
- Une promenade rapide des meilleurs articles pour la classification d’images en une décennie pour démarrer votre apprentissage de… vision par ordinateur
- 1998 : LeNet
- 2012 : AlexNet
- 2014 : VGG
- 2014 : GoogLeNet
- 2015 : Normalisation par lots
- 2015 : ResNet
- 2016 : Xception
- 2017 : MobileNet
- 2017 : NASNet
- 2019 : EfficientNet
- 2014 : SPPNet
- 2016 : DenseNet
- 2017 : SENet
- 2017 : ShuffleNet
- 2018 : Bag of Tricks
- Conclusion
Une promenade rapide des meilleurs articles pour la classification d’images en une décennie pour démarrer votre apprentissage de… vision par ordinateur

La vision par ordinateur est un sujet pour convertir les images et les vidéos en signaux compréhensibles par la machine.signaux compréhensibles par la machine. Avec ces signaux, les programmeurs peuvent ensuite contrôler le comportement de la machine en fonction de cette compréhension de haut niveau. Parmi les nombreuses tâches de vision par ordinateur, la classification des images est l’une des plus fondamentales. Elle peut non seulement être utilisée dans de nombreux produits réels comme le marquage de Google Photo et la modération de contenu par l’IA, mais elle ouvre également la voie à de nombreuses tâches de vision plus avancées, comme la détection d’objets et la compréhension de vidéos. En raison des changements rapides dans ce domaine depuis la percée de l’apprentissage profond, les débutants trouvent souvent qu’il est trop difficile d’apprendre. Contrairement aux sujets typiques de l’ingénierie logicielle, il n’existe pas beaucoup de bons livres sur la classification d’images à l’aide du DCNN, et la meilleure façon de comprendre ce domaine est de lire des articles universitaires. Mais quels articles lire ? Par où commencer ? Dans cet article, je vais vous présenter les 10 meilleurs articles à lire pour les débutants. Grâce à ces articles, nous pouvons voir comment ce domaine évolue, et comment les chercheurs ont apporté de nouvelles idées basées sur les résultats de recherches précédentes. Néanmoins, il est toujours utile pour vous d’avoir une vue d’ensemble, même si vous avez déjà travaillé dans ce domaine pendant un certain temps. Alors, commençons.
1998 : LeNet
Application de l’apprentissage par gradient à la reconnaissance de documents

Introduit en 1998, LeNet établit une base pour les futures recherches en classification d’images utilisant le réseau neuronal à convolution. De nombreuses techniques classiques de CNN, telles que les couches de mise en commun, les couches entièrement connectées, le rembourrage et les couches d’activation, sont utilisées pour extraire des caractéristiques et effectuer une classification. Avec une fonction de perte d’erreur quadratique moyenne et 20 époques d’apprentissage, ce réseau peut atteindre une précision de 99,05 % sur l’ensemble de test MNIST. Même après 20 ans, de nombreux réseaux de classification de pointe suivent toujours ce modèle en général.
2012 : AlexNet
Classification d’images avec des réseaux de neurones convolutifs profonds

.
Bien que LeNet ait obtenu un excellent résultat et montré le potentiel des CNN, le développement dans ce domaine a stagné pendant une décennie en raison de la puissance de calcul limitée et de la quantité de données. Il semblait que CNN ne pouvait résoudre que certaines tâches faciles comme la reconnaissance de chiffres, mais pour des caractéristiques plus complexes comme les visages et les objets, un extracteur de caractéristiques HarrCascade ou SIFT avec un classificateur SVM était une approche plus privilégiée.
Toutefois, dans le 2012 ImageNet Large Scale Visual Recognition Challenge, Alex Krizhevsky a proposé une solution basée sur CNN pour ce défi et a considérablement augmenté la précision du top-5 de l’ensemble de test ImageNet de 73,8% à 84,7%. Son approche hérite de l’idée du CNN multicouche de LeNet, mais a considérablement augmenté la taille du CNN. Comme vous pouvez le voir sur le diagramme ci-dessus, l’entrée est maintenant de 224×224 par rapport aux 32×32 de LeNet, et de nombreux noyaux de convolution ont 192 canaux par rapport aux 6 de LeNet. Bien que la conception n’ait pas beaucoup changé, avec des centaines de fois plus de paramètres, la capacité du réseau à capturer et représenter des caractéristiques complexes s’est améliorée des centaines de fois aussi. Pour former un modèle de cette taille, Alex a utilisé deux GPU GTX 580 avec 3 Go de RAM chacun, ce qui a ouvert la voie à la formation par GPU. En outre, l’utilisation de la non-linéarité ReLU a également contribué à réduire le coût de calcul.
En plus d’apporter beaucoup plus de paramètres pour le réseau, il a également exploré le problème d’overfitting apporté par un plus grand réseau en utilisant une couche Dropout. Sa méthode de normalisation de la réponse locale n’a pas été très populaire par la suite, mais elle a inspiré d’autres techniques de normalisation importantes, telles que BatchNorm, pour lutter contre le problème de saturation du gradient. Pour résumer, AlexNet a défini le cadre de facto des réseaux de classification pour les 10 prochaines années : une combinaison de Convolution, d’activation non linéaire ReLu, de MaxPooling et de couche Dense.
2014 : VGG
Very Deep Convolutional Networks for Large-.Scale Image Recognition
Avec un tel succès de l’utilisation du CNN pour la reconnaissance visuelle, toute la communauté des chercheurs a explosé et tous ont commencé à chercher à savoir pourquoi ce réseau neuronal fonctionne si bien. Par exemple, dans « Visualizing and Understanding Convolutional Networks » de 2013, Matthew Zeiler a discuté de la façon dont le CNN prélève des caractéristiques et a visualisé les représentations intermédiaires. Et soudain, tout le monde a commencé à réaliser que le CNN est l’avenir de la vision par ordinateur depuis 2014. Parmi tous ces adeptes immédiats, le réseau VGG de Visual Geometry Group est celui qui attire le plus l’attention. Il a obtenu un résultat remarquable de 93,2% de précision top-5, et 76,3% de précision top-1 sur l’ensemble de test ImageNet.
Suivant la conception d’AlexNet, le réseau VGG a deux mises à jour majeures : 1) VGG n’a pas seulement utilisé un réseau plus large comme AlexNet mais aussi plus profond. VGG-19 possède 19 couches de convolution, contre 5 pour AlexNet. 2) VGG a également démontré que quelques petits filtres de convolution 3×3 peuvent remplacer un seul filtre 7×7 ou même 11×11 d’AlexNet, et obtenir de meilleures performances tout en réduisant le coût de calcul. En raison de cette conception élégante, VGG est également devenu le réseau back-bone de nombreux réseaux pionniers dans d’autres tâches de vision par ordinateur, tels que FCN pour la segmentation sémantique, et Faster R-CNN pour la détection d’objets.
Avec un réseau plus profond, la disparition du gradient de la rétropropagation multicouches devient un problème plus important. Pour y faire face, le VGG a également discuté de l’importance du pré-entraînement et de l’initialisation des poids. Ce problème limite les chercheurs à ajouter sans cesse de nouvelles couches, sinon le réseau aura beaucoup de mal à converger. Mais nous verrons une meilleure solution pour cela après deux ans.
2014 : GoogLeNet
Gagner en profondeur avec les convolutions

VGG a une belle apparence et une structure facile à comprendre, mais ses performances ne sont pas les meilleures parmi tous les finalistes des concours ImageNet 2014. GoogLeNet, alias InceptionV1, a remporté le prix final. Tout comme VGG, l’une des principales contributions de GoogLeNet est de repousser la limite de la profondeur du réseau avec une structure à 22 couches. Cela a démontré une fois de plus qu’aller plus profond et plus large est effectivement la bonne direction pour améliorer la précision.
Contrairement à VGG, GoogLeNet a essayé d’aborder de front les problèmes de calcul et de diminution du gradient, au lieu de proposer une solution de contournement avec une meilleure initialisation des schémas et des poids pré-entraînés.

Premièrement, il a exploré l’idée de la conception de réseau asymétrique en utilisant un module appelé Inception (voir le diagramme ci-dessus). Idéalement, ils aimeraient poursuivre la convolution éparse ou les couches denses pour améliorer l’efficacité des fonctions, mais la conception matérielle moderne n’était pas adaptée à ce cas. Ils ont donc pensé qu’une sparsité au niveau de la topologie du réseau pourrait également aider à la fusion des caractéristiques tout en exploitant les capacités matérielles existantes.
Deuxièmement, il s’attaque au problème du coût de calcul élevé en empruntant une idée à un article intitulé « Network in Network ». Fondamentalement, un filtre de convolution 1×1 est introduit pour réduire les dimensions des caractéristiques avant de passer par une opération de calcul lourde comme un noyau de convolution 5×5. Cette structure est appelée plus tard « Bottleneck » et est largement utilisée dans de nombreux réseaux suivants. Semblable à « Network in Network », il a également utilisé une couche de mise en commun moyenne pour remplacer la couche finale entièrement connectée pour réduire davantage le coût.
Troisièmement, pour aider les gradients à s’écouler vers les couches plus profondes, GoogLeNet a également utilisé la supervision sur certaines sorties de couches intermédiaires ou la sortie auxiliaire. Cette conception n’est pas tout à fait populaire plus tard dans le réseau de classification d’image en raison de la complexité, mais devenant plus populaire dans d’autres domaines de la vision par ordinateur tels que le réseau de sablier dans l’estimation de pose.
Comme un suivi, cette équipe de Google a écrit plus de papiers pour cette série Inception. « Batch Normalization : Accélérer l’entraînement des réseaux profonds en réduisant le décalage des covariables internes » correspond à InceptionV2. « Repenser l’architecture Inception pour la vision par ordinateur » en 2015 correspond à InceptionV3. Et « Inception-v4, Inception-ResNet et l’impact des connexions résiduelles sur l’apprentissage », publié en 2015, correspond à InceptionV4. Chaque article a ajouté plus d’amélioration par rapport au réseau Inception original et a obtenu un meilleur résultat.
2015 : Normalisation par lots
Normalisation par lots : Accélérer l’entraînement des réseaux profonds en réduisant le décalage interne des covariables
Le réseau Inception a aidé les chercheurs à atteindre une précision surhumaine sur le jeu de données ImageNet. Cependant, en tant que méthode d’apprentissage statistique, CNN est très contraint à la nature statistique d’un ensemble de données d’entraînement spécifique. Par conséquent, pour obtenir une meilleure précision, nous devons généralement pré-calculer la moyenne et l’écart-type de l’ensemble du jeu de données et les utiliser pour normaliser nos entrées afin de s’assurer que la plupart des entrées des couches du réseau sont proches, ce qui se traduit par une meilleure réactivité d’activation. Cette approche approximative est très lourde, et parfois ne fonctionne pas du tout pour une nouvelle structure de réseau ou un nouveau jeu de données, de sorte que le modèle d’apprentissage profond est toujours considéré comme difficile à former. Pour résoudre ce problème, Sergey Ioffe et Chritian Szegedy, le gars qui a créé GoogLeNet, ont décidé d’inventer quelque chose de plus intelligent appelé Batch Normalization.

L’idée de la normalisation par lots n’est pas difficile : nous pouvons utiliser les statistiques d’une série de mini-lots pour approximer les statistiques de l’ensemble des données, tant que nous nous entraînons pendant un temps suffisamment long. De plus, au lieu de calculer manuellement les statistiques, nous pouvons introduire deux paramètres plus apprenables « scale » et « shift » pour que le réseau apprenne à normaliser chaque couche par lui-même.
Le diagramme ci-dessus a montré le processus de calcul des valeurs de normalisation par lot. Comme nous pouvons le voir, nous prenons la moyenne de l’ensemble du mini-batch et nous calculons également la variance. Ensuite, nous pouvons normaliser l’entrée avec cette moyenne et cette variance du mini-lot. Enfin, avec un paramètre d’échelle et un paramètre de décalage, le réseau apprendra à adapter le résultat normalisé du lot pour qu’il corresponde le mieux possible aux couches suivantes, généralement ReLU. Une solution consiste donc à calculer une moyenne mobile et une variance pendant la formation, puis à utiliser ces moyennes mobiles dans le chemin d’inférence. Cette petite innovation a un tel impact, et tous les réseaux ultérieurs commencent à l’utiliser immédiatement.
2015 : ResNet
Apprentissage résiduel profond pour la reconnaissance d’images
2015 est peut-être la meilleure année pour la vision par ordinateur depuis une décennie, nous avons vu tant de grandes idées surgir non seulement dans la classification d’images, mais toutes sortes de tâches de vision par ordinateur telles que la détection d’objets, la segmentation sémantique, etc. La plus grande avancée de l’année 2015 appartient à un nouveau réseau appelé ResNet, ou réseaux résiduels, proposé par un groupe de chercheurs chinois de Microsoft Research Asia.

Comme nous l’avons discuté plus tôt pour le réseau VGG, le plus grand obstacle pour aller encore plus profond est la question de la disparition du gradient, c’est-à-dire que les dérivés deviennent plus petits lorsque le gradient est faible.c’est-à-dire que les dérivées deviennent de plus en plus petites lors de la rétropropagation à travers des couches plus profondes, et finit par atteindre un point que l’architecture informatique moderne ne peut pas vraiment représenter de manière significative. GoogLeNet a essayé de s’attaquer à ce problème en utilisant une supervision auxiliaire et un module d’inception asymétrique, mais cela n’atténue le problème que dans une faible mesure. Si nous voulons utiliser 50 ou même 100 couches, y aura-t-il une meilleure façon pour le gradient de circuler dans le réseau ? La réponse de ResNet est d’utiliser un module résiduel.

ResNet a ajouté un raccourci d’identité à la sortie, afin que chaque module résiduel ne puisse pas au moins prédire ce qu’est l’entrée, sans se perdre dans la nature. Plus important encore, au lieu d’espérer que chaque couche s’adapte directement à la cartographie des caractéristiques souhaitées, le module résiduel tente d’apprendre la différence entre la sortie et l’entrée, ce qui rend la tâche beaucoup plus facile car le gain d’information nécessaire est moindre. Imaginez que vous appreniez les mathématiques. Pour chaque nouveau problème, on vous donne la solution d’un problème similaire, et tout ce que vous avez à faire est d’étendre cette solution et d’essayer de la faire fonctionner. C’est beaucoup plus facile que de penser à une toute nouvelle solution pour chaque problème que vous rencontrez. Ou comme l’a dit Newton, nous pouvons nous tenir sur les épaules de géants, et l’entrée d’identité est ce géant pour le module résiduel.
En plus de la cartographie d’identité, ResNet a également emprunté le goulot d’étranglement et la normalisation par lots aux réseaux Inception. Finalement, il a réussi à construire un réseau avec 152 couches de convolution et a atteint une précision top-1 de 80,72 % sur ImageNet. L’approche résiduelle devient également une option par défaut pour de nombreux autres réseaux par la suite, tels que Xception, Darknet, etc. En outre, grâce à sa conception simple et belle, il est encore largement utilisé dans de nombreux systèmes de reconnaissance visuelle de production de nos jours.
Il y a beaucoup plus d’invariants sont sortis en suivant la hype du réseau résiduel. Dans « Identity Mappings in Deep Residual Networks », l’auteur original de ResNet a essayé de mettre l’activation avant le module résiduel et a obtenu un meilleur résultat, et cette conception est appelée ResNetV2 par la suite. De même, dans un article de 2016 « Aggregated Residual Transformations for Deep Neural Networks », les chercheurs ont proposé ResNeXt qui a ajouté des branches parallèles pour les modules résiduels afin d’agréger les sorties de différentes transformations.
2016 : Xception
Xception: Deep Learning with Depthwise Separable Convolutions

Avec la sortie de ResNet, il semblait que la plupart des fruits mûrs du classificateur d’images avaient déjà été saisis. Les chercheurs ont commencé à se demander quel était le mécanisme interne de la magie du CNN. Comme la convolution transversale introduit généralement une tonne de paramètres, le réseau Xception a choisi d’étudier cette opération pour comprendre une image complète de son effet.
Comme son nom, Xception est issu du réseau Inception. Dans le module Inception, de multiples branches de différentes transformations sont agrégées ensemble pour obtenir une sparsité topologique. Mais pourquoi cette sparsité fonctionne-t-elle ? L’auteur de Xception, également l’auteur du framework Keras, a étendu cette idée à un cas extrême où un fichier de convolution 3×3 correspond à un canal de sortie avant une concaténation finale. Dans ce cas, ces noyaux de convolution parallèles forment en fait une nouvelle opération appelée convolution en profondeur.

Comme le montre le schéma ci-dessus, contrairement à la convolution traditionnelle où tous les canaux sont inclus pour un seul calcul, la convolution en profondeur ne calcule que la convolution pour chaque canal séparément, puis concatène la sortie ensemble. Cela permet de réduire l’échange de caractéristiques entre les canaux, mais aussi de réduire un grand nombre de connexions, d’où le résultat d’une couche avec moins de paramètres. Cependant, cette opération produira en sortie le même nombre de canaux qu’en entrée (ou un nombre plus petit de canaux si vous regroupez deux canaux ou plus). Par conséquent, une fois que les sorties des canaux sont fusionnées, nous avons besoin d’un autre filtre 1×1 régulier, ou d’une convolution par points, pour augmenter ou réduire le nombre de canaux, tout comme le fait la convolution régulière.
Cette idée ne vient pas de Xception à l’origine. Elle est décrite dans un article intitulé « Learning visual representations at scale » et également utilisée occasionnellement dans InceptionV2. Xception a fait un pas de plus et a remplacé presque toutes les convolutions par ce nouveau type. Et le résultat de l’expérience s’est avéré assez bon. Il surpasse ResNet et InceptionV3 et est devenu une nouvelle méthode SOTA pour la classification d’images. Cela a également prouvé que le mappage des corrélations transversales et des corrélations spatiales dans CNN peut être entièrement découplé. En outre, partageant la même vertu que ResNet, Xception a également un design simple et beau, de sorte que son idée est utilisée dans beaucoup d’autres recherches suivantes telles que MobileNet, DeepLabV3, etc.
2017 : MobileNet
MobileNets : Réseaux neuronaux convolutifs efficaces pour l’application de la vision mobile
Xception a atteint 79% de précision top-1 et 94,5% de précision top-5 sur ImageNet, mais c’est seulement 0,8% et 0,4% d’amélioration respectivement par rapport au précédent SOTA InceptionV3. Le gain marginal d’un nouveau réseau de classification d’images devient de plus en plus faible, de sorte que les chercheurs commencent à se concentrer sur d’autres domaines. Et MobileNet a mené une poussée significative de la classification des images dans un environnement à ressources limitées.

Similaire à Xception, MobileNet a utilisé un même module de convolution séparable en profondeur comme indiqué ci-dessus et a eu un accent sur la haute efficacité et moins de paramètres.
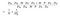
Le numérateur dans la formule ci-dessus est le nombre total de paramètres requis par une convolution séparable en profondeur. Et le dénominateur est le nombre total de paramètres d’une convolution régulière similaire. Ici, D est la taille du noyau de convolution, D est la taille de la carte de caractéristiques, M est le nombre de canaux d’entrée, N est le nombre de canaux de sortie. Puisque nous avons séparé le calcul du canal et de la caractéristique spatiale, nous pouvons transformer la multiplication en une addition, ce qui est une magnitude plus petite. Encore mieux, comme nous pouvons le voir dans ce rapport, plus le nombre de canaux de sortie est grand, plus nous avons économisé du calcul en utilisant cette nouvelle convolution.
Une autre contribution de MobileNet est le multiplicateur de largeur et de résolution. L’équipe de MobileNet voulait trouver un moyen canonique de réduire la taille du modèle pour les appareils mobiles, et le moyen le plus intuitif est de réduire le nombre de canaux d’entrée et de sortie, ainsi que la résolution de l’image d’entrée. Pour contrôler ce comportement, un ratio alpha est multiplié par les canaux, et un ratio rho est multiplié par la résolution d’entrée (qui affecte également la taille de la carte de caractéristiques). Ainsi, le nombre total de paramètres peut être représenté par la formule suivante :

Bien que ce changement semble naïf en termes d’innovation, il a une grande valeur d’ingénierie car c’est la première fois que les chercheurs concluent une approche canonique pour ajuster le réseau pour différentes contraintes de ressources. En outre, cela a en quelque sorte résumé la solution ultime de l’amélioration du réseau neuronal : une entrée plus large et à haute résolution conduit à une meilleure précision, une entrée plus fine et à basse résolution conduit à une moins bonne précision.
Plus tard en 2018 et 2019, l’équipe MobiletNet a également publié « MobileNetV2 : Résidus inversés et goulots d’étranglement linéaires » et « À la recherche de MobileNetV3 ». Dans MobileNetV2, une structure de goulot d’étranglement résiduel inversé est utilisée. Et dans MobileNetV3, il a commencé à rechercher la combinaison optimale d’architecture en utilisant la technologie de recherche d’architecture neuronale, que nous couvrirons ensuite.
2017 : NASNet
Learning Transferable Architectures for Scalable Image Recognition
Tout comme la classification d’images pour un environnement sous contrainte de ressources, la recherche d’architecture neuronale est un autre domaine qui a émergé autour de 2017. Avec ResNet, Inception et Xception, il semble que nous ayons atteint une topologie de réseau optimale que les humains peuvent comprendre et concevoir, mais que faire s’il existe une combinaison meilleure et beaucoup plus complexe qui dépasse de loin l’imagination humaine ? Un article de 2016 intitulé « Neural Architecture Search with Reinforcement Learning » a proposé une idée pour rechercher la combinaison optimale dans un espace de recherche prédéfini en utilisant l’apprentissage par renforcement. Comme nous le savons, l’apprentissage par renforcement est une méthode permettant de trouver la meilleure solution avec un objectif et une récompense clairs pour l’agent de recherche. Cependant, limité par la puissance de calcul, cet article n’a discuté de l’application que dans un petit ensemble de données CIFAR.

Dans le but de trouver une structure optimale pour un grand jeu de données comme ImageNet, NASNet a fait un espace de recherche adapté à ImageNet. Il espère concevoir un espace de recherche spécial afin que le résultat de la recherche sur CIFAR puisse également bien fonctionner sur ImageNet. Tout d’abord, NASNet part du principe que le module artisanal commun à de bons réseaux comme ResNet et Xception est toujours utile lors de la recherche. Ainsi, au lieu de rechercher des connexions et des opérations aléatoires, NASNet recherche la combinaison de ces modules dont l’utilité a déjà été prouvée sur ImageNet. Deuxièmement, la recherche effective est toujours effectuée sur l’ensemble de données CIFAR avec une résolution de 32×32, de sorte que NASNet ne recherche que des modules qui ne sont pas affectés par la taille de l’entrée. Afin de faire fonctionner le deuxième point, NASNet a prédéfini deux types de modèles de modules : Réduction et Normal. La cellule de réduction pourrait avoir une carte de caractéristiques réduite par rapport à l’entrée, et pour la cellule normale, ce serait la même chose.

Bien que NASNet présente de meilleures métriques que les réseaux conçus manuellement, il souffre également de quelques inconvénients. Le coût de la recherche d’une structure optimale est très élevé, ce qui n’est abordable que pour les grandes entreprises comme Google et Facebook. De plus, la structure finale n’a pas trop de sens pour les humains, donc plus difficile à maintenir et à améliorer dans un environnement de production. Plus tard en 2018, « MnasNet : Platform-Aware Neural Architecture Search for Mobile » étend encore cette idée de NASNet en limitant l’étape de recherche à une structure prédéfinie de blocs enchaînés. En outre, en définissant un facteur de poids, mNASNet a donné une façon plus systématique de rechercher le modèle étant donné des contraintes de ressources spécifiques, au lieu de simplement évaluer sur la base des FLOPs.
2019 : EfficientNet
EfficientNet : Repenser l’échelonnement des modèles pour les réseaux de neurones convolutifs
En 2019, il semble qu’il n’y ait plus d’idées passionnantes pour la classification supervisée d’images avec CNN. Un changement drastique de la structure du réseau n’offre généralement qu’une petite amélioration de la précision. Pire encore, lorsque le même réseau est appliqué à différents ensembles de données et tâches, les astuces précédemment revendiquées ne semblent pas fonctionner, ce qui a donné lieu à des critiques visant à déterminer si ces améliorations ne sont que des surajustements sur l’ensemble de données ImageNet. D’un autre côté, il y a une astuce qui n’a jamais failli à nos attentes : l’utilisation d’une entrée de plus haute résolution, l’ajout de plus de canaux pour les couches de convolution et l’ajout de plus de couches. Bien qu’il s’agisse d’une force très brutale, il semble qu’il existe un moyen de faire évoluer le réseau à la demande. MobileNetV1 a en quelque sorte suggéré cela en 2017, mais l’accent a été mis sur une meilleure conception du réseau plus tard.

Après NASNet et mNASNet, les chercheurs ont réalisé que même avec l’aide d’un ordinateur, un changement d’architecture n’apporte pas tant de bénéfices que cela. Ils ont donc commencé à se rabattre sur la mise à l’échelle du réseau. EfficientNet est construit à partir de cette hypothèse. D’une part, il utilise le bloc de construction optimal de mNASNet pour s’assurer d’une bonne base de départ. D’autre part, il a défini trois paramètres alpha, beta et rho pour contrôler la profondeur, la largeur et la résolution du réseau en conséquence. Ainsi, même s’ils ne disposent pas d’un grand pool de GPU pour rechercher une structure optimale, les ingénieurs peuvent toujours s’appuyer sur ces paramètres de principe pour ajuster le réseau en fonction de leurs différentes exigences. Au final, EfficientNet a donné 8 variantes différentes avec des ratios de largeur, de profondeur et de résolution différents et a obtenu de bonnes performances pour les petits et les grands modèles. En d’autres termes, si vous voulez une grande précision, optez pour un EfficientNet-B7 de 600×600 et 66M de paramètres. Si vous voulez une faible latence et un modèle plus petit, allez-y pour un 224×224 et 5.3M paramètres EfficientNet-B0. Problème résolu.
Si vous avez fini de lire les 10 articles ci-dessus, vous devriez avoir une assez bonne maîtrise de l’histoire de la classification d’images avec CNN. Si vous aimez continuer à apprendre ce domaine, j’ai également listé d’autres articles intéressants à lire. Bien qu’ils ne soient pas inclus dans la liste des 10 premiers, ces articles sont tous célèbres dans leur propre domaine et ont inspiré de nombreux autres chercheurs dans le monde.
2014 : SPPNet
Mise en commun de pyramides spatiales dans des réseaux convolutifs profonds pour la reconnaissance visuelle
SPPNet emprunte l’idée de pyramide de caractéristiques à l’extraction traditionnelle de caractéristiques de vision par ordinateur. Cette pyramide forme un sac de mots de caractéristiques avec différentes échelles, donc il est peut s’adapter à différentes tailles d’entrée et se débarrasser de la couche entièrement connectée de taille fixe. Cette idée a également inspiré davantage le module ASPP de DeepLab, ainsi que FPN pour la détection d’objets.
2016 : DenseNet
Réseaux convolutifs densément connectés
DenseNet de Cornell étend encore l’idée de ResNet. Il fournit non seulement une connexion de saut entre les couches mais a également des connexions de saut de toutes les couches précédentes.
2017 : SENet
Réseaux de squeeze-et-excitation
Le réseau Xception a démontré que la corrélation inter-canaux n’a pas grand chose à voir avec la corrélation spatiale. Cependant, en tant que champion de la dernière compétition ImageNet, SENet a conçu un bloc Squeeze-and-Excitation et a raconté une histoire différente. Le bloc SE comprime d’abord tous les canaux en un nombre réduit de canaux à l’aide d’une mise en commun globale, applique une transformation entièrement connectée, puis les « excite » pour revenir au nombre initial de canaux à l’aide d’une autre couche entièrement connectée. Donc, essentiellement, la couche FC a aidé le réseau à apprendre des attentions sur la carte de caractéristiques d’entrée.
2017 : ShuffleNet
ShuffleNet: Un réseau de neurones convolutifs extrêmement efficace pour les appareils mobiles
Construit sur le dessus du module de goulot d’étranglement inversé de MobileNetV2, ShuffleNet estime que la convolution ponctuelle dans la convolution séparable en profondeur sacrifie la précision en échange de moins de calcul. Pour compenser cela, ShuffleNet a ajouté une opération supplémentaire de brassage des canaux pour s’assurer que la convolution par point ne sera pas toujours appliquée au même « point ». Et dans ShuffleNetV2, ce mécanisme de brassage de canaux est encore étendu à une branche de mappage d’identité ResNet également, de sorte qu’une partie de la caractéristique d’identité sera également utilisée pour le brassage.
2018 : Bag of Tricks
Bag of Tricks for Image Classification with Convolutional Neural Networks
Bag of Tricks se concentre sur les astuces courantes utilisées dans le domaine de la classification d’images. Il sert de bonne référence aux ingénieurs lorsqu’ils ont besoin d’améliorer les performances du benchmark. Il est intéressant de noter que ces astuces, telles que l’augmentation des mélanges et le taux d’apprentissage en cosinus, permettent parfois d’obtenir une amélioration bien meilleure qu’une nouvelle architecture de réseau.
Conclusion
Avec la sortie d’EfficientNet, il semble que le benchmark de classification ImageNet touche à sa fin. Avec l’approche d’apprentissage profond existante, il n’y aura jamais un jour où nous pourrons atteindre une précision de 99,999% sur l’ImageNet, à moins qu’un autre changement de paradigme ne se produise. C’est pourquoi les chercheurs s’intéressent activement à de nouveaux domaines tels que l’apprentissage auto-supervisé ou semi-supervisé pour la reconnaissance visuelle à grande échelle. Entre-temps, avec les méthodes existantes, il s’agit plutôt pour les ingénieurs et les entrepreneurs de trouver l’application dans le monde réel de cette technologie imparfaite. À l’avenir, j’écrirai également une enquête pour analyser ces applications réelles de vision par ordinateur alimentées par la classification d’images, alors restez à l’écoute ! Si vous pensez qu’il y a aussi d’autres articles importants à lire pour la classification des images, veuillez laisser un commentaire ci-dessous et nous le faire savoir.
Originally published at http://yanjia.li on July 31, 2020
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Apprentissage par gradient appliqué à la reconnaissance de documents
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, Classification d’ImageNet avec des réseaux de neurones convolutifs profonds
- Karen Simonyan, Andrew Zisserman, Réseaux convolutifs très profonds pour la reconnaissance d’images à grande échelle
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Aller plus loin avec les convolutions
- Sergey Ioffe, Christian Szegedy, Normalisation par lots : Accélérer l’entraînement des réseaux profonds en réduisant le décalage des covariables internes
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Apprentissage résiduel profond pour la reconnaissance d’images
- François Chollet, Xception : Deep Learning with Depthwise Separable Convolutions
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets : Efficient Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Apprentissage d’architectures transférables pour la reconnaissance d’images évolutive
- Mingxing Tan, Quoc V. Le, EfficientNet : Repenser la mise à l’échelle des modèles pour les réseaux de neurones convolutifs
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Réseaux convolutifs densément connectés
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Réseaux à compression et excitation
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet : Un réseau neuronal convolutif extrêmement efficace pour les appareils mobiles
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Sac d’astuces pour la classification d’images avec des réseaux neuronaux convolutifs
.