
Gezicht tot gezicht is de manier waarop we elkaar meestal herkennen en met elkaar communiceren. De herkenning van individuele gezichten is alleen mogelijk omdat het menselijk gelaat zo enorm variabel is. De extreme gelijkenis van eeneiige tweelingen, die van elk van hun ouders dezelfde versies van elk gen erven, en dus identieke genotypen hebben, toont aan dat de verschillende gelaatstrekken waaraan wij mensen herkennen, erfelijk zijn. Dit betekent dat ze grotendeels bepaald worden door de specifieke combinaties van genetische varianten die ze van hun ouders erven. Met genetische variant bedoelen we een versie van een bepaald gen die op een bepaalde plaats in het DNA verschilt van andere versies van datzelfde gen. Het feit dat de gelaatstrekken van eeneiige tweelingen die apart van elkaar zijn opgegroeid, evenveel op elkaar lijken als die van tweelingen die samen zijn opgegroeid, ondersteunt sterk de opvatting dat milieu-effecten op gelaatstrekken normaal gesproken zeer beperkt zijn.
Gezichtstrekken, zoals de vorm van de neus, een terugwijkende kin of de ‘Habsburgse lip’, worden in families vaak van generatie op generatie doorgegeven. Ons doel was specifieke genetische varianten te identificeren die bepalend zijn voor bepaalde gelaatstrekken. Om dit te kunnen doen, wat nog niet eerder is gedaan, hebben wij ingewikkelde statistische procedures moeten gebruiken om gezichtsbeelden van menselijke vrijwilligers te analyseren.
Ons uitgangspunt was een grote verzameling 3-dimensionale gezichtsbeelden, genomen met een hoogtechnologische commerciële camera. Deze beelden leverden ons, na enige manipulatie, een definitie van elk gezicht als 30.000 punten op het oppervlak van het gezicht, effectief een 3-dimensionale kaart van het gezicht. Om de kenmerken van verschillende gezichten te vergelijken hebben we alle gezichtsbeelden ten opzichte van elkaar over elkaar gelegd. Dit wordt gedaan door eerst de beelden te overlappen ten opzichte van een aantal oriëntatiepunten, zoals op het puntje van de neus of in de hoeken van de ogen of de mond. Deze procedure is vergelijkbaar met die van Francis Galton, een pionier op het gebied van de studie van gezichten en tweelingen, bijna 150 jaar geleden, maar nu beschikken wij over gesofisticeerde computerhulpmiddelen en hoogtechnologische camera’s die de mate waarin wij alle beelden met elkaar kunnen overlappen, enorm verbeteren.
We hebben vrijwilligers uit drie bronnen gebruikt: a) 1832 unieke vrijwilligers uit onze zeer goed gekarakteriseerde People of the British Isles (PoBI) studie, b) 1567 unieke tweelingen uit het TwinsUK cohort, ongeveer evenveel identieke als niet-identieke tweelingen, en c) 33 afbeeldingen van Oost-Aziaten, voornamelijk Chinezen.
Het hebben van de gezichtsopnamen van de tweelingen maakte onze volgende belangrijke stap in de analyse mogelijk, namelijk het identificeren van de gelaatstrekken die waarschijnlijk een hoge erfelijkheidsgraad hebben. Twee individuen die een eeneiige tweeling zijn, hebben dezelfde set genetische varianten (DNA-sequenties). Het zijn deze varianten die hun gelaatstrekken bepalen en resulteren in sterk gelijkende gezichten. Gelaatstrekken worden bepaald door groepen punten op het gezicht, zoals de heuvels en dalen op een driedimensionale kaart.
De plaats van een punt op een gezichtsfoto van een lid van een eeneiig tweelingpaar moet sterk lijken op de plaats van het corresponderende punt op de foto van de andere tweeling. De mate waarin het verschilt zal een maat zijn voor de niet-genetische omgevingsinvloeden op de positie van dit punt op het gezicht. Daarentegen kunnen twee individuen die niet-identieke tweelingen zijn, verschillende genetische varianten hebben die ten minste enkele van hun gelaatstrekken bepalen. De positie van hetzelfde punt op een gezichtsbeeld van een van de afzonderlijke niet-identieke tweelingen zal daarom de neiging hebben niet zo dicht te liggen bij de positie van het corresponderende punt op een beeld van de andere tweeling dan wanneer zij eeneiige tweelingen zouden zijn. De mate waarin de punten verder uit elkaar liggen bij de niet-identieke tweelingen dan bij de identieke tweelingen is een maat voor de genetische invloeden op dit punt, die genetici de erfelijkheidsgraad noemen. Met behulp van andere complexe statistische procedures kunnen we elk punt op het gezicht wegen naar zijn erfelijkheidsgraad, die op deze manier wordt gemeten.
Het effect van deze weging is te zien in figuur 1, waarin we de frequenties hebben uitgezet van punten op het gezichtsprofiel die verschillende erfelijkheidsgraden hebben. De mate van erfelijkheid voor een bepaalde positie varieert van 1 als de meting altijd precies hetzelfde is bij paren van eeneiige tweelingen, maar verschillend bij
niet-identieke tweelingen, tot 0 als de verschillen tussen eeneiige tweelingen gelijk zijn aan die tussen niet-identieke tweelingen, en dus in feite allemaal
niet-genetisch, voornamelijk door de omgeving bepaald zijn. De rode kolommen zijn voor de gewogen waarden, de blauwe voor de oorspronkelijke waarden en de paarse voor de overlapping. Het rode profiel is gemiddeld duidelijk hoger en veel smaller dan het blauwe, waaruit het gunstige effect van de weging blijkt.
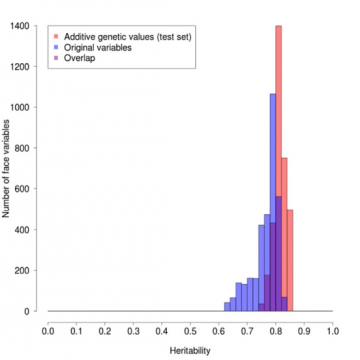
Figuur 1: Vergelijking van de erfelijkheidsgraden van de profielen voor de oorspronkelijke versus de erfelijkheidsgewogen waarden.
De volgende uitdaging is het definiëren van de gelaatstrekken die voor de genetische analyse moeten worden gebruikt, op basis van groepen van geassocieerde punten. Hiervoor gebruiken wij de met de erfelijkheidscoëfficiënt gewogen punten, in de veronderstelling dat dit een kenmerk oplevert dat over het geheel genomen waarschijnlijk erfelijker is dan het kenmerk dat verkregen wordt met de ongewogen punten. De gewogen punten werden gebruikt voor wat statistici een PCA noemen, wat staat voor Principal Components Analysis. Dit is een manier om uit de gegevens de kenmerken te halen die het meest variabel zijn. Elke PCA, en dat kunnen er wel 50 of meer zijn voor complexe gegevens zoals de gezichtsbeelden, is op zichzelf een maat voor een gelaatstrek, analoog aan de afstand tussen de ogen, maar die in feite verschillende metingen op basis van een groep punten combineert tot één enkele waarde.
Tot dusver hebben wij bij het definiëren van gelaatstrekken geen gebruik gemaakt van specifieke genetische informatie. Wij beschikken over op DNA gebaseerde genetische informatie over ongeveer 500.000 varianten voor elk van ongeveer 1500 individuen van onze PoBI-vrijwilligers van wie wij beelden hebben en voor een vergelijkbaar aantal van de TwinsUK-vrijwilligers met beelden. De volgende stap was daarom het zoeken naar specifieke genetische varianten die significant samenhingen met onze op PCA gebaseerde gelaatstrekken.
Onze benadering van de genetische analyse is gebaseerd op het idee dat verschillen in gelaatstrekken moeten worden geanalyseerd als discrete, individueel identificeerbare kenmerken, niet als een kwantitatieve maat, zoals de lengte van een persoon. Wij kunnen een persoon niet herkennen aan zijn lengte alleen of aan een enkel kwantitatief gezichtskenmerk, zoals de afstand tussen de ogen of de hoogte-breedteverhouding van het gezicht. Wij pakken dit aan door ons te concentreren op die individuen die zich in de uiterste bovenste of onderste 10% van elk van de door de PCA gegeven waarden bevinden en ons af te vragen of zij een of meer van de 500.000 genetische markers meer delen dan de individuen die zich niet in deze uitersten bevinden. Wij gebruikten de vrijwilligers van de “People of the British Isles” om uit de 500.000 geteste genvarianten kandidaat-genvarianten te kiezen voor verdere analyse op basis van de significantie van het verschil tussen de extremen en de niet-extremen en op basis van de grootte van dit verschil. Vervolgens vroegen we of één van deze kandidaat-effecten gerepliceerd werd in de ongeveer 1500 vrijwilligers van TwinsUK. Op deze manier hebben we drie specifieke en gerepliceerde genetische varianten met relatief grote effecten geïdentificeerd, twee voor kenmerken van gezichtsprofielen en één voor de regio rond de ogen. Elk van deze drie varianten heeft
een partner met een andere DNA-sequentie op dezelfde kritieke positie, en in elk van deze gevallen heeft de positief geassocieerde variant een PoBI-populatiefrequentie van ongeveer 10%, waarbij de partner de hogere frequentie van ongeveer 90% heeft. We noemen de geassocieerde variant a en zijn partner A, en aangezien genen in paren voorkomen, zijn er dus drie combinaties van deze varianten, aa, Aa en AA.
De eerste van deze varianten, gevonden in een gen dat PCDH15 heet, verhoogde de kans op het hebben van de vrouwelijke kenmerken die in figuur 2C worden getoond met een factor van meer dan 7 bij Britse vrouwen die beide exemplaren van de variant droegen (aa), vergeleken met degenen die slechts één (Aa) of geen exemplaren (AA) van de variant hadden. Deze variant is ook geassocieerd met kenmerken die verschillen tussen de Britse en de Oost-Aziatische vrouwelijke vrijwilligers. Let op het omgekeerde uiteinde van de neus en de bovenlip en de teruggetrokken kin in figuur 2A, het gemiddelde van de Chinese gezichten, en in figuur 2B, de meer Chinese groep van de PoBI-individuen, en contrasteer dit met figuur 2C. Het product van het PCDH15-gen wordt aangetroffen in de reukcellen en het kraakbeen van de neus van zich ontwikkelende muizen, wat consistent is met
een mogelijk effect op de neus van de variant die we bij mensen hebben gevonden.
De tweede variant, in het gen MBTPS1, is geassocieerd met het gezichtsverschil dat in figuur 3 wordt getoond. Dit verschil werd waargenomen bij vrouwen, en de kenmerkende subset van gezichten droeg beide kopieën van de variant (aa). In dit geval is de genetische variant die geassocieerd is met het bovenste extreme fenotype (figuur 3A), aanwezig (vermoedelijk als aa) in de Afrikaanse Groene Aap, Makaak en Olijfbaviaan, terwijl zijn partner, de gewone variant, aanwezig is (vermoedelijk als AA) in de Orang-oetan, Gorilla, Chimpansee en Marmoset, wat suggereert dat dit variantverschil geassocieerd kan zijn met de gezichtsverschillen tussen deze primaatgroepen.
De derde variant, in het gen genaamd TMEM163, is bij beide geslachten geassocieerd met een verschil in de ogen, zoals blijkt uit figuur 4. Een defecte versie van dit gen kan een rol spelen bij de ziekte mucolipidosis type IV, een aandoening die soms gepaard gaat met gezichtsafwijkingen, vooral rond de oogleden. In onze studies, is het de subset van individuen die beide exemplaren van de variant (aa) die wordt geassocieerd met de bovenste extreme, getoond in figuur 4A. Merk op dat de oogbreedte en ooghoogte (van de onderkant van de wenkbrauw tot de bovenkant van het ooglid) beide groter zijn in het bovenste uiterste dan in het onderste uiterste.
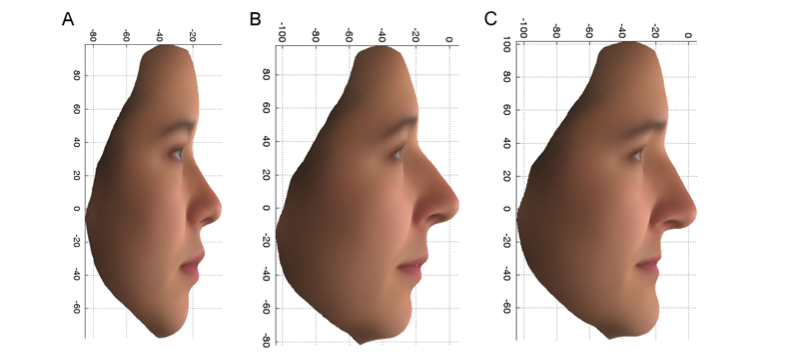
Figuur 2: PC2-profiel: Gemiddelde gezichten, met gebruikmaking van de oorspronkelijke variabelen, voor 14 Oost-Aziatische vrouwen (A) en de bovenste 10% (meer Oost-Aziatisch) (B) en onderste 10% (meer Europees) (C) extremen van de PoBI-vrouwen.
Elke van de drie genetische varianten die we in verband hebben kunnen brengen met een specifieke gelaatstrek verhoogt de kans op het hebben van de specifieke gelaatstrek met
een factor van meer dan 7 bij die Britse vrijwilligers die beide kopieën (aa) van de variant dragen, vergeleken met degenen die slechts één (Aa) of geen (AA) kopieën van de variant hebben.

Figuur 3: PC7-profiel: Gemiddelde profielen van vrouwelijke gezichten, met gebruikmaking van de oorspronkelijke variabelen, voor de bovenste variant geassocieerde 10% (A) en onderste 10% (C) extremen en het algemene gemiddelde (B).

Figuur 4: PC1-ogen: Gemiddelde oogfenotypes, gebruik makend van de originele variabelen, voor de bovenste 10% (A), de onderste 10% (C) extremen, en het algemene gemiddelde (B).
Het succes waarmee we deze genetische varianten vinden, hangt grotendeels af van ons vermogen om op basis van de tweelinggegevens gelaatstrekken te identificeren die een hoge erfelijkheidsgraad hebben, en van de keuze van extremen voor het bestuderen van de associaties tussen genetische varianten. Het lijkt waarschijnlijk dat in de toekomst veel meer specifieke en relatief grote effecten van genetische varianten op menselijke gelaatstrekken zullen worden gevonden met behulp van benaderingen zoals wij hebben beschreven. Dit effent de weg naar het ontrafelen van de moleculaire mechanismen waarmee genetische varianten de buitengewone variabiliteit in het menselijk gelaatsuiterlijk bepalen.