
L’allocazione delle risorse è un aspetto importante durante l’esecuzione di qualsiasi lavoro Spark. Se non è configurato correttamente, un lavoro Spark può consumare intere risorse del cluster e rendere le altre applicazioni affamate di risorse.
Questo blog aiuta a capire il flusso di base in un’applicazione Spark e quindi come configurare il numero di esecutori, le impostazioni di memoria di ogni esecutore e il numero di core per un lavoro Spark. Ci sono alcuni fattori che dobbiamo considerare per decidere i numeri ottimali per i tre di cui sopra, come:
- La quantità di dati
- Il tempo in cui un lavoro deve essere completato
- Allocazione statica o dinamica delle risorse
- Applicazione upstream o downstream
- Introduzione
- Passi coinvolti nella modalità cluster per un lavoro Spark
- Allocazione statica
- Caso 1 Hardware – 6 Nodi e ogni nodo ha 16 core, 64 GB di RAM
- Caso 2 Hardware – 6 Nodi e Ogni nodo ha 32 Core, 64 GB
- Caso 3 – Quando non è richiesta più memoria per gli esecutori
- Tabella riassuntiva
- Allocazione dinamica
Introduzione
Iniziamo con alcune definizioni di base dei termini usati nella gestione delle applicazioni Spark.
Partizioni : Una partizione è un piccolo pezzo di un grande insieme di dati distribuiti. Spark gestisce i dati utilizzando partizioni che aiutano a parallelizzare l’elaborazione dei dati con un minimo rimescolamento dei dati tra gli esecutori.
Task : Un task è un’unità di lavoro che può essere eseguito su una partizione di un set di dati distribuiti e viene eseguito su un singolo esecutore. L’unità di esecuzione parallela è a livello di task. Tutti i task di una singola fase possono essere eseguiti in parallelo
Executor : Un executor è un singolo processo JVM che viene lanciato per un’applicazione su un nodo worker. L’esecutore esegue i compiti e mantiene i dati in memoria o su disco attraverso di essi. Ogni applicazione ha i propri executor. Un singolo nodo può eseguire più esecutori e gli esecutori per un’applicazione possono abbracciare più nodi lavoratori. Un executor rimane attivo per la durata dell’applicazione Spark ed esegue i compiti in più thread. Il numero di esecutori per un’applicazione Spark può essere specificato all’interno di SparkConf o tramite il flag -num-executors da riga di comando.
Cluster Manager : Un servizio esterno per l’acquisizione di risorse sul cluster (ad esempio un manager standalone, Mesos, YARN). Spark è agnostico nei confronti di un cluster manager fintanto che può acquisire processi di esecuzione e questi possono comunicare tra loro.Siamo principalmente interessati a Yarn come cluster manager. Un cluster Spark può essere eseguito in modalità yarn cluster o yarn-client:
modalità yarn-client – Un driver viene eseguito sul processo client, l’Application Master viene utilizzato solo per richiedere risorse da YARN.
modalità yarn-cluster – Un driver viene eseguito all’interno del processo application master, il client viene eliminato una volta che l’applicazione viene inizializzata
Cores : Un core è un’unità di calcolo di base della CPU e una CPU può avere uno o più core per eseguire compiti in un dato momento. Più core abbiamo, più lavoro possiamo fare. In Spark, questo controlla il numero di compiti paralleli che un esecutore può eseguire.
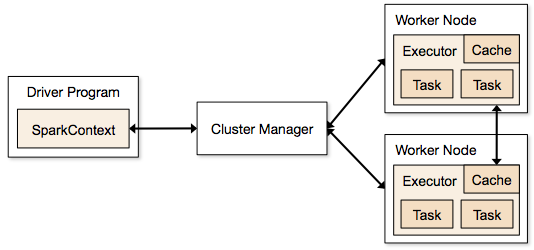
Passi coinvolti nella modalità cluster per un lavoro Spark
- Dal codice del driver, SparkContext si collega al cluster manager (standalone/Mesos/YARN).
- Il cluster manager alloca le risorse tra le altre applicazioni. Qualsiasi gestore di cluster può essere utilizzato finché i processi di esecuzione sono in esecuzione e comunicano tra loro.
- Spark acquisisce gli esecutori sui nodi nel cluster. Qui ogni applicazione otterrà i propri processi esecutori.
- Il codice dell’applicazione (file jar/python/file egg) viene inviato agli esecutori
- I compiti vengono inviati da SparkContext agli esecutori.
Dai passaggi precedenti, è chiaro che il numero di esecutori e la loro impostazione della memoria giocano un ruolo importante in un lavoro spark. Eseguire gli esecutori con troppa memoria spesso si traduce in eccessivi ritardi di garbage collection
Ora cerchiamo di capire, come configurare il miglior set di valori per ottimizzare un lavoro Spark.
Ci sono due modi in cui configuriamo i dettagli dell’esecutore e del core al lavoro Spark. Sono:
- Allocazione statica – I valori sono dati come parte di spark-submit
- Allocazione dinamica – I valori sono raccolti in base al requisito (dimensione dei dati, quantità di calcoli necessari) e rilasciati dopo l’uso. Questo aiuta le risorse ad essere riutilizzate per altre applicazioni.
Allocazione statica
Diversi casi sono discussi variando diversi parametri e arrivando a diverse combinazioni secondo i requisiti dell’utente/dati.
Caso 1 Hardware – 6 Nodi e ogni nodo ha 16 core, 64 GB di RAM
Primo su ogni nodo, 1 core e 1 GB è necessario per il sistema operativo e i demoni Hadoop, quindi abbiamo 15 core, 63 GB di RAM per ogni nodo
Iniziamo con come scegliere il numero di core:
Numero di core = compiti concorrenti che un esecutore può eseguire
Quindi potremmo pensare che più compiti concorrenti per ogni esecutore daranno migliori prestazioni. Ma la ricerca mostra che qualsiasi applicazione con più di 5 compiti concorrenti, porterebbe ad un cattivo spettacolo. Quindi il valore ottimale è 5.
Questo numero deriva dalla capacità di un esecutore di eseguire compiti paralleli e non da quanti core ha un sistema. Quindi il numero 5 rimane lo stesso anche se abbiamo il doppio (32) dei core nella CPU
Numero di esecutori:
Venendo al passo successivo, con 5 come core per esecutore, e 15 come core totali disponibili in un nodo (CPU) – arriviamo a 3 esecutori per nodo che è 15/5. Dobbiamo calcolare il numero di esecutori su ogni nodo e poi ottenere il numero totale per il lavoro.
Quindi con 6 nodi, e 3 esecutori per nodo – otteniamo un totale di 18 esecutori. Su 18 abbiamo bisogno di 1 esecutore (processo java) per Application Master in YARN. Quindi il numero finale è 17 esecutori
Questo 17 è il numero che diamo a spark usando -num-executors durante l’esecuzione dal comando shell spark-submit
Memoria per ogni esecutore:
Dal passo precedente, abbiamo 3 esecutori per nodo. E la RAM disponibile su ogni nodo è di 63 GB
Quindi la memoria per ogni esecutore in ogni nodo è 63/3 = 21GB.
Tuttavia una piccola memoria di overhead è anche necessaria per determinare la richiesta di memoria completa a YARN per ogni esecutore.
La formula per quell’overhead è max(384, .07 * spark.executor.memory)
Calcolando quell’overhead: .07 * 21 (Qui 21 è calcolato come sopra 63/3) = 1.47
Siccome 1.47 GB > 384 MB, l’overhead è 1.47
Prendi il sopra da ogni 21 sopra => 21 – 1.47 ~ 19 GB
Così memoria esecutore – 19 GB
Numeri finali – Esecutori – 17, Core 5, Memoria esecutore – 19 GB
Caso 2 Hardware – 6 Nodi e Ogni nodo ha 32 Core, 64 GB
Numero di core di 5 è uguale per buona concorrenza come spiegato sopra.
Numero di esecutori per ogni nodo = 32/5 ~ 6
Quindi esecutori totali = 6 * 6 Nodi = 36. Allora il numero finale è 36 – 1 (per AM) = 35
Memoria esecutori:
6 esecutori per ogni nodo. 63/6 ~ 10. L’overhead è .07 * 10 = 700 MB. Quindi, arrotondando a 1 GB come overhead, otteniamo 10-1 = 9 GB
Numeri finali – Esecutori – 35, Core 5, Memoria esecutori – 9 GB
Caso 3 – Quando non è richiesta più memoria per gli esecutori
Gli scenari precedenti iniziano accettando il numero di core come fisso e passando al numero di esecutori e memoria.
Ora per il primo caso, se pensiamo che non abbiamo bisogno di 19 GB, e solo 10 GB sono sufficienti in base alla dimensione dei dati e ai calcoli coinvolti, allora i numeri sono i seguenti:
Core: 5
Numero di esecutori per ogni nodo = 3. Ancora 15/5 come calcolato sopra.
A questo punto, questo porterebbe a 21 GB, e quindi 19 come da nostro primo calcolo. Ma siccome abbiamo pensato che 10 va bene (supponiamo un piccolo overhead), allora non possiamo passare il numero di esecutori per nodo a 6 (come 63/10). Perché con 6 esecutori per nodo e 5 core si arriva a 30 core per nodo, quando abbiamo solo 16 core. Quindi dobbiamo anche cambiare il numero di core per ogni esecutore.
Quindi calcolando di nuovo,
Il numero magico 5 arriva a 3 (qualsiasi numero minore o uguale a 5). Quindi con 3 core, e 15 core disponibili – otteniamo 5 esecutori per nodo, 29 esecutori ( che è (5*6 -1)) e la memoria è 63/5 ~ 12.
Overhead è 12*.07=.84. Quindi la memoria degli esecutori è 12 – 1 GB = 11 GB
I numeri finali sono 29 esecutori, 3 core, la memoria degli esecutori è 11 GB
Tabella riassuntiva
Allocazione dinamica
Nota: Il limite superiore del numero di esecutori se l’allocazione dinamica è abilitata è infinito. Quindi questo dice che l’applicazione spark può divorare tutte le risorse se necessario. In un cluster dove abbiamo altre applicazioni in esecuzione e anche loro hanno bisogno di core per eseguire i compiti, dobbiamo assicurarci di assegnare i core a livello di cluster.
Questo significa che possiamo assegnare un numero specifico di core per le applicazioni basate su YARN in base all’accesso dell’utente. Quindi possiamo creare un spark_user e poi dare dei core (min/max) per quell’utente. Questi limiti sono per la condivisione tra spark e altre applicazioni che girano su YARN.
Per capire l’allocazione dinamica, abbiamo bisogno di conoscere le seguenti proprietà:
spark.dynamicAllocation.enabled – quando questo è impostato su true non abbiamo bisogno di menzionare gli executor. La ragione è la seguente:
I numeri dei parametri statici che diamo a spark-submit sono per l’intera durata del lavoro. Tuttavia se entra in gioco l’allocazione dinamica, ci sarebbero diverse fasi come le seguenti:
Qual è il numero di esecutori con cui iniziare:
Numero iniziale di esecutori (spark.dynamicAllocation.initialExecutors) con cui iniziare
Controllo del numero di esecutori dinamicamente:
Poi in base al carico (compiti in sospeso) quanti esecutori richiedere. Questo sarebbe alla fine il numero che diamo a spark-submit in modo statico. Quindi, una volta che i numeri iniziali di esecutori sono impostati, andiamo ai numeri min (spark.dynamicAllocation.minExecutors) e max (spark.dynamicAllocation.maxExecutors).
Quando chiedere nuovi esecutori o dare via gli esecutori correnti:
Quando richiediamo nuovi esecutori (spark.dynamicAllocation.schedulerBacklogTimeout) – Questo significa che ci sono stati compiti in sospeso per questa durata. Quindi la richiesta del numero di esecutori richiesti in ogni round aumenta esponenzialmente dal round precedente. Per esempio, un’applicazione aggiungerà 1 esecutore nel primo turno, e poi 2, 4, 8 e così via nei turni successivi. A un punto specifico, la proprietà max di cui sopra entra in scena.
Quando diamo via un esecutore è impostato utilizzando spark.dynamicAllocation.executorIdleTimeout.
Per concludere, se abbiamo bisogno di più controllo sul tempo di esecuzione del lavoro, monitorare il lavoro per il volume di dati inaspettato i numeri statici aiuterebbero. Passando alla dinamica, le risorse verrebbero utilizzate in background e i lavori che coinvolgono volumi inaspettati potrebbero influenzare altre applicazioni.
.