
L’allocation de ressources est un aspect important lors de l’exécution de tout job spark. S’il n’est pas configuré correctement, un job spark peut consommer des ressources entières du cluster et faire en sorte que les autres applications soient affamées de ressources.
Ce blog permet de comprendre le flux de base dans une application Spark et ensuite comment configurer le nombre d’exécuteurs, les paramètres de mémoire de chaque exécuteur et le nombre de cœurs pour un job Spark. Il y a quelques facteurs que nous devons considérer pour décider des nombres optimaux pour les trois ci-dessus, comme :
- La quantité de données
- Le temps dans lequel un job doit se terminer
- Allocation statique ou dynamique des ressources
- Application en amont ou en aval
- Introduction
- Étapes impliquées dans le mode cluster pour un job Spark
- Allocation statique
- Cas 1 Matériel – 6 nœuds et chaque nœud a 16 cœurs, 64 Go de RAM
- Cas 2 Matériel – 6 nœuds et chaque nœud a 32 cœurs, 64 GB
- Cas 3 – Quand plus de mémoire n’est pas nécessaire pour les exécuteurs
- Tableau récapitulatif
- Allocation dynamique
Introduction
Débutons par quelques définitions de base des termes utilisés dans le traitement des applications Spark.
Partitions : Une partition est un petit morceau d’un grand ensemble de données distribuées. Spark gère les données en utilisant des partitions qui aident à paralléliser le traitement des données avec un brassage minimal des données entre les exécuteurs.
Tâche : Une tâche est une unité de travail qui peut être exécutée sur une partition d’un ensemble de données distribuées et qui est exécutée sur un seul exécuteur. L’unité d’exécution parallèle est au niveau de la tâche.Toutes les tâches d’une même étape peuvent être exécutées en parallèle
Exécuteur : Un exécuteur est un processus JVM unique qui est lancé pour une application sur un nœud de travail. L’exécuteur exécute les tâches et conserve les données en mémoire ou sur le disque à travers elles. Chaque application a ses propres exécuteurs. Un seul nœud peut exécuter plusieurs exécuteurs et les exécuteurs d’une application peuvent couvrir plusieurs nœuds de travail. Un exécuteur reste en place pendant la
durée de l’application Spark et exécute les tâches dans plusieurs threads. Le nombre d’exécuteurs pour une application spark peut être spécifié à l’intérieur du SparkConf ou via le drapeau -num-executors à partir de la ligne de commande.
Gestionnaire de cluster : Un service externe pour acquérir des ressources sur le cluster (par exemple, gestionnaire autonome, Mesos, YARN). Spark est agnostique à un gestionnaire de cluster tant qu’il peut acquérir des processus exécuteurs et que ceux-ci peuvent communiquer entre eux.Nous sommes principalement intéressés par Yarn comme gestionnaire de cluster. Un cluster spark peut fonctionner en mode yarn cluster ou yarn-client :
mode yarn-client – Un pilote s’exécute sur le processus client, le maître d’application n’est utilisé que pour demander des ressources à YARN.
mode yarn-cluster – Un pilote s’exécute à l’intérieur du processus maître d’application, le client disparaît une fois l’application initialisée
Cores : Un cœur est une unité de calcul de base du CPU et un CPU peut avoir un ou plusieurs cœurs pour effectuer des tâches à un moment donné. Plus on a de cœurs, plus on peut faire de travail. Dans spark, cela contrôle le nombre de tâches parallèles qu’un exécuteur peut exécuter.
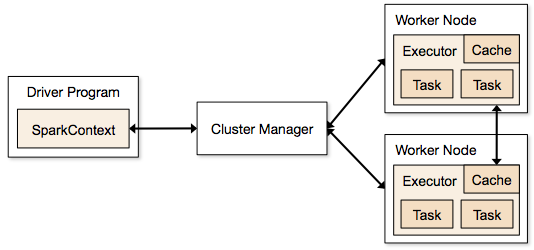
Étapes impliquées dans le mode cluster pour un job Spark
- Depuis le code du pilote, SparkContext se connecte au gestionnaire de cluster (standalone/Mesos/YARN).
- Le gestionnaire de cluster alloue les ressources à travers les autres applications. N’importe quel gestionnaire de cluster peut être utilisé tant que les processus exécuteurs sont en cours d’exécution et qu’ils communiquent entre eux.
- Spark acquiert des exécuteurs sur les nœuds du cluster. Ici, chaque application obtiendra ses propres processus d’exécuteurs.
- Le code de l’application (fichiers jar/python/fichiers œufs) est envoyé aux exécuteurs
- Les tâches sont envoyées par SparkContext aux exécuteurs.
D’après les étapes ci-dessus, il est clair que le nombre d’exécuteurs et leur réglage de mémoire jouent un rôle majeur dans un job spark. Exécuter des exécuteurs avec trop de mémoire entraîne souvent des retards excessifs de garbage collection
Maintenant, nous essayons de comprendre, comment configurer le meilleur ensemble de valeurs pour optimiser un job spark.
Il existe deux façons de configurer les détails de l’exécuteur et du noyau au job Spark. Ce sont :
- Allocation statique – Les valeurs sont données dans le cadre de spark-submit
- Allocation dynamique – Les valeurs sont prélevées en fonction des besoins (taille des données, quantité de calculs nécessaires) et libérées après utilisation. Cela aide les ressources à être réutilisées pour d’autres applications.
Allocation statique
Différents cas sont discutés en faisant varier différents paramètres et en arrivant à différentes combinaisons selon les besoins de l’utilisateur/des données.
Cas 1 Matériel – 6 nœuds et chaque nœud a 16 cœurs, 64 Go de RAM
Premièrement sur chaque nœud, 1 cœur et 1 Go sont nécessaires pour le système d’exploitation et les démons Hadoop, donc nous avons 15 cœurs, 63 Go de RAM pour chaque nœud
Nous commençons par comment choisir le nombre de cœurs :
Nombre de cœurs = Tâches concurrentes qu’un exécuteur peut exécuter
On pourrait donc penser que, plus de tâches concurrentes pour chaque exécuteur donnera de meilleures performances. Mais la recherche montre que toute application avec plus de 5 tâches concurrentes, conduirait à un mauvais spectacle. Donc la valeur optimale est 5.
Ce nombre provient de la capacité d’un exécuteur à exécuter des tâches parallèles et non du nombre de cœurs d’un système. Ainsi, le nombre 5 reste le même même si nous avons le double (32) cœurs dans le CPU
Nombre d’exécuteurs:
En passant à l’étape suivante, avec 5 comme cœurs par exécuteur, et 15 comme total des cœurs disponibles dans un nœud (CPU) – nous arrivons à 3 exécuteurs par nœud qui est 15/5. Nous devons calculer le nombre d’exécuteurs sur chaque nœud et ensuite obtenir le nombre total pour le travail.
Donc avec 6 nœuds, et 3 exécuteurs par nœud – nous obtenons un total de 18 exécuteurs. Sur les 18, nous avons besoin de 1 exécuteur (processus java) pour Application Master dans YARN. Donc, le nombre final est de 17 exécuteurs
Ce 17 est le nombre que nous donnons à spark en utilisant -num-executeurs lors de l’exécution de la commande shell spark-submit
Mémoire pour chaque exécuteur:
D’après l’étape ci-dessus, nous avons 3 exécuteurs par nœud. Et la RAM disponible sur chaque nœud est de 63 Go
Donc la mémoire pour chaque exécuteur dans chaque nœud est de 63/3 = 21 Go.
Cependant une petite mémoire de surcharge est également nécessaire pour déterminer la demande de mémoire complète à YARN pour chaque exécuteur.
La formule pour cet overhead est max(384, .07 * spark.executor.memory)
Calcul de cet overhead : .07 * 21 (Ici 21 est calculé comme ci-dessus 63/3) = 1,47
Si 1,47 GB > 384 MB, l’overhead est de 1.47
Prenez ce qui précède à partir de chaque 21 ci-dessus => 21 – 1,47 ~ 19 GB
Donc mémoire d’exécuteur – 19 GB
Nombre final – exécuteurs – 17, cœurs 5, mémoire d’exécuteur – 19 GB
Cas 2 Matériel – 6 nœuds et chaque nœud a 32 cœurs, 64 GB
Le nombre de cœurs de 5 est le même pour une bonne concurrence comme expliqué ci-dessus.
Nombre d’exécuteurs pour chaque nœud = 32/5 ~ 6
Donc le total des exécuteurs = 6 * 6 Nœuds = 36. Alors le nombre final est 36 – 1(pour AM) = 35
Mémoire des exécuteurs:
6 exécuteurs pour chaque nœud. 63/6 ~ 10. L’overhead est de 0,07 * 10 = 700 MB. Donc, en arrondissant à 1 Go comme overhead, nous obtenons 10-1 = 9 Go
Nombre final – exécuteurs – 35, cœurs 5, mémoire des exécuteurs – 9 Go
Cas 3 – Quand plus de mémoire n’est pas nécessaire pour les exécuteurs
Les scénarios ci-dessus commencent par accepter le nombre de cœurs comme fixe et passent au nombre d’exécuteurs et à la mémoire.
Maintenant pour le premier cas, si nous pensons que nous n’avons pas besoin de 19 Go, et que juste 10 Go sont suffisants en fonction de la taille des données et des calculs impliqués, alors voici les chiffres :
Cœurs : 5
Nombre d’exécuteurs pour chaque nœud = 3. Toujours 15/5 comme calculé ci-dessus.
À ce stade, cela conduirait à 21 Go, puis 19 selon notre premier calcul. Mais puisque nous avons pensé que 10 est ok (supposez peu d’overhead), alors nous ne pouvons pas passer le nombre d’exécuteurs par nœud à 6 (comme 63/10). Car avec 6 exécuteurs par nœud et 5 cœurs, cela revient à 30 cœurs par nœud, alors que nous n’avons que 16 cœurs. Donc nous devons aussi changer le nombre de cœurs pour chaque exécuteur.
Alors en calculant encore,
Le nombre magique 5 revient à 3 (tout nombre inférieur ou égal à 5). Donc avec 3 cœurs, et 15 cœurs disponibles – nous obtenons 5 exécuteurs par nœud, 29 exécuteurs ( qui est (5*6 -1)) et la mémoire est 63/5 ~ 12.
Les frais généraux sont 12*.07=.84. Donc la mémoire des exécuteurs est de 12 – 1 Go = 11 Go
Les chiffres finaux sont 29 exécuteurs, 3 cœurs, la mémoire des exécuteurs est de 11 Go
Tableau récapitulatif
Allocation dynamique
Note : la limite supérieure du nombre d’exécuteurs si l’allocation dynamique est activée est infinie. Cela signifie donc que l’application étincelle peut manger toutes les ressources si nécessaire. Dans un cluster où nous avons d’autres applications en cours d’exécution et ils ont également besoin de cœurs pour exécuter les tâches, nous devons nous assurer que nous attribuons les cœurs au niveau du cluster.
Cela signifie que nous pouvons allouer un nombre spécifique de cœurs pour les applications basées sur YARN en fonction de l’accès des utilisateurs. Ainsi, nous pouvons créer un spark_user et ensuite donner des cœurs (min/max) pour cet utilisateur. Ces limites sont pour le partage entre spark et d’autres applications qui s’exécutent sur YARN.
Pour comprendre l’allocation dynamique, nous devons avoir la connaissance des propriétés suivantes:
spark.dynamicAllocation.enabled – lorsque cela est défini à true, nous n’avons pas besoin de mentionner les exécuteurs. La raison est ci-dessous:
Les nombres de paramètres statiques que nous donnons à spark-submit est pour la durée entière du travail. Cependant, si l’allocation dynamique entre en jeu, il y aurait différentes étapes comme les suivantes:
Quel est le nombre d’exécuteurs pour commencer:
Nombre initial d’exécuteurs (spark.dynamicAllocation.initialExecutors) pour commencer
Contrôler le nombre d’exécuteurs dynamiquement:
Puis en fonction de la charge (tâches en attente) combien d’exécuteurs demander. Ce serait éventuellement le nombre ce que nous donnons à spark-submit de manière statique. Donc une fois que les nombres d’exécuteurs initiaux sont définis, nous passons aux nombres min (spark.dynamicAllocation.minExecutors) et max (spark.dynamicAllocation.maxExecutors).
Quand demander de nouveaux exécuteurs ou donner les exécuteurs actuels:
Quand demander de nouveaux exécuteurs (spark.dynamicAllocation.schedulerBacklogTimeout) – Cela signifie qu’il y a eu des tâches en attente pendant cette durée. Donc la demande du nombre d’exécuteurs demandés à chaque tour augmente de façon exponentielle par rapport au tour précédent. Par exemple, une application ajoutera 1 exécuteur dans le premier tour, puis 2, 4, 8 et ainsi de suite dans les tours suivants. À un moment précis, la propriété max ci-dessus entre en jeu.
Quand donnons-nous un exécuteur est défini en utilisant spark.dynamicAllocation.executorIdleTimeout.
En conclusion, si nous avons besoin de plus de contrôle sur le temps d’exécution du travail, surveiller le travail pour un volume de données inattendu les chiffres statiques aideraient. En passant au dynamique, les ressources seraient utilisées en arrière-plan et les travaux impliquant des volumes inattendus pourraient affecter d’autres applications.