
La prima cosa che dobbiamo capire è la natura delle variabili e come le variabili sono usate nel disegno di uno studio per rispondere alle domande dello studio. In questo capitolo imparerete:
- diversi tipi di variabili negli studi quantitativi,
- problemi che circondano la domanda sull’unità di analisi.
Comprendere le variabili quantitative
La radice della parola variabile è legata alla parola “variare”, il che dovrebbe aiutarci a capire cosa potrebbero essere le variabili. Le variabili sono elementi, entità o fattori che possono cambiare (variare); per esempio, la temperatura esterna, il costo della benzina per gallone, il peso di una persona e l’umore delle persone nella vostra famiglia estesa sono tutte variabili. In altre parole, possono avere valori diversi in condizioni diverse o per persone diverse.
Utilizziamo le variabili per descrivere caratteristiche o fattori di interesse. Esempi possono essere il numero di membri in diverse famiglie, la distanza da fonti di cibo salutare in diversi quartieri, il rapporto tra docenti di lavoro sociale e studenti in un programma di BSW o MSW, la proporzione di persone di diversi gruppi razziali/etnici incarcerati, il costo del trasporto per ricevere servizi da un programma di lavoro sociale, o il tasso di mortalità infantile in diverse contee. Nella ricerca sugli interventi di lavoro sociale, le variabili potrebbero includere le caratteristiche dell’intervento (intensità, frequenza, durata) e i risultati associati all’intervento.
Variabili demografiche. Gli assistenti sociali sono spesso interessati a quelle che chiamiamo variabili demografiche. Le variabili demografiche sono usate per descrivere le caratteristiche di una popolazione, gruppo o campione della popolazione. Esempi di variabili demografiche frequentemente applicate sono
- età,
- etnia,
- origine nazionale,
- affiliazione religiosa,
- genere,
- orientamento sessuale,
- stato civile/relazionale,
- stato lavorativo,
- affiliazione politica,
- località geografica,
- livello d’istruzione, e
- reddito.
A un livello più macro, la demografia di una comunità o di un’organizzazione spesso include le sue dimensioni; le organizzazioni sono spesso misurate in termini del loro budget complessivo.
Variabili indipendenti e dipendenti. Il modo in cui gli investigatori pensano alle variabili di studio ha importanti implicazioni per il disegno di uno studio. Gli investigatori decidono se farle servire come variabili indipendenti o come variabili dipendenti. Questa distinzione non è qualcosa di inerente a una variabile, ma si basa su come il ricercatore sceglie di definire ogni variabile. Le variabili indipendenti sono quelle a cui si potrebbe pensare come le variabili di “input” manipolate, mentre le variabili dipendenti sono quelle in cui l’impatto o “output” di quella variazione di input verrebbe osservato.
La manipolazione intenzionale della variabile “input” (indipendente) non è sempre coinvolta. Si consideri l’esempio di uno studio condotto in Svezia che esamina la relazione tra l’essere stato vittima di maltrattamento infantile e il successivo assenteismo dalla scuola superiore: nessuno ha manipolato intenzionalmente se i bambini sarebbero stati vittime di maltrattamento infantile (Hagborg, Berglund, & Fahlke, 2017). Gli investigatori hanno ipotizzato che le differenze che si verificano naturalmente nella variabile di input (storia di maltrattamento infantile) sarebbero state associate a una variazione sistematica in una specifica variabile di risultato (assenteismo scolastico). In questo caso, la variabile indipendente era una storia di maltrattamento infantile e la variabile dipendente era il risultato dell’assenteismo scolastico. In altre parole, la variabile indipendente è ipotizzata dal ricercatore per causare una variazione o un cambiamento nella variabile dipendente. Questo è ciò che potrebbe apparire in un diagramma dove “x” è la variabile indipendente e “y” è la variabile dipendente (nota: avete visto questa designazione prima, nel Capitolo 3, quando abbiamo discusso la logica di causa ed effetto):

Per un altro esempio, considerate la ricerca che indica che essere vittima di maltrattamento infantile è associato a un rischio maggiore di uso di sostanze durante l’adolescenza (Yoon, Kobulsky, Yoon, & Kim, 2017). La variabile indipendente in questo modello sarebbe avere una storia di maltrattamento infantile. La variabile dipendente sarebbe il rischio di uso di sostanze durante l’adolescenza. Questo esempio è ancora più elaborato perché specifica il percorso attraverso il quale la variabile indipendente (maltrattamento infantile) potrebbe imporre i suoi effetti sulla variabile dipendente (uso di sostanze nell’adolescenza). Gli autori dello studio hanno dimostrato che lo stress post-traumatico (PTS) era un legame tra l’abuso infantile (fisico e sessuale) e l’uso di sostanze durante l’adolescenza.

Prendetevi un momento per completare la seguente attività.
Tipi di variabili quantitative
Ci sono anche altri modi significativi per pensare alle variabili di interesse. Consideriamo diverse caratteristiche delle variabili usate negli studi di ricerca quantitativa. Qui esploriamo le variabili quantitative come categoriche, ordinali o a intervalli. Queste caratteristiche hanno implicazioni sia per la misurazione che per l’analisi dei dati.
Variabili categoriche. Alcune variabili possono assumere valori che variano, ma non in modo numerico significativo. Invece, potrebbero essere definite in termini di categorie possibili. Logicamente, queste sono chiamate variabili categoriche. I software statistici e i libri di testo a volte si riferiscono alle variabili con categorie come variabili nominali. Nominale può essere pensato in termini della radice latina “nom” che significa “nome”, e non dovrebbe essere confuso con il numero. Nominale significa la stessa cosa di categorico nel descrivere le variabili. In altre parole, le variabili categoriche o nominali sono identificate dai nomi o dalle etichette delle categorie rappresentate. Per esempio, il colore dell’ultima auto su cui siete saliti sarebbe una variabile categorica: blu, nero, argento, bianco, rosso, verde, giallo, o altro sono categorie della variabile che potremmo chiamare colore dell’auto.
Quello che è importante con le variabili categoriche è che queste categorie non hanno alcuna sequenza o ordine numerico rilevante. Non c’è alcuna differenza numerica tra i diversi colori di auto, o differenza tra “sì” o “no” come categorie nel rispondere se avete guidato un’auto blu. Non c’è alcun ordine implicito o gerarchia per le categorie “Ispanico o Latino” e “Non Ispanico o Latino” in una variabile di etnia; né c’è alcun ordine rilevante per le categorie di variabili come il genere, lo stato o la regione geografica in cui una persona risiede, o se la residenza di una persona è di proprietà o in affitto.
Se un ricercatore ha deciso di usare numeri come simboli relativi alle categorie in una variabile del genere, i numeri sono arbitrari – ogni numero è essenzialmente solo un nome diverso e più breve per ogni categoria. Per esempio, la variabile sesso potrebbe essere codificata nei seguenti modi, e non farebbe alcuna differenza, purché il codice sia applicato in modo coerente.
| Opzione di codifica A | categorie di variabili | Opzione di codifica B |
|---|---|---|
| 1 | maschio | 2 |
| 2 | femmina | 1 |
| 3 | altro che maschio o femmina da soli | 4 |
| 4 | preferiscono non rispondere | 3 |
Razze ed etnie.Una delle variabili categoriche più comunemente esplorate nel lavoro sociale e nella ricerca sulle scienze sociali è quella demografica che si riferisce al background razziale e/o etnico di una persona. Molti studi utilizzano le categorie specificate nei passati rapporti del Census Bureau degli Stati Uniti. Ecco cosa dice l’U.S. Census Bureau sulle due distinte variabili demografiche, razza ed etnia (https://www.census.gov/mso/www/training/pdf/race-ethnicity-onepager.pdf):
Che cos’è la razza? Il Census Bureau definisce la razza come l’autoidentificazione di una persona con uno o più gruppi sociali. Un individuo può dichiarare di essere bianco, nero o afroamericano, asiatico, indiano d’America e nativo dell’Alaska, nativo hawaiano e altro isolano del Pacifico, o di qualche altra razza. Gli intervistati possono segnalare più razze.
Che cos’è l’etnia? L’etnia determina se una persona è di origine ispanica o meno. Per questo motivo, l’etnia è suddivisa in due categorie, Ispanico o Latino e Non Ispanico o Latino. Gli ispanici possono segnalare come qualsiasi razza.
In altre parole, il Census Bureau definisce due categorie per la variabile chiamata etnia (ispanici o latini e non ispanici o latini), e sette categorie per la variabile chiamata razza. Mentre queste variabili e categorie sono spesso applicate nelle scienze sociali e nella ricerca sul lavoro sociale, non sono senza critiche.
In base a queste categorie, ecco cosa si stima essere vero della popolazione statunitense nel 2016:
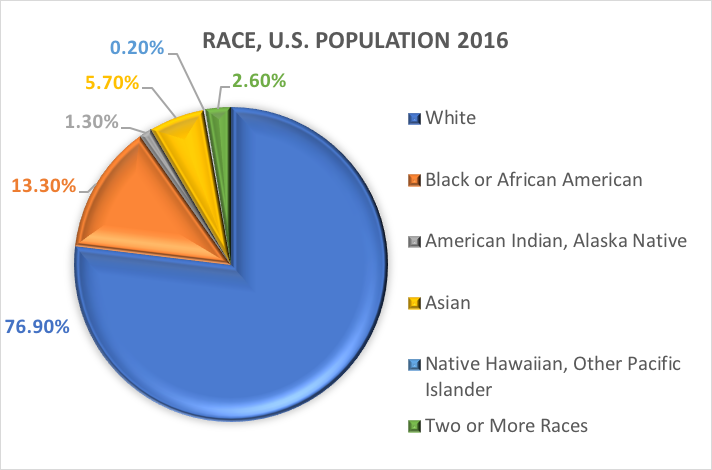
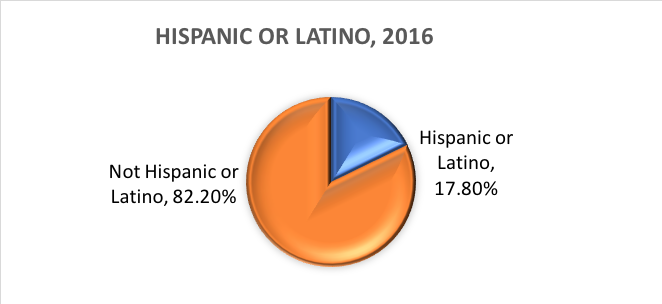
Variabili dicotomiche.Esiste una categoria speciale di variabile categorica con implicazioni per certe analisi statistiche. Le variabili categoriche che comprendono esattamente due opzioni, né più né meno, sono chiamate variabili dicotomiche. Un esempio è la dicotomia dell’U.S. Census Bureau tra etnia ispanica/latina e non ispanica/non-latina. Per un altro esempio, gli investigatori potrebbero voler confrontare le persone che completano il trattamento con quelle che lo abbandonano prima di completarlo. Con le due categorie, completato o non completato, questa variabile di completamento del trattamento non è solo categorica, è dicotomica. Anche le variabili in cui gli individui rispondono “sì” o “no” sono di natura dicotomica.
La tradizione passata di trattare il genere come maschio o femmina è un altro esempio di variabile dicotomica. Tuttavia, esistono argomenti molto forti per non trattare più il genere in questo modo dicotomico: una maggiore varietà di identità di genere è dimostrabilmente rilevante nel lavoro sociale per le persone la cui identità non si allinea con le categorie dicotomiche (chiamate anche binarie) di uomo/donna o maschio/femmina. Queste includono categorie come agender, androgino, bigender, cisgender, gender expansive, gender fluid, gender questioning, queer, transgender e altre.
Variabili ordinali. A differenza di queste variabili categoriche, a volte le categorie di una variabile hanno una sequenza logica numerica o un ordine. Ordinale, per definizione, si riferisce a una posizione in una serie. Le variabili con categorie numericamente rilevanti sono chiamate variabili ordinali. Per esempio, c’è un ordine implicito di categorie dal meno al più con la variabile chiamata livello di istruzione. Le categorie dei dati del U.S. Le categorie dei dati del censimento degli Stati Uniti per questa variabile ordinale sono:
- nessuno
- 1a-4a elementare
- 5a-6a elementare
- 7a-8a elementare
- 9a elementare
- 10a elementare
- 11a elementare
- diploma di scuola superiore
- qualche università, nessuna laurea
- laurea associata, Occupational
- associate’s degree academic
- bachelor’s degree
- master’s degree
- professional degree
- doctoral degree
Guardando i dati del Census Bureau del 2016 per questa variabile, possiamo vedere che le donne superano i maschi nella categoria di aver conseguito un bachelor’s degree: delle 47.718.000 persone in questa categoria, 22.485.000 erano maschi e 25.234.000 erano femmine. Mentre questo modello di genere si è mantenuto per coloro che hanno ricevuto diplomi di master, il modello è stato invertito per la ricezione di diplomi di dottorato: più maschi che femmine hanno ottenuto questo livello più alto di istruzione. È anche interessante notare che le femmine superavano i maschi all’estremità bassa dello spettro: 441.000 femmine hanno riferito di non avere istruzione rispetto a 374.000 maschi.
Ecco un altro esempio dell’uso di variabili ordinali nella ricerca sul lavoro sociale: quando gli individui cercano un trattamento per un problema di abuso di alcol, gli operatori sociali potrebbero voler sapere se questo è il loro primo, secondo, terzo, o qualsiasi altro serio tentativo numerato di cambiare il loro comportamento nel bere. I partecipanti arruolati in uno studio di confronto degli approcci di trattamento per i disturbi da uso di alcol hanno riferito che lo studio di intervento era ovunque dal primo all’undicesimo tentativo di cambiamento significativo (Begun, Berger, Salm-Ward, 2011). Questa variabile del tentativo di cambiamento ha implicazioni su come gli operatori sociali potrebbero interpretare i dati che valutano un intervento che non è stato il primo tentativo per tutte le persone coinvolte.
Scale di valutazione. Consideriamo un tipo diverso ma comunemente usato di variabile ordinale: le scale di valutazione. Gli investigatori sociali, comportamentali e di lavoro sociale spesso chiedono ai partecipanti allo studio di applicare una scala di valutazione per descrivere le loro conoscenze, attitudini, credenze, opinioni, abilità o comportamenti. Poiché le categorie su una tale scala sono in sequenza (dalla più alla meno o dalla meno alla più), chiamiamo queste variabili ordinali.

Gli esempi includono la valutazione dei partecipanti:
- quanto sono d’accordo o in disaccordo con certe affermazioni (da per niente a moltissimo);
- quanto spesso si impegnano in certi comportamenti (da mai a sempre);
- quanto spesso si impegnano in certi comportamenti (ogni ora, giorno, settimana, mese, anno, o meno spesso);
- la qualità della prestazione di qualcuno (da scarsa a eccellente);
- quanto sono stati soddisfatti del loro trattamento (da molto insoddisfatto a molto soddisfatto)
- il loro livello di fiducia (da molto basso a molto alto).
Variabili di intervallo. Ancora altre variabili assumono valori che variano in modo numerico significativo. Dalla nostra lista di variabili demografiche, l’età è un esempio comune. Il valore numerico assegnato a una singola persona indica il numero di anni da quando la persona è nata (nel caso dei neonati, il valore numerico può indicare giorni, settimane o mesi dalla nascita). Qui i possibili valori della variabile sono ordinati, come le variabili ordinali, ma viene introdotta una grande differenza: la natura degli intervalli tra i possibili valori. Con le variabili intervallari la “distanza” tra valori possibili adiacenti è uguale. Alcuni pacchetti di software statistici e libri di testo usano il termine variabile di scala: questa è esattamente la stessa cosa di ciò che noi chiamiamo una variabile di intervallo.
Per esempio, nel grafico qui sotto, la differenza di 1 oncia tra questa persona che consuma 1 oncia o 2 once di alcol (lunedì, martedì) è esattamente uguale alla differenza di 1 oncia tra consumare 4 once o 5 once (venerdì, sabato). Se dovessimo schematizzare i possibili punti sulla scala, sarebbero tutti equidistanti; l’intervallo tra due punti qualsiasi è misurato in unità standard (once, in questo esempio).
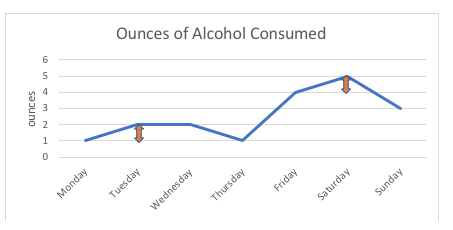
Con le variabili ordinali, come una scala di valutazione, nessuno può dire con certezza che la “distanza” tra le opzioni di risposta di “mai” e “a volte” è la stessa della “distanza” tra “a volte” e “spesso”, anche se abbiamo usato dei numeri per sequenziare queste opzioni di risposta. Così, la scala di valutazione rimane ordinale, non intervallare.
Quello che potrebbe confondere un po’ è che alcuni programmi di software statistici, come SPSS, si riferiscono a una variabile di intervallo come una variabile “scala”. Molte variabili usate nella ricerca sul lavoro sociale sono ordinate e hanno distanze uguali tra i punti. Consideriamo per esempio la variabile dell’ordine di nascita. Questa variabile è intervallare perché:
- i possibili valori sono ordinati (per esempio, il terzo figlio è nato dopo il primo e il secondo e prima del quarto), e
- le “distanze” o intervalli sono misurati in unità equivalenti di una persona.
Variabili continue. Esiste un tipo speciale di variabile numerica a intervalli che chiamiamo variabili continue. Una variabile come l’età potrebbe essere trattata come una variabile continua. L’età è di natura ordinale, poiché i numeri più alti significano qualcosa in relazione ai numeri più piccoli. L’età soddisfa anche i nostri criteri per essere una variabile di intervallo se la misuriamo in anni (o mesi o settimane o giorni) perché è ordinale e c’è la stessa “distanza” tra avere 15 e 30 anni come tra avere 40 e 55 anni (15 anni di calendario). Ciò che la rende una variabile continua è che ci sono anche possibili e significativi punti di “frazione” tra due intervalli qualsiasi. Per esempio, una persona può avere 20½ (20,5) o 20¼ (20,25) o 20¾ (20,75) anni; non siamo limitati solo ai numeri interi per l’età. Al contrario, quando abbiamo guardato l’ordine di nascita, non possiamo avere una frazione significativa di una persona tra due posizioni sulla scala.
Il caso speciale del reddito. Una delle variabili più abusate nelle scienze sociali e nella ricerca sul lavoro sociale è la variabile relativa al reddito. Si consideri un esempio sul reddito familiare (indipendentemente da quante persone ci sono nella famiglia). Questa variabile potrebbe essere categorica (nominale), ordinale o intervallare (scala) a seconda di come viene gestita.
Esempio categorico: A seconda della natura delle domande di ricerca, un ricercatore potrebbe semplicemente scegliere di utilizzare le categorie dicotomiche di “sufficientemente dotato di risorse” e “insufficientemente dotato di risorse” per classificare le famiglie, sulla base di qualche metodo di calcolo standard. Questi potrebbero essere chiamati “poveri” e “non poveri” se una soglia di povertà viene usata per classificare le famiglie. Queste categorie distinte della variabile reddito non sono significativamente sequenziate in modo numerico, quindi è una variabile categorica.
Esempio ordinale: Le categorie per classificare le famiglie potrebbero essere ordinate dal basso all’alto. Per esempio, queste categorie per il reddito annuale sono comuni nelle ricerche di mercato:
- Meno di $25,000.
- $25,000 a $34,999.
- $35,000 a $49,999.
- $50,000 a $74,999.
- $75,000 a $99,999.
- $100.000 a $149.999.
- $150.000 a $199.999.
- $200.000 o più.
Si noti che le categorie non sono di uguali dimensioni-la “distanza” tra coppie di categorie non è sempre la stessa. Iniziano con incrementi di circa 10.000 dollari, passano a incrementi di 25.000 dollari e finiscono con incrementi di circa 50.000 dollari.
Esempio di intervallo. Se un ricercatore ha chiesto ai partecipanti allo studio di riportare un importo in dollari effettivo per il reddito familiare, vedremmo una variabile di intervallo. I possibili valori sono ordinati e l’intervallo tra ogni possibile unità adiacente è di $1 (finché non si usano frazioni di dollaro o centesimi). Così, un reddito di $10.452 è la stessa distanza su un continuum da $9.452 e $11.452-$1.000 in entrambi i casi.

Il caso speciale dell’età. Come il reddito, “età” può significare cose diverse in studi diversi. L’età è di solito un indicatore di “tempo dalla nascita”. Possiamo calcolare l’età di una persona sottraendo una variabile data di nascita dalla data di misurazione (data odierna meno data di nascita). Per gli adulti, le età sono tipicamente misurate in anni dove i possibili valori adiacenti sono distanziati in unità di 1 anno: 18, 19, 20, 21, 22, e così via. Così, la variabile età potrebbe essere un tipo continuo di variabile di intervallo.
Tuttavia, un ricercatore potrebbe desiderare di far collassare i dati sull’età in categorie ordinate o gruppi di età. Questi sarebbero ancora ordinali, ma potrebbero non essere più intervalli se gli incrementi tra i possibili valori non sono unità equivalenti. Per esempio, se siamo più interessati all’età che rappresenta specifici periodi di sviluppo umano, gli intervalli di età potrebbero non essere uguali tra i criteri di età. Possibilmente potrebbero essere:
- Infanzia (dalla nascita ai 18 mesi)
- Infanzia (dai 18 mesi ai 2 anni e mezzo)
- Prescuola (dai 2 anni e mezzo ai 5 anni)
- Età scolastica (dai 6 agli 11 anni)
- Adolescenza (da 12 a 17 anni)
- Adolescenza emergente (da 18 a 25 anni)
- Adolescenza (da 26 a 45 anni)
- Adolescenza media (da 46 a 60 anni)
- Giovani-Old Adulthood (da 60 a 74 anni)
- Middle-Old Adulthood (da 75 a 84 anni)
- Old-Old Adulthood (85 o più anni)
L’età potrebbe anche essere trattata come una variabile strettamente categorica (non ordinale). Per esempio, se la variabile di interesse è se qualcuno ha l’età legale per bere (21 anni o più), o no. Abbiamo due categorie – soddisfa o non soddisfa i criteri dell’età legale per bere negli Stati Uniti – e l’una potrebbe essere codificata con un “1” e l’altra con uno “0” o un “2” senza alcuna differenza di significato.
Qual è la risposta “giusta” su come misurare l’età (o il reddito)? La risposta è “dipende”. Quello da cui dipende è la natura della domanda di ricerca: quale concettualizzazione dell’età (o del reddito) è più rilevante per lo studio che si sta progettando.
Variabili alfanumeriche. Infine, ci sono dati che non rientrano in nessuna di queste classificazioni. A volte le informazioni che conosciamo sono sotto forma di un indirizzo o numero di telefono, un nome o cognome, codice postale o altre frasi. Questi tipi di informazioni sono talvolta chiamati variabili alfanumeriche. Considerate la variabile “indirizzo” per esempio: l’indirizzo di una persona potrebbe essere composto da caratteri numerici (il numero civico) e caratteri letterali (che compongono i nomi di strada, città e stato), come 1600 Pennsylvania Ave. NW, Washington, DC, 20500.

In realtà, abbiamo diverse variabili presenti in questo esempio di indirizzo:
- l’indirizzo stradale: 1600 Pennsylvania Ave.
- la città (e lo “stato”): Washington, DC
- il codice postale: 20500.
Questo tipo di informazione non rappresenta categorie quantitative specifiche o valori con significato sistematico nei dati. Queste sono anche chiamate a volte variabili “stringa” in alcuni pacchetti software perché sono costituite da una stringa di simboli. Per essere utile ad un investigatore, una tale variabile dovrebbe essere convertita o ricodificata in valori significativi.
Una nota sull’unità di analisi
Una cosa importante da tenere a mente nel pensare alle variabili è che i dati possono essere raccolti a molti livelli diversi di osservazione. Gli elementi studiati potrebbero essere singole cellule, sistemi di organi o persone. Oppure, il livello di osservazione potrebbe essere costituito da coppie di individui, come coppie, fratelli e sorelle, o diadi genitori-figli. In questo caso, lo sperimentatore può raccogliere informazioni sulla coppia da ogni individuo, ma sta guardando i dati di ogni coppia. Quindi, diremmo che l’unità di analisi è la coppia o diade, non ogni singola persona. L’unità di analisi potrebbe anche essere un gruppo più grande: per esempio, i dati potrebbero essere raccolti da ciascuno degli studenti di intere classi, dove l’unità di analisi sono le classi di una scuola o di un sistema scolastico. Oppure, l’unità di analisi potrebbe essere a livello di quartieri, programmi, organizzazioni, contee, stati o persino nazioni. Per esempio, molte delle variabili usate come indicatori della sicurezza alimentare a livello di comunità, come l’accessibilità e l’economicità, si basano su dati raccolti da singole famiglie (Kaiser, 2017). L’unità di analisi negli studi che utilizzano questi indicatori sarebbero le comunità messe a confronto. Questa distinzione ha importanti implicazioni per la misurazione e l’analisi dei dati.
Un promemoria sulle variabili rispetto ai livelli delle variabili
Uno studio potrebbe essere descritto in termini di numero di categorie variabili, o livelli, che vengono confrontati. Per esempio, potreste vedere uno studio descritto come un disegno 2 X 2 – pronunciato come un disegno a due a due. Questo significa che ci sono 2 categorie possibili per la prima variabile e 2 categorie possibili per l’altra variabile – sono entrambe variabili dicotomiche. Uno studio che confronta 2 categorie della variabile “disturbo da uso di alcol” (categorie per soddisfare i criteri, sì o no) con 2 categorie della variabile “disturbo da uso di sostanze illecite” (categorie per soddisfare i criteri, sì o no) avrebbe 4 possibili risultati (matematicamente, 2 x 2=4) e potrebbe essere schematizzato così (dati basati sulle proporzioni del sondaggio NSDUH del 2016, presentati in SAMHSA, 2017):
| Disturbo da uso di sostanze illecite (SUD) | |||
|---|---|---|---|
|
Disturbo da uso di alcol (AUD) |
No | Sì | |
| No | 500 | 10 | |
| Sì | 26 | 4 | |
La lettura delle 4 celle di questa tabella 2 X 2 ci dice che in questo (ipotetico) sondaggio di 540 individui, 500 non hanno soddisfatto i criteri per un disturbo da uso di alcol o di sostanze illecite (No, No); 26 hanno soddisfatto i criteri per un disturbo da uso di alcol (Sì, No); 10 hanno soddisfatto i criteri per un disturbo da uso di sostanze illecite (No, Sì), e 4 hanno soddisfatto i criteri per un disturbo da uso di alcol e sostanze illecite (Sì, Sì). Inoltre, applicando un po’ di matematica, possiamo vedere che un totale di 30 avevano un disturbo da uso di alcol (26 + 4) e 14 avevano un disturbo da uso di sostanze illecite (10 + 4). E, possiamo vedere che 40 avevano qualche tipo di disturbo da uso di sostanze (26 + 10 + 4).
 Per rendere questa distinzione tra variabili e livelli o categorie di variabili cristallina, consideriamo un altro esempio: un disegno di studio 2 X 3. In primo luogo, facendo i conti, dovremmo vedere 6 possibili risultati (celle). In secondo luogo, sappiamo che la prima variabile (gruppo di età) ha 2 categorie (sotto i 30 anni, 30 o più) e l’altra variabile (stato occupazionale) ha 3 categorie (completamente occupato, parzialmente occupato, disoccupato). Questa volta le 6 celle del nostro disegno sono vuote perché stiamo aspettando i dati.
Per rendere questa distinzione tra variabili e livelli o categorie di variabili cristallina, consideriamo un altro esempio: un disegno di studio 2 X 3. In primo luogo, facendo i conti, dovremmo vedere 6 possibili risultati (celle). In secondo luogo, sappiamo che la prima variabile (gruppo di età) ha 2 categorie (sotto i 30 anni, 30 o più) e l’altra variabile (stato occupazionale) ha 3 categorie (completamente occupato, parzialmente occupato, disoccupato). Questa volta le 6 celle del nostro disegno sono vuote perché stiamo aspettando i dati.
| Stato di occupazione | ||||
|---|---|---|---|---|
|
Gruppo di età |
Pienamente occupato | Parzialmente Occupato | Non occupato | |
| <30 | ||||
| ≥30 | ||||
Quindi, quando vedete la descrizione di un disegno di studio che assomiglia a due numeri che vengono moltiplicati, questo vi sta essenzialmente dicendo quante categorie o livelli di ogni variabile ci sono e vi porta a capire quante celle o possibili risultati esistono. Un disegno 3 X 3 ha 9 celle, un disegno 3 X 4 ha 12 celle, e così via. Questo problema diventa importante ancora una volta quando discuteremo delle dimensioni del campione nel Capitolo 6.
Completa la seguente attività del Workbook:
- SWK 3401.3-4.1 Beginning Data Entry
Riassunto del capitolo
In sintesi, i ricercatori progettano molti dei loro studi quantitativi per testare ipotesi sulle relazioni tra variabili. Comprendere la natura delle variabili coinvolte aiuta a capire e valutare la ricerca condotta. Comprendere le distinzioni tra diversi tipi di variabili, così come tra variabili e categorie, ha importanti implicazioni per il disegno dello studio, la misurazione e i campioni. Tra gli altri argomenti, il prossimo capitolo esplora l’intersezione tra la natura delle variabili studiate nella ricerca quantitativa e il modo in cui gli investigatori misurano tali variabili.
Prenditi un momento per completare la seguente attività.