
Het eerste wat we moeten begrijpen is de aard van variabelen en hoe variabelen worden gebruikt in het ontwerp van een studie om de onderzoeksvragen te beantwoorden. In dit hoofdstuk leert u:
- verschillende soorten variabelen in kwantitatieve studies,
- vraagstukken rond de analyse-eenheid.
Inzicht in kwantitatieve variabelen
De wortel van het woord variabele is gerelateerd aan het woord “variëren,” wat ons moet helpen begrijpen wat variabelen kunnen zijn. Variabelen zijn elementen, entiteiten of factoren die kunnen veranderen (variëren); bijvoorbeeld, de buitentemperatuur, de benzineprijs per gallon, iemands gewicht, en de stemming van personen in uw uitgebreide familie zijn allemaal variabelen. Met andere woorden, ze kunnen verschillende waarden hebben onder verschillende omstandigheden of voor verschillende mensen.
We gebruiken variabelen om eigenschappen of factoren van belang te beschrijven. Voorbeelden hiervan zijn het aantal leden in verschillende huishoudens, de afstand tot gezonde voedingsbronnen in verschillende buurten, de verhouding tussen docenten sociaal werk en studenten in een BSW- of MSW-opleiding, het percentage personen uit verschillende raciale/etnische groepen dat in de gevangenis zit, de kosten van vervoer om diensten van een sociaal werkprogramma te ontvangen, of het percentage kindersterfte in verschillende provincies. In sociaal werk interventie-onderzoek, kunnen variabelen kenmerken van de interventie (intensiteit, frequentie, duur) en uitkomsten geassocieerd met de interventie omvatten.
Demografische Variabelen. Maatschappelijk werkers zijn vaak geïnteresseerd in wat we demografische variabelen noemen. Demografische variabelen worden gebruikt om kenmerken van een populatie, groep, of steekproef van de populatie te beschrijven. Voorbeelden van vaak toegepaste demografische variabelen zijn
- leeftijd,
- etniciteit,
- nationale herkomst,
- religieuze gezindheid,
- gender,
- seksuele geaardheid,
- burgerlijke staat/relatiestatus,
- werkstatus,
- politieke gezindheid,
- geografische ligging,
- onderwijsniveau, en
- inkomen.
Op een meer macroniveau omvat de demografie van een gemeenschap of organisatie vaak de omvang ervan; organisaties worden vaak gemeten in termen van hun totale budget.
Onafhankelijke en afhankelijke variabelen. De manier waarop onderzoekers over onderzoeksvariabelen denken, heeft belangrijke gevolgen voor de opzet van een onderzoek. Onderzoekers nemen beslissingen over de vraag of zij als onafhankelijke variabelen dan wel als afhankelijke variabelen moeten fungeren. Dit onderscheid is niet iets dat inherent is aan een variabele, het is gebaseerd op de manier waarop de onderzoeker elke variabele wenst te definiëren. Onafhankelijke variabelen zijn die variabelen die je zou kunnen beschouwen als de gemanipuleerde “input”-variabelen, terwijl de afhankelijke variabelen die variabelen zijn waar het effect of de “output” van die inputvariatie zou worden waargenomen.
Opzettelijke manipulatie van de “input”- (onafhankelijke) variabele is niet altijd aan de orde. Neem het voorbeeld van een onderzoek in Zweden naar de relatie tussen het slachtoffer zijn geweest van kindermishandeling en latere afwezigheid op de middelbare school: niemand manipuleerde opzettelijk of de kinderen slachtoffer zouden worden van kindermishandeling (Hagborg, Berglund, & Fahlke, 2017). De onderzoekers stelden de hypothese dat natuurlijk voorkomende verschillen in de inputvariabele (geschiedenis van kindermishandeling) geassocieerd zouden zijn met systematische variatie in een specifieke uitkomstvariabele (schoolverzuim). In dit geval was de onafhankelijke variabele een geschiedenis van kindermishandeling, en de afhankelijke variabele was het schoolverzuimresultaat. Met andere woorden, de onafhankelijke variabele wordt door de onderzoeker verondersteld variatie of verandering in de afhankelijke variabele te veroorzaken. Zo zou het eruit kunnen zien in een diagram waarin “x” de onafhankelijke variabele is en “y” de afhankelijke variabele (let op: u hebt deze aanduiding eerder gezien, in hoofdstuk 3, toen we oorzaak- en gevolglogica bespraken):

Voor een ander voorbeeld, denk aan onderzoek dat aangeeft dat het slachtoffer zijn van kindermishandeling geassocieerd is met een hoger risico op middelengebruik tijdens de adolescentie (Yoon, Kobulsky, Yoon, & Kim, 2017). De onafhankelijke variabele in dit model zou het hebben van een geschiedenis van kindermishandeling zijn. De afhankelijke variabele zou het risico op middelengebruik tijdens de adolescentie zijn. Dit voorbeeld is nog uitgebreider omdat het de route specificeert waarlangs de onafhankelijke variabele (kindermishandeling) zijn effecten op de afhankelijke variabele (middelengebruik in de adolescentie) zou kunnen opleggen. De auteurs van de studie toonden aan dat posttraumatische stress (PTS) een verband vormde tussen kindermishandeling (fysiek en seksueel) en middelengebruik tijdens de adolescentie.

Neem even de tijd om de volgende activiteit te voltooien.
Typen kwantitatieve variabelen
Er zijn ook andere zinvolle manieren om over variabelen van belang na te denken. Laten we eens kijken naar verschillende kenmerken van variabelen die in kwantitatieve onderzoeken worden gebruikt. Hier onderzoeken wij kwantitatieve variabelen als zijnde categorisch, ordinaal of interval van aard. Deze kenmerken hebben implicaties voor zowel meting als gegevensanalyse.
Categorische variabelen. Sommige variabelen kunnen waarden aannemen die variëren, maar niet op een zinvolle numerieke manier. In plaats daarvan kunnen zij worden gedefinieerd in termen van de categorieën die mogelijk zijn. Logischerwijs worden deze variabelen categorische variabelen genoemd. Statistische software en handboeken verwijzen soms naar variabelen met categorieën als nominale variabelen. Nominaal kan worden opgevat in termen van de Latijnse stam “nom”, die “naam” betekent, en niet moet worden verward met getal. Nominaal betekent hetzelfde als categorisch bij de beschrijving van variabelen. Met andere woorden, categorische of nominale variabelen worden aangeduid met de namen of labels van de vertegenwoordigde categorieën. Bijvoorbeeld, de kleur van de laatste auto waarin u hebt gereden zou een categorische variabele zijn: blauw, zwart, zilver, wit, rood, groen, geel, of andere zijn categorieën van de variabele die we autokleur zouden kunnen noemen.
Wat belangrijk is bij categorische variabelen is dat deze categorieën geen relevante numerieke volgorde of rangschikking hebben. Er is geen numeriek verschil tussen de verschillende autokleuren, of verschil tussen “ja” of “nee” als de categorieën bij het beantwoorden van de vraag of je in een blauwe auto hebt gereden. Er is geen impliciete volgorde of hiërarchie in de categorieën “Hispanic of Latino” en “Niet Hispanic of Latino” in een etniciteitsvariabele; evenmin is er een relevante volgorde in categorieën van variabelen zoals geslacht, de staat of geografische regio waar iemand woont, of iemands woning eigendom is of gehuurd wordt.
Als een onderzoeker zou besluiten getallen te gebruiken als symbolen voor categorieën in een dergelijke variabele, dan zijn de getallen arbitrair – elk getal is in wezen gewoon een andere, kortere naam voor elke categorie. De variabele geslacht zou bijvoorbeeld op de volgende manieren kunnen worden gecodeerd, en het zou geen verschil uitmaken, zolang de code maar consequent werd toegepast.
| Coding Option A | Variable Categories | Coding Option B |
|---|---|---|
| 1 | mannelijk | 2 |
| 2 | vrouwelijk | 1 |
| 3 | anders dan man of vrouw alleen | 4 |
| 4 | liever niet antwoorden | 3 |
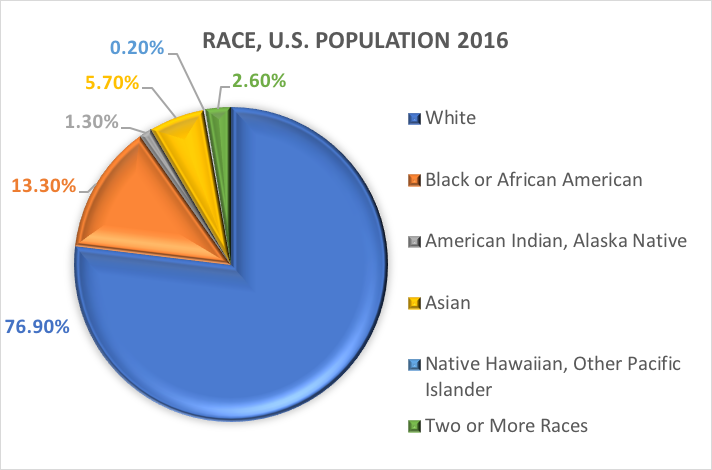
Ras en etniciteit.Een van de meest onderzochte categorische variabelen in sociaal werk en sociaal-wetenschappelijk onderzoek is de demografische die verwijst naar het ras en/of de etnische achtergrond van een persoon. In veel studies wordt gebruik gemaakt van de categorieën die in eerdere rapporten van het U.S. Census Bureau zijn gespecificeerd. Dit is wat het U.S. Census Bureau te zeggen heeft over de twee verschillende demografische variabelen, ras en etniciteit (https://www.census.gov/mso/www/training/pdf/race-ethnicity-onepager.pdf):
Wat is ras? Het Census Bureau definieert ras als de zelfidentificatie van een persoon met een of meer sociale groepen. Een persoon kan zich blank, zwart of Afro-Amerikaans, Aziatisch, Amerikaans-Indiaans en Alaska Native, Native Hawaiian en andere Pacific Islander, of een ander ras noemen. Enquête-respondenten kunnen meerdere rassen opgeven.
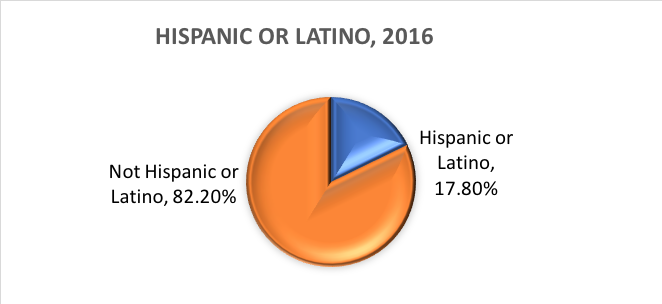
Wat is etniciteit? Etniciteit bepaalt of een persoon al dan niet van Spaanse afkomst is. Om deze reden wordt etniciteit opgesplitst in twee categorieën, Hispanic of Latino en Niet Hispanic of Latino. Hispanics kunnen als elk ras worden gerapporteerd.
Met andere woorden, het Census Bureau definieert twee categorieën voor de variabele die etniciteit heet (Hispanic of Latino en Not Hispanic of Latino), en zeven categorieën voor de variabele die ras heet. Hoewel deze variabelen en categorieën vaak worden toegepast in sociaal-wetenschappelijk en sociaal werkonderzoek, zijn ze niet zonder kritiek.
Gebaseerd op deze categorieën, is dit wat naar schatting waar is van de Amerikaanse bevolking in 2016:
Dichotome variabelen.Er bestaat een speciale categorie categorische variabele met implicaties voor bepaalde statistische analyses. Categorische variabelen die uit precies twee opties bestaan, niet meer en niet minder, worden dichotome variabelen genoemd. Een voorbeeld is de dichotomie van Hispanic/Latino en Non-Hispanic/Non-Latino ethnicity van het U.S. Census Bureau. Een ander voorbeeld is de wens van onderzoekers om mensen die de behandeling afmaken te vergelijken met degenen die afhaken voordat ze de behandeling afmaken. Met de twee categorieën, voltooid of niet voltooid, is deze variabele voor het voltooien van de behandeling niet alleen categorisch, maar ook dichotomisch. Variabelen waarbij individuen met “ja” of “nee” antwoorden, zijn ook dichotoom van aard.
De vroegere traditie om het geslacht als mannelijk of vrouwelijk te behandelen, is een ander voorbeeld van een dichotome variabele. Er zijn echter zeer sterke argumenten om gender niet langer op deze dichotome manier te behandelen: een grotere verscheidenheid aan genderidentiteiten is aantoonbaar relevant in het maatschappelijk werk voor personen wier identiteit niet overeenkomt met de dichotome (ook wel binaire) categorieën van man/vrouw of man/vrouw. Deze omvatten categorieën zoals agender, androgyn, bigender, cisgender, gender expansive, gender fluid, gender questioning, queer, transgender, en anderen.
Ordinale Variabelen. In tegenstelling tot deze categorische variabelen, hebben de categorieën van een variabele soms wel een logische numerieke volgorde of rangschikking. Ordinaal verwijst per definitie naar een positie in een reeks. Variabelen met numeriek relevante categorieën worden ordinale variabelen genoemd. Zo is er bijvoorbeeld een impliciete volgorde van categorieën van minst naar meest bij de variabele onderwijsniveau. De categorieën van de U.S. Census data categorieën voor deze ordinale variabele zijn:
- none
- 1st-4thgrade
- 5th-6thgrade
- 7th-8thgrade
- 9thgrade
- 10thgrade
- 11thgrade
- high school graduate
- some college, geen diploma
- associate’s degree, Beroep
- associate’s degree academisch
- bachelor’s degree
- master’s degree
- professional degree
- doctoral degree
Als we kijken naar de schattingsgegevens van het Census Bureau uit 2016 voor deze variabele, kunnen we zien dat er meer vrouwen dan mannen zijn in de categorie die een bachelor’s degree hebben behaald: van de 47.718.000 personen in deze categorie, waren 22.485.000 mannen en 25.234.000 vrouwen. Terwijl dit genderpatroon ook gold voor degenen die een masterdiploma behaalden, was het patroon omgekeerd voor degenen die een doctorsgraad behaalden: meer mannen dan vrouwen behaalden dit hoogste onderwijsniveau. Het is ook interessant op te merken dat er meer vrouwen dan mannen waren aan de onderkant van het spectrum: 441.000 vrouwen meldden geen opleiding tegenover 374.000 mannen.
Hier is een ander voorbeeld van het gebruik van ordinale variabelen in sociaal werk onderzoek: wanneer mensen zich laten behandelen voor een probleem van alcoholmisbruik, willen sociaal werkers misschien weten of dit hun eerste, tweede, derde, of wat voor genummerde serieuze poging is om hun drinkgedrag te veranderen. Deelnemers aan een studie die behandelingsbenaderingen voor alcoholgebruiksstoornissen vergeleek, meldden dat de interventiestudie hun eerste tot hun elfde significante veranderingspoging was (Begun, Berger, Salm-Ward, 2011). Deze veranderingspogingvariabele heeft implicaties voor hoe maatschappelijk werkers gegevens kunnen interpreteren die een interventie evalueren die niet voor alle betrokkenen de eerste poging was.
Rbeoordelingsschalen. Beschouw een ander, maar veelgebruikt type ordinale variabele: beoordelingsschalen. Onderzoekers op het gebied van sociale wetenschappen, gedragswetenschappen en maatschappelijk werk vragen studiedeelnemers vaak een beoordelingsschaal te gebruiken om hun kennis, attitudes, overtuigingen, meningen, vaardigheden of gedrag te beschrijven. Omdat de categorieën op zo’n schaal een volgorde hebben (van meest naar minst of van minst naar meest), noemen we dit ordinale variabelen.

Voorbeelden zijn onder meer het laten beoordelen van deelnemers:
- hoezeer zij het eens of oneens zijn met bepaalde uitspraken (helemaal niet tot extreem veel);
- hoe vaak zij zich bezighouden met bepaald gedrag (nooit tot altijd);
- hoe vaak zij zich bezighouden met bepaald gedrag (per uur, dagelijks, wekelijks, maandelijks, jaarlijks, of minder vaak);
- de kwaliteit van iemands prestaties (slecht tot uitstekend);
- hoe tevreden ze waren met hun behandeling (zeer ontevreden tot zeer tevreden)
- hun mate van vertrouwen (zeer laag tot zeer hoog).
Intervalvariabelen. Nog andere variabelen nemen waarden aan die op een zinvolle numerieke wijze variëren. Uit onze lijst van demografische variabelen is leeftijd een veel voorkomend voorbeeld. De numerieke waarde die aan een individuele persoon wordt toegekend, geeft het aantal jaren aan sinds de persoon werd geboren (in het geval van zuigelingen kan de numerieke waarde dagen, weken of maanden sinds de geboorte aangeven). Hier zijn de mogelijke waarden voor de variabele geordend, zoals bij de ordinale variabelen, maar er wordt een groot verschil ingevoerd: de aard van de intervallen tussen de mogelijke waarden. Bij intervalvariabelen is de “afstand” tussen aangrenzende mogelijke waarden gelijk. Sommige statistische softwarepakketten en leerboeken gebruiken de term schaalvariabele: dit is precies hetzelfde als wat wij een intervalvariabele noemen.
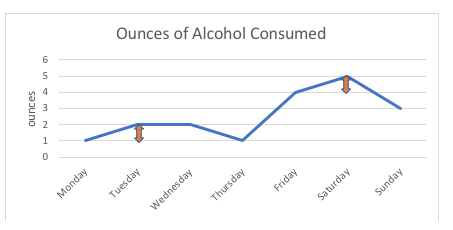
In de onderstaande grafiek bijvoorbeeld is het verschil van 1 ons tussen deze persoon die 1 ons of 2 ons alcohol gebruikt (maandag, dinsdag) precies hetzelfde als het verschil van 1 ons tussen het consumeren van 4 ons of 5 ons (vrijdag, zaterdag). Als we de mogelijke punten op de schaal schetsen, zouden ze allemaal op gelijke afstand van elkaar liggen; het interval tussen twee willekeurige punten wordt gemeten in standaardeenheden (ounces, in dit voorbeeld).
Met ordinale variabelen, zoals een waarderingsschaal, kan niemand met zekerheid zeggen dat de “afstand” tussen de antwoordopties “nooit” en “soms” dezelfde is als de “afstand” tussen “soms” en “vaak”, zelfs niet als we getallen zouden gebruiken om deze antwoordopties te rangschikken. De waarderingsschaal blijft dus ordinaal, niet interval.
Wat een beetje verwarrend kan worden, is dat bepaalde statistische softwareprogramma’s, zoals SPSS, verwijzen naar een intervalvariabele als een “schaal”-variabele. Veel variabelen die in sociaal-wetenschappelijk onderzoek worden gebruikt, zijn zowel geordend als hebben gelijke afstanden tussen de punten. Neem bijvoorbeeld de variabele geboortevolgorde. Deze variabele is interval omdat:
- de mogelijke waarden geordend zijn (bv. het kind van de derde geboorte kwam na het kind van de eerste en tweede geboorte en vóór het kind van de vierde geboorte), en
- de “afstanden” of intervallen worden gemeten in equivalente eenheden van één persoon.
Continue variabelen. Er bestaat een speciaal type numerieke intervalvariabele dat we continue variabelen noemen. Een variabele als leeftijd kan worden behandeld als een continue variabele. Leeftijd is ordinaal van aard, omdat hogere getallen iets betekenen ten opzichte van kleinere getallen. Leeftijd voldoet ook aan onze criteria om een intervalvariabele te zijn als we hem meten in jaren (of maanden of weken of dagen) omdat hij ordinaal is en er dezelfde “afstand” is tussen 15 en 30 jaar oud zijn als tussen 40 en 55 jaar oud zijn (15 kalenderjaren). Wat dit een continue variabele maakt, is dat er ook mogelijke, zinvolle “breukpunten” zijn tussen twee intervallen. Een persoon kan bijvoorbeeld 20½ (20,5) of 20¼ (20,25) of 20¾ (20,75) jaar oud zijn; we zijn niet beperkt tot alleen de gehele getallen voor leeftijd. Wanneer we daarentegen naar de geboortevolgorde kijken, kunnen we geen betekenisvolle fractie van een persoon tussen twee posities op de schaal hebben.
Het speciale geval van inkomen. Een van de meest misbruikte variabelen in sociaal-wetenschappelijk en maatschappelijk werk onderzoek is de variabele met betrekking tot inkomen. Beschouw een voorbeeld over het inkomen van een huishouden (ongeacht het aantal personen in het huishouden). Deze variabele kan categorisch (nominaal), ordinaal, of interval (schaal) zijn, afhankelijk van hoe ermee wordt omgegaan.
Categorisch voorbeeld: Afhankelijk van de aard van de onderzoeksvragen, zou een onderzoeker er eenvoudigweg voor kunnen kiezen de dichotome categorieën “voldoende middelen” en “onvoldoende middelen” te gebruiken voor het classificeren van huishoudens, op basis van een of andere standaardberekeningsmethode. Deze kunnen “arm” en “niet arm” worden genoemd als een armoedegrens wordt gebruikt om huishoudens te categoriseren. Deze verschillende categorieën van de inkomensvariabele zijn niet zinvol numeriek geordend, zodat het een categorische variabele is.
Ordinaal Voorbeeld: Categorieën voor het classificeren van huishoudens kunnen worden geordend van laag naar hoog. Deze categorieën voor het jaarinkomen zijn bijvoorbeeld gebruikelijk in marktonderzoek:
- Lager dan $25.000.
- $25.000 tot $34.999.
- $35.000 tot $49.999.
- $50.000 tot $74.999.
- $75.000 tot $99.999.
- $100.000 tot $149.999.
- $150.000 tot $199.999.
- $200.000 of meer.
Merk op dat de categorieën niet even groot zijn – de “afstand” tussen categorieënparen is niet altijd even groot. Ze beginnen in stappen van ongeveer $10.000, gaan naar stappen van $25.000, en eindigen in stappen van ongeveer $50.000.
Interval Voorbeeld. Als een onderzoeker deelnemers aan een studie vraagt een reëel bedrag in dollars op te geven voor het huishoudinkomen, zouden we een intervalvariabele zien. De mogelijke waarden zijn gerangschikt en het interval tussen mogelijke aangrenzende eenheden is $1 (zolang geen dollarfracties of centen worden gebruikt). Een inkomen van $10.452 is dus even ver op een continuüm van $9.452 en $11.452 – $1.000 in beide richtingen.

Het speciale geval van leeftijd. Net als inkomen kan “leeftijd” in verschillende studies verschillende betekenissen hebben. Leeftijd is meestal een indicator van de “tijd sinds de geboorte”. We kunnen de leeftijd van een persoon berekenen door een variabele voor de geboortedatum af te trekken van de meetdatum (de datum van vandaag min de geboortedatum). Voor volwassenen wordt de leeftijd gewoonlijk gemeten in jaren, waarbij de aangrenzende mogelijke waarden in eenheden van 1 jaar van elkaar verwijderd zijn: 18, 19, 20, 21, 22, enzovoort. De leeftijdsvariabele zou dus een continue soort intervalvariabele kunnen zijn.
Het kan echter voorkomen dat een onderzoeker leeftijdsgegevens wil samenvatten in geordende categorieën of leeftijdsgroepen. Deze zouden nog steeds ordinaal zijn, maar misschien niet langer interval als de incrementen tussen mogelijke waarden geen equivalente eenheden zijn. Als we bijvoorbeeld meer geïnteresseerd zijn in leeftijd die specifieke menselijke ontwikkelingsperioden vertegenwoordigt, zijn de leeftijdsintervallen misschien niet gelijk in spanwijdte tussen de leeftijdscriteria. Mogelijk zouden zij kunnen zijn:
- Infancy (geboorte tot 18 maanden)
- Toddging (18 maanden tot 2 ½ jaar)
- Preschool (2 ½ tot 5 jaar)
- Schoolleeftijd (6 tot 11 jaar)
- Adolescentie (12 tot 17 jaar)
- Uitgebloeide volwassenheid (18 tot 25 jaar)
- Volwassenheid (26 tot 45 jaar)
- Midden-volwassenheid (46 tot 60 jaar)
- Jong-oud-volwassenheid (60 tot 74 jaar)
- middel-oud-volwassenheid (75 tot 84 jaar)
- oud-oud-volwassenheid (85 jaar of ouder)
Leeftijd kan zelfs worden behandeld als een strikt categorische (niet-ordinale) variabele. Bijvoorbeeld, als de variabele van belang is of iemand de wettelijke leeftijd heeft om alcohol te drinken (21 jaar of ouder), of niet. We hebben twee categorieën – voldoet wel of niet aan de criteria voor de wettelijke drinkleeftijd in de Verenigde Staten – en elk van beide kan worden gecodeerd met een “1” en de andere met een “0” of een “2” zonder verschil in betekenis.
Wat is het “juiste” antwoord op de vraag hoe leeftijd (of inkomen) moet worden gemeten? Het antwoord is: “Dat hangt ervan af.” Waar het van afhangt is de aard van de onderzoeksvraag: welke conceptualisering van leeftijd (of inkomen) is het meest relevant voor de studie die wordt opgezet.
Alphanumerieke Variabelen. Tenslotte zijn er gegevens die niet in een van deze classificaties passen. Soms is de ons bekende informatie een adres of een telefoonnummer, een voor- of achternaam, een postcode of andere zinsneden. Dit soort informatie wordt soms alfanumerieke variabelen genoemd. Neem bijvoorbeeld de variabele “adres”: het adres van een persoon kan bestaan uit numerieke tekens (het huisnummer) en lettertekens (die de naam van de straat, de stad en de staat spellen), zoals 1600 Pennsylvania Ave. NW, Washington, DC, 20500.

In werkelijkheid hebben we verschillende variabelen in dit adresvoorbeeld:
- het straatadres: 1600 Pennsylvania Ave.
- de stad (en “staat”): Washington, DC
- de postcode: 20500.
Dit soort informatie staat niet voor specifieke kwantitatieve categorieën of waarden met een systematische betekenis in de gegevens. Zij worden in bepaalde softwarepakketten ook wel “string”-variabelen genoemd, omdat zij uit een reeks symbolen bestaan. Om bruikbaar te zijn voor een onderzoeker, zou een dergelijke variabele moeten worden omgezet of gehercodeerd in zinvolle waarden.
Een opmerking over analyse-eenheden
Een belangrijk ding om in gedachten te houden bij het denken over variabelen is dat gegevens kunnen worden verzameld op veel verschillende niveaus van waarneming. De bestudeerde elementen kunnen individuele cellen, orgaansystemen of personen zijn. Of, het niveau van observatie kan paren van individuen zijn, zoals paren, broers en zussen, of ouder-kind dyades. In dit geval kan de onderzoeker informatie over het paar verzamelen bij elk individu, maar kijkt hij naar de gegevens van elk paar. We zouden dus zeggen dat de eenheid van analyse het paar of de dyade is, niet elke individuele persoon. De analyse-eenheid kan ook een grotere groep zijn: er kunnen bijvoorbeeld gegevens worden verzameld van alle leerlingen in hele klaslokalen wanneer de analyse-eenheid de klaslokalen in een school of schoolsysteem zijn. Of de analyse-eenheid kan op het niveau van buurten, programma’s, organisaties, provincies, staten of zelfs naties liggen. Veel van de variabelen die worden gebruikt als indicatoren van voedselzekerheid op het niveau van gemeenschappen, zoals betaalbaarheid en toegankelijkheid, zijn bijvoorbeeld gebaseerd op gegevens die zijn verzameld bij individuele huishoudens (Kaiser, 2017). De analyse-eenheid in studies waarin deze indicatoren worden gebruikt, zouden de gemeenschappen zijn die worden vergeleken. Dit onderscheid heeft belangrijke implicaties voor metingen en gegevensanalyse.
Een herinnering over variabelen versus variabelenniveaus
Een studie kan worden beschreven in termen van het aantal variabele categorieën, of niveaus, die worden vergeleken. U kunt bijvoorbeeld een onderzoek beschreven zien als een 2 X 2 ontwerp – uitgesproken als een twee bij twee ontwerp. Dit betekent dat er 2 mogelijke categorieën zijn voor de eerste variabele en 2 mogelijke categorieën voor de andere variabele – het zijn beide dichotome variabelen. Een studie die 2 categorieën van de variabele “alcoholgebruiksstoornis” (categorieën voor voldoet aan criteria, ja of nee) vergelijkt met 2 categorieën van de variabele “stoornis in het gebruik van illegale middelen” (categorieën voor voldoet aan criteria, ja of nee) zou 4 mogelijke uitkomsten hebben (wiskundig gezien, 2 x 2=4) en zou als volgt kunnen worden geschematiseerd (gegevens gebaseerd op verhoudingen uit de NSDUH-enquête van 2016, gepresenteerd in SAMHSA, 2017):
| Illicit Substance Use Disorder (SUD) | |||
|---|---|---|---|
|
Alcohol Use Disorder (AUD) |
Nee | Ja | |
| Geen | 500 | 10 | |
| Ja | 26 | 4 | |
Het lezen van de 4 cellen in deze 2 X 2 tabel leert ons dat in dit (hypothetische) onderzoek van 540 personen, 500 niet voldeden aan de criteria voor een stoornis in het gebruik van alcohol of illegale middelen (Nee, Nee); 26 personen voldeden alleen aan de criteria voor een stoornis in het gebruik van alcohol (Ja, Nee); 10 personen voldeden alleen aan de criteria voor een stoornis in het gebruik van verboden middelen (Nee, Ja), en 4 personen voldeden zowel aan de criteria voor een stoornis in het gebruik van alcohol als van verboden middelen (Ja, Ja). Met een beetje rekenwerk kunnen we bovendien zien dat in totaal 30 personen een stoornis in het gebruik van alcohol hadden (26 + 4) en 14 personen een stoornis in het gebruik van illegale middelen (10 + 4). En, we kunnen zien dat 40 een of andere stoornis in het middelengebruik hadden (26 + 10 + 4).
 Om dit onderscheid tussen variabelen en variabele niveaus of categorieën kristalhelder te maken, laten we nog een voorbeeld bekijken: een 2 X 3 studieopzet. Ten eerste, als we rekenen, zouden we 6 mogelijke uitkomsten (cellen) moeten zien. Ten tweede weten we dat de eerste variabele (leeftijdsgroep) 2 categorieën heeft (jonger dan 30 jaar, 30 jaar of ouder) en de andere variabele (werkgelegenheidsstatus) 3 categorieën heeft (volledig werkzaam, gedeeltelijk werkzaam, werkloos). Deze keer zijn de 6 cellen van ons ontwerp leeg omdat we wachten op de gegevens.
Om dit onderscheid tussen variabelen en variabele niveaus of categorieën kristalhelder te maken, laten we nog een voorbeeld bekijken: een 2 X 3 studieopzet. Ten eerste, als we rekenen, zouden we 6 mogelijke uitkomsten (cellen) moeten zien. Ten tweede weten we dat de eerste variabele (leeftijdsgroep) 2 categorieën heeft (jonger dan 30 jaar, 30 jaar of ouder) en de andere variabele (werkgelegenheidsstatus) 3 categorieën heeft (volledig werkzaam, gedeeltelijk werkzaam, werkloos). Deze keer zijn de 6 cellen van ons ontwerp leeg omdat we wachten op de gegevens.
| Werkloosheidsstatus | ||||
|---|---|---|---|---|
|
Leeftijdsgroep |
Volledig Werkzaam | Deelelijk Werkzaam | Werkloos | |
| <30 | ||||
| ≥30 | ||||
Thus, Wanneer u een studieopzetbeschrijving ziet die eruitziet alsof twee getallen worden vermenigvuldigd, vertelt dat u in wezen hoeveel categorieën of niveaus van elke variabele er zijn en leidt dat u te begrijpen hoeveel cellen of mogelijke uitkomsten er zijn. Een 3 X 3 design heeft 9 cellen, een 3 X 4 design heeft 12 cellen, enzovoort. Deze kwestie is opnieuw van belang wanneer we het in hoofdstuk 6 hebben over de steekproefgrootte.
Vul de volgende Workbook Activity:
- SWK 3401.3-4.1 Begin Data Entry
Chapter Summary
Samenvattend ontwerpen onderzoekers veel van hun kwantitatieve studies om hypothesen te testen over de relaties tussen variabelen. Inzicht in de aard van de betrokken variabelen helpt bij het begrijpen en evalueren van het uitgevoerde onderzoek. Inzicht in het onderscheid tussen verschillende soorten variabelen, en tussen variabelen en categorieën, heeft belangrijke implicaties voor onderzoeksopzet, meting, en steekproeven. In het volgende hoofdstuk wordt onder meer ingegaan op het raakvlak tussen de aard van de variabelen die in kwantitatief onderzoek worden bestudeerd en de manier waarop onderzoekers deze variabelen gaan meten.
Neem even de tijd om de volgende activiteit uit te voeren.