
Resurssien jakaminen on tärkeä näkökohta minkä tahansa spark-työn suorittamisen aikana. Jos sitä ei ole konfiguroitu oikein, spark-työ voi kuluttaa koko klusterin resursseja ja saada muut sovellukset näännyttämään resursseja.
Tämä blogi auttaa ymmärtämään Spark-sovelluksen perusvirtauksen ja sen jälkeen, miten Spark-työn suorittajien määrä, kunkin suorittajan muistiasetukset ja ytimien määrä määritetään. On olemassa muutamia tekijöitä, jotka meidän on otettava huomioon, jotta voimme päättää optimaaliset numerot edellä mainituille kolmelle, kuten:
- Datan määrä
- Aika, jossa työn on valmistuttava
- Resurssien staattinen tai dynaaminen jako
- Virtaussuuntainen tai virtaussuuntainen sovellus
- Esittely
- Vaiheet, jotka liittyvät Spark-työn klusteritilaan
- Static Allocation
- Tapaus 1 Laitteisto – 6 solmua ja jokaisessa solmussa on 16 ydintä, 64 GB RAM
- Tapaus 2 Laitteisto – 6 solmua ja jokaisella solmulla on 32 ydintä, 64 GB
- Tapaus 3 – Kun suorittajiin ei tarvita lisää muistia
- Yhteenvetotaulukko
- Dynaaminen allokaatio
Esittely
Aloitetaan muutamalla perusmääritelmällä termeistä, joita käytetään Spark-sovellusten käsittelyssä.
Partitions : Osio on pieni palanen suuresta hajautetusta datajoukosta. Spark hallitsee dataa osioiden avulla, mikä auttaa rinnakkaistamaan datan käsittelyä siten, että dataa sekoitetaan mahdollisimman vähän suorittajien välillä.
Tehtävä : Tehtävä on työyksikkö, joka voidaan suorittaa hajautetun tietokokonaisuuden osiossa ja joka suoritetaan yhdellä suorittajalla. Rinnakkaisen suorituksen yksikkö on tehtävätasolla.Kaikki yhden vaiheen sisällä olevat tehtävät voidaan suorittaa rinnakkain
Toteuttaja : Toteuttaja on yksittäinen JVM-prosessi, joka käynnistetään sovellusta varten työläissolmulla. Executor suorittaa tehtäviä ja pitää tietoja muistissa tai levytallennuksessa niiden välillä. Jokaisella sovelluksella on omat toteuttajansa. Yhdessä solmussa voi olla useita suorittajia, ja sovelluksen suorittajat voivat kattaa useita työläissolmuja. Suoritin pysyy toiminnassa Spark-sovelluksen
keston ajan ja suorittaa tehtäviä useissa säikeissä. Spark-sovelluksen suorittajien määrä voidaan määrittää SparkConfissa tai komentoriviltä lipun -num-executors avulla.
Cluster Manager : Ulkoinen palvelu klusterin resurssien hankkimiseen (esim. standalone manager, Mesos, YARN). Spark on agnostinen klusterin managerista, kunhan se voi hankkia suoritinprosesseja ja nämä voivat kommunikoida keskenään. olemme ensisijaisesti kiinnostuneita Yarnista klusterin managerina. Spark-klusteri voi toimia joko yarn-klusteri- tai yarn-client-tilassa:
yarn-client-tila – Ajuri pyörii asiakasprosessissa, Application Masteria käytetään vain resurssien pyytämiseen YARN:lta.
yarn-cluster-tila – Ajuri pyörii Application Master-prosessin sisällä, asiakas poistuu, kun sovellus on alustettu
Cores : Ydin on suorittimen peruslaskentayksikkö ja suorittimessa voi olla yksi tai useampi ydin suorittamaan tehtäviä tiettynä aikana. Mitä enemmän ytimiä meillä on, sitä enemmän työtä voimme tehdä. Sparkissa tämä ohjaa sitä, kuinka monta rinnakkaista tehtävää suoritin voi suorittaa.
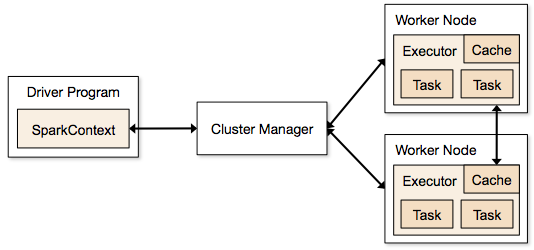
Vaiheet, jotka liittyvät Spark-työn klusteritilaan
- Ajurikoodista SparkContext muodostaa yhteyden klusterihallintaan (standalone/Mesos/YARN).
- Klusterihallinta jakaa resursseja muille sovelluksille. Mitä tahansa klusterinhallintaa voidaan käyttää, kunhan suoritinprosessit ovat käynnissä ja ne kommunikoivat keskenään.
- Spark hankkii suoritinprosessit klusterin solmuihin. Tässä jokainen sovellus saa omat executor-prosessinsa.
- Sovelluskoodi (jar/python-tiedostot/python egg-tiedostot) lähetetään executoreille
- Tehtävät lähetetään SparkContextin toimesta executoreille.
Yllämainituista vaiheista nähdään, että executoreiden lukumäärällä ja niiden muistiasetuksella on suuri merkitys spark-työssä. Suorittimien ajaminen liian suurella muistimäärällä johtaa usein liiallisiin roskienkeräysviiveisiin
Yritämme nyt ymmärtää, miten konfiguroidaan parhaat arvot spark-työn optimoimiseksi.
On kaksi tapaa, joilla konfiguroidaan suoritin- ja ydintietoja Spark-työhön. Ne ovat:
- Static Allocation – Arvot annetaan osana spark-submit
- Dynamic Allocation – Arvot poimitaan tarpeen mukaan (datan koko, tarvittavien laskutoimitusten määrä) ja vapautetaan käytön jälkeen. Näin resursseja voidaan käyttää uudelleen muissa sovelluksissa.
Static Allocation
Erilaisia tapauksia käsitellään vaihtelemalla eri parametreja ja päätymällä erilaisiin yhdistelmiin käyttäjän/datan vaatimusten mukaan.
Tapaus 1 Laitteisto – 6 solmua ja jokaisessa solmussa on 16 ydintä, 64 GB RAM
Ensiksi jokaisessa solmussa tarvitaan 1 ydin ja 1 GB käyttöjärjestelmää ja Hadoop Daemoneja varten, joten meillä on 15 ydintä, 63 GB RAM-muistia jokaisessa solmussa
Aloitetaan siitä, miten ytimien määrä valitaan:
Ytimien määrä = yhtäaikaiset tehtävät, joita suoritin voi suorittaa
Voisimme siis ajatella, että useampi yhtäaikainen tehtävä kullekin suorittajalle antaa paremman suorituskyvyn. Mutta tutkimus osoittaa, että kaikki sovellukset, joissa on yli 5 samanaikaista tehtävää, johtavat huonoon esitykseen. Joten optimaalinen arvo on 5.
Tämä luku tulee suorittajan kyvystä suorittaa rinnakkaisia tehtäviä eikä siitä, kuinka monta ydintä järjestelmässä on. Joten luku 5 pysyy samana, vaikka CPU:ssa olisi kaksinkertaiset (32) ydintä
Toteuttajien määrä:
Seuraavaan vaiheeseen siirryttäessä, kun 5 ydintä per toteuttaja ja 15 käytettävissä olevaa ydintä yhdessä solmussa (CPU:ssa) – saamme 3 toteuttajaa solmua kohti, mikä on 15/5. Meidän on laskettava suorittajien määrä kussakin solmussa ja saatava sitten työn kokonaislukumäärä.
Siten kun solmuja on 6 ja suorittajia 3 solmua kohden, saamme yhteensä 18 suorittajaa. 18:sta tarvitsemme 1 suorittajan (java-prosessi) Application Masteria varten YARNissa. Lopullinen määrä on siis 17 suorittajaa
Tämä 17 on määrä, jonka annamme sparkille käyttämällä -num-executors-käskyä suoritettaessa spark-submit-komentoa
Muistia kullekin suorittajalle:
Ylläolevan vaiheen perusteella meillä on 3 suorittajaa per solmu. Ja käytettävissä oleva RAM-muisti kussakin solmussa on 63 Gt
Siten muistia kullekin suorittajalle kussakin solmussa on 63/3 = 21 Gt.
Mutta tarvitaan myös pientä päällekkäismuistia, jotta voidaan määrittää koko muistipyyntö YARN:lle kunkin suorittajan osalta.
Tämän yleiskustannuksen kaava on max(384, .07 * spark.executor.memory)
Tämän yleiskustannuksen laskeminen: .07 * 21 (Tässä 21 lasketaan kuten edellä 63/3) = 1.47
Koska 1.47 Gt > 384 MB, yleiskustannus on 1.47
Vie edellä mainittu jokaisesta edellä mainitusta 21:stä => 21 – 1.47 ~ 19 GB
Siten toteuttajamuisti – 19 GB
Loppuluvut – toteuttajat – 17, ytimet 5, toteuttajamuisti – 19 GB
Tapaus 2 Laitteisto – 6 solmua ja jokaisella solmulla on 32 ydintä, 64 GB
Ytimien määrä on sama kuin 5 ytimessä, jotta saadaan aikaan hyvä rinnakkaisuus, joka on selostettu edellä.
Toteuttajien määrä jokaiselle solmulle = 32/5 ~ 6
Silloin toteuttajien kokonaismäärä = 6 * 6 solmua = 36. Sitten lopullinen määrä on 36 – 1(AM:lle) = 35
Toteuttajamuisti:
6 toteuttajaa kutakin solmua kohden. 63/6 ~ 10. Yleiskustannus on ,07 * 10 = 700 Mt. Pyöristämällä yleiskustannukseksi siis 1 Gt, saadaan 10-1 = 9 Gt
Loppuluvut – Suorittajat – 35, ytimet 5, suoritinmuisti – 9 Gt
Tapaus 3 – Kun suorittajiin ei tarvita lisää muistia
Ylläolevat skenaariot alkavat siitä, että ytimien määrä hyväksytään kiinteäksi ja siirrytään suorittajien ja muistin määrään.
Nyt ensimmäisessä tapauksessa, jos ajattelemme, ettemme tarvitse 19 Gt:tä, ja vain 10 Gt riittää datan koon ja suoritettavien laskutoimitusten perusteella, seuraavat luvut ovat:
Ytimet:
Toteuttajien määrä kussakin solmussa = 3. Edelleen 15/5, kuten edellä laskettiin.
Tässä vaiheessa tämä johtaisi 21 Gt:hen, ja sitten 19 Gt:hen ensimmäisen laskelmamme mukaisesti. Mutta koska ajattelimme, että 10 on ok (oletetaan pieni yleiskustannus), emme voi vaihtaa suorittajien lukumäärää solmua kohti 6:een (kuten 63/10). Koska 6 toteuttajaa solmua kohti ja 5 ydintä tarkoittaa 30 ydintä solmua kohti, vaikka meillä on vain 16 ydintä. Joten meidän on myös muutettava ytimien lukumäärää kutakin suoritinta kohden.
Lasketaan siis uudelleen,
Taikaluvuksi 5 tulee 3 (mikä tahansa luku, joka on pienempi tai yhtä suuri kuin 5). Joten 3 ytimellä ja 15 käytettävissä olevalla ytimellä – saamme 5 suoritinta per solmu, 29 suoritinta ( joka on (5*6 -1)) ja muistia on 63/5 ~ 12.
Overhead on 12*.07=.84. Eli suoritinmuisti on 12 – 1 GB = 11 GB
Loppuluvut ovat 29 suoritinta, 3 ydintä, suoritinmuisti on 11 GB
Yhteenvetotaulukko
Dynaaminen allokaatio
Huomautus: Yläraja suoritinten lukumäärälle, jos dynaaminen allokaatio on käytössä on ääretön. Tämä siis kertoo, että kipinäsovellus voi tarvittaessa syödä kaikki resurssit. Klusterissa, jossa on käynnissä muita sovelluksia, jotka myös tarvitsevat ytimiä tehtävien suorittamiseen, on varmistettava, että ytimet jaetaan klusteritasolla.
Tämä tarkoittaa, että voimme jakaa tietyn määrän ytimiä YARN-pohjaisille sovelluksille käyttäjän käyttöoikeuden perusteella. Voimme siis luoda spark_user-käyttäjän ja sitten antaa ytimiä (min/max) kyseiselle käyttäjälle. Nämä rajoitukset on tarkoitettu jaettavaksi sparkin ja muiden YARN:llä toimivien sovellusten välillä.
Ymmärtääksemme dynaamisen allokaation meidän on tunnettava seuraavat ominaisuudet:
spark.dynamicAllocation.enabled – kun tämä on asetettu arvoon true, meidän ei tarvitse mainita suorittajia. Syy on alla:
Staattiset parametriluvut, jotka annamme spark-submitissa, koskevat koko työn kestoa. Kuitenkin jos dynaaminen allokaatio tulee kuvaan, olisi eri vaiheita kuten seuraavat:
Millä suorittajien määrällä aloitetaan:
Alustava suorittajien määrä (spark.dynamicAllocation.initialExecutors), jolla aloitetaan
Suorittajien määrän ohjaaminen dynaamisesti:
Sitten kuorman (vireillä olevat tehtävät) perusteella kuinka monta suorittajaa pyydetään. Tämä olisi lopulta se määrä, jonka annamme spark-submitissa staattisesti. Eli kun alkuperäiset suorittajamäärät on asetettu, siirrymme min (spark.dynamicAllocation.minExecutors) ja max (spark.dynamicAllocation.maxExecutors) -lukuihin.
Milloin pyydetään uusia suorittajia tai annetaan pois nykyiset suorittajat:
Milloin pyydetään uusia suorittajia (spark.dynamicAllocation.schedulerBacklogTimeout) – Tämä tarkoittaa sitä, että vireillä olevia tehtäviä on odottanut tämän verran aikaa. Jokaisella kierroksella pyydettyjen suorittajien määrä kasvaa siis eksponentiaalisesti edellisestä kierroksesta. Esimerkiksi sovellus lisää ensimmäisellä kierroksella yhden suorittajan ja seuraavilla kierroksilla 2, 4, 8 ja niin edelleen suorittajia. Tietyssä vaiheessa edellä mainittu ominaisuus max tulee kuvaan.
Kuinka annamme suorittajan pois, asetetaan käyttämällä spark.dynamicAllocation.executorIdleTimeout.
Johtopäätöksenä voidaan todeta, että jos tarvitsemme enemmän kontrollia työn suoritusaikaan, työn seuraaminen odottamattomien tietomäärien osalta staattiset luvut auttaisivat. Siirtymällä dynaamiseen resursseja käytettäisiin taustalla ja odottamattomia volyymeja sisältävät työt saattaisivat vaikuttaa muihin sovelluksiin.