzelne Person. Die Analyseeinheit könnte auch eine größere Gruppe sein: So könnten beispielsweise Daten von allen Schülern in ganzen Klassenzimmern erhoben werden, wenn die Analyseeinheit die Klassenzimmer einer Schule oder eines Schulsystems ist. Oder die Analyseeinheit könnte auf der Ebene von Stadtteilen, Programmen, Organisationen, Bezirken, Staaten oder sogar Nationen liegen. So basieren beispielsweise viele der Variablen, die als Indikatoren für die Ernährungssicherheit auf Gemeindeebene verwendet werden, wie Erschwinglichkeit und Zugänglichkeit, auf Daten, die von einzelnen Haushalten erhoben wurden (Kaiser, 2017). Die Analyseeinheit in Studien, die diese Indikatoren verwenden, wären die zu vergleichenden Gemeinschaften. Diese Unterscheidung hat wichtige Auswirkungen auf die Messung und die Datenanalyse.
Eine Erinnerung an Variablen versus Variablenniveaus
Eine Studie kann anhand der Anzahl der Variablenkategorien oder -niveaus beschrieben werden, die verglichen werden. Zum Beispiel kann eine Studie als 2 x 2 Design beschrieben werden – ausgesprochen als ein zwei mal zwei Design. Das bedeutet, dass es 2 mögliche Kategorien für die erste Variable und 2 mögliche Kategorien für die andere Variable gibt – beides sind dichotome Variablen. Eine Studie, die 2 Kategorien für die Variable „Alkoholkonsumstörung“ (Kategorien für „erfüllt die Kriterien“, ja oder nein) mit 2 Kategorien für die Variable „illegale Substanzkonsumstörung“ (Kategorien für „erfüllt die Kriterien“, ja oder nein) vergleicht, hätte 4 mögliche Ergebnisse (mathematisch gesehen, 2 x 2=4) und könnte wie folgt dargestellt werden (die Daten basieren auf den Anteilen aus der NSDUH-Erhebung 2016, dargestellt in SAMHSA, 2017):
| Illicit Substance Use Disorder (SUD) | |||
|---|---|---|---|
|
Alcohol Use Disorder (AUD) |
Ja | ||
| Nein | 500 | 10 | |
| Ja | 26 | 4 | |
Wenn man die 4 Zellen in dieser 2 x 2 Tabelle liest, erfährt man, dass in dieser (hypothetischen) Erhebung von 540 Personen, 500 Personen erfüllten weder die Kriterien für eine Alkohol- noch für eine illegale Substanzkonsumstörung (Nein, Nein); 26 erfüllten die Kriterien nur für eine Alkoholkonsumstörung (Ja, Nein); 10 erfüllten die Kriterien nur für eine Störung des Konsums illegaler Substanzen (Nein, Ja) und 4 erfüllten die Kriterien sowohl für eine Alkohol- als auch für eine Störung des Konsums illegaler Substanzen (Ja, Ja). Darüber hinaus können wir mit ein wenig Mathematik feststellen, dass insgesamt 30 Personen eine Alkoholkonsumstörung (26 + 4) und 14 Personen eine Störung des Konsums illegaler Substanzen (10 + 4) aufwiesen. Und wir können sehen, dass 40 eine Art von Substanzkonsumstörung hatten (26 + 10 + 4).
 Um diese Unterscheidung zwischen Variablen und Variablenniveaus oder -kategorien kristallklar zu machen, lassen Sie uns ein weiteres Beispiel betrachten: ein 2 x 3 Studiendesign. Erstens, wenn wir rechnen, sollten wir 6 mögliche Ergebnisse (Zellen) sehen. Zweitens wissen wir, dass die erste Variable (Altersgruppe) 2 Kategorien hat (unter 30 Jahre, 30 Jahre oder älter) und die andere Variable (Beschäftigungsstatus) 3 Kategorien hat (voll beschäftigt, teilweise beschäftigt, arbeitslos). Diesmal sind die 6 Zellen unseres Entwurfs leer, weil wir auf die Daten warten.
Um diese Unterscheidung zwischen Variablen und Variablenniveaus oder -kategorien kristallklar zu machen, lassen Sie uns ein weiteres Beispiel betrachten: ein 2 x 3 Studiendesign. Erstens, wenn wir rechnen, sollten wir 6 mögliche Ergebnisse (Zellen) sehen. Zweitens wissen wir, dass die erste Variable (Altersgruppe) 2 Kategorien hat (unter 30 Jahre, 30 Jahre oder älter) und die andere Variable (Beschäftigungsstatus) 3 Kategorien hat (voll beschäftigt, teilweise beschäftigt, arbeitslos). Diesmal sind die 6 Zellen unseres Entwurfs leer, weil wir auf die Daten warten.
| Beschäftigungsstatus | ||||
|---|---|---|---|---|
|
Altersgruppe |
Teilweise beschäftigt Erwerbstätig | Arbeitslos | ||
| <30 | ||||
| ≥30 | ||||
Damit, Wenn Sie eine Beschreibung des Studiendesigns sehen, die aussieht wie zwei Zahlen, die multipliziert werden, bedeutet dies im Wesentlichen, dass Sie erfahren, wie viele Kategorien oder Ebenen es für jede Variable gibt, und dass Sie verstehen, wie viele Zellen oder mögliche Ergebnisse existieren. Ein 3 x 3-Design hat 9 Zellen, ein 3 x 4-Design hat 12 Zellen und so weiter. Dieses Thema wird noch einmal wichtig, wenn wir in Kapitel 6 über den Stichprobenumfang sprechen.
Füllen Sie die folgende Workbook-Aktivität aus:
- SWK 3401.3-4.1 Beginn der Dateneingabe
Kapitelzusammenfassung
Zusammenfassend lässt sich sagen, dass Forscher viele ihrer quantitativen Studien entwerfen, um Hypothesen über die Beziehungen zwischen Variablen zu testen. Das Verständnis der Art der beteiligten Variablen hilft beim Verstehen und Bewerten der durchgeführten Forschung. Das Verständnis der Unterscheidungen zwischen verschiedenen Arten von Variablen sowie zwischen Variablen und Kategorien hat wichtige Auswirkungen auf das Studiendesign, die Messung und die Stichproben. Das nächste Kapitel befasst sich unter anderem mit der Überschneidung zwischen der Art der in der quantitativen Forschung untersuchten Variablen und der Art und Weise, wie die Forscher diese Variablen messen.
Nehmen Sie sich einen Moment Zeit, um die folgende Aufgabe zu lösen.