
- Een snelle doorloop van de beste papers over beeldclassificatie in een decennium om een vliegende start te maken met het leren van computer vision
- 1998: LeNet
- 2012: AlexNet
- 2014: VGG
- 2014: GoogLeNet
- 2015: Batch Normalization
- 2015: ResNet
- 2016: Xception
- 2017: MobileNet
- 2017: NASNet
- 2019: EfficientNet
- 2014: SPPNet
- 2016: DenseNet
- 2017: SENet
- 2017: ShuffleNet
- 2018: Bag of Tricks
- Conclusie
Een snelle doorloop van de beste papers over beeldclassificatie in een decennium om een vliegende start te maken met het leren van computer vision

Computer vision is een vak om afbeeldingen en video’s om te zetten in machine-begrijpelijke signalen. Met deze signalen kunnen programmeurs het gedrag van de machine verder sturen op basis van dit inzicht op hoog niveau. Van de vele computervisietaken is beeldclassificatie een van de meest fundamentele. Het kan niet alleen worden gebruikt in veel echte producten zoals Google Photo’s tagging en AI content moderation, maar opent ook de deur voor veel meer geavanceerde vision-taken, zoals objectdetectie en video-inzicht. Door de snelle veranderingen op dit gebied sinds de doorbraak van Deep Learning, vinden beginners het vaak te overweldigend om te leren. In tegenstelling tot typische software engineering onderwerpen, zijn er niet veel goede boeken over beeldclassificatie met behulp van DCNN, en de beste manier om dit veld te begrijpen is door het lezen van academische papers. Maar welke papers moet ik lezen? Waar moet ik beginnen? In dit artikel stel ik 10 beste papers voor die beginners kunnen lezen. Aan de hand van deze papers kunnen we zien hoe dit vakgebied evolueert, en hoe onderzoekers nieuwe ideeën hebben ontwikkeld op basis van eerdere onderzoeksresultaten. Toch is het nog steeds nuttig voor u om het grote plaatje te sorteren, zelfs als je al hebt gewerkt in dit gebied voor een tijdje. Dus, laten we beginnen.
1998: LeNet
Gradient-based Learning Applied to Document Recognition

Ingevoerd in 1998, LeNet legt de basis voor toekomstig onderzoek naar beeldclassificatie met behulp van het Convolution Neural Network. Veel klassieke CNN-technieken, zoals poolinglagen, volledig aangesloten lagen, opvulling en activeringslagen, worden gebruikt om kenmerken te extraheren en een classificatie te maken. Met een Mean Square Error verliesfunctie en 20 epochs van training, kan dit netwerk 99,05% nauwkeurigheid bereiken op de MNIST test set. Zelfs na 20 jaar volgen veel state-of-the-art classificatienetwerken in het algemeen nog steeds dit patroon.
2012: AlexNet
ImageNet Classificatie met Diepe Convolutionele Neurale Netwerken

Hoewel LeNet een geweldig resultaat heeft behaald en het potentieel van CNN heeft laten zien, stagneerde de ontwikkeling op dit gebied gedurende een decennium als gevolg van beperkte rekenkracht en de hoeveelheid gegevens. Het leek erop dat CNN alleen eenvoudige taken zoals cijferherkenning kon oplossen, maar voor complexere eigenschappen zoals gezichten en objecten werd de voorkeur gegeven aan een HarrCascade- of SIFT-extractor met een SVM-classifier.
Bij de ImageNet Large Scale Visual Recognition Challenge van 2012 stelde Alex Krizhevsky echter een CNN-gebaseerde oplossing voor deze uitdaging voor en verhoogde de top-5-nauwkeurigheid van de ImageNet-testset drastisch van 73,8% tot 84,7%. Hun aanpak erft het meerlaagse CNN-idee van LeNet, maar heeft de CNN veel groter gemaakt. Zoals je in het diagram hierboven kunt zien, is de invoer nu 224×224 vergeleken met LeNet’s 32×32, ook hebben veel Convolutiekernels 192 kanalen vergeleken met LeNet’s 6. Hoewel het ontwerp niet veel veranderd is, met honderden malen meer parameters, is het vermogen van het netwerk om complexe kenmerken vast te leggen en te representeren ook honderden keren verbeterd. Om zo’n groot model te trainen, gebruikte Alex twee GTX 580 GPU’s met 3GB RAM voor elk, waarmee hij een trend van GPU-training inluidde. Ook het gebruik van ReLU niet-lineariteit hielp om de rekenkosten te verlagen.
Naast het brengen van veel meer parameters voor het netwerk, onderzocht het ook het overfitting probleem dat een groter netwerk met zich meebrengt door een Dropout laag te gebruiken. De Local Response Normalization methode werd daarna niet al te populair, maar inspireerde andere belangrijke normalisatietechnieken zoals BatchNorm om het probleem van gradiëntverzadiging tegen te gaan. Kortom, AlexNet definieerde het de facto classificatie netwerk raamwerk voor de komende 10 jaar: een combinatie van Convolutie, ReLu niet-lineaire activering, MaxPooling, en Dense layer.
2014: VGG
Very Deep Convolutional Networks for Large-Scale Image Recognition
Met zo’n groot succes van het gebruik van CNN voor visuele herkenning, is de hele onderzoeksgemeenschap opgeblazen en zijn ze allemaal gaan onderzoeken waarom dit neurale netwerk zo goed werkt. In “Visualizing and Understanding Convolutional Networks” uit 2013 besprak Matthew Zeiler bijvoorbeeld hoe CNN kenmerken oppikt en visualiseerde hij de tussenliggende representaties. En plotseling begon iedereen zich sinds 2014 te realiseren dat CNN de toekomst van computervisie is. Van al die onmiddellijke volgelingen springt het VGG-netwerk van de Visual Geometry Group het meest in het oog. Het behaalde een opmerkelijk resultaat van 93,2% top-5 nauwkeurigheid, en 76,3% top-1 nauwkeurigheid op de ImageNet test set.
Na het ontwerp van AlexNet, heeft het VGG netwerk twee belangrijke updates: 1) VGG gebruikt niet alleen een breder netwerk zoals AlexNet, maar ook dieper. VGG-19 heeft 19 convolutielagen, vergeleken met 5 van AlexNet. 2) VGG toonde ook aan dat een paar kleine 3×3 convolutiefilters een enkele 7×7 of zelfs 11×11 filters van AlexNet kunnen vervangen, betere prestaties kunnen bereiken en tegelijkertijd de berekeningskosten kunnen verlagen. Door dit elegante ontwerp werd VGG ook het back-bone netwerk van vele baanbrekende netwerken in andere computervisietaken, zoals FCN voor semantische segmentatie, en Faster R-CNN voor objectdetectie.
Met een dieper netwerk wordt het verdwijnen van de gradiënt van meerlagige back-propagatie een groter probleem. Om hiermee om te gaan, besprak VGG ook het belang van pre-training en gewicht initialisatie. Dit probleem beperkt onderzoekers om steeds meer lagen toe te voegen, anders zal het netwerk heel moeilijk kunnen convergeren. Maar we zullen hier na twee jaar een betere oplossing voor zien.
2014: GoogLeNet
Going Deeper with Convolutions

VGG heeft een goed uitziende en makkelijk te begrijpen structuur, maar de prestaties zijn niet de beste van alle finalisten in de ImageNet 2014-wedstrijden. GoogLeNet, ook bekend als InceptionV1, won de eindprijs. Net als VGG is een van de belangrijkste bijdragen van GoogLeNet het verleggen van de grens van de netwerkdiepte met een structuur van 22 lagen. Dit toonde opnieuw aan dat dieper en breder gaan inderdaad de juiste richting is om de nauwkeurigheid te verbeteren.
In tegenstelling tot VGG probeerde GoogLeNet de problemen met de berekening en gradiëntafname frontaal aan te pakken, in plaats van een workaround voor te stellen met betere voorgetrainde schema’s en initialisatie van gewichten.

Eerst werd het idee van asymmetrisch netwerkontwerp verkend met behulp van een module die Inception wordt genoemd (zie het bovenstaande diagram). Idealiter zouden ze spaarzame convolutie of dichte lagen willen nastreven om de functie-efficiëntie te verbeteren, maar het moderne hardwareontwerp was hier niet op toegesneden. Dus ze geloofden dat een spaarzaamheid op het niveau van de netwerktopologie ook zou kunnen helpen bij de fusie van kenmerken, terwijl gebruik wordt gemaakt van bestaande hardwaremogelijkheden.
Ten tweede valt het het probleem van de hoge computationele kosten aan door een idee te lenen uit een paper genaamd “Network in Network”. In principe wordt een 1×1 convolutiefilter geïntroduceerd om de dimensies van kenmerken te reduceren voordat een zware rekenoperatie als een 5×5 convolutiekernel wordt uitgevoerd. Deze structuur wordt later “Bottleneck” genoemd en wordt op grote schaal gebruikt in vele volgende netwerken. Vergelijkbaar met “Network in Network”, gebruikte het ook een gemiddelde poollaag om de laatste volledig aangesloten laag te vervangen om de kosten verder te verlagen.
Derde, om gradiënten te helpen naar diepere lagen te stromen, gebruikte GoogLeNet ook supervisie op sommige tussenlaagoutputs of hulpoutput. Dit ontwerp is niet vrij populair later in het beeld classificatie netwerk vanwege de complexiteit, maar steeds meer populair in andere gebieden van computer vision, zoals Zandloper netwerk in pose estimation.
Als een follow-up, dit Google-team schreef meer papers voor deze Inception-serie. “Batch Normalisatie: Accelerating Deep Network Training by Reducing Internal Covariate Shift” staat voor InceptionV2. “Rethinking the Inception Architecture for Computer Vision” in 2015 staat voor InceptionV3. En “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning” in 2015 staat voor InceptionV4. Elk artikel voegde meer verbeteringen toe ten opzichte van het originele Inception-netwerk en behaalde een beter resultaat.
2015: Batch Normalization
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Het Inception-netwerk hielp onderzoekers om een bovenmenselijke nauwkeurigheid te bereiken op de ImageNet-dataset. Als een statistische leermethode is CNN echter sterk beperkt tot de statistische aard van een specifieke trainingsdataset. Daarom moeten we, om een betere nauwkeurigheid te bereiken, meestal het gemiddelde en de standaardafwijking van de hele dataset vooraf berekenen en deze gebruiken om onze invoer eerst te normaliseren, om er zeker van te zijn dat de meeste laagingangen in het netwerk dicht bij elkaar liggen, wat zich vertaalt in een betere activeringsreactie. Deze benaderende aanpak is erg omslachtig, en werkt soms helemaal niet voor een nieuwe netwerkstructuur of een nieuwe dataset, zodat het deep learning-model nog steeds als moeilijk te trainen wordt beschouwd. Om dit probleem aan te pakken, besloten Sergey Ioffe en Chritian Szegedy, de man die GoogLeNet heeft gemaakt, iets slimmers uit te vinden, genaamd Batch Normalization.

Het idee van batchnormalisatie is niet moeilijk: we kunnen de statistieken van een reeks mini-batch gebruiken om de statistieken van de hele dataset te benaderen, zolang we maar lang genoeg trainen. Ook kunnen we, in plaats van de statistieken handmatig te berekenen, twee meer leerbare parameters “schaal” en “verschuiving” introduceren om het netwerk te laten leren hoe het elke laag zelf kan normaliseren.
Het bovenstaande diagram toont het proces van het berekenen van batch normalisatiewaarden. Zoals we kunnen zien, nemen we het gemiddelde van de hele mini-batch en berekenen ook de variantie. Vervolgens kunnen we de invoer normaliseren met dit gemiddelde en deze variantie van de minipartij. Tenslotte zal het netwerk, met een schaal en een verschuivingsparameter, leren om het batch genormaliseerde resultaat aan te passen zodat het het beste past bij de volgende lagen, meestal ReLU. Een kanttekening is dat we geen mini-batch informatie hebben tijdens de inferentie, dus een workaround is om een voortschrijdend gemiddelde van gemiddelde en variantie te berekenen tijdens de training, en dan deze voortschrijdende gemiddelden te gebruiken in het inferentiepad. Deze kleine innovatie is zo impactvol, en alle latere netwerken beginnen het meteen te gebruiken.
2015: ResNet
Deep Residual Learning for Image Recognition
2015 is misschien wel het beste jaar voor computervisie in een decennium, we hebben zoveel geweldige ideeën zien opduiken, niet alleen in beeldclassificatie, maar in allerlei computervisietaken zoals objectdetectie, semantische segmentatie, enzovoort. De grootste vooruitgang van het jaar 2015 behoort tot een nieuw netwerk genaamd ResNet, of residuele netwerken, voorgesteld door een groep Chinese onderzoekers van Microsoft Research Asia.

Zoals we eerder hebben besproken voor VGG-netwerk, is de grootste hindernis om nog dieper te gaan het gradiënt verdwijnende probleem, d.w.z.Dat wil zeggen dat de afgeleiden steeds kleiner worden bij het back-propageren door diepere lagen, en uiteindelijk een punt bereiken dat moderne computerarchitectuur niet echt zinvol kan weergeven. GoogLeNet heeft geprobeerd dit aan te pakken door gebruik te maken van hulpsupervisie en een asymmetrische waarnemingsmodule, maar dit verlicht het probleem slechts in geringe mate. Als we 50 of zelfs 100 lagen willen gebruiken, is er dan een betere manier om de gradiënt door het netwerk te laten stromen? Het antwoord van ResNet is het gebruik van een restmodule.

ResNet voegde een identiteitssnelkoppeling toe aan de uitvoer, zodat elke residual module op zijn minst kan voorspellen wat de invoer ook is, zonder in het wilde weg te verdwalen. Nog belangrijker is dat de residuele module, in plaats van te hopen dat elke laag direct past op de gewenste feature mapping, probeert het verschil te leren tussen output en input, wat de taak veel gemakkelijker maakt omdat de benodigde informatiewinst minder is. Stel je voor dat je wiskunde leert, voor elk nieuw probleem krijg je een oplossing van een soortgelijk probleem, dus het enige wat je hoeft te doen is deze oplossing uit te breiden en te proberen het te laten werken. Dit is veel gemakkelijker dan voor elk probleem dat je tegenkomt een gloednieuwe oplossing te bedenken. Of zoals Newton zei, we kunnen op de schouders van reuzen staan, en de identiteitsinvoer is die reus voor de restmodule.
Naast de identiteitsmapping heeft ResNet ook de bottleneck en Batch Normalization geleend van Inception-netwerken. Uiteindelijk lukte het om een netwerk met 152 convolutielagen te bouwen en 80,72% top-1 nauwkeurigheid op ImageNet te bereiken. De residuele aanpak wordt later ook een standaardoptie voor veel andere netwerken, zoals Xception, Darknet, enz. Dankzij het eenvoudige en mooie ontwerp wordt het tegenwoordig nog steeds veel gebruikt in veel visuele productiesystemen.
Er zijn nog veel meer invarianten uitgekomen door de hype van het residuele netwerk te volgen. In “Identity Mappings in Deep Residual Networks”, probeerde de oorspronkelijke auteur van ResNet activering vóór de residuele module te plaatsen en bereikte een beter resultaat, en dit ontwerp wordt daarna ResNetV2 genoemd. Ook in een paper uit 2016 “Aggregated Residual Transformations for Deep Neural Networks”, stelden onderzoekers ResNeXt voor, dat parallelle takken toevoegde voor residuele modules om uitgangen van verschillende transformaties te aggregeren.
2016: Xception
Xception: Deep Learning with Depthwise Separable Convolutions

Met de release van ResNet leek het erop dat het meeste laaghangende fruit in de beeldclassificator al was gegrepen. Onderzoekers begonnen na te denken over wat het interne mechanisme is van de magie van CNN. Omdat kanaaloverschrijdende convolutie gewoonlijk een ton aan parameters introduceert, koos het Xception-netwerk ervoor om deze bewerking te onderzoeken om een volledig beeld te krijgen van het effect ervan.
Net als zijn naam, is Xception afkomstig van het Inception-netwerk. In de Inception-module worden meerdere takken van verschillende transformaties samengevoegd om een topologische sparsity te bereiken. Maar waarom werkt deze spaarzaamheid? De auteur van Xception, tevens de auteur van het Keras framework, heeft dit idee uitgebreid naar een extreem geval waarbij één 3×3 convolutie bestand overeenkomt met één output kanaal voor een uiteindelijke concatenatie. In dit geval vormen deze parallelle convolutiekernels in feite een nieuwe bewerking die diepte-wise convolutie wordt genoemd.

Zoals in bovenstaand diagram is te zien, in tegenstelling tot traditionele convolutie waarbij alle kanalen in één berekening worden opgenomen, convolueert de diepte-afhankelijke convolutie alleen voor elk kanaal afzonderlijk en wordt de uitvoer vervolgens samengevoegd. Dit vermindert de uitwisseling van kenmerken tussen kanalen, maar vermindert ook veel verbindingen, wat resulteert in een laag met minder parameters. Deze bewerking zal echter hetzelfde aantal kanalen als invoer uitvoeren (of een kleiner aantal kanalen als u twee of meer kanalen samenvoegt). Daarom hebben we, zodra de kanaaluitgangen zijn samengevoegd, een ander regulier 1×1 filter nodig, of puntsgewijze convolutie, om het aantal kanalen te verhogen of te verlagen, net zoals reguliere convolutie dat doet.
Dit idee is oorspronkelijk niet van Xception. Het is beschreven in een paper genaamd “Learning visual representations at scale” en ook af en toe gebruikt in InceptionV2. Xception ging een stap verder en verving bijna alle convoluties door dit nieuwe type. En het experimentele resultaat bleek behoorlijk goed te zijn. Het overtreft ResNet en InceptionV3 en werd een nieuwe SOTA methode voor beeldclassificatie. Dit bewees ook dat de mapping van cross-channel correlaties en ruimtelijke correlaties in CNN volledig kan worden ontkoppeld. Bovendien deelt Xception dezelfde deugd als ResNet en heeft het ook een eenvoudig en mooi ontwerp, zodat het idee ervan wordt gebruikt in veel andere volgende onderzoeken zoals MobileNet, DeepLabV3, enz.
2017: MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
Xception behaalde 79% top-1 nauwkeurigheid en 94,5% top-5 nauwkeurigheid op ImageNet, maar dat is respectievelijk slechts 0,8% en 0,4% verbetering ten opzichte van de vorige SOTA InceptionV3. De marginale winst van een nieuw beeldclassificatienetwerk wordt steeds kleiner, dus beginnen onderzoekers hun aandacht te verleggen naar andere gebieden. En MobileNet heeft een belangrijke impuls gegeven aan beeldclassificatie in een omgeving met beperkte middelen.

Gelijk aan Xception, gebruikte MobileNet dezelfde dieptescheidbare convolutiemodule als hierboven getoond en lag de nadruk op de hoge efficiëntie en minder parameters.
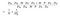
De teller in de bovenstaande formule is het totale aantal parameters dat nodig is voor een in de diepte scheidbare convolutie. En de noemer is het totale aantal parameters van een soortgelijke regelmatige convolutie. Hierin is D de grootte van de convolutiekernel, D de grootte van de kenmerkenkaart, M het aantal ingangskanalen en N het aantal uitgangskanalen. Aangezien we de berekening van kanaal en ruimtelijk kenmerk hebben gescheiden, kunnen we de vermenigvuldiging omzetten in een optelling, die een grootte kleiner is. Nog beter, zoals we kunnen zien in deze verhouding, hoe groter het aantal uitgangskanalen is, hoe meer berekening we besparen door deze nieuwe convolutie te gebruiken.
Een andere bijdrage van MobileNet is de breedte en resolutie vermenigvuldiger. Het MobileNet-team wilde een canonieke manier vinden om de modelgrootte voor mobiele apparaten te verkleinen, en de meest intuïtieve manier is om het aantal invoer- en uitvoerkanalen te verminderen, evenals de invoerbeeldresolutie. Om dit gedrag te controleren, wordt een ratio alpha vermenigvuldigd met kanalen, en een ratio rho wordt vermenigvuldigd met invoerresolutie (die ook de grootte van de feature map beïnvloedt). Het totale aantal parameters kan dus in de volgende formule worden weergegeven:

Hoewel deze wijziging naïef lijkt in termen van innovatie, heeft ze een grote technische waarde omdat het de eerste keer is dat onderzoekers een canonieke benadering concluderen om het netwerk aan te passen voor verschillende middelenbeperkingen. Ook, het soort samengevat de ultieme oplossing van het verbeteren van neurale netwerken: bredere en high-res input leidt tot betere nauwkeurigheid, dunnere en low-res input leidt tot slechtere nauwkeurigheid.
Later in 2018 en 2019, het MobiletNet-team bracht ook “MobileNetV2: Inverted Residuals and Linear Bottlenecks” en “Searching for MobileNetV3”. In MobileNetV2 wordt een omgekeerde residuele knelpuntenstructuur gebruikt. En in MobileNetV3 is men begonnen met het zoeken naar de optimale architectuurcombinatie met behulp van Neural Architecture Search technologie, die we hierna zullen behandelen.
2017: NASNet
Learning Transferable Architectures for Scalable Image Recognition
Net als beeldclassificatie voor een resource-beperkte omgeving, is het zoeken naar neurale architecturen een ander gebied dat rond 2017 opkwam. Met ResNet, Inception en Xception lijkt het alsof we een optimale netwerktopologie hebben bereikt die mensen kunnen begrijpen en ontwerpen, maar wat als er een betere en veel complexere combinatie is die het menselijk voorstellingsvermogen ver te boven gaat? Een paper uit 2016 genaamd “Neural Architecture Search with Reinforcement Learning” stelde een idee voor om de optimale combinatie te zoeken binnen een vooraf gedefinieerde zoekruimte door gebruik te maken van reinforcement learning. Zoals we weten, is reinforcement learning een methode om de beste oplossing te vinden met een duidelijk doel en beloning voor de zoekagent. Beperkt door de rekenkracht, werd in dit artikel echter alleen de toepassing in een kleine CIFAR-dataset besproken.

Met het doel een optimale structuur te vinden voor een grote dataset als ImageNet, heeft NASNet een zoekruimte gemaakt die is afgestemd op ImageNet. Het hoopt een speciale zoekruimte te ontwerpen, zodat het gezochte resultaat op CIFAR ook goed kan werken op ImageNet. Ten eerste gaat NASNet ervan uit dat gemeenschappelijke handgemaakte module in goede netwerken zoals ResNet en Xception nog steeds nuttig zijn bij het zoeken. Dus in plaats van te zoeken naar willekeurige verbindingen en bewerkingen, zoekt NASNet naar de combinatie van deze modules die al nuttig zijn gebleken op ImageNet. Ten tweede, het eigenlijke zoeken wordt nog steeds uitgevoerd op de CIFAR dataset met 32×32 resolutie, dus NASNet zoekt alleen naar modules die niet worden beïnvloed door de invoer grootte. Om het tweede punt te laten werken, heeft NASNet twee soorten module sjablonen voorgedefinieerd: Reductie en Normaal. Een verkleinde cel kan een verkleinde feature map hebben vergeleken met de input, en voor een normale cel zou dat hetzelfde zijn.

Hoewel NASNet betere metrieken heeft dan handmatig ontworpen netwerken, lijdt het ook aan een paar nadelen. De kosten voor het zoeken naar een optimale structuur zijn zeer hoog, wat alleen betaalbaar is voor grote bedrijven zoals Google en Facebook. Ook is de uiteindelijke structuur niet al te logisch voor mensen, en dus moeilijker te onderhouden en te verbeteren in een productieomgeving. Later in 2018, “MnasNet: Platform-Aware Neural Architecture Search for Mobile” dit NASNet-idee verder uit door de zoekstap te beperken met een vooraf gedefinieerde chained-blocks-structuur. Door een gewichtsfactor te definiëren, biedt mNASNet een meer systematische manier om een model te zoeken met specifieke beperkingen voor de middelen, in plaats van enkel te evalueren op basis van FLOPs.
2019: EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
In 2019 lijkt het erop dat er geen spannende ideeën meer zijn voor gesuperviseerde beeldclassificatie met CNN. Een drastische verandering in de netwerkstructuur biedt meestal slechts een kleine nauwkeurigheidsverbetering. Erger nog, wanneer hetzelfde netwerk wordt toegepast op verschillende datasets en taken, lijken eerder geclaimde trucs niet te werken, wat leidde tot kritiek dat die verbeteringen gewoon overfitting zijn op de ImageNet-dataset. Aan de andere kant is er één truc die onze verwachtingen nooit inlost: het gebruik van input met een hogere resolutie, het toevoegen van meer kanalen voor convolutielagen, en het toevoegen van meer lagen. Hoewel het erg hardhandig is, lijkt het erop dat er een principiële manier is om het netwerk op verzoek te schalen. MobileNetV1 suggereerde dit min of meer in 2017, maar de focus werd later verlegd naar een beter netwerkontwerp.

Na NASNet en mNASNet realiseerden onderzoekers zich dat zelfs met de hulp van een computer een verandering in de architectuur niet zo veel voordeel oplevert. Dus beginnen ze terug te vallen op het schalen van het netwerk. EfficientNet is juist op deze aanname gebouwd. Aan de ene kant gebruikt het de optimale bouwsteen van mNASNet om te zorgen voor een goede basis om mee te beginnen. Anderzijds definieert het drie parameters alpha, beta, en rho om de diepte, breedte, en resolutie van het netwerk dienovereenkomstig te regelen. Op die manier kunnen ingenieurs, zelfs zonder een grote GPU pool om te zoeken naar een optimale structuur, nog steeds vertrouwen op deze principiële parameters om het netwerk af te stemmen op basis van hun verschillende eisen. Uiteindelijk gaf EfficientNet 8 verschillende varianten met verschillende breedte, diepte, en resolutie verhoudingen en kreeg goede prestaties voor zowel kleine als grote modellen. Met andere woorden, als u een hoge nauwkeurigheid wilt, ga dan voor een 600×600 en 66M parameters EfficientNet-B7. Als u een lage latency en een kleiner model wilt, ga dan voor een 224×224 en 5.3M parameters EfficientNet-B0. Probleem opgelost.
Als je bovenstaande 10 papers hebt gelezen, zou je een aardig idee moeten hebben van de geschiedenis van beeldclassificatie met CNN. Als je verder wilt leren op dit gebied, heb ik nog een aantal andere interessante papers voor je op een rijtje gezet. Hoewel niet opgenomen in de top-10 lijst, zijn deze papers allemaal beroemd in hun eigen gebied en inspireerden ze vele andere onderzoekers in de wereld.
2014: SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPPNet leent het idee van feature-piramide van traditionele computervisie feature-extractie. Deze piramide vormt een zak met woorden van kenmerken met verschillende schalen, zodat het zich kan aanpassen aan verschillende invoergroottes en zich kan ontdoen van de volledig aangesloten laag met vaste grootte. Dit idee inspireerde ook de ASPP-module van DeepLab, en ook FPN voor objectdetectie.
2016: DenseNet
Densely Connected Convolutional Networks
DenseNet van Cornell breidt het idee van ResNet verder uit. Het biedt niet alleen overgeslagen verbindingen tussen lagen, maar heeft ook overgeslagen verbindingen van alle voorgaande lagen.
2017: SENet
Squeeze-and-Excitation Networks
Het Xception-netwerk toonde aan dat cross-channel correlatie niet veel te maken heeft met ruimtelijke correlatie. SENet, de kampioen van de laatste ImageNet-competitie, bedacht echter een Squeeze-and-Excitation-blok en vertelde een ander verhaal. Het SE-blok perst eerst alle kanalen tot minder kanalen met behulp van global pooling, past een volledig verbonden transformatie toe, en “exciteert” ze dan terug naar het oorspronkelijke aantal kanalen met behulp van een andere volledig verbonden laag. Dus in wezen hielp de FC-laag het netwerk om te leren letten op de ingangskenmerkenkaart.
2017: ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Gebouwd bovenop de omgekeerde knelpuntmodule van MobileNetV2, is ShuffleNet van mening dat puntsgewijze convolutie in dieptesgewijs scheidbare convolutie nauwkeurigheid opoffert in ruil voor minder rekenwerk. Om dit te compenseren heeft ShuffleNet een extra kanaal shuffling operatie toegevoegd om er voor te zorgen dat point-wise convolutie niet altijd op hetzelfde “punt” zal worden toegepast. En in ShuffleNetV2, is dit kanaal shuffling mechanisme verder uitgebreid met een ResNet identiteit mapping tak, zodat een deel van de identiteit eigenschap ook zal worden gebruikt om te shuffelen.
2018: Bag of Tricks
Bag of Tricks for Image Classification with Convolutional Neural Networks
Bag of Tricks richt zich op veelgebruikte trucs op het gebied van beeldclassificatie. Het dient als een goede referentie voor ingenieurs wanneer ze de benchmarkprestaties moeten verbeteren. Interessant is dat deze trucs, zoals mixup augmentation en cosine learning rate, soms een veel betere verbetering kunnen opleveren dan een nieuwe netwerkarchitectuur.
Conclusie
Met de release van EfficientNet lijkt er een einde te komen aan de ImageNet classificatiebenchmark. Met de bestaande deep learning-aanpak zal er nooit een dag komen waarop we 99,999% nauwkeurigheid kunnen bereiken op ImageNet, tenzij er een andere paradigmaverschuiving plaatsvindt. Vandaar dat onderzoekers actief op zoek zijn naar nieuwe gebieden zoals zelf- of semi-toezichtgestuurd leren voor grootschalige visuele herkenning. In de tussentijd, met bestaande methoden, werd het meer een vraag voor ingenieurs en ondernemers om de real-world toepassing van deze niet-perfecte technologie te vinden. In de toekomst zal ik ook een overzicht schrijven om die echte computervisietoepassingen te analyseren die worden aangedreven door beeldclassificatie, dus blijf op de hoogte! Als u denkt dat er ook andere belangrijke papers te lezen voor beeldclassificatie, laat dan een reactie hieronder en laat het ons weten.
Originally gepubliceerd op http://yanjia.li op 31 juli 2020
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based Learning Applied to Document Recognition
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
- Sergey Ioffe, Christian Szegedy, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition
- François Chollet, Xception: Deep Learning with Depthwise Separable Convolutions
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
- Mingxing Tan, Quoc V. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Connected Convolutional Networks
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Bag of Tricks for Image Classification with Convolutional Neural Networks