
- Una rapida carrellata dei migliori documenti per la classificazione delle immagini in un decennio per avviare il tuo apprendimento di computer vision
- 1998: LeNet
- 2012: AlexNet
- 2014: VGG
- 2014: GoogLeNet
- 2015: Batch Normalization
- 2015: ResNet
- 2016: Xception
- 2017: MobileNet
- 2017: NASNet
- 2019: EfficientNet
- 2014: SPPNet
- 2016: DenseNet
- 2017: SENet
- 2017: ShuffleNet
- 2018: Bag of Tricks
- Conclusione
Una rapida carrellata dei migliori documenti per la classificazione delle immagini in un decennio per avviare il tuo apprendimento di computer vision

La computer vision è una materia per convertire immagini e video in segnali comprensibili alla macchinasegnali comprensibili alla macchina. Con questi segnali, i programmatori possono controllare ulteriormente il comportamento della macchina sulla base di questa comprensione di alto livello. Tra i molti compiti di computer vision, la classificazione delle immagini è uno dei più fondamentali. Non solo può essere usata in molti prodotti reali come il tagging di Google Photo e la moderazione dei contenuti AI, ma apre anche la porta a molti compiti di visione più avanzati, come il rilevamento degli oggetti e la comprensione dei video. A causa dei rapidi cambiamenti in questo campo dalla scoperta del Deep Learning, i principianti spesso lo trovano troppo travolgente da imparare. A differenza dei tipici argomenti di ingegneria del software, non ci sono molti grandi libri sulla classificazione delle immagini utilizzando DCNN, e il modo migliore per capire questo campo è attraverso la lettura di articoli accademici. Ma quali articoli leggere? Da dove iniziare? In questo articolo, presenterò 10 migliori articoli da leggere per i principianti. Con questi articoli, possiamo vedere come questo campo si evolve, e come i ricercatori hanno portato nuove idee basate sui risultati delle ricerche precedenti. Tuttavia, è ancora utile per voi per ordinare il quadro generale anche se avete già lavorato in questo settore per un po’. Quindi, iniziamo.
1998: LeNet
Gradient-based Learning Applied to Document Recognition

Introdotto nel 1998, LeNet pone le basi per la futura ricerca sulla classificazione delle immagini utilizzando la rete neurale di convoluzione. Molte tecniche CNN classiche, come gli strati di pooling, gli strati completamente connessi, il padding e gli strati di attivazione sono usati per estrarre le caratteristiche e fare una classificazione. Con una funzione di perdita di errore quadratico medio e 20 epoche di allenamento, questa rete può raggiungere il 99,05% di precisione sul test set MNIST. Anche dopo 20 anni, molte reti di classificazione all’avanguardia seguono ancora questo modello in generale.
2012: AlexNet
ImageNet Classificazione con Reti Neurali Convoluzionali Profonde

Anche se LeNet ha raggiunto un grande risultato e ha mostrato il potenziale delle CNN, lo sviluppo in quest’area ha ristagnato per un decennio a causa della limitata potenza di calcolo e la quantità di dati. Sembrava che CNN potesse risolvere solo alcuni compiti facili come il riconoscimento delle cifre, ma per caratteristiche più complesse come i volti e gli oggetti, un estrattore di caratteristiche HarrCascade o SIFT con un classificatore SVM era un approccio più preferito.
Tuttavia, nel 2012 ImageNet Large Scale Visual Recognition Challenge, Alex Krizhevsky ha proposto una soluzione basata su CNN per questa sfida e ha aumentato drasticamente la precisione top-5 del set di test ImageNet dal 73,8% al 84,7%. Il loro approccio eredita l’idea della CNN multistrato da LeNet, ma ha aumentato molto le dimensioni della CNN. Come si può vedere dal diagramma qui sopra, l’input è ora 224×224 rispetto al 32×32 di LeNet, inoltre molti kernel di convoluzione hanno 192 canali rispetto ai 6 di LeNet. Anche se il design non è cambiato molto, con centinaia di volte in più di parametri, la capacità della rete di catturare e rappresentare caratteristiche complesse è migliorata anche centinaia di volte. Per addestrare un modello così grande, Alex ha usato due GPU GTX 580 con 3GB di RAM per ciascuna, che ha aperto la strada all’addestramento su GPU. Inoltre, l’uso della non linearità ReLU ha anche aiutato a ridurre il costo di calcolo.
Oltre a portare molti più parametri per la rete, ha anche esplorato il problema dell’overfitting portato da una rete più grande utilizzando uno strato di Dropout. Il suo metodo di normalizzazione della risposta locale non ha ottenuto troppa popolarità in seguito, ma ha ispirato altre importanti tecniche di normalizzazione come BatchNorm per combattere il problema della saturazione del gradiente. Per riassumere, AlexNet ha definito il quadro de facto delle reti di classificazione per i prossimi 10 anni: una combinazione di Convoluzione, attivazione non lineare ReLu, MaxPooling e strato denso.
2014: VGG
Reti convoluzionali molto profonde per il riconoscimento di immagini su larga scalaScale Image Recognition
Con un così grande successo dell’uso di CNN per il riconoscimento visivo, l’intera comunità di ricerca è esplosa e tutti hanno iniziato a cercare di capire perché questa rete neurale funziona così bene. Per esempio, in “Visualizing and Understanding Convolutional Networks” del 2013, Matthew Zeiler ha discusso come la CNN raccoglie le caratteristiche e visualizza le rappresentazioni intermedie. E improvvisamente tutti hanno iniziato a capire che la CNN è il futuro della computer vision dal 2014. Tra tutti questi seguaci immediati, la rete VGG di Visual Geometry Group è la più accattivante. Ha ottenuto un risultato notevole di 93,2% di precisione top-5, e 76,3% di precisione top-1 sul set di test ImageNet.
Seguendo il design di AlexNet, la rete VGG ha due importanti aggiornamenti: 1) VGG non solo ha usato una rete più ampia come AlexNet ma anche più profonda. VGG-19 ha 19 strati di convoluzione, rispetto ai 5 di AlexNet. 2) VGG ha anche dimostrato che alcuni piccoli filtri di convoluzione 3×3 possono sostituire un singolo 7×7 o anche 11×11 filtri da AlexNet, ottenere prestazioni migliori riducendo il costo di calcolo. A causa di questo design elegante, VGG è diventato anche la rete di back-bone di molte reti pionieristiche in altri compiti di computer vision, come FCN per la segmentazione semantica, e Faster R-CNN per il rilevamento degli oggetti.
Con una rete più profonda, la scomparsa del gradiente dalla back-propagation multistrato diventa un problema più grande. Per affrontarlo, VGG ha anche discusso l’importanza del pre-addestramento e dell’inizializzazione dei pesi. Questo problema limita i ricercatori a continuare ad aggiungere più strati, altrimenti, la rete sarà davvero difficile da convergere. Ma vedremo una soluzione migliore per questo dopo due anni.
2014: GoogLeNet
Going Deeper with Convolutions

VGG ha una struttura bella e facile da capire, ma le sue prestazioni non sono le migliori tra tutti i finalisti delle competizioni ImageNet 2014. GoogLeNet, alias InceptionV1, ha vinto il premio finale. Proprio come VGG, uno dei principali contributi di GoogLeNet è quello di spingere il limite della profondità della rete con una struttura a 22 strati. Questo ha dimostrato ancora una volta che andare più in profondità e più ampio è davvero la direzione giusta per migliorare la precisione.
A differenza di VGG, GoogLeNet ha cercato di affrontare i problemi di calcolo e di diminuzione del gradiente a testa alta, invece di proporre un workaround con un migliore schema pre-addestrato e inizializzazione dei pesi.

In primo luogo, ha esplorato l’idea della progettazione della rete asimmetrica utilizzando un modulo chiamato Inception (vedi schema sopra). Idealmente, vorrebbero perseguire la convoluzione sparsa o gli strati densi per migliorare l’efficienza delle funzioni, ma il design dell’hardware moderno non era fatto su misura per questo caso. Così hanno creduto che una sparsità a livello di topologia di rete potrebbe anche aiutare la fusione delle caratteristiche sfruttando le capacità hardware esistenti.
In secondo luogo, attacca il problema dell’alto costo di calcolo prendendo in prestito un’idea da un documento chiamato “Network in Network”. Fondamentalmente, viene introdotto un filtro di convoluzione 1×1 per ridurre le dimensioni delle caratteristiche prima di passare attraverso pesanti operazioni di calcolo come un kernel di convoluzione 5×5. Questa struttura è chiamata in seguito “Bottleneck” e ampiamente utilizzata in molte reti successive. Simile a “Network in Network”, ha anche usato uno strato di pooling medio per sostituire lo strato finale completamente connesso per ridurre ulteriormente i costi.
In terzo luogo, per aiutare i gradienti a fluire verso gli strati più profondi, GoogLeNet ha anche usato la supervisione su alcuni livelli intermedi o output ausiliari. Questo design non è molto popolare in seguito nella rete di classificazione delle immagini a causa della complessità, ma sta diventando più popolare in altre aree della visione artificiale come la rete Clessidra nella stima della posa.
Come follow-up, questo team di Google ha scritto altri documenti per questa serie Inception. “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift” sta per InceptionV2. “Rethinking the Inception Architecture for Computer Vision” nel 2015 sta per InceptionV3. E “Inception-v4, Inception-ResNet e l’impatto delle connessioni residue sull’apprendimento” del 2015 sta per InceptionV4. Ogni articolo ha aggiunto ulteriori miglioramenti rispetto alla rete Inception originale e ha raggiunto un risultato migliore.
2015: Batch Normalization
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
La rete Inception ha aiutato i ricercatori a raggiungere una precisione sovrumana sul dataset ImageNet. Tuttavia, come metodo di apprendimento statistico, la CNN è molto vincolata alla natura statistica di uno specifico set di dati di allenamento. Pertanto, per ottenere una migliore accuratezza, di solito abbiamo bisogno di pre-calcolare la media e la deviazione standard dell’intero set di dati e usarle per normalizzare prima il nostro input per garantire che la maggior parte degli input degli strati della rete siano vicini, il che si traduce in una migliore reattività di attivazione. Questo approccio approssimativo è molto ingombrante, e a volte non funziona affatto per una nuova struttura di rete o un nuovo set di dati, quindi il modello di apprendimento profondo è ancora visto come difficile da addestrare. Per affrontare questo problema, Sergey Ioffe e Chritian Szegedy, il tizio che ha creato GoogLeNet, hanno deciso di inventare qualcosa di più intelligente chiamato Batch Normalization.

L’idea della normalizzazione batch non è difficile: possiamo usare le statistiche di una serie di mini-batch per approssimare le statistiche dell’intero set di dati, a patto di allenarci per un tempo sufficiente. Inoltre, invece di calcolare manualmente le statistiche, possiamo introdurre altri due parametri apprendibili “scale” e “shift” per far sì che la rete impari a normalizzare ogni strato da sola.
Il diagramma precedente ha mostrato il processo di calcolo dei valori di normalizzazione batch. Come possiamo vedere, prendiamo la media di tutto il mini-batch e calcoliamo anche la varianza. Successivamente, possiamo normalizzare l’input con questa media e varianza del mini-batch. Infine, con un parametro di scala e uno di spostamento, la rete imparerà ad adattare il risultato normalizzato del batch per adattarsi meglio agli strati successivi, di solito ReLU. Un’avvertenza è che non abbiamo informazioni sul mini-batch durante l’inferenza, quindi un workaround è quello di calcolare una media mobile e una varianza durante l’allenamento, e poi usare queste medie mobili nel percorso di inferenza. Questa piccola innovazione è così impattante, e tutte le reti successive iniziano ad usarla subito.
2015: ResNet
Deep Residual Learning for Image Recognition
Il 2015 potrebbe essere il miglior anno per la computer vision in un decennio, abbiamo visto così tante grandi idee spuntare non solo nella classificazione delle immagini ma in tutti i tipi di compiti di computer vision come il rilevamento di oggetti, la segmentazione semantica, ecc. Il più grande progresso dell’anno 2015 appartiene a una nuova rete chiamata ResNet, o reti residue, proposta da un gruppo di ricercatori cinesi di Microsoft Research Asia.

Come abbiamo discusso in precedenza per la rete VGG, il più grande ostacolo per andare ancora più in profondità è il problema del gradiente vanishing, cioè.Cioè, le derivate diventano sempre più piccole quando si retroagisce attraverso strati più profondi, e alla fine raggiunge un punto che la moderna architettura del computer non può davvero rappresentare in modo significativo. GoogLeNet ha cercato di attaccare questo problema usando la supervisione ausiliaria e il modulo di inizio asimmetrico, ma allevia il problema solo in piccola misura. Se vogliamo usare 50 o anche 100 strati, ci sarà un modo migliore per far fluire il gradiente attraverso la rete? La risposta di ResNet è di usare un modulo residuale.

ResNet ha aggiunto una scorciatoia di identità all’output, in modo che ogni modulo residuale non possa almeno prevedere qualunque sia l’input, senza perdersi nella natura. Una cosa ancora più importante è che, invece di sperare che ogni strato si adatti direttamente alla mappatura delle caratteristiche desiderate, il modulo residuo cerca di imparare la differenza tra l’uscita e l’ingresso, il che rende il compito molto più facile perché il guadagno di informazioni necessario è minore. Immaginate di imparare la matematica, per ogni nuovo problema, vi viene data una soluzione di un problema simile, quindi tutto quello che dovete fare è estendere questa soluzione e cercare di farla funzionare. Questo è molto più facile che pensare ad una soluzione nuova per ogni problema che si incontra. O come disse Newton, possiamo stare sulle spalle dei giganti, e l’input di identità è quel gigante per il modulo residuo.
Oltre alla mappatura dell’identità, ResNet ha anche preso in prestito il collo di bottiglia e la normalizzazione dei lotti dalle reti Inception. Alla fine, è riuscito a costruire una rete con 152 strati di convoluzione e ha raggiunto l’80,72% di accuratezza top-1 su ImageNet. L’approccio residuale diventa anche un’opzione predefinita per molte altre reti in seguito, come Xception, Darknet, ecc. Inoltre, grazie al suo design semplice e bello, è ancora ampiamente utilizzato in molti sistemi di riconoscimento visivo di produzione al giorno d’oggi.
Ci sono molte altre invarianti venute fuori seguendo il successo della rete residuale. In “Identity Mappings in Deep Residual Networks”, l’autore originale di ResNet ha cercato di mettere l’attivazione prima del modulo residuo e ha ottenuto un risultato migliore, e questo design è chiamato ResNetV2 in seguito. Inoltre, in un documento del 2016 “Aggregated Residual Transformations for Deep Neural Networks”, i ricercatori hanno proposto ResNeXt che ha aggiunto rami paralleli per i moduli residui per aggregare le uscite di diverse trasformazioni.
2016: Xception
Xception: Deep Learning with Depthwise Separable Convolutions

Con il rilascio di ResNet, sembrava che la maggior parte dei frutti a portata di mano nel classificatore di immagini fossero già stati colti. I ricercatori hanno iniziato a pensare a quale sia il meccanismo interno della magia della CNN. Poiché la convoluzione a canali incrociati di solito introduce una tonnellata di parametri, la rete Xception ha scelto di indagare questa operazione per capire un quadro completo del suo effetto.
Come il suo nome, Xception ha origine dalla rete Inception. Nel modulo Inception, più rami di diverse trasformazioni sono aggregati insieme per ottenere una sparsità topologica. Ma perché questa sparsità ha funzionato? L’autore di Xception, anche l’autore del framework Keras, ha esteso questa idea a un caso estremo in cui un file di convoluzione 3×3 corrisponde a un canale di uscita prima di una concatenazione finale. In questo caso, questi kernel di convoluzione paralleli formano effettivamente una nuova operazione chiamata convoluzione in profondità.

Come mostrato nel diagramma sopra, a differenza della convoluzione tradizionale dove tutti i canali sono inclusi in un calcolo, la convoluzione di profondità calcola solo la convoluzione per ogni canale separatamente e poi concatena l’uscita insieme. Questo taglia lo scambio di caratteristiche tra i canali, ma riduce anche molte connessioni, quindi il risultato è uno strato con meno parametri. Tuttavia, questa operazione produrrà lo stesso numero di canali come input (o un numero minore di canali se si raggruppano due o più canali). Quindi, una volta che le uscite dei canali sono unite, abbiamo bisogno di un altro filtro regolare 1×1, o di una convoluzione point-wise, per aumentare o ridurre il numero di canali, proprio come fa la convoluzione regolare.
Questa idea non è originariamente di Xception. È descritta in un documento chiamato “Learning visual representations at scale” e usata occasionalmente anche in InceptionV2. Xception ha fatto un passo avanti e ha sostituito quasi tutte le convoluzioni con questo nuovo tipo. E il risultato dell’esperimento si è rivelato piuttosto buono. Supera ResNet e InceptionV3 e diventa un nuovo metodo SOTA per la classificazione delle immagini. Questo ha anche dimostrato che la mappatura delle correlazioni tra canali e delle correlazioni spaziali nella CNN può essere completamente disaccoppiata. Inoltre, condividendo la stessa virtù con ResNet, Xception ha anche un design semplice e bello, quindi la sua idea è usata in molte altre ricerche successive come MobileNet, DeepLabV3, ecc.
2017: MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
Xception ha raggiunto il 79% di precisione top-1 e il 94,5% di precisione top-5 su ImageNet, ma questo è solo lo 0,8% e lo 0,4% di miglioramento rispettivamente rispetto al precedente SOTA InceptionV3. Il guadagno marginale di una nuova rete di classificazione delle immagini sta diventando più piccolo, quindi i ricercatori iniziano a spostare la loro attenzione su altre aree. E MobileNet ha guidato una spinta significativa della classificazione delle immagini in un ambiente con risorse limitate.

Simile a Xception, MobileNet ha usato uno stesso modulo di convoluzione separabile depthwise come mostrato sopra e ha avuto un’enfasi sull’alta efficienza e meno parametri.
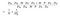
Il numeratore nella formula precedente è il numero totale di parametri richiesti da una convoluzione separabile in profondità. E il denominatore è il numero totale di parametri di una convoluzione regolare simile. Qui D è la dimensione del kernel di convoluzione, D è la dimensione della mappa delle caratteristiche, M è il numero di canali di ingresso, N è il numero di canali di uscita. Poiché abbiamo separato il calcolo del canale e della caratteristica spaziale, possiamo trasformare la moltiplicazione in un’addizione, che è di una grandezza inferiore. Ancora meglio, come possiamo vedere da questo rapporto, più grande è il numero di canali di uscita, più calcolo abbiamo risparmiato usando questa nuova convoluzione.
Un altro contributo di MobileNet è il moltiplicatore di larghezza e risoluzione. Il team di MobileNet ha voluto trovare un modo canonico per ridurre le dimensioni del modello per i dispositivi mobili, e il modo più intuitivo è quello di ridurre il numero di canali di input e di output, così come la risoluzione dell’immagine di input. Per controllare questo comportamento, un rapporto alfa è moltiplicato per i canali, e un rapporto rho è moltiplicato per la risoluzione di input (che influenza anche la dimensione della mappa delle caratteristiche). Così il numero totale di parametri può essere rappresentato nella seguente formula:

Anche se questo cambiamento sembra ingenuo in termini di innovazione, ha un grande valore ingegneristico perché è la prima volta che i ricercatori concludono un approccio canonico per regolare la rete per diversi vincoli di risorse. Inoltre, ha riassunto la soluzione definitiva del miglioramento della rete neurale: un input più ampio e ad alta risoluzione porta a una migliore precisione, un input più sottile e a bassa risoluzione porta a una precisione più scarsa.
Più tardi nel 2018 e 2019, il team MobiletNet ha anche rilasciato “MobileNetV2: Residui invertiti e colli di bottiglia lineari” e “Ricerca di MobileNetV3”. In MobileNetV2, viene utilizzata una struttura a collo di bottiglia residuo invertito. E in MobileNetV3, ha iniziato a cercare la combinazione ottimale dell’architettura usando la tecnologia Neural Architecture Search, di cui parleremo in seguito.
2017: NASNet
Learning Transferable Architectures for Scalable Image Recognition
Proprio come la classificazione delle immagini per un ambiente con risorse limitate, la ricerca di architetture neurali è un altro campo emerso intorno al 2017. Con ResNet, Inception e Xception, sembra che abbiamo raggiunto una topologia di rete ottimale che gli umani possono capire e progettare, ma cosa succede se c’è una combinazione migliore e molto più complessa che supera di gran lunga l’immaginazione umana? Un articolo del 2016 chiamato “Neural Architecture Search with Reinforcement Learning” ha proposto un’idea per cercare la combinazione ottimale all’interno di uno spazio di ricerca predefinito utilizzando l’apprendimento per rinforzo. Come sappiamo, l’apprendimento per rinforzo è un metodo per trovare la soluzione migliore con un obiettivo chiaro e una ricompensa per l’agente di ricerca. Tuttavia, limitato dalla potenza di calcolo, questo articolo ha discusso solo l’applicazione in un piccolo set di dati CIFAR.

Con l’obiettivo di trovare una struttura ottimale per un grande dataset come ImageNet, NASNet ha creato uno spazio di ricerca su misura per ImageNet. Spera di progettare uno spazio di ricerca speciale in modo che il risultato cercato su CIFAR possa funzionare bene anche su ImageNet. In primo luogo, NASNet presuppone che il modulo comune creato a mano in buone reti come ResNet e Xception sia ancora utile durante la ricerca. Quindi, invece di cercare connessioni e operazioni casuali, NASNet cerca la combinazione di questi moduli che hanno dimostrato di essere utili già su ImageNet. In secondo luogo, la ricerca effettiva viene ancora eseguita sul set di dati CIFAR con risoluzione 32×32, quindi NASNet cerca solo i moduli che non sono influenzati dalla dimensione dell’input. Per far funzionare il secondo punto, NASNet ha predefinito due tipi di modelli di moduli: Riduzione e Normale. La cella Reduction potrebbe avere una mappa di caratteristiche ridotta rispetto all’input, e per la cella Normal sarebbe lo stesso.

Anche se NASNet ha metriche migliori delle reti progettate manualmente, soffre di alcuni svantaggi. Il costo della ricerca di una struttura ottimale è molto alto, che è accessibile solo alle grandi aziende come Google e Facebook. Inoltre, la struttura finale non ha troppo senso per gli umani, quindi è più difficile da mantenere e migliorare in un ambiente di produzione. Più tardi nel 2018, “MnasNet: Platform-Aware Neural Architecture Search for Mobile” estende ulteriormente questa idea NASNet limitando la fase di ricerca con una struttura predefinita di blocchi a catena. Inoltre, definendo un fattore di peso, mNASNet ha dato un modo più sistematico per cercare il modello dato vincoli di risorse specifiche, invece di valutare solo in base ai FLOP.
2019: EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Nel 2019, sembra che non ci siano più idee eccitanti per la classificazione supervisionata delle immagini con CNN. Un cambiamento drastico nella struttura della rete di solito offre solo un piccolo miglioramento della precisione. Ancora peggio, quando la stessa rete applicata a diversi set di dati e compiti, i trucchi precedentemente rivendicati non sembrano funzionare, il che ha portato a critiche che se quei miglioramenti sono solo overfitting sul set di dati ImageNet. D’altra parte, c’è un trucco che non fallisce mai la nostra aspettativa: usare input a risoluzione più alta, aggiungere più canali per gli strati di convoluzione e aggiungere più strati. Anche se la forza è molto brutale, sembra che ci sia un modo di principio per scalare la rete su richiesta. MobileNetV1 ha più o meno suggerito questo nel 2017, ma l’attenzione è stata spostata su un design di rete migliore in seguito.

Dopo NASNet e mNASNet, i ricercatori hanno capito che anche con l’aiuto di un computer, un cambiamento nell’architettura non produce molti benefici. Così hanno iniziato a ripiegare sullo scaling della rete. EfficientNet è semplicemente costruito sulla base di questo presupposto. Da un lato, utilizza il blocco di costruzione ottimale di mNASNet per assicurarsi una buona base di partenza. D’altra parte, ha definito tre parametri alfa, beta e rho per controllare la profondità, la larghezza e la risoluzione della rete in modo corrispondente. Così facendo, anche senza un grande pool di GPU per cercare una struttura ottimale, gli ingegneri possono ancora contare su questi parametri di principio per sintonizzare la rete in base alle loro diverse esigenze. Alla fine, EfficientNet ha fornito 8 diverse varianti con diversi rapporti di larghezza, profondità e risoluzione e ha ottenuto buone prestazioni sia per i modelli piccoli che per quelli grandi. In altre parole, se volete un’alta precisione, scegliete una EfficientNet-B7 da 600×600 e 66M parametri. Se vuoi una bassa latenza e un modello più piccolo, vai per un 224×224 e 5.3M parametri EfficientNet-B0. Problema risolto.
Se finisci di leggere i 10 articoli precedenti, dovresti avere una buona conoscenza della storia della classificazione delle immagini con CNN. Se volete continuare ad imparare questo settore, ho anche elencato alcuni altri documenti interessanti da leggere. Anche se non sono inclusi nella lista dei primi 10, questi articoli sono tutti famosi nella loro area e hanno ispirato molti altri ricercatori nel mondo.
2014: SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPPNet prende in prestito l’idea di feature pyramid dalla tradizionale estrazione di feature di computer vision. Questa piramide forma un sacchetto di parole di caratteristiche con scale diverse, in modo che possa adattarsi a diverse dimensioni di input e sbarazzarsi dello strato completamente connesso di dimensioni fisse. Questa idea ha anche ulteriormente ispirato il modulo ASPP di DeepLab, e anche FPN per il rilevamento degli oggetti.
2016: DenseNet
Reti Convoluzionali densamente connesse
DenseNet di Cornell estende ulteriormente l’idea di ResNet. Non solo fornisce connessioni di salto tra gli strati ma ha anche connessioni di salto da tutti gli strati precedenti.
2017: SENet
Reti di spremitura ed eccitazione
La rete Xception ha dimostrato che la correlazione cross-channel non ha molto a che fare con la correlazione spaziale. Tuttavia, come campione dell’ultima competizione ImageNet, SENet ha ideato un blocco Squeeze-and-Excitation e ha raccontato una storia diversa. Il blocco SE prima spreme tutti i canali in meno canali usando il pooling globale, applica una trasformazione completamente connessa, e poi li “eccita” di nuovo al numero originale di canali usando un altro strato completamente connesso. Quindi, essenzialmente, lo strato FC ha aiutato la rete a imparare le attenzioni sulla mappa delle caratteristiche di input.
2017: ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Costruito sopra il modulo a collo di bottiglia invertito di MobileNetV2, ShuffleNet ritiene che la convoluzione point-wise nella convoluzione separabile depthwise sacrifichi la precisione in cambio di meno calcolo. Per compensare questo, ShuffleNet ha aggiunto un’ulteriore operazione di rimescolamento dei canali per assicurarsi che la convoluzione point-wise non sia sempre applicata allo stesso “punto”. E in ShuffleNetV2, questo meccanismo di rimescolamento dei canali è ulteriormente esteso anche a un ramo di mappatura dell’identità ResNet, in modo che parte della caratteristica dell’identità venga utilizzata anche per rimescolare.
2018: Bag of Tricks
Bag of Tricks for Image Classification with Convolutional Neural Networks
Bag of Tricks si concentra sui trucchi comuni usati nel campo della classificazione delle immagini. Serve come un buon riferimento per gli ingegneri quando hanno bisogno di migliorare le prestazioni del benchmark. È interessante notare che questi trucchi, come l’aumento del mixup e il tasso di apprendimento del coseno, a volte possono ottenere miglioramenti di gran lunga migliori di una nuova architettura di rete.
Conclusione
Con il rilascio di EfficientNet, sembra che il benchmark di classificazione ImageNet giunga al termine. Con l’attuale approccio di deep learning, non ci sarà mai un giorno in cui potremo raggiungere il 99,999% di precisione su ImageNet, a meno che non avvenga un altro cambio di paradigma. Quindi, i ricercatori stanno cercando attivamente alcune nuove aree come l’apprendimento auto-supervisionato o semi-supervisionato per il riconoscimento visivo su larga scala. Nel frattempo, con i metodi esistenti, è diventata più una questione per ingegneri e imprenditori di trovare l’applicazione nel mondo reale di questa tecnologia non perfetta. In futuro, scriverò anche un’indagine per analizzare quelle applicazioni reali di computer vision basate sulla classificazione delle immagini, quindi rimanete sintonizzati! Se pensi che ci siano altri articoli importanti da leggere per la classificazione delle immagini, per favore lascia un commento qui sotto e facci sapere.
Originariamente pubblicato su http://yanjia.li il 31 luglio 2020
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based Learning Applied to Document Recognition
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
- Sergey Ioffe, Christian Szegedy, Batch Normalization: Accelerare l’addestramento delle reti profonde riducendo lo spostamento interno delle covariate
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition
- François Chollet, Xception: Deep Learning with Depthwise Separable Convolutions
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
- Mingxing Tan, Quoc V. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Connected Convolutional Networks
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Bag of Tricks for Image Classification with Convolutional Neural Networks