
Az erőforrás-elosztás fontos szempont bármely Spark feladat végrehajtása során. Ha nem megfelelően van konfigurálva, akkor egy spark feladat a teljes fürt erőforrásait felemésztheti, és más alkalmazások éheznek az erőforrásokra.
Ez a blog segít megérteni az alapvető áramlást egy Spark alkalmazásban, majd hogyan kell konfigurálni a végrehajtók számát, az egyes végrehajtók memória beállításait és a magok számát egy Spark feladathoz. Van néhány tényező, amit figyelembe kell vennünk, hogy eldöntsük a fenti három optimális számot, mint például:
- Az adatmennyiség
- Az idő, amely alatt a feladatnak be kell fejeződnie
- Az erőforrások statikus vagy dinamikus elosztása
- Upstream vagy downstream alkalmazás
- Bevezetés
- Lépések egy Spark Job klaszter üzemmódban
- Statikus allokáció
- 1. eset Hardver – 6 csomópont és minden csomópont 16 maggal, 64 GB RAM-mal
- 2. eset Hardver – 6 csomópont és minden csomópont 32 maggal, 64 GB
- 3. eset – Amikor nincs szükség több memóriára a végrehajtók számára
- Összefoglaló táblázat
- Dinamikus kiosztás
Bevezetés
Kezdjük a Spark alkalmazások kezelésében használt fogalmak néhány alapvető meghatározásával.
Partíciók : A partíció egy nagy elosztott adathalmaz egy kis darabja. A Spark az adatokat partíciók segítségével kezeli, ami segít az adatfeldolgozás párhuzamosításában úgy, hogy az adatok minimálisan keverednek a végrehajtók között.
Task : A task egy olyan munkaegység, amely egy elosztott adathalmaz egy partícióján futtatható, és egyetlen végrehajtón kerül végrehajtásra. A párhuzamos végrehajtás egysége a feladat szintjén van.Az egyetlen szakaszban lévő összes feladat párhuzamosan végrehajtható
Végrehajtó : A végrehajtó egyetlen JVM-folyamat, amelyet egy alkalmazáshoz egy munkás csomóponton indítanak el. A végrehajtó futtatja a feladatokat, és az adatokat a memóriában vagy a lemezes tárolóban tartja rajtuk keresztül. Minden alkalmazásnak saját végrehajtói vannak. Egyetlen csomópont több végrehajtót is futtathat, és egy alkalmazás végrehajtói több munkáscsomópontra is kiterjedhetnek. Egy végrehajtó a Spark-alkalmazás
idejéig fennmarad, és a feladatokat több szálban futtatja. Egy Spark alkalmazás végrehajtóinak száma megadható a SparkConf-on belül vagy a parancssorból a -num-executors flag segítségével.
Cluster Manager : Egy külső szolgáltatás a klaszter erőforrásainak megszerzésére (pl. önálló menedzser, Mesos, YARN). A Spark agnosztikus a klasztermenedzserrel szemben, amíg képes végrehajtó folyamatokat szerezni, és azok kommunikálni tudnak egymással. minket elsősorban a Yarn érdekel, mint klasztermenedzser. Egy spark fürt futhat yarn cluster vagy yarn-client módban:
yarn-client mód – A vezérlő fut a kliensfolyamatban, az alkalmazásmester csak az erőforrások kérésére szolgál a YARN-től.
yarn-cluster mód – A vezérlő fut az alkalmazásmesterfolyamaton belül, a kliens eltűnik, amint az alkalmazás inicializálódik
Magok : A mag a CPU alapvető számítási egysége, és egy CPU-nak egy vagy több magja lehet, hogy egy adott időben feladatokat hajtson végre. Minél több magunk van, annál több munkát tudunk elvégezni. A Sparkban ez szabályozza, hogy egy végrehajtó hány párhuzamos feladatot tud futtatni.
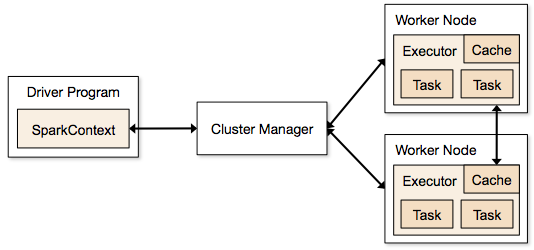
Lépések egy Spark Job klaszter üzemmódban
- A vezérlőkódból a SparkContext csatlakozik a klaszterkezelőhöz (standalone/Mesos/YARN).
- A klaszterkezelő elosztja az erőforrásokat a többi alkalmazás között. Bármilyen fürtkezelő használható, amíg a végrehajtó folyamatok futnak és kommunikálnak egymással.
- A Spark a fürt csomópontjain végrehajtókat szerez. Itt minden alkalmazás megkapja a saját végrehajtó folyamatait.
- Az alkalmazás kódját (jar/python fájlok/python egg fájlok) elküldi a végrehajtóknak
- A feladatokat a SparkContext küldi a végrehajtóknak.
A fenti lépésekből egyértelmű, hogy a végrehajtók száma és memória beállítása nagy szerepet játszik egy spark feladatban. A végrehajtók túl sok memóriával történő futtatása gyakran túlzott szemétgyűjtési késedelmeket eredményez
Most megpróbáljuk megérteni, hogyan lehet a legjobb értékkészletet beállítani egy spark feladat optimalizálásához.
Kétféleképpen konfigurálhatjuk a végrehajtók és a mag adatait a Spark feladathoz. Ezek a következők:
- Static Allocation – Az értékeket a spark-submit
- Dynamic Allocation – Az értékeket az igény (adatméret, szükséges számítások mennyisége) alapján vesszük fel, és használat után felszabadítjuk. Ez segíti az erőforrások újrafelhasználását más alkalmazások számára.
Statikus allokáció
A különböző eseteket különböző paraméterek variálásával tárgyaljuk, és különböző kombinációkhoz jutunk a felhasználó/adatigény szerint.
1. eset Hardver – 6 csomópont és minden csomópont 16 maggal, 64 GB RAM-mal
Először minden csomóponton 1 mag és 1 GB szükséges az operációs rendszer és a Hadoop démonok számára, így minden csomóponthoz 15 magot, 63 GB RAM-ot kapunk
Azzal kezdjük, hogyan válasszuk ki a magok számát:
Magok száma = Egy végrehajtó által futtatható párhuzamos feladatok száma
Ezért azt gondolhatnánk, hogy több párhuzamos feladat egy végrehajtó számára jobb teljesítményt ad. De a kutatások azt mutatják, hogy minden olyan alkalmazás, amely 5-nél több párhuzamos feladatot tartalmaz, rossz előadáshoz vezet. Tehát az optimális érték 5.
Ez a szám a végrehajtó párhuzamos feladatok futtatására való képességéből származik, és nem abból, hogy hány maggal rendelkezik a rendszer. Tehát az 5-ös szám akkor is ugyanaz marad, ha dupla (32) magunk van a CPU-ban
Futtatók száma:
A következő lépésre térve, 5 maggal, mint végrehajtónként, és 15-tel, mint egy csomópontban (CPU) összesen rendelkezésre álló magokkal – csomópontonként 3 végrehajtóhoz jutunk, ami 15/5. Ki kell számolnunk a végrehajtók számát az egyes csomópontokon, majd megkapjuk a feladat teljes számát.
Így 6 csomóponttal és csomópontonként 3 végrehajtóval – összesen 18 végrehajtót kapunk. A 18-ból 1 végrehajtóra (java folyamat) van szükségünk az Application Master számára a YARN-ban. Tehát a végső szám 17 végrehajtó
Ezt a 17-et adjuk meg a sparknak a -num-executors használatával, miközben a spark-submit shell parancsból futtatjuk
Memória minden végrehajtóhoz:
A fenti lépésből adódóan csomópontonként 3 végrehajtónk van. És a rendelkezésre álló RAM minden csomóponton 63 GB
Az egyes csomópontok minden végrehajtójának memóriája tehát 63/3 = 21 GB.
Az egyes végrehajtók teljes memóriaigényének a YARN-hez történő meghatározásához azonban kis overhead memóriára is szükség van minden végrehajtó számára.
Ez a rezsiköltség képlete: max(384, .07 * spark.executor.memory)
A rezsiköltség kiszámítása: .07 * 21 (Itt a 21-et a fenti 63/3 szerint számoljuk) = 1,47
Mivel 1,47 GB > 384 MB, a rezsiköltség 1.47
Vegyük a fentieket minden fenti 21-ből => 21 – 1.47 ~ 19 GB
Szóval végrehajtói memória – 19 GB
A végső számok – végrehajtók – 17, magok 5, végrehajtói memória – 19 GB
2. eset Hardver – 6 csomópont és minden csomópont 32 maggal, 64 GB
A magok száma 5 azonos a jó párhuzamossághoz, ahogy fentebb kifejtettük.
A végrehajtók száma csomópontonként = 32/5 ~ 6
Az összes végrehajtó = 6 * 6 csomópont = 36. Akkor a végső szám 36 – 1(az AM-hez) = 35
Végrehajtók memóriája:
6 végrehajtó minden csomópontra. 63/6 ~ 10. Az általános költség 0,07 * 10 = 700 MB. Tehát 1 GB-ra kerekítve a rezsiköltséget, 10-1 = 9 GB
A végső számok – Végrehajtók – 35, Magok 5, Végrehajtói memória – 9 GB
3. eset – Amikor nincs szükség több memóriára a végrehajtók számára
A fenti forgatókönyvek a magok számának fixnek való elfogadásával kezdődnek, és a végrehajtók és a memória száma felé haladnak.
Most az első esetben, ha úgy gondoljuk, hogy nincs szükségünk 19 GB-ra, és az adatok mérete és az elvégzett számítások alapján csak 10 GB is elegendő, akkor a következő számok a következők:
Magok:
A végrehajtók száma csomópontonként = 3. Még mindig 15/5, ahogy fentebb kiszámoltuk.
Ebben a szakaszban ez 21 GB-ot eredményezne, és nem 19 GB-ot az első számításunk szerint. De mivel úgy gondoltuk, hogy a 10 rendben van (feltételezzük a kis overheadet), akkor nem tudjuk a csomópontonkénti végrehajtók számát 6-ra változtatni (mint 63/10). Mert 6 végrehajtóval csomópontonként és 5 maggal ez 30 magra jön le csomópontonként, amikor nekünk csak 16 magunk van. Tehát az egyes végrehajtókhoz tartozó magok számát is meg kell változtatnunk.
Így újra számolva,
A bűvös 5-ös számból 3 jön ki (bármilyen szám, ami 5-nél kisebb vagy azzal egyenlő). Tehát 3 maggal és 15 elérhető maggal – csomópontonként 5 végrehajtót kapunk, 29 végrehajtót ( ami (5*6 -1)) és a memória 63/5 ~ 12.
Az overhead 12*.07=.84. Tehát a végrehajtói memória 12 – 1 GB = 11 GB
A végső számok: 29 végrehajtó, 3 mag, a végrehajtói memória 11 GB
Összefoglaló táblázat
Dinamikus kiosztás
Megjegyzés: A végrehajtók számának felső határa, ha a dinamikus kiosztás engedélyezett, végtelen. Ez tehát azt mondja, hogy a szikra alkalmazás szükség esetén felfalhatja az összes erőforrást. Egy olyan fürtben, ahol más alkalmazások is futnak, és azoknak is szükségük van magokra a feladatok futtatásához, gondoskodnunk kell arról, hogy a magokat fürt szinten osszuk ki.
Ez azt jelenti, hogy a YARN-alapú alkalmazások számára a felhasználói hozzáférés alapján meghatározott számú magot tudunk kiosztani. Tehát létrehozhatunk egy spark_user-t, majd adhatunk magokat (min/max) ennek a felhasználónak. Ezek a korlátok a spark és más, a YARN-en futó alkalmazások közötti megosztásra szolgálnak.
A dinamikus allokáció megértéséhez ismernünk kell a következő tulajdonságokat:
spark.dynamicAllocation.enabled – ha ez true-ra van állítva, akkor nem kell végrehajtókat említenünk. Ennek oka az alábbi:
A statikus paraméterszámok, amelyeket a spark-submitnél megadunk, a teljes munka időtartamára vonatkoznak. Ha azonban dinamikus allokáció kerül a képbe, akkor különböző szakaszok lennének, mint például a következő:
Mivel kezdjük a végrehajtók számát:
A végrehajtók kezdeti száma (spark.dynamicAllocation.initialExecutors), amivel kezdjük
A végrehajtók számának dinamikus vezérlése:
Azután a terhelés (függőben lévő feladatok) alapján hány végrehajtót kérünk. Ez lenne végül az a szám, amit a spark-submitnél statikusan megadunk. Tehát ha a kezdeti végrehajtói számok meg vannak határozva, akkor megyünk a min (spark.dynamicAllocation.minExecutors) és max (spark.dynamicAllocation.maxExecutors) számokhoz.
Mikor kérünk új végrehajtókat vagy adjuk le a jelenlegi végrehajtókat:
Mikor kérünk új végrehajtókat (spark.dynamicAllocation.schedulerBacklogTimeout) – Ez azt jelenti, hogy ennyi ideig voltak függőben lévő feladatok. Tehát az egyes fordulókban kért végrehajtók száma exponenciálisan növekszik az előző fordulóhoz képest. Például egy alkalmazás az első körben 1 végrehajtót ad hozzá, majd a következő körökben 2, 4, 8 és így tovább végrehajtókat. Egy adott ponton a fenti max tulajdonság kerül a képbe.
Az, hogy mikor adunk ki egy végrehajtót, a spark.dynamicAllocation.executorIdleTimeout segítségével állítható be.
Végezetül, ha nagyobb kontrollra van szükségünk a feladat végrehajtási ideje felett, a feladat váratlan adatmennyiségre való figyelése a statikus számok segítenének. A dinamikusra való áttéréssel az erőforrásokat a háttérben használnánk, és a váratlan volumenű munkák más alkalmazásokat is érinthetnének.