最初に理解しなければならないのは、変数の性質と、研究質問に答えるための研究デザインにおいて変数がどのように使用されるかということである。 この章では、次のことを学びます:
- 定量研究における変数のさまざまなタイプ、
- 分析単位に関する問題
定量変数の理解
変数の語源は、「変化」という言葉に関連しており、変数とは何かを理解する助けになるはずです。 たとえば、外気温、1 ガロンあたりのガソリン代、人の体重、親戚の雰囲気などはすべて変数です。 言い換えれば、それらは異なる条件または異なる人々に対して異なる値を持つことができます。
私たちは、関心のある特徴や要因を記述するために変数を使用します。 例えば、異なる世帯の構成員数、異なる地域の健康的な食料源までの距離、BSWまたはMSWプログラムの学生に対するソーシャルワーク教員の比率、異なる人種/民族グループの人の投獄の割合、ソーシャルワークプログラムからサービスを受けるための交通費、異なる郡における乳児死亡率などである。 ソーシャルワーク介入研究では、変数に介入の特徴(強度、頻度、期間)および介入に関連する結果を含めることができる。 ソーシャルワーカーは、人口統計学的変数と呼ばれるものに関心を持つことが多い。 人口統計学的変数は、集団、グループ、または集団のサンプルの特性を記述するために使用される。 頻繁に適用される人口統計学的変数の例は、
- 年齢、
- 民族、
- 国籍、
- 宗教的所属、
- ジェンダー、
- 性的指向などです。
- 配偶者/交際ステータス、
- 雇用ステータス、
- 政治的所属、
- 地理的位置、
- 教育レベル、
- 所得。
よりマクロなレベルでは、コミュニティや組織の人口統計学にはその規模が含まれることが多く、組織はしばしば全体的な予算で測定されることがあります。 研究者が研究変数について考える方法は、研究デザインにとって重要な意味を持つ。 研究者は、独立変数として機能させるか、従属変数として機能させるかを決定する。 この区別は、変数に固有のものではなく、研究者がそれぞれの変数をどのように定義するかを選択することに基づいています。 独立変数とは、操作された「入力」変数と考えられるもので、従属変数とは、その入力変動の影響または「出力」が観察されるものです。
「入力」(独立)変数の意図的な操作は、常に関与するわけではありません。 スウェーデンで行われた、児童虐待の被害者になったこととその後の高校欠席率との関係を調べた研究の例を考えてみましょう:児童虐待の被害者になるかどうかを意図的に操作した人はいませんでした(Hagborg, Berglund, & Fahlke, 2017)。 研究者たちは,入力変数(児童虐待歴)における自然発生的な差異が,特定の結果変数(学校欠席率)における系統的な変動と関連すると仮定した。 この場合、独立変数は児童虐待の被害者であった履歴であり、従属変数は学校欠席率の結果であった。 言い換えれば、独立変数は、従属変数の変動または変化を引き起こすと調査者によって仮定されます。 これは、「x」が独立変数、「y」が従属変数である図で、どのように見えるかです(注:以前、第3章で原因と結果の論理について議論したときに、この指定を見ました):

別の例として、児童虐待の被害者であることは、思春期の物質使用の高いリスクと関連するという研究を考えます(Yoon、Kobulsky、Yoon、& Kim、2017)。 このモデルにおける独立変数は、児童虐待の履歴を持つことであろう。 従属変数は、思春期における物質使用のリスクであろう。 この例は,独立変数(児童虐待)が従属変数(青年期の物質使用)に影響を及ぼす可能性のある経路を特定しているため,さらに精巧なものとなっている。 この研究の著者は、心的外傷後ストレス(PTS)が幼少期の虐待(身体的および性的)と思春期の物質使用の間のリンクであることを実証しました。

次の活動を完了する時間を取ってください。 定量的な調査研究で使われる変数のさまざまな特徴について考えてみましょう。 ここでは、量的変数がカテゴリー、序数、またはインターバルであることを探ります。 これらの特徴は、測定とデータ解析の両方に影響します。
カテゴリー変数。 いくつかの変数は変化する値を取ることができるが、意味のある数値的な方法ではない。 その代わり、それらは可能なカテゴリの観点から定義されるかもしれない。 論理的には、これらをカテゴリカル変数と呼びます。 統計ソフトや教科書では、カテゴリを持つ変数をノミナル変数と呼ぶことがある。 名目とは、「名前」を意味するラテン語の語源「nom」から考えることができ、数字と混同してはいけない。 名目は、変数を記述する際のカテゴリカルと同じ意味である。 言い換えると,カテゴリカルまたはノミナル変数は,表現されたカテゴリの名前またはラベルによって識別される. 例えば、最後に乗った車の色はカテゴリ変数になります。青、黒、銀、白、赤、緑、黄色、その他は、私たちが車の色と呼ぶ変数のカテゴリです。
カテゴリ変数で重要なことは、これらのカテゴリには関連する数字の順序や配列がないことです。 異なる車の色の間に数値的な違いはありませんし、青い車に乗ったかどうかを答える際のカテゴリとして「はい」または「いいえ」の違いもありません。 また、性別、人が居住する州または地理的地域、または人の住居が所有されているか賃借されているかなどの変数のカテゴリに関連する順序はありません。
研究者がこのような変数のカテゴリに関連する記号として数字を使うことを決めた場合、数字は任意です。 例えば、性別という変数は以下のようにコード化することができ、コードが一貫して適用されている限り、違いはないでしょう。
| コーディング オプション A | 変数カテゴリ | コーディング オプション B |
|---|---|---|
| 1 | male | 2 |
| 2 | female1 | |
| 3 | 男性・女性単独以外 | 4 |
| 4 | 答えたくない | 3 |
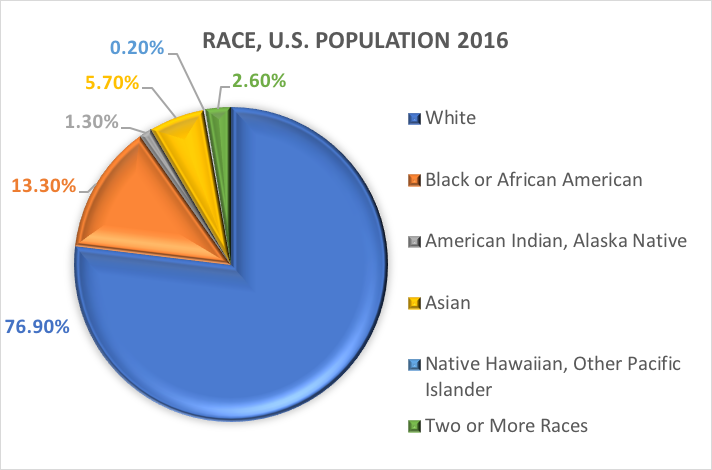
人種と民族。ソーシャルワークや社会科学の研究において、最もよく探求されるカテゴリー変数のひとつが、人の人種的・民族的背景を指す人口統計学である。 多くの研究では、過去の米国国勢調査局の報告書で指定されたカテゴリーを利用しています。 以下は、人種と民族という 2 つの異なる人口統計学的変数について、米国国勢調査局が発表した内容です (https://www.census.gov/mso/www/training/pdf/race-ethnicity-onepager.pdf):
人種とは何でしょうか? 国勢調査局は、人種を、1つまたは複数の社会集団に属する人の自認と定義している。 個人は、白人、黒人またはアフリカ系アメリカ人、アジア人、アメリカンインディアンおよびアラスカ先住民、ネイティブハワイアンおよびその他の太平洋諸島民、またはその他の人種であると報告することができます。 調査回答者は複数の人種を報告することができます。
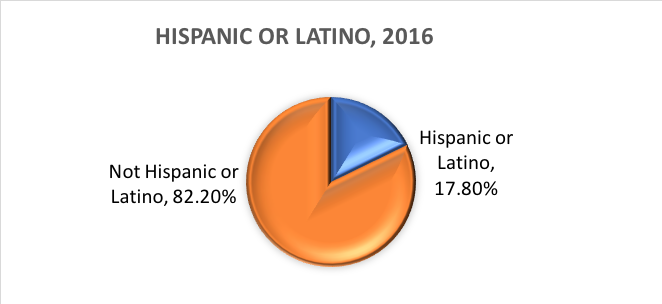
民族性とは何ですか? エスニシティは、その人がヒスパニック系であるか否かを決定します。 このため、民族性は「ヒスパニックまたはラテン系」と「ヒスパニックまたはラテン系でない」の2つのカテゴリーに分けられています。 つまり、国勢調査局はエスニシティという変数に2つのカテゴリー(Hispanic or LatinoとNot Hispanic or Latino)、人種という変数に7つのカテゴリーを定義しています。 これらの変数とカテゴリは社会科学やソーシャルワークの研究によく適用されるが、批判がないわけではない。
これらのカテゴリに基づいて、2016年の米国の人口を推定すると以下のようになる。
2値変数(Dichotomous variables)。特定の統計解析に意味を持つカテゴリ変数という特別なカテゴリが存在する。 2つの選択肢からなり、それ以上でも以下でもないカテゴリカル変数を2分法変数と呼びます。 1つの例は、米国国勢調査局のHispanic/LatinoとNon-Hispanic/Non-Latino ethnicityの2分法である。 別の例として、研究者は、治療を完了した人と治療を完了する前に脱落した人を比較したいと思うかもしれない。 完了または未完了の2つのカテゴリーで、この治療完了変数は、カテゴリーであるだけでなく、二項対立である。
性別を男性か女性のどちらかとして扱う過去の伝統は、二項変数のもう1つの例である。 しかし、もはやこの二項対立的な方法でジェンダーを扱わないための非常に強い論拠が存在する。より多様なジェンダー・アイデンティティが、男/女や男/女という二項対立的(バイナリとも呼ばれる)カテゴリーと一致しない人々のソーシャルワークに明らかに関連しているのである。 これには、アジェンダー、アンドロジナス、ビジェンダー、シスジェンダー、ジェンダー・エクスパンダブル、ジェンダー・フルイド、ジェンダー・クエスチョニング、クィア、トランスジェンダー、その他のカテゴリーがある。 これらのカテゴリー変数とは異なり、変数のカテゴリーに論理的な数値の順序や順番がある場合がある。 順序とは、定義上、系列における位置を意味する。 数値的に関連するカテゴリを持つ変数を順序変数と呼びます。 たとえば、教育達成度と呼ばれる変数には、最低から最高までのカテゴリの順序が暗示的に存在します。 U.S. この順序変数の米国国勢調査データのカテゴリは以下の通りである。
- none
- 1th-4thgrade
- 5th-6thgrade
- 7th-8thgrade
- 9thgrade
- 10thgrade
- 11thgrade
- high school graduate
- 準学位 occupational
- associate’s degree academic
- bachelor’s degree
- master’s degree
- professional degree
- doctoral degree
この変数について2016 Census Bureau estimate dataを見ていると、学士号取得のカテゴリーで女性が男性を上回わることが分かる。 47,718,000人のうち、22,485,000人が男性、25,234,000人が女性である。 この性別パターンは修士号取得者でも維持されているが、博士号取得者では逆転し、女性よりも男性の方がこの最高学府の学位取得者が多い。 また、低学年では女性が男性を上回っていることも興味深い。441,000人の女性が無学と答えたのに対し、男性は374,000人だった。
ここでソーシャルワーク研究における順序変数の使用についてもう一つ例を挙げる。個人がアルコール誤用の問題で治療を求めたとき、ソーシャルワーカーは、これが彼らの飲料行動を変えるための最初の、2番目の、または何番目かの真剣な試みか知りたいかもしれない。 アルコール使用障害の治療アプローチを比較する研究に登録した参加者は、介入研究が1回目から11回目までの重大な変化の試みであったと報告している(Bgun, Berger, Salm-Ward, 2011)。 この変化の試みという変数は、関係者全員にとって最初の試みではなかった介入を評価するデータを、ソーシャルワーカーがどのように解釈するかに影響を与える。 異なるが一般的に使用される序数変数である評価尺度を考えてみよう。 社会、行動、ソーシャルワークの研究者は、しばしば研究参加者に自分の知識、態度、信念、意見、スキル、または行動を記述するために評価尺度を適用するように求めます。 このような尺度のカテゴリーは、順番に並んでいるので(最も多いものから少ないもの、少ないものから多いもの)、我々はこれを順序変数と呼んでいます。
例としては、参加者に評価してもらうことが挙げられます。
- 特定のステートメントにどの程度同意または同意しないか(まったく~非常に)、
- 特定の行動をどの程度頻繁に行うか(決して~常に)、
- 特定の行動をどの程度頻繁に行うか(時間ごと、毎日、毎週、毎月、毎年、またはそれほど頻繁ではない)。
- 誰かのパフォーマンスの質(悪い~優れている);
- 自分の治療にどの程度満足しているか(非常に不満~非常に満足)
- 自信のレベル(非常に低い~非常に高い)。
間隔変数. さらに他の変数は、意味のある数値的な方法で変化する値を取ります。 人口統計学的変数のリストから、年齢が一般的な例です。 個々の人に割り当てられた数値は、その人が生まれてからの年数を示します(幼児の場合、数値は生まれてからの日数、週数、月数を示すことがあります)。 ここでは、変数の取りうる値は順序変数と同様であるが、取りうる値間の間隔の性質に大きな違いがある。 区間変数では、隣接する可能な値間の「距離」が等しくなります。 統計ソフトのパッケージや教科書によっては、スケール変数という用語が使われていますが、これは我々が区間変数と呼ぶものと全く同じものです。
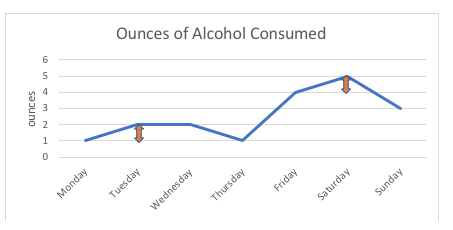
例えば、下のグラフで、この人が1オンスまたは2オンスのアルコールを消費したとき(月曜日、火曜日)の1オンスの差は、4オンスまたは5オンスを消費したとき(金曜日、土曜日)の1オンスの差と全く同じものです。 2点間の間隔は標準単位(この例ではオンス)で測定されています。
評価スケールのような順序変数では、たとえ数字を使用してこれらの回答オプションを並べたとしても、「決して」と「時々」の回答オプション間の「距離」と「時々」と「しばしば」の「距離」が同じだと誰も確実に言うことができません。
少し混乱するのは、SPSSのような特定の統計ソフトウェア・プログラムが、間隔変数を「スケール」変数として参照することです。 ソーシャルワーク研究で使用される多くの変数は、順序付けされ、ポイント間の距離が等しいです。 例えば、出生順の変数を考えてみましょう。 この変数が区間変数である理由は、
- 可能な値が順序付けされ(例えば、3番目に生まれた子供は、1番目と2番目に生まれた子供の後で、4番目に生まれた子供の前に来た)、
- その「距離」または区間が、等しい1人単位で測定されるからである。 連続変数と呼ばれる特殊なタイプの数値区間変数が存在する。 年齢のような変数は、連続変数として扱われるかもしれない。 ageは自然界では序数的であり、より大きな数値はより小さな数値との関係で何かを意味するからです。 また、年齢は順序変数であり、15歳と30歳の間には40歳と55歳の間と同じ「距離」がある(15暦年)ので、年(または月、週、日)で測定すると、区間変数であることの基準を満たします。 これが連続変数であるのは、任意の2つの区間の間に、可能で意味のある「分数」ポイントが存在することです。 例えば、20歳半(20.5歳)、20歳¼(20.25歳)、20歳¾(20.75歳)など、年齢を表すのは整数だけにとどまりません。 これに対して、出生順を見た場合、尺度の2つの位置の間に意味のある分数を持つことはできない
所得の特殊なケース。 社会科学やソーシャルワークの研究で最も乱用される変数のひとつに、収入に関する変数がある。 世帯収入(世帯に何人いるかは関係なく)についての例を考えてみましょう。 この変数は、扱い方によって、カテゴリー(名義)、順序、またはインターバル(尺度)になります。
カテゴリーの例。 カテゴリ型例:リサーチクエスチョンの性質によっては、調査者は何らかの標準的な計算方法に基づいて、世帯を分類するために「十分に資源がある」と「十分に資源がない」の2値カテゴリを単純に使用することを選択するかもしれない。 また、貧困線が設定されている場合は、「貧困」「貧困でない」と分類される。 これらの明確な所得変数のカテゴリは、数値的な方法で意味を持って配列されていないので、カテゴリ変数です。
Ordinal Example: 世帯を分類するためのカテゴリは、低いものから高いものへと順序付けられるかもしれません。 例えば、年収のこれらのカテゴリは市場調査で一般的です:
- Less than $25,000.
$25,000 to $34,999.
- $35,000 to $49,999.
- $50,000 to $74,999.
- $75,000 to $99,999.L
- $100,000 to $149,999。
- $150,000 to $199,999。
- $200,000 or more。
カテゴリは同じサイズではないことに注意してください-カテゴリ間のペアは常に同じではない「距離」です。 最初は約1万ドル単位で、2万5千ドル単位になり、最後は約5万ドル単位になります。
Interval 例。 調査者が調査参加者に世帯収入の実際のドル額を報告するよう求めた場合、区間変数が見られるでしょう。 可能な値は順序付けられ、任意の可能な隣接する単位間の間隔は$1です(ドルの端数またはセントが使用されていない限り)。 したがって、$10,452の収入は$9,452と$11,452-$1,000からの連続体上の同じ距離です。
年齢の特殊ケースです。 収入と同様に、「年齢」も研究によって意味が異なることがある。 年齢は通常、”生まれてからの時間 “を示す指標である。 測定日から生年月日の変数を引く(今日の日付から生年月日を引く)ことで、その人の年齢を計算することができる。 成人の場合、年齢は一般的に年単位で測定され、隣り合う可能性のある値は1年単位で離れている:18、19、20、21、22、……。
しかし、調査者は年齢データを順序付けられたカテゴリーや年齢グループに分類したいかもしれない。 これらはまだ序数であるが、可能な値間の増分が等価な単位でない場合は、もはや区間ではないかもしれない。 例えば、人間の特定の発達段階を表す年齢に関心がある場合、年齢区分は年齢基準間のスパンが等しくないかもしれない。 可能性としては、以下のようになる。
- 乳児期(出生から18カ月)
- 幼児期(18カ月から2年半)
- 就学前(2年半から5年)
- 学齢(6年から11年)
など
- 青年期(12~17歳)
- 初老期(18~25歳)
- 成人期(26~45歳)
- 中年期(46~60歳)
- ヤング(Y)期(Y)期(Y)期(Y)
- 青年期(12~17歳)
初老期(12~25歳)
- 成人期(12~18歳)
初老期(12~17歳Old Adulthood (60 to 74 years)
- Middle-Old Adulthood (75 to 84 years)
- Old-Old Adulthood (85 or more years)
年齢は厳密にカテゴリー変数(非序数)として扱われることもあるようです。 例えば、興味のある変数が、誰かが合法的な飲酒年齢(21歳以上)であるか、そうでないかであるとします。 そして、どちらかを “1” でコード化し、もう一方を “0” または “2” として、意味の違いはありません。
年齢(または収入)の測定方法について、何が「正しい」答えなのでしょうか。 答えは “it depends “である。 つまり、年齢(または収入)のどの概念が、計画中の研究に最も関連しているかということです。
英数字変数。 最後に、これらの分類のいずれにも当てはまらないデータがある。 私たちが知っている情報は、住所や電話番号、姓や名、郵便番号、その他のフレーズの形をしていることがあります。 このような情報は英数字変数と呼ばれることもある。 たとえば、「住所」という変数を考えてみよう。ある人の住所は、数字(番地)と文字(通り名、市名、州名を綴ったもの)から構成されるかもしれない、たとえば1600 Pennsylvania Ave.のように。 NW, Washington, DC, 20500.
実際には、この住所の例にはいくつかの変数があります:
- the street address.NW(番地)。 1600 Pennsylvania Ave.
- 都市 (および「州」)。 Washington, DC
- 郵便番号。 20500.
このような情報は、データの中で体系的な意味を持つ特定の量的カテゴリーや値を表すものではありません。 これらは、記号の列で構成されているため、特定のソフトウェアパッケージでは「文字列」変数と呼ばれることもあります。 調査者にとって有用であるためには、このような変数は意味のある値に変換または再コード化されなければならない。
A Note about Unit of Analysis
変数について考える上で重要なことは、データは多くの異なるレベルの観察で収集される可能性があることである。 研究される要素は、個々の細胞、器官系、または人であるかもしれません。 あるいは、カップル、兄弟姉妹、親子など、個人のペアが観察の対象となるかもしれません。 この場合、研究者は各個人からペアに関する情報を収集するかもしれないが、各ペアのデータを見ていることになる。 したがって、分析単位は各個人ではなく、ペアまたはダイアドであると言うことになる。 例えば、学校や学校システムの教室を分析単位とする場合、教室全体の生徒からデータを収集することができる。 また、近隣、プログラム、組織、郡、州、あるいは国家といった単位で分析することもできる。 例えば、手頃な価格やアクセス性など、地域社会のレベルで食料安全保障の指標として用いられる変数の多くは、個々の世帯から収集したデータに基づいている(Kaiser, 2017)。 これらの指標を用いた研究の分析単位は、比較対象となるコミュニティとなる。 この区別は、測定とデータ分析に重要な意味を持ちます。
変数対変数レベルに関する注意点
研究は、比較されている変数カテゴリ、またはレベルの数で説明される場合があります。 例えば、ある研究が2×2デザイン(two by two designと発音されます)として記述されているのを見るかもしれません。 これは、最初の変数に2つの可能なカテゴリがあり、もう1つの変数に2つの可能なカテゴリがあることを意味します-これらは両方とも2分変数です。 変数「アルコール使用障害」の2つのカテゴリー(基準を満たす、はいまたはいいえ)と変数「違法物質使用障害」の2つのカテゴリー(基準を満たす、はいまたはいいえ)を比較する研究は、4つの可能な結果を持ち(数学的には、2×2=4)、次のように図示することができます(2016 NSDUH調査からの割合に基づくデータ、SAMHSA、2017に提示されたもの)。
違法物質使用障害(SUD) アルコール使用障害(AUD)
No Yes No 500 10 Yes 26 4 この2×2表の4セルを読むと、この(仮の)調査対象者540人の場合、次のことがわかります。 500人は、アルコールまたは違法薬物使用障害のいずれの基準も満たしていない(No, No)。 26人がアルコール使用障害のみの基準を満たし(はい、いいえ)、10人が違法薬物使用障害のみの基準を満たし(いいえ、はい)、4人がアルコールと違法薬物の両方の使用障害の基準を満たし(はい、はい)ました。 また、少し計算をすると、アルコール使用障害が26人+4人の合計30人、違法薬物使用障害が10人+4人の合計14人であることがわかります。 そして、40人が何らかの物質使用障害(26+10+4)を持っていることがわかります。
変数と変数のレベルまたはカテゴリとのこの区別を明確にするために、もう1つの例、2 X 3研究デザインを考えてみましょう。 まず、計算をすると、6つの可能な結果(セル)が見えるはずです。 次に、最初の変数(age group)が2つのカテゴリ(under age 30, 30 or older)を持ち、もう1つの変数(employment status)が3つのカテゴリ(fully employed, partially employed, unemployed)を持っていることがわかります。 今回はデータ待ちのため、設計の6つのセルは空です。
Employment Status Age Group
Fully Employed PartiallyのPrivate 被雇用者 無職 <30 ≧30 このようにです。 2つの数字を掛け合わせたような研究デザインの記述を目にしたとき、それは本質的に、各変数のカテゴリまたはレベルがいくつあるかを教えており、いくつのセルまたは可能な結果が存在するかを理解させるものです。 3×3デザインは9個のセルを持ち、3×4デザインは12個のセルを持つ、といった具合です。 3766>
次のワークブック活動を完了する:
- SWK 3401.3-4.1 Beginning Data Entry
Chapter Summary
まとめとして、研究者は変数間の関係についての仮説をテストするために定量研究の多くを設計しています。 関係する変数の性質を理解することは、実施された研究を理解し評価するのに役立つ。 変数とカテゴリだけでなく、変数の異なるタイプの間の区別を理解することは、研究デザイン、測定、およびサンプルに重要な意味を持っています。 他のトピックの中で、次の章では、定量的研究で研究される変数の性質と、調査者がそれらの変数の測定に着手する方法との間の交差を探ります。