
Resource Allocation is een belangrijk aspect tijdens de uitvoering van een spark job. Als het niet correct is geconfigureerd, kan een spark job volledige cluster resources verbruiken en andere applicaties hongerig maken naar resources.
Deze blog helpt om de basis flow in een Spark Application te begrijpen en vervolgens hoe het aantal executors, geheugen instellingen van elke executor en het aantal cores voor een Spark Job te configureren. Er zijn een paar factoren die we moeten overwegen om de optimale aantallen voor de bovenstaande drie te bepalen, zoals:
- De hoeveelheid data
- De tijd waarin een job moet worden voltooid
- Statische of dynamische toewijzing van resources
- Upstream of downstream applicatie
- Inleiding
- Stappen die betrokken zijn bij de clustermodus voor een Spark Job
- Static Allocation
- Case 1 Hardware – 6 Nodes en elke node heeft 16 cores, 64 GB RAM
- Case 2 Hardware – 6 Nodes en Elke node heeft 32 Cores, 64 GB
- Geval 3 – Wanneer meer geheugen niet nodig is voor de executors
- Samenvattende tabel
- Dynamische toewijzing
Inleiding
Laten we beginnen met een aantal basisdefinities van de termen die worden gebruikt bij het omgaan met Spark-toepassingen.
Partities : Een partitie is een kleine brok van een grote gedistribueerde dataset. Spark beheert gegevens met behulp van partities die helpt bij het parallel verwerken van gegevens met minimale data shuffle over de executors.
Task : Een taak is een eenheid van het werk dat kan worden uitgevoerd op een partitie van een gedistribueerde dataset en wordt uitgevoerd op een enkele executor. De eenheid van parallelle uitvoering is op het niveau van de taak. Alle taken binnen een enkele fase kunnen parallel worden uitgevoerd
Executor : Een executor is een enkel JVM proces dat wordt gestart voor een applicatie op een worker node. Executor voert taken uit en bewaart gegevens in het geheugen of op de schijf over hen heen. Elke applicatie heeft zijn eigen executors. Een enkele node kan meerdere executors draaien en executors voor een applicatie kunnen meerdere worker nodes overspannen. Een executor blijft in de lucht voor de
duur van de Spark Applicatie en voert de taken in meerdere threads uit. Het aantal executors voor een spark applicatie kan worden opgegeven in de SparkConf of via de flag -num-executors from command-line.
Cluster Manager : Een externe service voor het verkrijgen van resources op het cluster (bijv. standalone manager, Mesos, YARN). Spark is agnostisch ten opzichte van een cluster manager, zolang het executor processen kan verwerven en deze met elkaar kunnen communiceren. Wij zijn primair geinteresseerd in Yarn als de cluster manager. Een spark cluster kan zowel in yarn cluster als yarn-client mode draaien:
yarn-client mode – Een driver draait op client proces, Application Master wordt alleen gebruikt voor het aanvragen van resources van YARN.
yarn-cluster mode – Een driver draait binnen application master proces, client gaat weg zodra de applicatie is geinitialiseerd
Cores : Een core is een basis rekeneenheid van CPU en een CPU kan een of meer cores hebben om taken uit te voeren op een bepaald moment. Hoe meer cores we hebben, hoe meer werk we kunnen doen. In spark regelt dit het aantal parallelle taken dat een uitvoerder kan uitvoeren.
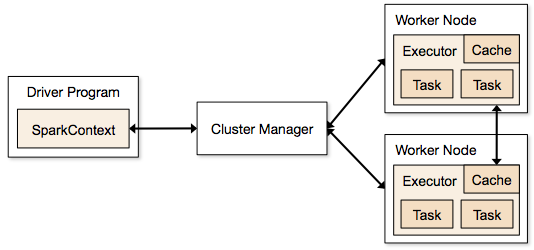
Stappen die betrokken zijn bij de clustermodus voor een Spark Job
- Vanuit de drivercode maakt SparkContext verbinding met de clustermanager (standalone/Mesos/YARN).
- Clustermanager verdeelt de resources over de andere applicaties. Elke cluster manager kan worden gebruikt, zolang de executor processen draaien en ze met elkaar communiceren.
- Spark verwerft executors op nodes in cluster. Hier krijgt elke applicatie zijn eigen executor processen.
- Applicatie code (jar/python bestanden/python egg bestanden) wordt naar executors gestuurd
- Taken worden door SparkContext naar de executors gestuurd.
Uit de bovenstaande stappen is duidelijk dat het aantal executors en hun geheugen instelling een grote rol spelen in een spark job. Running executors met te veel geheugen resulteert vaak in buitensporige garbage collection vertragingen
Nu proberen we te begrijpen, hoe de beste set van waarden te configureren om een spark job te optimaliseren.
Er zijn twee manieren waarop we de executor en core details te configureren om de Spark job. Deze zijn:
- Static Allocation – De waarden worden gegeven als onderdeel van spark-submit
- Dynamic Allocation – De waarden worden opgepikt op basis van de eis (grootte van de gegevens, hoeveelheid benodigde berekeningen) en vrijgegeven na gebruik. Hierdoor kunnen de bronnen voor andere toepassingen worden hergebruikt.
Static Allocation
Different cases are discussed varying different parameters and arriving at different combinations as per user/data requirements.
Case 1 Hardware – 6 Nodes en elke node heeft 16 cores, 64 GB RAM
Eerst op elke node is 1 core en 1 GB nodig voor Operating System en Hadoop Daemons, dus we hebben 15 cores, 63 GB RAM voor elke node
We beginnen met hoe het aantal cores te kiezen:
Aantal kernen = Gelijktijdige taken die een uitvoerder kan uitvoeren
Dus we zouden kunnen denken, meer gelijktijdige taken voor elke uitvoerder zal betere prestaties geven. Maar onderzoek toont aan dat elke applicatie met meer dan 5 gelijktijdige taken, tot een slechte show zou leiden. Dus de optimale waarde is 5.
Dit getal komt van het vermogen van een executor om parallelle taken uit te voeren en niet van het aantal cores dat een systeem heeft. Dus het getal 5 blijft hetzelfde, zelfs als we dubbele (32) cores in de CPU hebben
Aantal executors:
Komen we bij de volgende stap, met 5 als cores per executor, en 15 als totaal beschikbare cores in een node (CPU) – komen we op 3 executors per node wat 15/5 is. We moeten het aantal executors op elke node berekenen en dan het totale aantal voor de job krijgen.
Dus met 6 nodes, en 3 executors per node – krijgen we een totaal van 18 executors. Van de 18 hebben we 1 executor (java process) nodig voor Application Master in YARN. Dus het uiteindelijke aantal is 17 executors
Dit 17 is het aantal dat we geven aan spark met behulp van -num-executors tijdens het uitvoeren van spark-submit shell commando
Memory voor elke executor:
Vanuit bovenstaande stap, hebben we 3 executors per node. En beschikbare RAM op elke node is 63 GB
Dus geheugen voor elke executor in elke node is 63/3 = 21GB.
Echter is er ook klein overhead geheugen nodig om de volledige geheugenaanvraag aan YARN voor elke executor te bepalen.
De formule voor die overhead is max(384, .07 * spark.executor.memory)
Bereken die overhead: .07 * 21 (Hier is 21 berekend als boven 63/3) = 1.47
Omdat 1.47 GB > 384 MB is, is de overhead 1.07 * 21 (Hier is 21 berekend als boven 63/3) = 1.47
Omdat 1.47 GB > 384 MB is, is de overhead 1.47
.47
Neem het bovenstaande van elke 21 hierboven => 21 – 1.47 ~ 19 GB
Dus executor geheugen – 19 GB
Eindgetallen – Executors – 17, Cores 5, Executor geheugen – 19 GB
Case 2 Hardware – 6 Nodes en Elke node heeft 32 Cores, 64 GB
Aantal cores van 5 is hetzelfde voor goede concurrency zoals hierboven uitgelegd.
Aantal uitvoerders voor elke node = 32/5 ~ 6
Dus totaal uitvoerders = 6 * 6 Nodes = 36. Dan is het uiteindelijke aantal 36 – 1 (voor AM) = 35
Executor geheugen:
6 executors voor elk knooppunt. 63/6 ~ 10. Overhead is .07 * 10 = 700 MB. Dus afrondend op 1 GB als overhead, krijgen we 10-1 = 9 GB
Eindgetallen – Executors – 35, Cores 5, Executor Memory – 9 GB
Geval 3 – Wanneer meer geheugen niet nodig is voor de executors
De bovenstaande scenario’s beginnen met het aantal cores als vast te nemen en gaan over naar het aantal executors en geheugen.
Nu voor het eerste geval, als we denken dat we geen 19 GB nodig hebben, en slechts 10 GB voldoende is op basis van de datagrootte en de betrokken berekeningen, dan zijn de getallen als volgt:
Cores: 5
Aantal executors voor elke node = 3. Nog steeds 15/5 zoals hierboven berekend.
In dit stadium zou dit leiden tot 21 GB, en dan 19 zoals volgens onze eerste berekening. Maar omdat we dachten dat 10 ok is (veronderstel weinig overhead), dan kunnen we het aantal executors per node niet op 6 zetten (zoals 63/10). Want met 6 executors per node en 5 cores komt het neer op 30 cores per node, terwijl we maar 16 cores hebben. Dus moeten we ook het aantal cores voor elke executor veranderen.
Dus opnieuw rekenend,
Het magische getal 5 komt uit op 3 (elk getal kleiner dan of gelijk aan 5). Dus met 3 cores, en 15 beschikbare cores – krijgen we 5 executors per node, 29 executors ( dat is (5*6 -1)) en geheugen is 63/5 ~ 12.
Overhead is 12*.07=.84. Dus executor geheugen is 12 – 1 GB = 11 GB
Eindgetallen zijn 29 executors, 3 cores, executor geheugen is 11 GB
Samenvattende tabel
Dynamische toewijzing
Note: Bovengrens voor het aantal executors als dynamische toewijzing is ingeschakeld is oneindig. Dus dit zegt dat spark applicatie alle bronnen kan opeten als dat nodig is. In een cluster waar we andere applicaties hebben draaien en zij ook cores nodig hebben om de taken uit te voeren, moeten we ervoor zorgen dat we de cores op clusterniveau toewijzen.
Dit betekent dat we een specifiek aantal cores kunnen toewijzen voor YARN gebaseerde applicaties, gebaseerd op gebruikerstoegang. Dus we kunnen een spark_user aanmaken en dan cores (min/max) voor die gebruiker geven. Deze limieten zijn voor het delen tussen spark en andere applicaties die op YARN draaien.
Om dynamische toewijzing te begrijpen, moeten we kennis hebben van de volgende eigenschappen:
spark.dynamicAllocation.enabled – wanneer dit op true is gezet, hoeven we geen executors te noemen. De reden hiervoor is hieronder:
De statische parameternummers die we bij spark-submit opgeven, zijn voor de gehele duur van de job. Maar als dynamische toewijzing in beeld komt, zouden er verschillende stadia zijn zoals de volgende:
Wat is het aantal executors om mee te beginnen:
Initieel aantal executors (spark.dynamicAllocation.initialExecutors) om mee te beginnen
Het aantal executors dynamisch regelen:
Dan op basis van belasting (taken in afwachting) hoeveel executors aan te vragen. Dit zou uiteindelijk het aantal zijn wat we geven bij spark-submit op statische wijze. Dus zodra de initiële executor nummers zijn ingesteld, gaan we naar min (spark.dynamicAllocation.minExecutors) en max (spark.dynamicAllocation.maxExecutors) nummers.
Wanneer nieuwe executors te vragen of weg te geven huidige executors:
Wanneer vragen we nieuwe executors (spark.dynamicAllocation.schedulerBacklogTimeout) – Dit betekent dat er zijn geweest in afwachting van taken voor zo veel duur. Dus de aanvraag voor het aantal executors dat in elke ronde wordt aangevraagd, neemt exponentieel toe ten opzichte van de vorige ronde. Bijvoorbeeld, een applicatie zal 1 executor toevoegen in de eerste ronde, en dan 2, 4, 8 enzovoort executors in de volgende rondes. Op een bepaald punt komt de bovenstaande eigenschap max in beeld.
Wanneer geven we een executor weg wordt ingesteld met behulp van spark.dynamicAllocation.executorIdleTimeout.
Om te concluderen, als we meer controle over de taakuitvoeringstijd nodig hebben, monitoren de baan voor onverwachte gegevens volume de statische getallen zou helpen. Door over te gaan op dynamisch, zouden de middelen worden gebruikt op de achtergrond en de banen met onverwachte volumes zou kunnen beïnvloeden andere toepassingen.