
画像分類の学習を始めるために、10年間で最高の論文を素早くウォークスルーする。 コンピュータビジョン

コンピュータビジョンは画像や動画を機械的に変換する科目であります。理解できる信号です。 この信号があれば、プログラマーはこの高度な理解に基づいて、さらに機械の動作を制御することができます。 コンピュータビジョンの中でも、画像の分類は最も基本的なタスクの一つです。 この分類は、Google Photoのタグ付けやAIコンテンツモデレーションなど多くの製品で利用されているだけでなく、物体検出やビデオ理解など、より高度なビジョンタスクへの扉を開くものでもある。 この分野は、Deep Learningの登場以来、急速に変化しているため、初心者は学ぶのに圧倒されることが多いようです。 ソフトウェア工学とは異なり、DCNNを用いた画像分類に関する名著はあまりなく、この分野を理解するには、学術論文を読むのが一番です。 しかし、どんな論文を読めばいいのでしょうか? どこから手をつければいいのでしょうか? 今回は、初心者が読むべき論文ベスト10を紹介します。 これらの論文を読めば、この分野がどのように発展してきたか、研究者が過去の研究成果を基にどのように新しいアイデアを生み出したかが分かります。 とはいえ、すでにこの分野で働いている方でも、全体像を整理するのに役立つと思います。 では、さっそくですが、
1998: LeNet
Gradient-based Learning Applied to Document Recognition

1998年に導入された。 LeNetは、今後のConvolution Neural Networkを用いた画像分類研究の礎となるものである。 プーリング層、完全連結層、パディング、活性化層など、多くの古典的なCNN技術が、特徴を抽出し分類を行うために使用されている。 平均二乗誤差損失関数と20エポックの学習により、このネットワークはMNISTテストセットで99.05%の精度を達成することができます。 20年経った今でも、多くの最先端の分類ネットワークは、一般にこのパターンを踏襲している
2012: AlexNet
ImageNet Classification with Deep Convolutional Neural Networks

「ImageNet Classification with Deep Convolutional Neural Networks」より
LeNetは大きな成果を上げ、CNNの可能性を示したが、CNNはどのように進化したのだろうか? この分野の開発は、計算機の性能とデータ量の制限により、10年間停滞していました。 CNN は数字認識などの簡単なタスクしか解決できないように見えましたが、顔や物体などのより複雑な特徴については、HarrCascade または SIFT 特徴抽出器と SVM 分類器がより好ましいアプローチでした。
しかし、2012 ImageNet Large Scale Visual Recognition Challenge で、Alex Krizhevsky はこのチャレンジに対して CNN ベースのソリューションを提案し、 ImageNet テストセットのトップ 5 の正確度を 73.8% から 84.7% まで劇的に増加させました。 彼らのアプローチは、LeNetから多層CNNのアイデアを継承しつつ、CNNのサイズを大幅に増加させました。 上図からわかるように、入力はLeNetの32×32から224×224になり、多くのConvolutionカーネルはLeNetの6チャンネルから192チャンネルになっています。デザインはあまり変わっていませんが、パラメータが数百倍になったことで、複雑な特徴を捉えて表現するネットワーク能力も数百倍に向上しています。 このような大規模なモデルを学習させるために、Alexは2つのGTX 580 GPUとそれぞれに3GB RAMを使用し、GPUトレーニングのトレンドを先取りしています。 また、ReLU 非線形性の使用も、計算コストの削減に役立ちました。
ネットワークに多くのパラメータをもたらすことに加えて、ドロップアウト層を使用することにより、より大きなネットワークがもたらすオーバーフィッティングの問題も検討しました。 その局所応答正規化法は、その後あまり人気を得ませんでしたが、勾配の飽和問題に対処するためのバッチノルムなど、他の重要な正規化技術に影響を与えました。 要約すると、AlexNet は、今後 10 年間の事実上の分類ネットワークのフレームワークを定義した。それは、Convolution、ReLu 非線形活性化、MaxPooling、および Dense 層の組合せである。 VGG
Very Deep Convolutional Networks for Large->
2014大規模画像認識
ビジュアル認識にCNNを使って大成功したことにより。 研究者コミュニティ全体が爆発し、このニューラルネットワークがなぜそんなにうまく機能するのかを調べ始めました。 例えば、2013年の「Visualizing and Understanding Convolutional Networks」では、Matthew ZeilerがCNNがどのように特徴を拾い上げ、中間表現を視覚化するのかを論じています。 そして、2014年から突然、CNNがコンピュータビジョンの未来であることを誰もが認識し始めたのです。 そうした直後のフォロワーの中で、最も目を引くのがVisual Geometry GroupのVGGネットワークです。 ImageNetテストセットで93.2%のトップ5精度、76.3%のトップ1精度という驚くべき結果を得ました。
AlexNetの設計に続いて、VGGネットワークには2つの大きなアップデートがあります。 1)VGGは、AlexNetのように広いネットワークを使用するだけでなく、より深いネットワークも使用しました。 VGG-19はAlexNetの5層に対し、19層の畳み込み層を持つ。 2) VGGはまた、少数の小さな3×3畳み込みフィルタが、AlexNetの7×7あるいは11×11のフィルタ1つを置き換え、計算コストを下げながらより良い性能を達成できることを実証しました。 このエレガントな設計により、VGGは、セマンティックセグメンテーションのためのFCNや、オブジェクト検出のためのFaster R-CNNなど、他のコンピュータビジョンタスクにおける多くの先駆的なネットワークのバックボーンネットワークとなった。 この問題に対処するために、VGGでは事前学習と重みの初期化の重要性についても議論している。 この問題は、研究者がより多くの層を追加し続けることを制限し、さもなければ、ネットワークが本当に収束するのが難しくなる。 しかし、2年後にはこれに対するよりよい解決策が見つかるでしょう。
2014: GoogLeNet
Going Deeper with Convolutions
よりVGGには見た目と分かりやすい構造がある。 しかし、その性能はImageNet 2014コンペティションの全ファイナリストの中でベストではありません。 GoogLeNet、別名InceptionV1が最終賞を獲得しました。 VGGと同様、GoogLeNetの主な貢献の1つは、22層構造でネットワークの深さの限界に挑戦したことです。 8049>
VGGとは異なり、GoogLeNetは、より良い事前学習済みスキーマと重みの初期化で回避策を提案するのではなく、計算と勾配減少の問題に正面から取り組もうとしました。

最初に、Inception というモジュールを使用して非対称ネットワーク設計のアイデアを検討しました(上図参照)。 理想的には、機能効率を向上させるために、疎な畳み込みまたは密な層を追求したいところですが、現代のハードウェア設計はこのケースに合わせたものではありませんでした。 そこで彼らは、ネットワークトポロジーレベルでのスパース性が、既存のハードウェア能力を活用しながら、特徴の融合にも役立つと考えました。
次に、「ネットワークにおけるネットワーク」という論文からアイデアを拝借して、高い計算コストの問題を攻撃しています。 基本的には、5×5のコンボリューションカーネルのような重い計算操作を行う前に、1×1のコンボリューションフィルターを導入し、特徴の次元を減らします。 この構造は後に「ボトルネック」と呼ばれ、多くの後続のネットワークで広く使われている。 ネットワーク・イン・ネットワーク」と同様に、さらにコストを削減するために、最後の完全連結層の代わりに平均プーリング層を使用しました。
第三に、勾配がより深い層に流れるように、GoogLeNetはいくつかの中間層の出力や補助出力に監視を使用しました。 このデザインは複雑なため、画像分類ネットワークではあまり一般的ではありませんが、姿勢推定における砂時計ネットワークなど、コンピュータビジョンの他の分野ではより一般的になってきています。 “バッチ正規化”。 Accelerating Deep Network Training by Reducing Internal Covariate Shift “は、InceptionV2の略です。 2015年の “Rethinking the Inception Architecture for Computer Vision “がInceptionV3の略です。 そして、2015年の “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning “は、InceptionV4の略称です。 それぞれの論文では、オリジナルのInceptionネットワークに対してより改良を加え、より良い結果を得ています
2015: Batch Normalization
Batch Normalizationの略。 Accelerating Deep Network Training by Reducing Internal Covariate Shift
インセプション ネットワークは、研究者が ImageNet データセットで超人的な精度に到達するのを助けました。 しかし、統計的な学習方法として、CNNは特定のトレーニングデータセットの統計的性質に非常に制約されます。 したがって、より良い精度を達成するためには、通常、データセット全体の平均と標準偏差を事前に計算し、それを使って最初に入力を正規化し、ネットワーク内のほとんどの層の入力が近いことを確認し、より良い活性化応答性に変換する必要があります。 この近似的なアプローチは非常に面倒で、新しいネットワーク構造や新しいデータセットに対して全く機能しないこともあり、深層学習モデルの学習はまだ難しいと見られています。 この問題を解決するために、GoogLeNetを作ったSergey IoffeとChritian SzegedyがBatch Normalizationというスマートなものを発明することにしました。

バッチ正規化の考え方は難しくありません:十分な時間をかけて訓練さえすれば、一連のミニバッチの統計を使ってデータセット全体の統計値を近似することができるのです。 また、統計量を手動で計算する代わりに、学習可能なパラメータ「scale」と「shift」を導入することで、ネットワークに各層の正規化方法を自ら学習させることができます。
上の図は、バッチ正規化値の計算の過程を示しています。 見ての通り、ミニバッチ全体の平均を取り、分散も計算しています。 次に、このミニバッチの平均と分散で入力を正規化することができます。 最後に、スケールとシフトのパラメータで、ネットワークはバッチ正規化された結果を次の層、通常はReLUに最も適合するように学習する。 1つの注意点は、推論時にミニバッチの情報がないことで、回避策として、学習時に移動平均と分散を計算し、これらの移動平均を推論経路で使用する。 この小さなイノベーションはとてもインパクトがあり、後のすべてのネットワークはすぐにこれを使い始めました。
2015: ResNet
Deep Residual Learning for Image Recognition
2015年は、ここ10年でコンピューター ビジョンにとって最高の年かもしれません。画像分類だけでなく、オブジェクト検出、セマンティック セグメンテーションなど、あらゆる種類のコンピューター ビジョン タスクで、非常に多くの素晴らしいアイデアが飛び出しているのを目にしました。 2015年の最大の進歩は、マイクロソフトリサーチアジアの中国の研究者グループが提案したResNet(残差ネットワーク)と呼ばれる新しいネットワークに属します。

VGG networkについて先に述べたように、さらに深くするための最大のハードルはグラジェントバニッシュ問題、すなわち、勾配のないネットワークである。すなわち、より深い層をバックプロパゲートすると、導関数がどんどん小さくなり、最終的には現代のコンピューター アーキテクチャでは本当に意味のある表現ができないポイントに到達してしまうのです。 GoogLeNetでは、補助監視と非対称受信モジュールを使ってこの問題を解決しようとしましたが、ほんの少ししか軽減されませんでした。 もし、50層、100層と使っていきたいのであれば、勾配がネットワーク内を流れるような良い方法はないのだろうか? ResNetの答えは、残差モジュールを使用することです。

ResNet は出力に ID ショートカットを追加し、各残留モジュールが少なくともどんな入力であるかを迷わずに予測できるようにしたのである。 さらに重要なことは、各層が目的の特徴マッピングに直接適合することを望むのではなく、残差モジュールが出力と入力の違いを学習しようとすることで、必要な情報利得が少なくなり、タスクがより簡単になりました。 数学を学習しているとき、新しい問題を解くたびに、似たような問題の解が与えられるので、この解を拡張してうまくいくようにすればよいのだと想像してください。 これは、問題にぶつかるたびにまったく新しい解法を考えるよりずっと簡単です。 あるいは、ニュートンが言ったように、巨人の肩の上に立つことができ、ID入力はResidualモジュールにとってその巨人です。
IDマッピングに加えて、ResNetはInceptionネットワークからボトルネックとBatch Normalizationも借用しています。 最終的に、152の畳み込み層を持つネットワークを構築することに成功し、ImageNetで80.72%のトップ1精度を達成した。 この残差アプローチは、後にXceptionやDarknetなど、他の多くのネットワークでもデフォルトのオプションとなります。 また、そのシンプルで美しいデザインのおかげで、現在でも多くの生産用視覚認識システムで広く使われています。
Residual Networkの宣伝にしたがって、さらに多くの不変量が出てきました。 ResNetの原作者は、”Identity Mappings in Deep Residual Networks “で、residualモジュールの前にactivationを置くことを試み、より良い結果を得ており、この設計は後にResNetV2と呼ばれている。 また、2016年の論文 “Aggregated Residual Transformations for Deep Neural Networks “では、異なる変換の出力を集約するために残差モジュールの並列分岐を追加したResNeXtを提案しています
2016: Xception
Xception: Deep Learning with Depthwise Separable Convolutions
ResNet のリリースにより、画像分類器における低ぶら下がりフルーツのほとんどはすでに掴まれたように見えました。 研究者たちは、CNNの魔法のような内部メカニズムは何なのかを考えるようになりました。 クロスチャネル畳み込みは通常、大量のパラメータを導入するため、Xceptionネットワークは、その効果の全体像を理解するために、この操作を調査することを選択しました。 Inceptionモジュールでは、異なる変換の複数のブランチを集約して、トポロジーのスパース性を実現する。 しかし、なぜこのスパース性が効いたのでしょうか。 Xceptionの作者は、Kerasフレームワークの作者でもあり、このアイデアを、最終的な連結の前に1つの3×3コンボリューションファイルが1つの出力チャンネルに対応するという極端なケースに拡張したのです。 この場合、これらの並列コンボリューションカーネルは、実際には、深さ方向のコンボリューションと呼ばれる新しい操作を形成します。

上の図で示すように、「深度方向の畳み込み」と「深度方向の分離可能な畳み込み」は同じです。 従来のコンボリューションでは、すべてのチャンネルを含めて1回の計算を行っていましたが、デプスワイズコンボリューションでは、各チャンネルのコンボリューションだけを個別に計算し、その出力を連結しています。 これにより、チャンネル間の特徴量の交換が削減されるだけでなく、多くのコネクションが削減されるため、より少ないパラメータでレイヤーを構成することができます。 しかし,この操作では,入力と同じ数のチャンネルが出力されます(2つ以上のチャンネルをグループ化した場合は,より少ない数のチャンネルが出力されます). したがって、いったんチャネル出力がマージされると、通常の畳み込みと同様に、チャネル数を増減させるために、別の通常の 1×1 フィルタ、またはポイントワイズ畳み込みが必要になります。 これは、「Learning visual representations at scale」という論文に記載されており、InceptionV2でも時折使用されています。 Xceptionはさらに一歩進んで、ほとんどすべての畳み込みをこの新しいタイプに置き換えたのです。 そして、実験結果はかなり良いものになりました。 ResNetやInceptionV3を凌駕し、画像分類の新しいSOTA手法となったのです。 これはまた、CNNにおけるチャネル間相関と空間相関のマッピングが完全に切り離せることを証明した。 また、ResNetと共通する長所として、Xceptionはシンプルで美しいデザインを持っているため、そのアイデアはMobileNetやDeepLabV3など、他の後続研究にも多く用いられている
2017.3: MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
Xception は ImageNet で 79% top-1 accuracy と 94.5% top-5 accuracy を達成しましたが、これは以前の SOTA InceptionV3 と比較してそれぞれ 0.8% と 0.4% しか向上していません。 新しい画像分類ネットワークの限界利得が小さくなってきているため、研究者は他の分野に焦点を移し始めているのです。 そして、MobileNetは、リソースに制約のある環境での画像分類を大きく推し進めたのです。

“MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application”
Xceptionと同じようにMobileNetでも上記の深さで分離できる畳込みモジュールで、高効率と少ないパラメーターに重点が置かれていたようです。
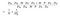
上の式の分子は、深さ方向の分離可能なコンボリューションが必要とするパラメータの合計数である。 そして、分母は同様の通常の畳み込みのパラメータの総数である。 ここで、Dはコンボリューションカーネルのサイズ、Dは特徴マップのサイズ、Mは入力チャンネル数、Nは出力チャンネル数である。 チャンネルと空間特徴の計算を分離したため、乗算を加算に変えることができ、一桁小さくなる。 さらに良いことに、この比率からわかるように、出力チャンネル数が大きければ大きいほど、この新しいコンボリューションを使うことで計算を節約できます。
MobileNet のもうひとつの貢献は、幅と解像度の乗算器です。 MobileNet チームは、モバイル デバイス用にモデル サイズを縮小する標準的な方法を見つけたいと考えており、最も直感的な方法は、入力および出力チャネル数と入力画像解像度を減らすことです。 この動作を制御するために、比率alphaはチャンネルに、比率rhoは入力解像度(これは特徴マップサイズにも影響します)に乗算されます。 つまり、パラメータの総数は以下の式で表すことができる:

この変更は、革新という点では単純に見えますが、研究者が初めて、異なるリソース制約に対してネットワークを調整するための標準的なアプローチを結論付けたので、大きな工学的価値を持っています。 また、それは一種のニューラルネットワークを改善する究極の解決策を要約したものです:広くて高解像度の入力はより良い精度につながり、薄くて低解像度の入力はより悪い精度につながります」
その後、2018年と2019年に、MobiletNetチームは「MobileNetV2」もリリースしています。 反転残差と線形ボトルネック」、「MobileNetV3の探索」を発表しました。 MobileNetV2では、逆残留ボトルネック構造を採用しています。 そして、MobileNetV3では、次に取り上げるNeural Architecture Search技術を使って、最適なアーキテクチャの組み合わせを探索するようになりました
2017: NASNet
Learning Transferable Architectures for Scalable Image Recognition
リソース制約環境での画像分類と同様に、ニューラルアーキテクチャ探索も2017年頃に登場した分野である。 ResNet、Inception、Xceptionと、人間が理解し設計できる最適なネットワークトポロジーに到達したように思えますが、人間の想像力をはるかに超える、より優れた、より複雑な組み合わせがあるとしたらどうでしょうか。 2016年に発表された「強化学習を用いた神経アーキテクチャ探索」という論文では、強化学習を用いることで、あらかじめ定義された探索空間内で最適な組み合わせを探索するアイディアが提案されています。 ご存知の通り、強化学習は探索エージェントに対して明確なゴールと報酬を与え、最適な解を見つけ出す手法である。 しかし、計算能力の制限から、この論文では小さなCIFARデータセットでの適用についてしか述べていない。

ImageNetのような大規模データセットに最適な構造を見つけるという目的で、NASNetはImageNetに合わせた探索空間を作りました。 CIFARで検索された結果がImageNetでもうまくいくように、特別な検索空間を設計したいと考えているのである。 まず、NASNetでは、ResNetやXceptionのような優れたネットワークに共通する手作りモジュールが、やはり検索時に有効であると想定しています。 そこで、NASNetは、ランダムな接続や操作を検索するのではなく、ImageNet上で既に有用性が証明されているこれらのモジュールの組み合わせを検索する。 次に、実際の検索はやはり32×32の解像度のCIFARデータセットで行うので、NASNetは入力サイズに影響されないモジュールのみを検索します。 2点目を実現するために、NASNetは2種類のモジュールテンプレートをあらかじめ定義しています。 ReductionとNormalです。 Reductionセルでは、入力に比べてフィーチャーマップが縮小され、Normalセルでは、同じように縮小される可能性がある。

より NASNet は手動設計ネットワークより良い指標を持っているものの、いくつかの欠点も抱えています。 最適な構造を探索するためのコストが非常に高く、Google や Facebook のような大企業しか手が出せないのです。 また、最終的な構造は人間にとってあまり意味がなく、それゆえ本番環境での維持や改善が難しくなります。 その後、2018年に「MnasNet: Platform-Aware Neural Architecture Search for Mobile」は、このNASNetのアイデアをさらに拡張し、検索ステップをあらかじめ定義された連鎖ブロック構造で限定しています。 また、重み係数を定義することで、mNASNetは、単にFLOPsに基づいて評価するのではなく、特定のリソース制約を与えられたモデルを検索する、より体系的な方法を与えた<8049><6025>2019:EfficientNet<1454><9527><8910>EfficientNet.NASNet.NASNet.NASNet.NASNet.NASNet.NASNet.NASNet.NASNet: Rethinking Model Scaling for Convolutional Neural Networks
2019年は、CNNによる教師あり画像分類のエキサイティングなアイデアはもうないように見えますね。 ネットワーク構造の大幅な変更は、通常、わずかな精度向上しかもたらしません。 さらに悪いことに、同じネットワークを異なるデータセットやタスクに適用すると、以前主張したトリックが機能しないようで、それらの改善は ImageNet データセットでのオーバーフィッティングに過ぎないのではないかという批評につながりました。 一方、私たちの期待を裏切らないトリックがあります。それは、より高い解像度の入力の使用、コンボリューション層のチャンネル数の増加、レイヤー数の増加です。 非常に残酷な力技ですが、オンデマンドでネットワークを拡張する原理的な方法があるように思います。 MobileNetV1 は 2017 年にこれを一種の提案しましたが、フォーカスは後でより良いネットワーク設計に移行しました。”EfficientNet” から

NASNet と mNASNet の後、研究者は、コンピューターからの助けがあったとしても、アーキテクチャの変更はそれほど大きな利益をもたらさないことに気づきました。 そこで、彼らはネットワークをスケーリングすることに回帰し始めたのです。 EfficientNetは、まさにこの前提の上に構築されています。 一方では、mNASNetから最適なビルディングブロックを使用し、最初に良い基盤を作ることを確認します。 一方、ネットワークの深さ、幅、解像度を制御するために、3つのパラメータalpha、beta、rhoを定義しています。 こうすることで、最適な構造を探すための大規模なGPUプールがなくても、エンジニアはこれらの原則的なパラメータを頼りに、さまざまな要件に基づいてネットワークを調整することができるのです。 最終的に EfficientNet は、幅、深さ、解像度の比率が異なる 8 種類のバリアントを提供し、小型モデルでも大型モデルでも良好な性能を得ることができました。 つまり、高い精度を求めるなら600×600、66Mのパラメータを持つEfficientNet-B7を。 低レイテンシーで小型のモデルを希望する場合は、224×224、パラメータ5.3MのEfficientNet-B0をお勧めします。 8049>
以上の10論文を読み終えると、CNNによる画像分類の歴史がかなり把握できるはずです。 この分野の勉強を続けたい方は、他にも興味深い論文をリストアップしていますので、ぜひ読んでみてください。 トップ10には入っていませんが、これらの論文はいずれもそれぞれの分野で有名で、世界の多くの研究者に影響を与えたものです。 SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPPNetは従来のコンピュータビジョン特徴抽出から特徴ピラミッドのアイデアを借用している。 このピラミッドは、異なるスケールを持つ特徴の単語のバッグを形成するため、異なる入力サイズに適応でき、固定サイズの完全接続層を取り除くことができる。 このアイデアは、DeepLabのASPPモジュールや、物体検出のためのFPNにもインスピレーションを与えている。 DenseNet
Densely Connected Convolutional Networks
コーネルからのDenseNetは、ResNetからのアイデアをさらに拡張しています。 これは、層間のスキップ接続を提供するだけでなく、すべての前の層からのスキップ接続も持っています。 SENet
Squeeze-and-Excitation Networks
Xceptionネットワークは、チャネル間相関は空間相関とあまり関係がないことを実証しました。 しかし、前回のImageNetコンペティションのチャンピオンであるSENetは、Squeeze-and-Excitationブロックを考案し、異なるストーリーを語っています。 SEブロックは、まずグローバルプーリングで全チャンネルをより少ないチャンネルに絞り、完全連結変換を適用し、次に別の完全連結層を使って元のチャンネル数に「励起」して戻します。 つまり、本質的にFC層は、ネットワークが入力特徴マップに対する注意を学習するのを助けたのである。
2017: ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
MobileNetV2の逆ボトルネックモジュール上に構築されたShuffleNetは、深さ方向に分離可能なコンボリューションにおけるポイントワイズコンボリューションが、少ない計算量と引き換えに精度を犠牲にすると信じています。 これを補うために、ShuffleNetは、ポイントワイズコンボリューションが常に同じ「点」に適用されないようにするために、チャンネルシャッフル操作を追加しています。 そして、ShuffleNetV2では、このチャンネルシャッフリング機構がさらにResNetのIDマッピングブランチにも拡張され、ID機能の一部もシャッフルに使われるようになりました。
2018: Bag of Tricks
Bag of Tricks for Image Classification with Convolutional Neural Networks
Bag of Tricksでは、画像分類分野でよく使われるトリックに焦点を当てました。 これは、エンジニアがベンチマークのパフォーマンスを向上させる必要があるときに、良いリファレンスとして機能します。 興味深いことに、mixup augmentation や cosine learning rate などのこれらのトリックは、新しいネットワーク アーキテクチャよりもはるかに優れた改善を達成できることがあります。
Conclusion
EfficientNetのリリースにより、ImageNet分類ベンチマークは終焉を迎えることになりそうです。 既存の深層学習アプローチでは、別のパラダイムシフトが起きない限り、ImageNetで99.999%の精度に到達できる日は来ないでしょう。 そのため、研究者は大規模な視覚認識のための自己教師付き学習や半教師付き学習など、いくつかの新しい分野を積極的に検討しています。 一方、既存の手法では、この非完璧な技術の実世界への応用が、技術者や起業家にとってより重要な課題となっている。 将来的には、画像分類を利用したコンピュータビジョンの実世界での応用を分析するための調査も行う予定ですので、ご期待ください。 他にも画像分類のために読むべき重要な論文があるとお考えの方は、ぜひ下のコメント欄からお知らせください!
2020年7月31日付http://yanjia.li掲載
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based Learning Applied to Document Recognition
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
- Christian Ssegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
- Sergey Ioffe, Christian Szegedy, Batch Normalization, (※英語)。 3582>
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition
- François Chollet, Xception.The Deep Network Training: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- François Chollet, Xception: Deep Learning with Depthwise Separable Convolutions
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
- Mingxing Tan, Quoc V. Le, EfficientNet:
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q., K. Huang, Zhuang Liu, Laurens van der Maaten, K. Huang, K. Huang, K. Huang, K. Huang, K. Huang, K. Huang, K. Huang, K. Huang, K. N. Huang, K. N. Hu N. Weinberger, Densely Connected Convolutional Networks
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet.Net:
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Bag of Tricks for Image Classification with Convolutional Neural Networks