
- Egy gyors áttekintés a képosztályozás legjobb tanulmányairól az elmúlt egy évtizedben, hogy beindítsd a tanulást. számítógépes látás
- 1998: LeNet
- 2012: AlexNet
- 2014: VGG
- 2014: GoogLeNet
- 2015: Batch Normalization
- 2015: ResNet
- 2016: Xception
- 2017: MobileNet
- 2017: NASNet
- 2019: EfficientNet
- 2014: SPPNet
- 2016: DenseNet
- 2017: SENet
- 2017: ShuffleNet
- 2018: Bag of Tricks
- Következtetés
Egy gyors áttekintés a képosztályozás legjobb tanulmányairól az elmúlt egy évtizedben, hogy beindítsd a tanulást. számítógépes látás

A számítógépes látás a képek és videók gépi átalakításával foglalkozó téma.érthető jelekké alakítani. Ezekkel a jelekkel a programozók a magas szintű megértés alapján tovább tudják irányítani a gép viselkedését. A számítógépes látás számos feladata közül a képosztályozás az egyik legalapvetőbb. Nemcsak számos valós termékben használható, mint például a Google Photo címkézése és a mesterséges intelligencia alapú tartalommoderálás, hanem számos fejlettebb látásfeladat, például a tárgyak felismerése és a videók megértése előtt is megnyitja az utat. A Deep Learning áttörése óta ezen a területen bekövetkezett gyors változások miatt a kezdők számára gyakran túl nehézkes a tanulás. A tipikus szoftvermérnöki témákkal ellentétben nem sok nagyszerű könyv létezik a DCNN használatával történő képosztályozásról, és a terület megértésének legjobb módja a tudományos cikkek olvasása. De milyen tanulmányokat olvassunk? Hol kezdjem? Ebben a cikkben bemutatom a 10 legjobb dolgozatot, amelyet kezdőknek érdemes elolvasni. Ezekkel a papírokkal láthatjuk, hogyan fejlődik ez a terület, és hogyan hoztak fel új ötleteket a kutatók a korábbi kutatási eredmények alapján. Mindazonáltal akkor is hasznos, ha már egy ideje ezen a területen dolgozol, hogy rendszerezd az összképet. Tehát kezdjük el.
1998: LeNet
Gradient-based Learning Applied to Document Recognition

Bemutatkozott 1998-ban, LeNet megalapozza a konvolúciós neurális hálózatot használó jövőbeli képosztályozási kutatásokat. Számos klasszikus CNN-technikát, például pooling rétegeket, teljesen összekapcsolt rétegeket, kitöltést és aktiválási rétegeket használnak a jellemzők kinyeréséhez és az osztályozáshoz. A Mean Square Error veszteségfüggvénnyel és 20 epochás képzéssel ez a hálózat 99,05%-os pontosságot tud elérni az MNIST tesztkészleten. Még 20 év elteltével is sok korszerű osztályozóhálózat általában ezt a mintát követi.
2012: AlexNet
ImageNet Classification with Deep Convolutional Neural Networks

.
Bár a LeNet nagyszerű eredményt ért el, és megmutatta a CNN-ben rejlő lehetőségeket, a fejlesztés ezen a területen egy évtizeden át stagnált a korlátozott számítási teljesítmény és az adatok mennyisége miatt. Úgy tűnt, hogy a CNN csak néhány egyszerű feladatot, például a számjegyfelismerést képes megoldani, de az összetettebb jellemzők, például az arcok és a tárgyak esetében a HarrCascade vagy a SIFT jellemző-kivonatoló SVM osztályozóval előnyösebb megközelítés volt.
A 2012-es ImageNet Large Scale Visual Recognition Challenge versenyen azonban Alex Krizhevsky CNN-alapú megoldást javasolt erre a kihívásra, és drasztikusan, 73,8%-ról 84,7%-ra növelte az ImageNet tesztkészlet top-5 pontosságát. Megközelítésük a többrétegű CNN ötletét a LeNet-től örökölte, de a CNN méretét jelentősen megnövelte. Amint a fenti ábrán látható, a bemenet immár 224×224-es a LeNet 32×32-es méretével szemben, továbbá sok konvolúciós mag 192 csatornával rendelkezik a LeNet 6 csatornájával szemben. Bár a felépítés nem sokat változott, a több százszor több paraméterrel a hálózat komplex jellemzők megragadására és reprezentálására való képessége is több százszorosára javult. Egy ekkora modell betanításához Alex két GTX 580 GPU-t használt, mindegyikhez 3 GB RAM-mal, ami úttörő volt a GPU-tanítás trendjében. Emellett a ReLU nemlinearitás használata is segített a számítási költségek csökkentésében.
Amellett, hogy sokkal több paramétert hozott a hálózat számára, a Dropout réteg használatával a nagyobb hálózat által hozott túlillesztési problémát is feltárta. A Local Response Normalization módszere később nem kapott túl nagy népszerűséget, de inspirált más fontos normalizációs technikákat, például a BatchNormot a gradiens telítődés problémájának leküzdésére. Összefoglalva, az AlexNet a következő 10 évre meghatározta a de facto osztályozási hálózati keretrendszert: a konvolúció, a ReLu nemlineáris aktiválás, a MaxPooling és a sűrű réteg kombinációja.
2014: VGG
Very Deep Convolutional Networks for Large-Scale Image Recognition
Mivel ilyen nagy sikert aratott a CNN használata vizuális felismeréshez, az egész kutatóközösség felrobbant, és mindenki elkezdte vizsgálni, hogy miért működik ilyen jól ez a neurális hálózat. Matthew Zeiler például a 2013-as “Visualizing and Understanding Convolutional Networks” című könyvében arról értekezett, hogy a CNN hogyan veszi fel a jellemzőket, és hogyan vizualizálja a köztes reprezentációkat. És hirtelen mindenki kezdett rájönni, hogy 2014 óta a CNN a számítógépes látás jövője. A közvetlen követők közül a Visual Geometry Grouptól származó VGG hálózat a legszembetűnőbb. Figyelemre méltó eredményt ért el: 93,2%-os top-5 pontosságot és 76,3%-os top-1 pontosságot az ImageNet tesztkészleten.
A VGG hálózat az AlexNet tervezését követve két jelentős frissítéssel rendelkezik: 1) A VGG nemcsak szélesebb hálózatot használt, mint az AlexNet, hanem mélyebbet is. A VGG-19 19 konvolúciós réteggel rendelkezik, szemben az AlexNet 5 rétegével. 2) A VGG azt is megmutatta, hogy néhány kis 3×3-as konvolúciós szűrő helyettesítheti az AlexNet egyetlen 7×7-es vagy akár 11×11-es szűrőjét, jobb teljesítményt érhet el, miközben csökkenti a számítási költségeket. Ennek az elegáns kialakításnak köszönhetően a VGG más számítógépes látási feladatokban is számos úttörő hálózat háttérhálózata lett, mint például az FCN a szemantikus szegmentáláshoz és a Faster R-CNN a tárgyak felismeréséhez.
Mélyebb hálózat esetén a többrétegű visszaterjedésből származó gradiens eltűnése nagyobb problémává válik. Ennek kezelésére a VGG az előképzés és a súlyinicializálás fontosságát is tárgyalta. Ez a probléma korlátozza a kutatókat, hogy folyamatosan több réteget adjanak hozzá, különben a hálózat nagyon nehéz lesz konvergálni. De erre két év múlva jobb megoldást fogunk látni.
2014: GoogLeNet
Going Deeper with Convolutions

VGG jól néz ki és könnyen érthető szerkezete van, de a teljesítménye nem a legjobb az ImageNet 2014 versenyek döntősei között. A GoogLeNet, azaz az InceptionV1 nyerte a végső díjat. A VGG-hez hasonlóan a GoogLeNet egyik fő hozzájárulása az, hogy 22 rétegű struktúrájával a hálózat mélységének határát feszegeti. Ez ismét bebizonyította, hogy a mélyebb és szélesebb hálózat valóban a helyes irány a pontosság javítása érdekében.
A VGG-vel ellentétben a GoogLeNet megpróbálta közvetlenül kezelni a számítási és gradienscsökkenési problémákat, ahelyett, hogy jobb előre betanított sémával és súlyok inicializálásával próbált volna megoldást javasolni.

Először is az aszimmetrikus hálózattervezés ötletét vizsgálta az Inception nevű modul segítségével (lásd a fenti ábrát). Ideális esetben ritka konvolúciót vagy sűrű rétegeket szeretnének folytatni a funkciók hatékonyságának javítása érdekében, de a modern hardvertervezés nem erre az esetre volt szabva. Ezért úgy gondolták, hogy a hálózati topológia szintjén a ritkaság a funkciók fúzióját is segítheti, miközben kihasználja a meglévő hardveres képességeket.
Második lépésként a magas számítási költség problémáját támadják a “Hálózat a hálózatban” című tanulmányból kölcsönzött ötlet segítségével. Alapvetően egy 1×1 konvolúciós szűrőt vezetnek be a jellemzők dimenzióinak csökkentésére, mielőtt nehéz számítási műveleten mennének keresztül, mint egy 5×5 konvolúciós mag. Ezt a struktúrát később “Bottleneck”-nek nevezik, és széles körben használják számos következő hálózatban. Hasonlóan a “Hálózat a hálózatban”-hoz, a költségek további csökkentése érdekében egy átlagos pooling réteget is használt a végső, teljesen összekapcsolt réteg helyettesítésére.
Harmadszor, a gradiensek mélyebb rétegekbe való áramlásának elősegítése érdekében a GoogLeNet felügyeletet is alkalmazott néhány köztes réteg kimenetén vagy segédkimenetén. Ez a kialakítás később a képosztályozó hálózatban a bonyolultság miatt nem elég népszerű, de egyre népszerűbb a számítógépes látás más területein, például a Hourglass-hálózat a pózbecslésben.
Következtetésként ez a Google-csapat további cikkeket írt ehhez az Inception-sorozathoz. “Batch normalizáció: Accelerating Deep Network Training by Reducing Internal Covariate Shift” áll az InceptionV2-ben. A 2015-ös “Rethinking the Inception Architecture for Computer Vision” az InceptionV3-at jelöli. A 2015-ös “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning” pedig az InceptionV4-et jelenti. Mindegyik cikk további fejlesztéseket tett hozzá az eredeti Inception-hálózathoz képest, és jobb eredményt ért el.
2015: Batch Normalization
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Az Inception hálózat segítségével a kutatók emberfeletti pontosságot értek el az ImageNet adathalmazon. Azonban mint statisztikai tanulási módszer, a CNN nagyon erősen kötődik egy adott képzési adathalmaz statisztikai jellegéhez. Ezért a jobb pontosság elérése érdekében általában előzetesen ki kell számolnunk a teljes adathalmaz átlagát és szórását, és ezeket először a bemenetünk normalizálására kell használnunk, hogy a hálózatban a legtöbb réteg bemenete közel legyen egymáshoz, ami jobb aktiválási reakciókészséget jelent. Ez a közelítő megközelítés nagyon nehézkes, és néha egyáltalán nem működik egy új hálózati struktúra vagy egy új adatkészlet esetében, így a mélytanulási modell továbbra is nehezen képezhetőnek tekinthető. Ennek a problémának a megoldására Sergey Ioffe és Chritian Szegedy, a GoogLeNet megalkotója úgy döntött, hogy kitalálnak valami okosabbat, amit Batch Normalizationnek hívnak.

A tételes normalizálás ötlete nem nehéz: egy sor minitétel statisztikáját felhasználhatjuk a teljes adathalmaz statisztikájának közelítésére, amennyiben elég hosszú ideig edzünk. Emellett a statisztikák kézi kiszámítása helyett bevezethetünk két további tanulható paramétert, a “scale”-t és a “shift”-et, hogy a hálózat magától megtanulja, hogyan kell az egyes rétegeket normalizálni.
A fenti ábra a kötegnormálási értékek kiszámításának folyamatát mutatta be. Mint látható, az egész minitétel átlagát vesszük, és kiszámítjuk a varianciát is. Ezután ezzel a minitétel átlaggal és varianciával normalizálhatjuk a bemenetet. Végül egy skála és egy eltolási paraméter segítségével a hálózat megtanulja, hogy a tétel normalizált eredményt a következő rétegekhez, általában a ReLU-hoz igazítsa a legjobban. Az egyik kikötés az, hogy a következtetés során nem rendelkezünk mini-batch információval, ezért a megoldás az, hogy a képzés során mozgóátlag-átlagot és varianciát számolunk, majd ezeket a mozgóátlagokat használjuk a következtetési útvonalban. Ez a kis újítás annyira hatásos, hogy az összes későbbi hálózat azonnal használni kezdi.
2015: ResNet
Deep Residual Learning for Image Recognition
2015 talán a legjobb év a számítógépes látás számára az elmúlt évtizedben, annyi nagyszerű ötletet láttunk felbukkanni nemcsak a képosztályozásban, hanem mindenféle számítógépes látási feladatban, mint például a tárgyfelismerés, szemantikus szegmentálás stb. A 2015-ös év legnagyobb előrelépése a ResNet, azaz reziduális hálózatok nevű új hálózathoz tartozik, amelyet a Microsoft Research Asia kínai kutatócsoportja javasolt.

Amint korábban a VGG hálózat esetében tárgyaltuk, a még mélyebbre jutás legnagyobb akadálya a gradiens eltűnésének problémája, ill.azaz a deriváltak egyre kisebbek lesznek a mélyebb rétegeken való visszaterjedés során, és végül elér egy olyan pontot, amelyet a modern számítógép-architektúra nem igazán tud értelmesen ábrázolni. A GoogLeNet megpróbálta ezt megtámadni a segédfelügyelet és az aszimmetrikus befogadó modul használatával, de ez csak kis mértékben enyhíti a problémát. Ha 50 vagy akár 100 réteget akarunk használni, lesz-e jobb módja annak, hogy a gradiens a hálózaton keresztül áramoljon? A ResNet válasza a reziduális modul használata.

ResNet hozzáadott egy identitás rövidítést a kimenethez, így minden reziduális modul legalább azt tudja megjósolni, ami a bemenet, anélkül, hogy elveszne a vadonban. Még fontosabb dolog, hogy ahelyett, hogy abban reménykedne, hogy minden réteg közvetlenül illeszkedik a kívánt jellemző leképezéshez, a reziduális modul megpróbálja megtanulni a kimenet és a bemenet közötti különbséget, ami sokkal könnyebbé teszi a feladatot, mert a szükséges információnyereség kisebb. Képzeljük el, hogy matematikát tanulunk, minden új problémához kapunk egy hasonló probléma megoldását, így csak annyit kell tennünk, hogy ezt a megoldást kibővítjük, és megpróbáljuk működőképessé tenni. Ez sokkal egyszerűbb, mint minden egyes problémára, amibe belefutsz, egy teljesen új megoldást kitalálni. Vagy ahogy Newton mondta, óriások vállán állhatunk, és az identitás bemenet ez az óriás a reziduális modul számára.
Az identitás leképezés mellett a ResNet a szűk keresztmetszetet és a tételes normalizálást is az Inception hálózatokból kölcsönözte. Végül sikerült egy 152 konvolúciós réteggel rendelkező hálózatot építeni, és 80,72%-os top-1 pontosságot ért el az ImageNet-en. A reziduális megközelítés később számos más hálózat alapértelmezett opciójává is vált, mint például az Xception, a Darknet stb. Emellett egyszerű és szép kialakításának köszönhetően manapság is széles körben használják számos gyártósori vizuális felismerő rendszerben.
A reziduális hálózat hype-ját követve sok további invariáns jött ki. Az “Identity Mappings in Deep Residual Networks” című könyvben a ResNet eredeti szerzője megpróbálta az aktiválást a reziduális modul elé helyezni, és jobb eredményt ért el, és ezt a tervezést ResNetV2-nek nevezték el azután. Továbbá az “Aggregated Residual Transformations for Deep Neural Networks” című 2016-os cikkben a kutatók javasolták a ResNeXt, amely párhuzamos ágakat adott a reziduális modulokhoz a különböző transzformációk kimeneteinek aggregálásához.
2016: Xception
Xception: Deep Learning with Depthwise Separable Convolutions

A ResNet megjelenésével úgy tűnt, hogy a képosztályozóban a legtöbb alacsonyan lógó gyümölcsöt már lekapkodták. A kutatók elkezdtek azon gondolkodni, hogy mi lehet a CNN varázslatos belső mechanizmusa. Mivel a keresztcsatornás konvolúció általában rengeteg paramétert vezet be, az Xception hálózatot választották e művelet vizsgálatára, hogy teljes képet kapjanak a hatásáról.
Az Xception a nevéhez hasonlóan az Inception hálózatból származik. Az Inception modulban a topológia ritkaságának elérése érdekében a különböző transzformációk több ága összevonásra kerül. De miért működött ez a ritkaság? Az Xception szerzője, aki egyben a Keras keretrendszer szerzője is, ezt az ötletet kiterjesztette egy extrém esetre, ahol egy 3×3 konvolúciós fájl egy kimeneti csatornának felel meg a végső összefűzés előtt. Ebben az esetben ezek a párhuzamos konvolúciós kernelek valójában egy új műveletet alkotnak, amelyet mélységi konvolúciónak nevezünk.

A fenti ábrán látható módon, a hagyományos konvolúcióval ellentétben, ahol az összes csatornát egy számításba vonjuk be, a mélység szerinti konvolúció csak az egyes csatornák konvolúcióját számítja külön-külön, majd a kimenetet összevonja. Ez csökkenti a csatornák közötti jellemzőcserét, de sok kapcsolatot is csökkent, így kevesebb paraméterrel rendelkező réteget eredményez. Ez a művelet azonban ugyanannyi csatornát ad ki, mint a bemenet (Vagy kisebb számú csatornát, ha két vagy több csatornát csoportosít). Ezért, miután a csatornák kimeneteit összevontuk, szükségünk van egy másik szabályos 1×1 szűrőre, vagy pontszerű konvolúcióra, hogy növeljük vagy csökkentsük a csatornák számát, ahogy a szabályos konvolúció is teszi.
Ez az ötlet eredetileg nem az Xceptionből származik. A “Vizuális reprezentációk tanulása skálán” című dolgozatban van leírva, és az InceptionV2-ben is használják alkalmanként. Az Xception egy lépéssel továbbment, és szinte minden konvolúciót ezzel az új típussal helyettesített. És a kísérlet eredménye elég jónak bizonyult. Túlszárnyalta a ResNet-et és az InceptionV3-at, és a képosztályozás új SOTA-módszerévé vált. Ez azt is bizonyította, hogy a csatornák közötti korrelációk és a térbeli korrelációk leképezése a CNN-ben teljesen szétválasztható. Ráadásul az Xception a ResNettel azonos erényt megosztva egyszerű és szép dizájnnal is rendelkezik, így az ötletét sok más következő kutatásban is használják, mint például a MobileNet, DeepLabV3 stb.
2017: MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
Az Xception 79%-os top-1 pontosságot és 94,5%-os top-5 pontosságot ért el az ImageNet-en, de ez csak 0,8%-os, illetve 0,4%-os javulás a korábbi SOTA InceptionV3-hoz képest. Egy új képosztályozó hálózat marginális nyeresége egyre kisebb, ezért a kutatók kezdik más területekre helyezni a hangsúlyt. A MobileNet pedig jelentős lendületet adott a képosztályozásnak egy erőforrás-korlátozott környezetben.

A MobileNet az Xceptionhez hasonlóan ugyanazt a mélységben elválasztható konvolúciós modult használta, mint a fentebb bemutatott, és a nagy hatékonyságra és a kevesebb paraméterre helyezte a hangsúlyt.
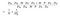
A fenti képlet számlálója a mélységben elválasztható konvolúcióhoz szükséges összes paraméter száma. A nevező pedig egy hasonló szabályos konvolúció összes paraméterszáma. Itt D a konvolúciós kernel mérete, D a jellemzőtérkép mérete, M a bemeneti csatornák száma, N a kimeneti csatornák száma. Mivel szétválasztottuk a csatorna és a térbeli jellemző számítását, a szorzást összeadássá alakíthatjuk, ami egy nagyságrenddel kisebb. Még jobb, ahogy ebből az arányból láthatjuk, minél nagyobb a kimeneti csatornák száma, annál több számítást spóroltunk meg az új konvolúció használatával.
A MobileNet másik hozzájárulása a szélesség és a felbontás szorzója. A MobileNet csapata egy kanonikus módszert akart találni a modell méretének csökkentésére a mobileszközök számára, és a legintuitívabb módja a bemeneti és kimeneti csatornák számának, valamint a bemeneti kép felbontásának csökkentése. Ennek a viselkedésnek a szabályozásához egy alfa arány szorozza a csatornákat, és egy rho arány szorozza a bemeneti felbontást (ami szintén befolyásolja a feature map méretét). Így a paraméterek teljes száma a következő képlettel ábrázolható:
Bár ez a változtatás az innováció szempontjából naivnak tűnik, nagy mérnöki értéke van, mert ez az első alkalom, amikor a kutatók egy kanonikus megközelítésre következtetnek a hálózat különböző erőforrás-korlátozásokhoz való igazítására. Emellett ez mintegy összefoglalta a neurális hálózat javításának végső megoldását: a szélesebb és nagy felbontású bemenet jobb pontossághoz, a vékonyabb és alacsony felbontású bemenet rosszabb pontossághoz vezet.
Később, 2018-ban és 2019-ben a MobiletNet csapat is kiadta a “MobileNetV2: Invertált maradékok és lineáris szűk keresztmetszetek” és a “Searching for MobileNetV3” című kiadványokat. A MobileNetV2-ben egy invertált reziduális szűk keresztmetszeti struktúrát használnak. A MobileNetV3-ban pedig elkezdte keresni az optimális architektúra-kombinációt a Neural Architecture Search technológia segítségével, amivel a következőkben foglalkozunk.
2017: NASNet
Transzferálható architektúrák tanulása skálázható képfelismeréshez
A képosztályozáshoz hasonlóan erőforrás-korlátozott környezetben a neurális architektúra-keresés egy másik terület, amely 2017 körül jelent meg. A ResNet, az Inception és az Xception segítségével úgy tűnik, hogy elértünk egy olyan optimális hálózati topológiát, amelyet az ember képes megérteni és megtervezni, de mi van, ha létezik egy jobb és sokkal összetettebb kombináció, amely messze meghaladja az emberi képzeletet? A 2016-ban megjelent “Neural Architecture Search with Reinforcement Learning” című tanulmány egy olyan ötletet javasolt, amely az optimális kombináció keresésére szolgál egy előre meghatározott keresési téren belül, megerősítéses tanulás segítségével. Mint tudjuk, a megerősítéses tanulás egy olyan módszer, amellyel a kereső ágens számára egyértelmű cél és jutalom mellett lehet megtalálni a legjobb megoldást. Azonban a számítási teljesítmény által korlátozva ez a cikk csak egy kis CIFAR-adatkészletben tárgyalta az alkalmazást.

A NASNet azzal a céllal, hogy optimális struktúrát találjon egy olyan nagy adathalmazhoz, mint az ImageNet, elkészítette az ImageNet-re szabott keresési teret. Azt reméli, hogy egy speciális keresőtér kialakításával a CIFAR-on keresett eredmény az ImageNet-en is jól működhet. Először is, a NASNet feltételezi, hogy az olyan jó hálózatokban, mint a ResNet és az Xception, a keresés során még mindig hasznosak a közös, kézzel készített modulok. Így a NASNet a véletlenszerű kapcsolatok és műveletek keresése helyett ezeknek a moduloknak a kombinációját keresi, amelyek már az ImageNet-en is hasznosnak bizonyultak. Másodszor, a tényleges keresés továbbra is a 32×32-es felbontású CIFAR-adatkészleten történik, így a NASNet csak olyan modulokat keres, amelyeket nem befolyásol a bemeneti méret. Annak érdekében, hogy a második pont működjön, a NASNet kétféle modulsablont definiált előre: Reduction és Normal. A redukciós cellának a bemenethez képest csökkentett jellemzőtérképe lehet, a normál cellánál pedig ugyanez a helyzet.

Bár a NASNet jobb metrikákkal rendelkezik, mint a kézzel tervezett hálózatok, van néhány hátránya is. Az optimális struktúra keresésének költsége nagyon magas, amit csak olyan nagyvállalatok engedhetnek meg maguknak, mint a Google és a Facebook. Emellett a végső struktúrának nincs túl sok értelme az emberek számára, ezért nehezebb karbantartani és javítani egy termelési környezetben. Később, 2018-ban a “MnasNet: Platform-Aware Neural Architecture Search for Mobile” tovább bővíti ezt a NASNet-ötletet azzal, hogy a keresési lépést egy előre meghatározott láncos-blokkos struktúrával korlátozza. Emellett egy súlytényező meghatározásával az mNASNet szisztematikusabb módot adott a modell keresésére adott konkrét erőforrás-korlátozások mellett, ahelyett, hogy csak a FLOP-ok alapján értékelne.
2019: EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
2019-ben úgy tűnik, hogy már nincsenek izgalmas ötletek a CNN-ekkel történő felügyelt képosztályozásra. A hálózat szerkezetének drasztikus megváltoztatása általában csak kis pontosságjavulást kínál. Még rosszabb, ha ugyanazt a hálózatot különböző adatkészletekre és feladatokra alkalmazzák, úgy tűnik, hogy a korábban állított trükkök nem működnek, ami olyan kritikákhoz vezetett, hogy vajon ezek a javulások csak túlillesztések-e az ImageNet adatkészleten. A másik oldalon van egy trükk, amely soha nem mond ellent a várakozásainknak: nagyobb felbontású bemenet használata, több csatorna hozzáadása a konvolúciós rétegekhez és több réteg hozzáadása. Bár nagyon brutális erő, úgy tűnik, hogy van egy elvi módja a hálózat igény szerinti skálázásának. A MobileNetV1 mondhatni ezt javasolta 2017-ben, de a hangsúlyt később áthelyezték egy jobb hálózattervezésre.

A NASNet és az mNASNet után a kutatók rájöttek, hogy az architektúra megváltoztatása még számítógépes segítséggel sem hoz olyan nagy hasznot. Ezért kezdenek visszanyúlni a hálózat skálázásához. Az EfficientNet csak erre a feltevésre épül. Egyrészt az mNASNet optimális építőelemét használja, hogy biztosítsa a jó alapot a kezdéshez. Másrészt három paramétert definiált alfa, béta és rho, hogy ennek megfelelően szabályozza a hálózat mélységét, szélességét és felbontását. Ezáltal még akkor is, ha nincs nagy GPU-állomány az optimális struktúra kereséséhez, a mérnökök ezekre az elvi paraméterekre támaszkodhatnak, hogy a hálózatot a különböző követelmények alapján hangolják. Végül az EfficientNet 8 különböző változatot adott különböző szélesség, mélység és felbontás arányokkal, és mind a kis, mind a nagy modellek esetében jó teljesítményt ért el. Más szóval, ha nagy pontosságot szeretne, válasszon egy 600×600-as és 66M paraméterű EfficientNet-B7-et. Ha alacsony késleltetést és kisebb modellt szeretne, válasszon egy 224×224-es és 5,3M paraméterű EfficientNet-B0-t. A probléma megoldva.
Ha befejezi a fenti 10 cikk elolvasását, akkor már elég jól ismeri a CNN-nel történő képosztályozás történetét. Ha szeretné tovább tanulni ezt a területet, felsoroltam még néhány más érdekes dolgozatot is, amelyeket elolvashat. Bár nem szerepelnek a top 10-es listán, ezek a dolgozatok mind híresnek számítanak a saját területükön, és sok más kutatót inspiráltak a világon.
2014: SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Az SPPNet a hagyományos számítógépes látás jellemzőkinyeréséből kölcsönzi a jellemzőpiramis ötletét. Ez a piramis egy szózsákot alkot a különböző léptékű jellemzőkből, így alkalmazkodni tud a különböző bemeneti méretekhez, és megszabadul a rögzített méretű, teljesen összekapcsolt rétegtől. Ez az ötlet inspirálta a DeepLab ASPP modulját és az FPN-t is a tárgyfelismeréshez.
2016: DenseNet
Densely Connected Convolutional Networks
A Cornellből származó DenseNet tovább bővíti a ResNet ötletét. Nemcsak a rétegek közötti kihagyásos kapcsolatot biztosítja, hanem az összes korábbi rétegből is rendelkezik kihagyásos kapcsolatokkal.
2017: SENet
Squeeze-and-Excitation Networks
A Xception hálózat megmutatta, hogy a csatornák közötti korrelációnak nem sok köze van a térbeli korrelációhoz. A legutóbbi ImageNet verseny bajnokaként a SENet azonban egy Squeeze-and-Excitation blokkot dolgozott ki, és másról mesélt. Az SE blokk először az összes csatornát globális pooling segítségével kevesebb csatornává szorítja össze, egy teljesen összekapcsolt transzformációt alkalmaz, majd egy másik teljesen összekapcsolt réteg segítségével “gerjeszti” vissza őket az eredeti csatornaszámra. Tehát lényegében az FC réteg segített a hálózatnak megtanulni a bemeneti jellemzőtérképre való odafigyelést.
2017: ShuffleNet
ShuffleNet: A MobileNetV2 fordított szűk keresztmetszetű moduljára épülő ShuffleNet úgy véli, hogy a pontonkénti konvolúció a mélység szerint szeparálható konvolúcióban feláldozza a pontosságot a kevesebb számításért cserébe. Ennek ellensúlyozására a ShuffleNet egy további csatornakeverési műveletet adott hozzá, hogy a pontonkénti konvolúciót ne mindig ugyanarra a “pontra” alkalmazza. A ShuffleNetV2-ben pedig ez a csatornakeverési mechanizmus tovább bővült a ResNet identitás-leképezési ágára is, így az identitásjellemző egy része is felhasználásra kerül a keveréshez.
2018: Bag of Tricks
Bag of Tricks for Image Classification with Convolutional Neural Networks
A Bag of Tricks a képosztályozás területén használt gyakori trükkökkel foglalkozik. Jó referenciaként szolgál a mérnökök számára, amikor javítaniuk kell a benchmarkok teljesítményét. Érdekes módon ezek a trükkök, mint például a keverésnövelés és a koszinusz tanulási ráta, néha sokkal jobb javulást érhetnek el, mint egy új hálózati architektúra.
Következtetés
Az EfficientNet megjelenésével úgy tűnik, hogy az ImageNet osztályozási benchmark véget ér. A jelenlegi mélytanulási megközelítéssel soha nem lesz olyan nap, amikor elérhetjük a 99,999%-os pontosságot az ImageNet-en, hacsak nem történik újabb paradigmaváltás. Ezért a kutatók aktívan keresnek néhány új területet, például az önfelügyelt vagy félig felügyelt tanulást a nagyméretű vizuális felismeréshez. Eközben a meglévő módszerekkel a mérnökök és vállalkozók számára inkább az vált kérdéssé, hogy megtalálják e nem tökéletes technológia valós alkalmazását. A jövőben egy felmérést is fogok írni, hogy elemezzem ezeket a képosztályozással hajtott valós számítógépes látásalkalmazásokat, úgyhogy kérem, maradjon velünk! Ha úgy gondolja, hogy vannak más fontos tanulmányok is, amelyeket érdemes elolvasni a képosztályozáshoz, kérjük, írja meg nekünk.
Originally published at http://yanjia.li on July 31, 2020
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based Learning Applied to Document Recognition
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
- Sergey Ioffe, Christian Szegedy, Batch Normalization: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition
- François Chollet, Xception: Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
- Mingxing Tan, Quoc V. Le, EfficientNet: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Connected Convolutional Networks
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Bag of Tricks for Image Classification with Convolutional Neural Networks