
Resource Allocation は、任意のスパーク ジョブの実行中に重要な側面です。 このブログでは、Spark アプリケーションの基本的なフローを理解し、Spark ジョブの実行者数、各実行者のメモリ設定、コア数を設定する方法について説明します。 上記3つの最適な数値を決定するためには、いくつかの要素を考慮する必要があります。
- データ量
- ジョブが完了するまでの時間
- リソースの静的または動的割り当て
- 上流または下流のアプリケーション
はじめに
Spark アプリケーションの処理で使用する基本用語の定義からはじめましょう。
Partitions : パーティションは、大きな分散データ セットの小さなチャンクです。 Spark はパーティションを使用してデータを管理し、エグゼキューター間でのデータのシャッフルを最小限に抑えてデータ処理を並列化するのに役立ちます。
タスク:タスクは、分散データセットのパーティションで実行できる作業単位で、1 つのエグゼキューターで実行されます。 並列実行の単位はタスクレベルであり、1つのステージ内のすべてのタスクが並列実行されます
Executor : エグゼキュータとは、ワーカーノード上のアプリケーションに対して起動される単一のJVMプロセスです。 エグゼキュータはタスクを実行し、その間にメモリやディスクストレージにデータを保持する。 各アプリケーションはそれぞれ独自のエグゼキュータを持っています。 1つのノードで複数のエグゼキュータを実行することもできますし、1つのアプリケーションのエグゼキュータを複数のワーカーノードにまたがって実行することもできます。 エグゼキュータは、Sparkアプリケーションの
期間中は稼働し続け、複数のスレッドでタスクを実行します。 スパーク アプリケーションのエグゼキューターの数は、SparkConf 内で指定するか、コマンドラインから -num-executors フラグで指定できます。
Cluster Manager : クラスター上のリソースを取得するための外部サービス (例 : スタンドアロンのマネージャー、Mesos、YARN など) です。 Spark は、実行プロセスを取得し、それらが互いに通信できる限り、クラスタマネージャに不可知論です。
yarn-client mode – ドライバはクライアントプロセスで実行され、アプリケーションマスターはYARNからのリソースのリクエストにのみ使用されます。
yarn-cluster mode – ドライバはアプリケーションマスターのプロセス内で実行し、アプリケーションは初期化するとクライアントから解放されます
Cores : コアは CPU の基本的な計算単位であり、CPU は任意の時点でタスクを実行するために 1 つまたは複数のコアを持つことができます。 コアが多ければ多いほど、より多くの作業を行うことができる。 スパークでは、これは実行者が実行できる並列タスクの数を制御します。
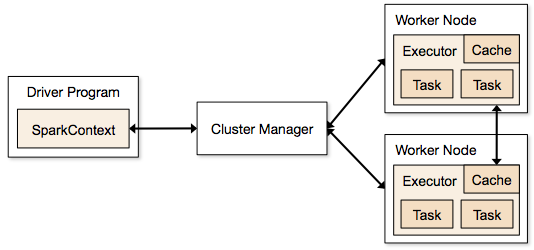
スパーク ジョブのクラスターモードに関わるステップ
- ドライバー コードから SparkContext がクラスターマネージャー (standalone/Mesos/YARN) へ接続されます。 エグゼキューター プロセスが実行されていて、互いに通信している限り、どのようなクラスターマネージャーでも使用できます。
- Spark は、クラスターのノードでエグゼキューターを取得します。
- Application code (jar/python files/python egg files) is sent to executors
- Tasks are sent by SparkContext to the executors.
From above steps, it is clear that the number of executors and their memory setting play a major role in a spark job.上記のステップから、エグゼキュータの数およびメモリ設定は、スパークのジョブで大きな役割を果たします。 メモリが多すぎるエグゼキューターを実行すると、ガベージ コレクションの遅延が大きくなることがよくあります。
ここで、Spark ジョブを最適化するために最適な値のセットを構成する方法を理解しようとします。 それらは次のとおりです。
- Static Allocation – 値は spark-submit
- Dynamic Allocation – 値は要件(データのサイズ、必要な計算の量)に基づいてピックアップされ、使用後に解放される。 4334>
Static Allocation
さまざまなケースで、ユーザー/データ要件に応じてさまざまなパラメータを変え、さまざまな組み合わせになるよう議論されています。
ケース 1 ハードウェア – 6 ノードで、各ノードは 16 コア、64 GB RAM
最初に、各ノードで 1 コアと 1 GB が OS と Hadoop デーモンに必要なので、各ノードには 15 コア、63 GB RAM
コア数の選択方法から開始しました。
コア数=実行者が実行できる同時タスク
ですから、各実行者の同時タスクが多ければ多いほど性能が良くなると思うかもしれません。 しかし、研究によると、5つ以上の同時実行タスクがあるアプリケーションは、悪いショーにつながることが分かっています。 そのため、最適な値は 5 です。
この数は、システムのコア数ではなく、並列タスクを実行するエグゼキュータの能力からきています。 つまり、CPUのコアが2倍(32個)あっても5という数字は変わりません。
次のステップですが、1つのノード(CPU)で利用できるコアの合計が15で、1ノードあたり3つのエグゼキュータとなり、15/5になります。 各ノードの実行者数を計算し、ジョブの総数を求めます。
つまり、6ノードで、ノードあたり3実行者、合計18実行者になります。 18個のうち、YARNのアプリケーションマスターに必要なエグゼキュータ(Javaプロセス)は1個です。 この17は、spark-submitシェルコマンドで実行中に-num-executorsでsparkに与えた数字です。 各ノードで利用可能なRAMは63GB
したがって、各ノードの各エグゼキュータのメモリは63/3 = 21GBです。
ただし、各エグゼキュータのYARNへのフルメモリ要求を決定するには、小さなオーバーヘッド・メモリも必要です。
そのオーバーヘッドの式は max(384, .07 * spark.executor.memory)
そのオーバーヘッドを計算すると: .07 * 21(ここで 21 は上記の 63/3 として計算) = 1.47
1.47 GB > 384 MB なのでオーバーヘッドは 1.47となります。47
上記の各21から上記の値を取る => 21 – 1.47 ~ 19 GB
つまり実行メモリ – 19 GB
最終数 – 実行器 – 17、コア 5、実行メモリ – 19 GB
ケース 2 ハードウェア – 6ノード、各ノードは32コア、64 GB
コア数 5は上記説明と同様に良い同時実行を行うために同じです。
各ノードの実行数 = 32/5 ~ 6
つまり総実行数 = 6 * 6 Node = 36. すると最終的には36 – 1(for AM) = 35
Executor memory:
各ノードに6つのエグゼキュータがあります。 63/6 ~ 10. オーバーヘッドは、0.07 * 10 = 700 MBです。 したがって、オーバーヘッドとして 1GB に丸めると、10-1 = 9 GB
最終的な数値 – エグゼキュータ – 35、コア 5、エグゼキュータ メモリ – 9 GB
ケース 3 – メモリを増やさない場合
上記のシナリオは、コア数を固定として受け入れることから始めて、エグゼキュータの数およびメモリの数に移行しています。
さて、最初のケースですが、データサイズと計算内容から 19GB は必要なく、10GB で十分だと考えた場合、次のようになります:
Cores: 5
Number of executors for each node = 3.Still 15/5 as calculated above.
At this stage would lead to 21 GB, and then as our first calculation as 19.This stage, this would lead to 21 GB, and then as 19. しかし、10個でOK(オーバーヘッドが少ないと仮定)とした以上、1ノードあたりの実行器数を6個(63/10のように)に変更することはできません。 なぜなら、16コアしかないのに、6コアにすると30コアになってしまうからです。
そこでもう一度計算すると、
マジックナンバー5は3(5以下の任意の数)になります。 つまり、3 コアで、利用可能なコアが 15 個の場合、1 ノードあたり 5 個の実行プログラムがあり、実行プログラムは 29 個 (5*6 -1) で、メモリは 63/5 ~ 12.
オーバーヘッドは 12*.07=.84 です。 つまり、実行メモリは 12 – 1 GB = 11 GB
Final Numbers are 29 executors, 3 cores, executor memory is 11 GB
Summary Table
Dynamic Allocation
注意:動的割り当てが有効な場合の実行数の上限値は無限大です。 つまり、スパークアプリケーションは必要であればすべてのリソースを食い尽くすことができる、ということです。 他のアプリケーションが動作しており、それらのアプリケーションもタスクを実行するためにコアを必要とするクラスタでは、クラスタレベルでコアを割り当てることを確認する必要があります。
これは、ユーザー アクセスに基づいて、YARN ベースのアプリケーションに特定の数のコアを割り当てることができることを意味します。 つまり、spark_user を作成し、そのユーザーに対してコア数 (最小/最大) を割り当てることができるのです。
動的割り当てを理解するには、次のプロパティの知識が必要です。
spark.dynamicAllocation.enabled – これを true に設定すると、実行者を言及する必要がありません。 その理由は以下のとおりです。
私たちが spark-submit で与える静的なパラメーター数は、ジョブ期間全体に対するものです。
最初に使用するエグゼキュータ数:
最初に使用するエグゼキュータ数 (spark.dynamicAllocation.initialExecutors):
エグゼキュータ数を動的に制御する:
次に、ロード(保留タスク)に基づいて要求すべきエグゼキュータ数…
最初に使用するエグゼキュータ数は何個か? これは最終的には spark-submit で静的な方法で指定した数になります。
When do we request new executors (spark.dynamicAllocation.schedulerBacklogTimeout) – これは、保留中のタスクがこの時間だけ存在することを意味します。 そのため、各ラウンドで要求されるエグゼキュータの数は、前のラウンドから指数関数的に増加します。 例えば、アプリケーションは最初のラウンドで1つのエクゼキュータを追加し、その後のラウンドで2、4、8…とエクゼキュータを追加していくことになります。
When do we give away an executor is set using spark.dynamicAllocation.executorIdleTimeout.
結論として、ジョブ実行時間をより制御したい場合、予期しないデータ量のためにジョブを監視するには、静的数値は助けになるでしょう。 ダイナミックに移行することで、リソースはバックグラウンドで使用され、予期しないボリュームを含むジョブは、他のアプリケーションに影響を与える可能性があります。