
La première chose que nous devons comprendre est la nature des variables et comment les variables sont utilisées dans la conception d’une étude pour répondre aux questions de l’étude. Dans ce chapitre, vous apprendrez :
- différents types de variables dans les études quantitatives,
- les questions entourant la question de l’unité d’analyse.
Comprendre les variables quantitatives
La racine du mot variable est liée au mot « varier », ce qui devrait nous aider à comprendre ce que peuvent être les variables. Les variables sont des éléments, des entités ou des facteurs qui peuvent changer (varier) ; par exemple, la température extérieure, le coût de l’essence par gallon, le poids d’une personne et l’humeur des personnes de votre famille élargie sont tous des variables. En d’autres termes, elles peuvent avoir des valeurs différentes dans différentes conditions ou pour différentes personnes.
Nous utilisons des variables pour décrire des caractéristiques ou des facteurs d’intérêt. Il peut s’agir, par exemple, du nombre de membres de différents ménages, de la distance aux sources d’aliments sains dans différents quartiers, du rapport entre les professeurs de travail social et les étudiants dans un programme de BSW ou de MSW, de la proportion de personnes de différents groupes raciaux/ethniques incarcérées, du coût du transport pour recevoir les services d’un programme de travail social, ou du taux de mortalité infantile dans différents comtés. Dans la recherche sur les interventions en travail social, les variables pourraient inclure les caractéristiques de l’intervention (intensité, fréquence, durée) et les résultats associés à l’intervention.
Variables démographiques. Les travailleurs sociaux s’intéressent souvent à ce que l’on appelle les variables démographiques. Les variables démographiques sont utilisées pour décrire les caractéristiques d’une population, d’un groupe ou d’un échantillon de la population. Des exemples de variables démographiques fréquemment appliquées sont
- l’âge,
- l’ethnicité,
- l’origine nationale,
- l’affiliation religieuse,
- le genre,
- l’orientation sexuelle,
- statut matrimonial/relationship,
- situation professionnelle,
- affiliation politique,
- localisation géographique,
- niveau d’éducation, et
- revenu.
A un niveau plus macro, la démographie d’une communauté ou d’une organisation inclut souvent sa taille ; les organisations sont souvent mesurées en fonction de leur budget global.
Variables indépendantes et dépendantes. Une façon dont les enquêteurs pensent aux variables de l’étude a des implications importantes pour la conception d’une étude. Les enquêteurs décident de les faire servir soit de variables indépendantes, soit de variables dépendantes. Cette distinction n’est pas inhérente à une variable, elle est basée sur la façon dont l’enquêteur choisit de définir chaque variable. Les variables indépendantes sont celles que l’on pourrait considérer comme les variables » d’entrée » manipulées, tandis que les variables dépendantes sont celles où l’impact ou la » sortie » de cette variation d’entrée serait observée.
La manipulation intentionnelle de la variable » d’entrée » (indépendante) n’est pas toujours impliquée. Prenons l’exemple d’une étude menée en Suède qui examine la relation entre le fait d’avoir été victime de maltraitance infantile et l’absentéisme ultérieur au lycée : personne n’a manipulé intentionnellement le fait que les enfants soient ou non victimes de maltraitance infantile (Hagborg, Berglund, & Fahlke, 2017). Les enquêteurs ont émis l’hypothèse que les différences naturelles dans la variable d’entrée (antécédents de maltraitance des enfants) seraient associées à une variation systématique dans une variable de résultat spécifique (absentéisme scolaire). Dans ce cas, la variable indépendante était les antécédents de maltraitance des enfants, et la variable dépendante était le résultat de l’absentéisme scolaire. En d’autres termes, la variable indépendante est supposée par l’enquêteur causer une variation ou un changement dans la variable dépendante. Voici à quoi cela pourrait ressembler dans un diagramme où » x » est la variable indépendante et » y » est la variable dépendante (note : vous avez vu cette désignation plus tôt, au chapitre 3, lorsque nous avons discuté de la logique de cause à effet) :

Pour un autre exemple, considérons une recherche indiquant que le fait d’être victime de maltraitance infantile est associé à un risque plus élevé de consommation de substances à l’adolescence (Yoon, Kobulsky, Yoon, & Kim, 2017). La variable indépendante dans ce modèle serait d’avoir des antécédents de maltraitance envers les enfants. La variable dépendante serait le risque de consommation de substances psychoactives à l’adolescence. Cet exemple est encore plus élaboré car il précise la voie par laquelle la variable indépendante (la maltraitance des enfants) pourrait imposer ses effets sur la variable dépendante (la consommation de substances à l’adolescence). Les auteurs de l’étude ont démontré que le stress post-traumatique (SPT) était un lien entre la maltraitance infantile (physique et sexuelle) et la consommation de substances à l’adolescence.

Prenez un moment pour réaliser l’activité suivante.
Types de variables quantitatives
Il existe également d’autres façons significatives de penser aux variables d’intérêt. Considérons différentes caractéristiques des variables utilisées dans les études de recherche quantitative. Ici, nous explorons les variables quantitatives comme étant de nature catégorielle, ordinale ou d’intervalle. Ces caractéristiques ont des implications à la fois pour la mesure et l’analyse des données.
Variables catégorielles. Certaines variables peuvent prendre des valeurs qui varient, mais pas d’une manière numérique significative. Au lieu de cela, elles peuvent être définies en termes de catégories possibles. Logiquement, on les appelle des variables catégorielles. Les logiciels et les manuels de statistique font parfois référence aux variables catégorielles en tant que variables nominales. Le terme nominal est issu de la racine latine « nom », qui signifie « nom », et ne doit pas être confondu avec le terme « nombre ». Le terme nominal a la même signification que le terme catégorique dans la description des variables. En d’autres termes, les variables catégorielles ou nominales sont identifiées par les noms ou les étiquettes des catégories représentées. Par exemple, la couleur de la dernière voiture dans laquelle vous êtes monté serait une variable catégorielle : bleu, noir, argent, blanc, rouge, vert, jaune ou autre sont des catégories de la variable que nous pourrions appeler couleur de la voiture.
Ce qui est important avec les variables catégorielles, c’est que ces catégories n’ont aucune séquence ou ordre numérique pertinent. Il n’y a pas de différence numérique entre les différentes couleurs de voiture, ou de différence entre « oui » ou « non » comme catégories pour répondre si vous avez roulé dans une voiture bleue. Il n’y a pas d’ordre ou de hiérarchie implicite aux catégories « Hispanique ou Latino » et « Non hispanique ou Latino » dans une variable d’ethnicité ; il n’y a pas non plus d’ordre pertinent aux catégories de variables comme le sexe, l’état ou la région géographique où une personne réside, ou si la résidence d’une personne est en propriété ou en location.
Si un chercheur décide d’utiliser des nombres comme symboles liés aux catégories d’une telle variable, les nombres sont arbitraires – chaque nombre est essentiellement juste un nom différent et plus court pour chaque catégorie. Par exemple, la variable sexe pourrait être codée de la manière suivante, et cela ne ferait aucune différence, tant que le code est appliqué de manière cohérente.
| Option de codage A | Catégories de variables | Option de codage B |
|---|---|---|
| 1 | mâle | 2 |
| 2 | femme | 1 |
| 3 | autre que homme ou femme seul(e) | 4 |
| 4 | préfère ne pas répondre | 3 |
Race et ethnicité.L’une des variables catégorielles les plus couramment explorées dans la recherche en travail social et en sciences sociales est la variable démographique faisant référence à l’origine raciale et/ou ethnique d’une personne. De nombreuses études utilisent les catégories spécifiées dans les anciens rapports du Bureau du recensement des États-Unis. Voici ce que le Bureau du recensement des États-Unis a à dire sur les deux variables démographiques distinctes, la race et l’ethnicité (https://www.census.gov/mso/www/training/pdf/race-ethnicity-onepager.pdf):
Qu’est-ce que la race ? Le Census Bureau définit la race comme l’auto-identification d’une personne à un ou plusieurs groupes sociaux. Un individu peut déclarer être blanc, noir ou afro-américain, asiatique, indien d’Amérique et natif d’Alaska, hawaïen natif et autre insulaire du Pacifique, ou une autre race. Les répondants à l’enquête peuvent déclarer plusieurs races.
Qu’est-ce que l’ethnicité ? L’ethnicité détermine si une personne est d’origine hispanique ou non. Pour cette raison, l’ethnicité est divisée en deux catégories, hispanique ou latino et non hispanique ou latino. Les hispaniques peuvent se déclarer comme n’importe quelle race.
En d’autres termes, le Census Bureau définit deux catégories pour la variable appelée ethnicité (Hispanique ou Latino et Non hispanique ou Latino), et sept catégories pour la variable appelée race. Bien que ces variables et catégories soient souvent appliquées dans la recherche en sciences sociales et en travail social, elles ne sont pas exemptes de critiques.
Sur la base de ces catégories, voici ce que l’on estime être vrai de la population américaine en 2016 :
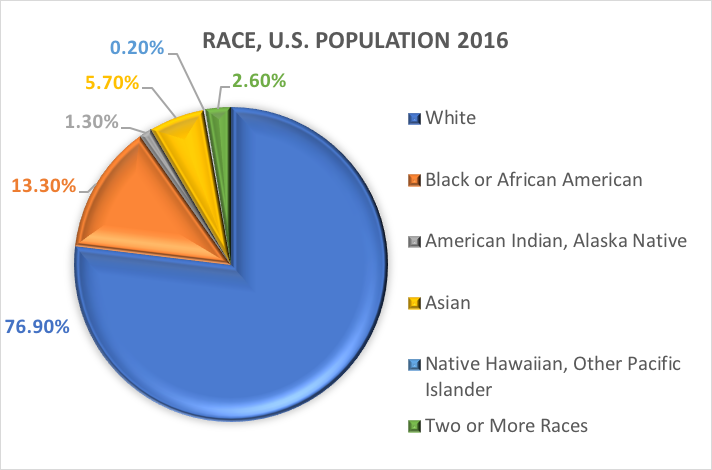
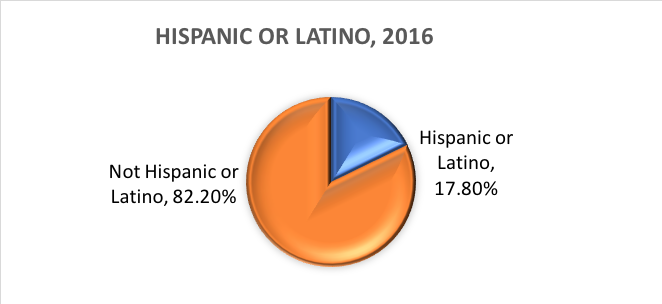
Variables dichotomiques.Il existe une catégorie spéciale de variable catégorielle ayant des implications pour certaines analyses statistiques. Les variables catégorielles composées d’exactement deux options, ni plus ni moins, sont appelées variables dichotomiques. Un exemple est la dichotomie du Bureau de recensement des États-Unis entre l’ethnicité hispanique/latino et non hispanique/non latino. Autre exemple : les enquêteurs peuvent souhaiter comparer les personnes qui terminent leur traitement avec celles qui l’abandonnent avant de l’avoir terminé. Avec les deux catégories, terminé ou non terminé, cette variable d’achèvement du traitement n’est pas seulement catégorique, elle est dichotomique. Les variables où les individus répondent « oui » ou « non » sont également de nature dichotomique.
La tradition passée de traiter le genre comme étant soit masculin soit féminin est un autre exemple de variable dichotomique. Cependant, des arguments très forts existent pour ne plus traiter le genre de cette manière dichotomique : une plus grande variété d’identités de genre est manifestement pertinente dans le travail social pour les personnes dont l’identité ne s’aligne pas sur les catégories dichotomiques (également appelées binaires) homme/femme ou homme/femme. Il s’agit de catégories telles que agender, androgyne, bigender, cisgenre, genre expansif, genre fluide, genre en questionnement, queer, transgenre, et autres.
Variables ordinales. Contrairement à ces variables catégorielles, il arrive que les catégories d’une variable aient une séquence numérique ou un ordre logique. Ordinal, par définition, fait référence à une position dans une série. Les variables dont les catégories sont numériquement pertinentes sont appelées variables ordinales. Par exemple, il existe un ordre implicite des catégories du moins au plus avec la variable appelée niveau d’instruction. Les catégories des données du U.S. Les catégories de données du recensement américain pour cette variable ordinale sont :
- aucune
- 1ère-4ème classe
- 5ème-6ème classe
- 7ème-8ème classe
- 9ème classe
- 10ème classe
- 11ème classe
- diplômé de l’enseignement secondaire
- quelques études universitaires, aucun diplôme
- un diplôme d’associé, professionnel
- diplôme d’associé académique
- baccalauréat
- maître
- diplôme professionnel
- doctorat
En examinant les données d’estimation du Bureau du recensement de 2016 pour cette variable, nous pouvons voir que les femmes sont plus nombreuses que les hommes dans la catégorie des personnes ayant obtenu un baccalauréat : sur les 47 718 000 personnes de cette catégorie, 22 485 000 étaient des hommes et 25 234 000 des femmes. Si ce schéma sexué se vérifie pour les titulaires d’une maîtrise, il s’inverse pour les titulaires d’un doctorat : les hommes sont plus nombreux que les femmes à avoir obtenu ce niveau d’études le plus élevé. Il est également intéressant de noter que les femmes étaient plus nombreuses que les hommes à l’extrémité inférieure du spectre : 441 000 femmes ont déclaré n’avoir reçu aucune éducation, contre 374 000 hommes.
Voici un autre exemple de l’utilisation de variables ordinales dans la recherche en travail social : lorsque des personnes demandent un traitement pour un problème d’abus d’alcool, les travailleurs sociaux peuvent souhaiter savoir s’il s’agit de leur première, deuxième, troisième ou toute autre tentative sérieuse numérotée de changer leur comportement de consommation. Les participants inscrits à une étude comparant les approches de traitement des troubles liés à la consommation d’alcool ont déclaré que l’étude d’intervention constituait entre leur première et leur onzième tentative de changement significatif (Begun, Berger, Salm-Ward, 2011). Cette variable de tentative de changement a des implications sur la façon dont les travailleurs sociaux pourraient interpréter les données évaluant une intervention qui n’était pas le premier essai pour toutes les personnes impliquées.
Échelles de notation. Considérons un type différent mais couramment utilisé de variable ordinale : les échelles d’évaluation. Les enquêteurs sociaux, comportementaux et du travail social demandent souvent aux participants à l’étude d’appliquer une échelle d’évaluation pour décrire leurs connaissances, attitudes, croyances, opinions, compétences ou comportements. Parce que les catégories sur une telle échelle sont séquencées (de la plus à la moins ou de la moins à la plus), nous appelons ces variables ordinales.

On peut par exemple demander aux participants d’évaluer :
- à quel point ils sont d’accord ou non avec certaines déclarations (pas du tout à extrêmement beaucoup);
- à quelle fréquence ils adoptent certains comportements (jamais à toujours);
- à quelle fréquence ils adoptent certains comportements (toutes les heures, tous les jours, toutes les semaines, tous les mois, tous les ans ou moins souvent) ;
- la qualité de la performance de quelqu’un (médiocre à excellente);
- le degré de satisfaction de leur traitement (très insatisfait à très satisfait)
- leur niveau de confiance (très faible à très élevé).
Variables intervalles. D’autres variables encore prennent des valeurs qui varient de manière numérique significative. Dans notre liste de variables démographiques, l’âge est un exemple courant. La valeur numérique attribuée à une personne individuelle indique le nombre d’années écoulées depuis sa naissance (dans le cas des nourrissons, la valeur numérique peut indiquer des jours, des semaines ou des mois depuis la naissance). Ici, les valeurs possibles de la variable sont ordonnées, comme pour les variables ordinales, mais une grande différence est introduite : la nature des intervalles entre les valeurs possibles. Avec les variables d’intervalle, la « distance » entre les valeurs possibles adjacentes est égale. Certains logiciels et manuels statistiques utilisent le terme de variable d’échelle : c’est exactement la même chose que ce que nous appelons une variable d’intervalle.
Par exemple, dans le graphique ci-dessous, la différence de 1 once entre cette personne consommant 1 once ou 2 onces d’alcool (lundi, mardi) est exactement la même que la différence de 1 once entre la consommation de 4 onces ou 5 onces (vendredi, samedi). Si nous devions schématiser les points possibles sur l’échelle, ils seraient tous équidistants ; l’intervalle entre deux points est mesuré en unités standard (onces, dans cet exemple).
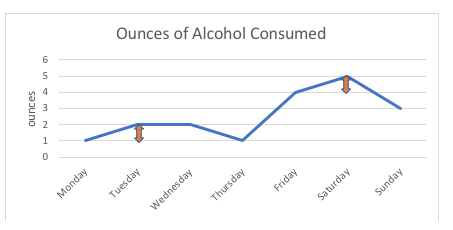
Avec des variables ordinales, comme une échelle d’évaluation, personne ne peut dire avec certitude que la » distance » entre les options de réponse » jamais » et » parfois » est la même que la » distance » entre » parfois » et » souvent « , même si nous utilisions des chiffres pour séquencer ces options de réponse. Ainsi, l’échelle d’évaluation reste ordinale, et non pas d’intervalle.
Ce qui peut devenir un peu déroutant, c’est que certains logiciels statistiques, comme SPSS, font référence à une variable d’intervalle comme une variable d' » échelle « . De nombreuses variables utilisées dans la recherche en travail social sont à la fois ordonnées et ont des distances égales entre les points. Prenons par exemple la variable de l’ordre de naissance. Cette variable est d’intervalle parce que :
- les valeurs possibles sont ordonnées (par exemple, le troisième né est venu après le premier et le deuxième né et avant le quatrième né), et
- les « distances » ou intervalles sont mesurés en unités équivalentes d’une personne.
Variables continues. Il existe un type spécial de variable numérique d’intervalle que nous appelons variables continues. Une variable comme l’âge pourrait être traitée comme une variable continue. L’âge est de nature ordinale, puisque les nombres plus élevés signifient quelque chose par rapport aux nombres plus petits. L’âge répond également à nos critères de variable d’intervalle si nous le mesurons en années (ou en mois, en semaines ou en jours) car il est ordinal et il existe la même « distance » entre 15 et 30 ans qu’entre 40 et 55 ans (15 années civiles). Ce qui en fait une variable continue, c’est qu’il existe également des points de « fraction » possibles et significatifs entre deux intervalles quelconques. Par exemple, une personne peut avoir 20½ (20,5) ou 20¼ (20,25) ou 20¾ (20,75) ans ; nous ne sommes pas limités aux seuls nombres entiers pour l’âge. En revanche, lorsque nous avons examiné l’ordre de naissance, nous ne pouvons pas avoir une fraction significative d’une personne entre deux positions sur l’échelle.
Le cas particulier du revenu. L’une des variables les plus malmenées dans la recherche en sciences sociales et en travail social est la variable liée au revenu. Prenons un exemple sur le revenu du ménage (quel que soit le nombre de personnes dans le ménage). Cette variable pourrait être catégorique (nominale), ordinale ou d’intervalle (échelle) selon la façon dont elle est traitée.
Exemple catégorique : Selon la nature des questions de recherche, un enquêteur pourrait simplement choisir d’utiliser les catégories dichotomiques de « ressources suffisantes » et « ressources insuffisantes » pour classer les ménages, sur la base d’une méthode de calcul standard. Ceux-ci pourraient être appelés « pauvres » et « non pauvres » si un seuil de pauvreté est utilisé pour classer les ménages. Ces catégories distinctes de variable de revenu ne sont pas séquencées de manière significative de façon numérique, il s’agit donc d’une variable catégorielle.
Exemple ordonné : Les catégories pour classer les ménages pourraient être ordonnées de faible à élevé. Par exemple, ces catégories de revenu annuel sont courantes dans les études de marché :
- Moins de 25 000 $.
- 25 000 à 34 999 $.
- 35 000 à 49 999 $.
- 50 000 à 74 999 $.
- 75 000 à 99 999 $.
- 100 000 $ à 149 999 $.
- 150 000 $ à 199 999 $.
- 200 000 $ ou plus.
Notez que les catégories ne sont pas de taille égale – la « distance » entre les paires de catégories n’est pas toujours la même. Elles commencent par des incréments d’environ 10 000 $, passent à des incréments de 25 000 $ et finissent par des incréments d’environ 50 000 $.
Exemple d’intervalle. Si un enquêteur demandait aux participants à l’étude de déclarer un montant réel en dollars pour le revenu du ménage, nous verrions une variable d’intervalle. Les valeurs possibles sont ordonnées et l’intervalle entre toutes les unités adjacentes possibles est de 1 $ (tant que les fractions de dollars ou les cents ne sont pas utilisés). Ainsi, un revenu de 10 452 $ est à la même distance sur un continuum de 9 452 $ et de 11 452 $ – 1 000 $ dans les deux cas.

Le cas particulier de l’âge. Comme le revenu, l' »âge » peut avoir des significations différentes selon les études. L’âge est généralement un indicateur du « temps écoulé depuis la naissance ». On peut calculer l’âge d’une personne en soustrayant une variable de date de naissance à la date de mesure (date du jour moins date de naissance). Pour les adultes, les âges sont généralement mesurés en années où les valeurs adjacentes possibles sont distancées par des unités d’un an : 18, 19, 20, 21, 22, et ainsi de suite. Ainsi, la variable d’âge pourrait être un type continu de variable d’intervalle.
Cependant, un enquêteur pourrait souhaiter réduire les données d’âge en catégories ordonnées ou en groupes d’âge. Ceux-ci seraient encore ordinaux, mais pourraient ne plus être des intervalles si les incréments entre les valeurs possibles ne sont pas des unités équivalentes. Par exemple, si nous sommes plus intéressés par l’âge représentant des périodes spécifiques du développement humain, les intervalles d’âge pourraient ne pas être égaux dans l’étendue entre les critères d’âge. Ils pourraient éventuellement être :
- Infantile (naissance à 18 mois)
- Petite enfance (18 mois à 2 ½ ans)
- Préscolaire (2 ½ à 5 ans)
- Age scolaire (6 à 11 ans)
- Adolescence (12 à 17 ans)
- Adolescence émergente (18 à 25 ans)
- Adolescence (26 à 45 ans)
- Adolescence moyenne (46 à 60 ans)
- Jeune-.Old Adulthood (60 à 74 ans)
- Middle-Old Adulthood (75 à 84 ans)
- Old-Old Adulthood (85 ans ou plus)
.
L’âge pourrait même être traité comme une variable strictement catégorielle (non ordinale). Par exemple, si la variable d’intérêt est de savoir si une personne a l’âge légal pour boire (21 ans ou plus), ou non. Nous avons deux catégories – répond ou ne répond pas aux critères de l’âge légal de consommation d’alcool aux États-Unis – et l’une ou l’autre pourrait être codée avec un « 1 » et l’autre avec un « 0 » ou un « 2 » sans différence de signification.
Quelle est la « bonne » réponse quant à la façon de mesurer l’âge (ou le revenu) ? La réponse est « ça dépend ». Ce qui dépend, c’est la nature de la question de recherche : quelle conceptualisation de l’âge (ou du revenu) est la plus pertinente pour l’étude conçue.
Variables alphanumériques. Enfin, il existe des données qui ne correspondent à aucune de ces classifications. Parfois, les informations que nous connaissons se présentent sous la forme d’une adresse ou d’un numéro de téléphone, d’un prénom ou d’un nom, d’un code postal ou d’autres phrases. Ces types d’informations sont parfois appelés variables alphanumériques. Prenons l’exemple de la variable « adresse » : l’adresse d’une personne peut être composée de caractères numériques (le numéro de la maison) et de lettres (les noms de la rue, de la ville et de l’État), comme 1600 Pennsylvania Ave. NW, Washington, DC, 20500.

En réalité, nous avons plusieurs variables présentes dans cet exemple d’adresse :
- l’adresse de la rue : 1600 Pennsylvania Ave.
- la ville (et « l’état ») : Washington, DC
- le code postal : 20500.
Ce type d’information ne représente pas des catégories quantitatives spécifiques ou des valeurs ayant une signification systématique dans les données. Elles sont aussi parfois appelées variables « string » dans certains logiciels car elles sont constituées d’une chaîne de symboles. Pour être utile à un enquêteur, une telle variable devrait être convertie ou recodée en valeurs significatives.
Une remarque sur l’unité d’analyse
Une chose importante à garder à l’esprit en pensant aux variables est que les données peuvent être collectées à de nombreux niveaux d’observation différents. Les éléments étudiés peuvent être des cellules individuelles, des systèmes d’organes ou des personnes. Le niveau d’observation peut aussi être constitué de paires d’individus, comme des couples, des frères et sœurs ou des dyades parents-enfants. Dans ce cas, l’enquêteur peut recueillir des informations sur la paire auprès de chaque individu, mais il étudie les données de chaque paire. Ainsi, nous dirions que l’unité d’analyse est la paire ou la dyade, et non chaque personne individuelle. L’unité d’analyse peut également être un groupe plus important : par exemple, les données peuvent être collectées auprès de chacun des élèves d’une classe entière lorsque l’unité d’analyse est la classe d’une école ou d’un système scolaire. L’unité d’analyse peut également se situer au niveau des quartiers, des programmes, des organisations, des comtés, des états ou même des nations. Par exemple, de nombreuses variables utilisées comme indicateurs de la sécurité alimentaire au niveau des communautés, telles que l’abordabilité et l’accessibilité, sont basées sur des données recueillies auprès de ménages individuels (Kaiser, 2017). L’unité d’analyse dans les études utilisant ces indicateurs serait les communautés comparées. Cette distinction a des implications importantes en matière de mesure et d’analyse des données.
Un rappel sur les variables par rapport aux niveaux de variables
Une étude pourrait être décrite en termes de nombre de catégories de variables, ou niveaux, qui sont comparées. Par exemple, vous pouvez voir une étude décrite comme une conception 2 X 2 – prononcée comme une conception deux par deux. Cela signifie qu’il existe deux catégories possibles pour la première variable et deux catégories possibles pour l’autre variable – ce sont toutes deux des variables dichotomiques. Une étude comparant 2 catégories de la variable « trouble de la consommation d’alcool » (catégories pour répondre aux critères, oui ou non) à 2 catégories de la variable « trouble de la consommation de substances illicites » (catégories pour répondre aux critères, oui ou non) aurait 4 résultats possibles (mathématiquement, 2 x 2=4) et pourrait être schématisée comme suit (données basées sur les proportions de l’enquête NSDUH 2016, présentées dans SAMHSA, 2017) :
| Trouble de l’usage de substances illicites (SUD) | |||
|---|---|---|---|
|
Trouble de l’usage d’alcool (AUD) |
Non | Oui | |
| Non | 500 | 10 | |
| Oui | 26 | 4 | |
La lecture des 4 cellules de ce tableau 2 X 2 nous indique que dans cette enquête (hypothétique) de 540 individus, 500 ne répondaient pas aux critères d’un trouble lié à la consommation d’alcool ou de substances illicites (Non, Non) ; 26 répondaient aux critères d’un trouble lié à la consommation d’alcool uniquement (Oui, Non) ; 10 répondaient aux critères d’un trouble lié à la consommation de substances illicites uniquement (Non, Oui), et 4 répondaient aux critères d’un trouble lié à la consommation d’alcool et de substances illicites (Oui, Oui). De plus, en faisant un peu de mathématiques, nous pouvons voir qu’un total de 30 personnes avaient un trouble lié à la consommation d’alcool (26 + 4) et 14 avaient un trouble lié à la consommation de substances illicites (10 + 4). Et, nous pouvons voir que 40 avaient une sorte de trouble de la consommation de substances (26 + 10 + 4).
 Pour que cette distinction entre variables et niveaux ou catégories de variables soit claire comme de l’eau de roche, considérons un autre exemple : un plan d’étude 2 X 3. Premièrement, en faisant le calcul, nous devrions voir 6 résultats possibles (cellules). Ensuite, nous savons que la première variable (groupe d’âge) comporte 2 catégories (moins de 30 ans, 30 ans ou plus) et que l’autre variable (situation professionnelle) comporte 3 catégories (plein emploi, emploi partiel, chômage). Cette fois, les 6 cellules de notre plan sont vides car nous attendons les données.
Pour que cette distinction entre variables et niveaux ou catégories de variables soit claire comme de l’eau de roche, considérons un autre exemple : un plan d’étude 2 X 3. Premièrement, en faisant le calcul, nous devrions voir 6 résultats possibles (cellules). Ensuite, nous savons que la première variable (groupe d’âge) comporte 2 catégories (moins de 30 ans, 30 ans ou plus) et que l’autre variable (situation professionnelle) comporte 3 catégories (plein emploi, emploi partiel, chômage). Cette fois, les 6 cellules de notre plan sont vides car nous attendons les données.
| Situation d’emploi | |||||
|---|---|---|---|---|---|
|
Groupe d’âge |
Tout à fait employé | Partiellement employé | . Employé | Chômage | |
| <30 | |||||
| ≥30 | |||||
Ainsi , lorsque vous voyez une description de plan d’étude qui ressemble à deux nombres multipliés, cela vous indique essentiellement combien de catégories ou de niveaux de chaque variable il y a et vous amène à comprendre combien de cellules ou de résultats possibles existent. Un plan d’étude 3 X 3 comporte 9 cellules, un plan d’étude 3 X 4 comporte 12 cellules, et ainsi de suite. Cette question redevient importante lorsque nous discutons de la taille de l’échantillon au chapitre 6.
Complétez l’activité suivante du cahier d’exercices:
- SWK 3401.3-4.1 Beginning Data Entry
Chapter Summary
En résumé, les enquêteurs conçoivent un grand nombre de leurs études quantitatives pour tester des hypothèses sur les relations entre les variables. Comprendre la nature des variables impliquées aide à comprendre et à évaluer la recherche menée. La compréhension des distinctions entre les différents types de variables, ainsi qu’entre les variables et les catégories, a des implications importantes pour la conception des études, les mesures et les échantillons. Entre autres sujets, le prochain chapitre explore l’intersection entre la nature des variables étudiées dans la recherche quantitative et la façon dont les enquêteurs entreprennent de mesurer ces variables.
Prenez un moment pour réaliser l’activité suivante.