
- Szybki przegląd najlepszych dokumentów na temat klasyfikacji obrazów w ciągu dekady, aby rozpocząć naukę wizji komputerowej
- 1998: LeNet
- 2012: AlexNet
- 2014: VGG
- 2014: GoogLeNet
- 2015: Batch Normalization
- 2015: ResNet
- 2016: Xception
- 2017: MobileNet
- 2017: NASNet
- 2019: EfficientNet
- 2014: SPPNet
- 2016: DenseNet
- 2017: SENet
- 2017: ShuffleNet
- 2018: Bag of Tricks
- Wnioski
Szybki przegląd najlepszych dokumentów na temat klasyfikacji obrazów w ciągu dekady, aby rozpocząć naukę wizji komputerowej

Wizja komputerowa jest przedmiotem konwersji obrazów i wideo na sygnały zrozumiałe dla maszyn.zrozumiałe dla maszyny sygnały. Dzięki tym sygnałom programiści mogą dalej kontrolować zachowanie maszyny w oparciu o to wysokopoziomowe zrozumienie. Wśród wielu zadań wizji komputerowej, klasyfikacja obrazów jest jednym z najbardziej podstawowych. Nie tylko może być wykorzystywana w wielu rzeczywistych produktach, takich jak tagowanie zdjęć Google Photo i moderowanie treści AI, ale także otwiera drzwi dla wielu bardziej zaawansowanych zadań wizyjnych, takich jak wykrywanie obiektów i rozumienie wideo. Ze względu na szybkie zmiany w tej dziedzinie od czasu przełomu w Deep Learning, początkujący często uważają, że nauka jest zbyt przytłaczająca. W przeciwieństwie do typowych tematów inżynierii oprogramowania, nie ma zbyt wielu książek na temat klasyfikacji obrazów przy użyciu DCNN, a najlepszym sposobem na zrozumienie tej dziedziny jest czytanie prac naukowych. Ale jakie prace czytać? Od czego zacząć? W tym artykule, przedstawię 10 najlepszych prac do przeczytania dla początkujących. Z tych prac, możemy zobaczyć, jak to pole ewoluuje, i jak naukowcy przyniósł nowe pomysły w oparciu o poprzednie wyniki badań. Niemniej jednak, jest to nadal pomocne dla Ciebie, aby uporządkować duży obraz, nawet jeśli już pracował w tej dziedzinie na chwilę. Tak więc, zaczynajmy.
1998: LeNet
Uczenie oparte na gradiencie zastosowane do rozpoznawania dokumentów

Wprowadzony w 1998 roku, LeNet stanowi podstawę dla przyszłych badań nad klasyfikacją obrazów przy użyciu sieci neuronowych konwertujących. Wiele klasycznych technik CNN, takich jak warstwy łączące, w pełni połączone warstwy, wyściełanie i warstwy aktywacji są używane do ekstrakcji cech i klasyfikacji. Przy funkcji straty Mean Square Error i 20 epokach treningu, sieć ta może osiągnąć 99,05% dokładności na zbiorze testowym MNIST. Nawet po 20 latach wiele sieci klasyfikacyjnych state-of-the-art nadal podąża za tym wzorcem w ogóle.
2012: AlexNet
ImageNet Classification with Deep Convolutional Neural Networks

.
Although LeNet achieved a great result and showed the potential of CNN, rozwój w tej dziedzinie zastopował na dekadę z powodu ograniczonej mocy obliczeniowej i ilości danych. Wyglądało na to, że CNN może rozwiązać tylko niektóre łatwe zadania, takie jak rozpoznawanie cyfr, ale dla bardziej złożonych cech, takich jak twarze i obiekty, HarrCascade lub SIFT ekstraktor cech z klasyfikatorem SVM był bardziej preferowanym podejściem.
Jednakże w 2012 ImageNet Large Scale Visual Recognition Challenge, Alex Krizhevsky zaproponował rozwiązanie oparte na CNN dla tego wyzwania i drastycznie zwiększył dokładność zestawu testowego ImageNet top-5 z 73,8% do 84,7%. Ich podejście dziedziczy ideę wielowarstwowej sieci CNN z LeNet, ale znacznie zwiększyło rozmiar CNN. Jak widać na powyższym diagramie, dane wejściowe mają teraz rozmiar 224×224 w porównaniu z 32×32 w LeNecie, również wiele jąder konwolucji ma 192 kanały w porównaniu z 6 w LeNecie. Chociaż konstrukcja nie zmieniła się zbytnio, z setkami razy większą liczbą parametrów, zdolność sieci do przechwytywania i reprezentowania złożonych cech również poprawiła się setki razy. Do wytrenowania tak dużego modelu Alex wykorzystał dwie jednostki GPU GTX 580 z 3 GB pamięci RAM dla każdej z nich, co zapoczątkowało trend trenowania na GPU. Również zastosowanie nieliniowości ReLU pomogło obniżyć koszty obliczeniowe.
Oprócz wprowadzenia wielu dodatkowych parametrów dla sieci, Alexa zbadała również problem przepasowania, jaki niesie ze sobą większa sieć, poprzez zastosowanie warstwy Dropout. Jego metoda Local Response Normalization nie zdobyła później zbyt dużej popularności, ale zainspirowała inne ważne techniki normalizacji, takie jak BatchNorm do walki z problemem nasycenia gradientu. Podsumowując, AlexNet zdefiniował de facto ramy sieci klasyfikacyjnej na następne 10 lat: połączenie konwolucji, nieliniowej aktywacji ReLu, MaxPoolingu i warstwy gęstej.
2014: VGG
Very Deep Convolutional Networks for Large-Scale Image Recognition
Przy tak wielkim sukcesie wykorzystania CNN do rozpoznawania wizualnego, cała społeczność badawcza wybuchła i wszyscy zaczęli sprawdzać, dlaczego ta sieć neuronowa działa tak dobrze. Na przykład, w „Visualizing and Understanding Convolutional Networks” z 2013 roku, Matthew Zeiler omówił, jak CNN zbiera cechy i zwizualizował pośrednie reprezentacje. I nagle wszyscy zaczęli zdawać sobie sprawę, że CNN jest przyszłością wizji komputerowej od 2014 roku. Wśród tych wszystkich natychmiastowych naśladowców, sieć VGG od Visual Geometry Group jest najbardziej przykuwająca uwagę. Uzyskała ona niezwykły wynik 93,2% dokładności top-5 i 76,3% dokładności top-1 na zestawie testowym ImageNet.
Podążając za projektem AlexNet, sieć VGG ma dwie główne aktualizacje: 1) VGG nie tylko użył szerszej sieci jak AlexNet, ale także głębszej. VGG-19 ma 19 warstw konwolucji, w porównaniu do 5 z AlexNet. 2) VGG pokazała również, że kilka małych filtrów konwolucji 3×3 może zastąpić pojedyncze filtry 7×7 lub nawet 11×11 z AlexNet, osiągnąć lepszą wydajność przy jednoczesnym zmniejszeniu kosztów obliczeniowych. Ze względu na ten elegancki projekt, VGG stał się również siecią szkieletową wielu pionierskich sieci w innych zadaniach widzenia komputerowego, takich jak FCN do segmentacji semantycznej i Faster R-CNN do wykrywania obiektów.
W przypadku głębszej sieci, zanikanie gradientu z wielowarstwowej propagacji wstecznej staje się większym problemem. Aby sobie z nim poradzić, VGG omówiło również znaczenie wstępnego szkolenia i inicjalizacji wagi. Ten problem ogranicza naukowców do ciągłego dodawania kolejnych warstw, w przeciwnym razie sieć będzie naprawdę trudna do konwergencji. Ale zobaczymy lepsze rozwiązanie tego problemu po dwóch latach.
2014: GoogLeNet
Going Deeper with Convolutions

VGG ma dobrze wyglądającą i łatwą do zrozumienia strukturę, ale jego wydajność nie jest najlepsza spośród wszystkich finalistów konkursu ImageNet 2014. GoogLeNet, aka InceptionV1, zdobył ostateczną nagrodę. Podobnie jak w przypadku VGG, jednym z głównych osiągnięć GoogLeNet jest przekroczenie granicy głębokości sieci o strukturze 22 warstw. To ponownie pokazało, że pogłębianie i poszerzanie sieci jest rzeczywiście właściwym kierunkiem do poprawy dokładności.
W przeciwieństwie do VGG, GoogLeNet próbował zająć się problemami związanymi z obliczeniami i zmniejszaniem gradientu, zamiast proponować obejście z lepszym wstępnie wytrenowanym schematem i inicjalizacją wag.

Po pierwsze, zbadano ideę asymetrycznego projektowania sieci za pomocą modułu o nazwie Inception (patrz diagram powyżej). Idealnie, chcieliby ścigać sparse convolution lub gęstych warstw w celu poprawy wydajności funkcji, ale nowoczesny projekt sprzętu nie został dostosowany do tego przypadku. Więc uwierzyli, że rozproszenie na poziomie topologii sieci może również pomóc w fuzji cech przy jednoczesnym wykorzystaniu istniejących możliwości sprzętowych.
Po drugie, atakuje problem wysokiego kosztu obliczeniowego poprzez zapożyczenie pomysłu z papieru o nazwie „Sieć w sieci”. Zasadniczo, filtr konwolucyjny 1×1 jest wprowadzony w celu zmniejszenia wymiarów cech przed przejściem przez ciężką operację obliczeniową, taką jak jądro konwolucyjne 5×5. Struktura ta nazywana jest później „Bottleneck” i jest szeroko stosowana w wielu kolejnych sieciach. Podobnie jak w przypadku „sieci w sieci”, użyto również warstwy łączenia średniej, aby zastąpić końcową w pełni połączoną warstwę w celu dalszego zmniejszenia kosztów.
Po trzecie, aby pomóc gradientom w przepływie do głębszych warstw, GoogLeNet użył również nadzoru na niektórych wyjściach warstwy pośredniej lub wyjściach pomocniczych. Ten projekt nie jest dość popularny później w sieci klasyfikacji obrazu ze względu na złożoność, ale coraz bardziej popularne w innych dziedzinach wizji komputerowej, takich jak sieć klepsydra w szacowania pose.
Jako kontynuacja, ten zespół Google napisał więcej papierów dla tej serii Inception. „Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift” oznacza InceptionV2. „Rethinking the Inception Architecture for Computer Vision” z 2015 roku oznacza InceptionV3. Natomiast „Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning” z 2015 roku oznacza InceptionV4. Każdy papier dodał więcej ulepszeń w stosunku do oryginalnej sieci Inception i osiągnął lepszy wynik.
2015: Batch Normalization
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Sieć Inception pomogła badaczom osiągnąć nadludzką dokładność na zbiorze danych ImageNet. Jednakże, jako statystyczna metoda uczenia, CNN jest bardzo ograniczona do statystycznej natury konkretnego zbioru danych treningowych. Dlatego, aby osiągnąć lepszą dokładność, zazwyczaj musimy wstępnie obliczyć średnią i odchylenie standardowe całego zbioru danych i użyć ich do normalizacji naszych danych wejściowych, aby upewnić się, że większość wejść warstw w sieci jest zbliżona, co przekłada się na lepszą reaktywność aktywacji. To przybliżone podejście jest bardzo kłopotliwe, a czasami w ogóle nie działa dla nowej struktury sieci lub nowego zbioru danych, więc model głębokiego uczenia jest nadal postrzegany jako trudny do wytrenowania. Aby rozwiązać ten problem, Sergey Ioffe i Chritian Szegedy, facet, który stworzył GoogLeNet, postanowili wymyślić coś mądrzejszego o nazwie Batch Normalization.

Pomysł normalizacji wsadowej nie jest trudny: Możemy użyć statystyk serii mini wsadów do przybliżenia statystyk całego zbioru danych, o ile trenujemy przez wystarczająco długi czas. Ponadto, zamiast ręcznego obliczania statystyk, możemy wprowadzić dwa parametry „scale” i „shift”, aby sieć sama nauczyła się normalizować każdą warstwę.
Powyższy diagram pokazuje proces obliczania wartości normalizacji wsadowej. Jak widzimy, bierzemy średnią z całej minipartii i obliczamy również wariancję. Następnie, możemy znormalizować dane wejściowe za pomocą tej średniej i wariancji mini-partii. W końcu, z parametrem skali i przesunięcia, sieć nauczy się dostosowywać znormalizowany wynik, aby najlepiej pasował do kolejnych warstw, zwykle ReLU. Jednym zastrzeżeniem jest to, że nie mamy informacji o mini-partii podczas wnioskowania, więc obejściem jest obliczenie średniej ruchomej i wariancji podczas szkolenia, a następnie użycie tych średnich ruchomych w ścieżce wnioskowania. Ta mała innowacja jest tak wpływowa i wszystkie późniejsze sieci od razu zaczynają z niej korzystać.
2015: ResNet
Deep Residual Learning for Image Recognition
2015 może być najlepszym rokiem dla wizji komputerowej od dekady, widzieliśmy tak wiele świetnych pomysłów wyskakujących nie tylko w klasyfikacji obrazów, ale wszelkiego rodzaju zadaniach wizji komputerowej, takich jak wykrywanie obiektów, segmentacja semantyczna itp. Największy postęp roku 2015 należy do nowej sieci o nazwie ResNet, czyli sieci rezydualnych, zaproponowanej przez grupę chińskich badaczy z Microsoft Research Asia.

Jak omawialiśmy wcześniej dla sieci VGG, największą przeszkodą w uzyskaniu jeszcze większej głębokości jest problem zaniku gradientu, tzn.tzn. pochodne stają się coraz mniejsze podczas wstecznej propagacji przez głębsze warstwy i w końcu osiągają punkt, którego współczesna architektura komputerowa nie jest w stanie sensownie reprezentować. GoogLeNet próbował zaatakować ten problem poprzez użycie pomocniczego nadzoru i modułu asymetrycznego przyjmowania, ale to tylko w niewielkim stopniu łagodzi problem. Jeśli chcemy użyć 50 lub nawet 100 warstw, czy znajdzie się lepszy sposób na to, aby gradient przepłynął przez sieć? Odpowiedzią ResNetu jest użycie modułu rezydualnego.

ResNet dodał skrót tożsamościowy do wyjścia, aby każdy moduł resztkowy nie mógł przynajmniej przewidzieć, czymkolwiek jest wejście, bez gubienia się w dziczy. Jeszcze ważniejszą rzeczą jest to, że zamiast mieć nadzieję, że każda warstwa pasuje bezpośrednio do pożądanego odwzorowania cech, moduł resztkowy próbuje nauczyć się różnicy między wyjściem a wejściem, co znacznie ułatwia zadanie, ponieważ potrzebny zysk informacyjny jest mniejszy. Wyobraź sobie, że uczysz się matematyki, dla każdego nowego problemu dostajesz rozwiązanie podobnego problemu, więc wszystko, co musisz zrobić, to rozszerzyć to rozwiązanie i spróbować sprawić, by działało. Jest to o wiele łatwiejsze niż wymyślanie zupełnie nowego rozwiązania dla każdego problemu, na który się natkniesz. Albo jak powiedział Newton, możemy stanąć na ramionach gigantów, a wejście tożsamości jest tym gigantem dla modułu residual.
Oprócz mapowania tożsamości, ResNet pożyczył również wąskie gardło i Batch Normalization z sieci Inception. Ostatecznie udało się zbudować sieć z 152 warstwami konwolucyjnymi i osiągnąć 80,72% dokładności top-1 na ImageNet. Podejście rezydualne stało się również domyślną opcją dla wielu innych sieci później, takich jak Xception, Darknet, itp. Ponadto, dzięki prostej i pięknej konstrukcji, jest nadal szeroko stosowany w wielu systemach rozpoznawania wizualnego produkcji obecnie.
Jest wiele więcej inwariantów wyszło przez podążanie za hype sieci rezydualnej. W „Identity Mappings in Deep Residual Networks”, oryginalny autor ResNet próbował umieścić aktywację przed modułem rezydualnym i osiągnął lepszy wynik, a ten projekt jest nazywany ResNetV2 po tym. Również w pracy z 2016 roku „Aggregated Residual Transformations for Deep Neural Networks” badacze zaproponowali ResNeXt, który dodał równoległe gałęzie dla modułów resztkowych, aby agregować wyjścia różnych transformacji.
2016: Xception
Xception: Deep Learning with Depthwise Separable Convolutions

Z chwilą wydania ResNetu wyglądało na to, że większość nisko wiszących owoców w klasyfikatorach obrazów została już zgarnięta. Naukowcy zaczęli się zastanawiać, jaki jest wewnętrzny mechanizm magii CNN. Ponieważ cross-channel convolution zwykle wprowadza tonę parametrów, sieć Xception postanowiła zbadać tę operację, aby zrozumieć pełny obraz jej działania.
Jak sama nazwa wskazuje, Xception wywodzi się z sieci Inception. W module Inception, wiele gałęzi różnych transformacji są agregowane razem, aby osiągnąć topologię sparsity. Ale dlaczego ta rozproszoność zadziałała? Autor Xception, również twórca frameworka Keras, rozszerzył ten pomysł do ekstremalnego przypadku, w którym jeden plik konwolucji 3×3 odpowiada jednemu kanałowi wyjściowemu przed ostateczną konkatenacją. W tym przypadku te równoległe jądra konwolucji faktycznie tworzą nową operację zwaną depth-wise convolution.

Jak pokazano na powyższym diagramie, w przeciwieństwie do tradycyjnej konwolucji, gdzie wszystkie kanały są uwzględnione w jednym obliczeniu, depth-wise convolution tylko oblicza konwolucję dla każdego kanału osobno, a następnie konkatenuje wyjście razem. To zmniejsza wymianę cech między kanałami, ale także redukuje wiele połączeń, a więc skutkuje warstwą z mniejszą liczbą parametrów. Jednak ta operacja spowoduje wyjście tej samej liczby kanałów, co na wejściu (lub mniejszej, jeśli zgrupujesz dwa lub więcej kanałów razem). Dlatego, gdy wyjścia kanałów zostaną połączone, potrzebujemy innego regularnego filtra 1×1 lub konwolucji punktowej, aby zwiększyć lub zmniejszyć liczbę kanałów, tak jak robi to regularna konwolucja.
Ten pomysł nie pochodzi oryginalnie z Xception. Jest on opisany w artykule o nazwie „Learning visual representations at scale” i również używany sporadycznie w InceptionV2. Xception poszedł o krok dalej i zastąpił prawie wszystkie konwolucje tym nowym typem. Wynik eksperymentu okazał się całkiem niezły. Przewyższa on ResNet i InceptionV3 i stał się nową metodą SOTA do klasyfikacji obrazów. To również udowodniło, że mapowanie korelacji międzykanałowych i korelacji przestrzennych w CNN może być całkowicie odłączone. Ponadto, dzieląc tę samą zaletę z ResNet, Xception ma prosty i piękny design, jak również, więc jego pomysł jest używany w wielu innych następujących badań, takich jak MobileNet, DeepLabV3, etc.
2017: MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
Xception osiągnął 79% dokładności top-1 i 94,5% dokładności top-5 na ImageNet, ale to tylko 0,8% i 0,4% poprawy odpowiednio w porównaniu z poprzednim SOTA InceptionV3. Marginalny zysk z nowej sieci klasyfikacji obrazów staje się coraz mniejszy, więc badacze zaczynają przenosić swoją uwagę na inne obszary. A MobileNet doprowadził do znaczącego rozwoju klasyfikacji obrazów w środowisku o ograniczonych zasobach.

Podobny do Xception, MobileNet używał tego samego modułu konwolucji rozdzielnej w głąb, jak pokazano powyżej i kładł nacisk na wysoką wydajność i mniej parametrów.
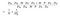
Licznik w powyższym wzorze to całkowita liczba parametrów wymaganych przez konwolucję rozdzielną w głąb. A mianownik to całkowita liczba parametrów podobnej regularnej konwolucji. Tutaj D jest rozmiarem jądra konwolucji, D jest rozmiarem mapy cech, M jest liczbą kanałów wejściowych, N jest liczbą kanałów wyjściowych. Ponieważ rozdzieliliśmy obliczanie cech kanałowych i przestrzennych, możemy zamienić mnożenie na dodawanie, co jest o wiele mniejsze. Jeszcze lepiej, jak widzimy z tego stosunku, im większa jest liczba kanałów wyjściowych, tym więcej obliczeń zaoszczędziliśmy dzięki użyciu tej nowej konwolucji.
Kolejnym wkładem MobileNet jest mnożnik szerokości i rozdzielczości. Zespół MobileNet chciał znaleźć kanoniczny sposób na zmniejszenie rozmiaru modelu dla urządzeń mobilnych, a najbardziej intuicyjnym sposobem jest zmniejszenie liczby kanałów wejściowych i wyjściowych, jak również rozdzielczości obrazu wejściowego. Aby kontrolować to zachowanie, stosunek alfa jest mnożony przez kanały, a stosunek rho jest mnożony przez rozdzielczość wejściową (co również wpływa na rozmiar mapy cech). Tak więc całkowita liczba parametrów może być przedstawiona w następującym wzorze:

Chociaż ta zmiana wydaje się naiwna pod względem innowacyjności, ma wielką wartość inżynieryjną, ponieważ po raz pierwszy badacze zawierają kanoniczne podejście do dostosowania sieci do różnych ograniczeń zasobów. Również, to rodzaj podsumowania ostatecznego rozwiązania poprawy sieci neuronowej: szersze i wysokiej rozdzielczości dane wejściowe prowadzą do lepszej dokładności, cieńsze i niskiej rozdzielczości dane wejściowe prowadzą do gorszej dokładności.
Później w 2018 i 2019 roku, zespół MobiletNet wydał również „MobileNetV2: Inverted Residuals and Linear Bottlenecks” oraz „Searching for MobileNetV3”. W MobileNetV2 używana jest struktura odwróconej rezydualnej wąskiej gardła. Natomiast w MobileNetV3 rozpoczęto wyszukiwanie optymalnej kombinacji architektur przy użyciu technologii Neural Architecture Search, którą zajmiemy się w następnej części.
2017: NASNet
Learning Transferable Architectures for Scalable Image Recognition
Tak jak klasyfikacja obrazów dla środowiska o ograniczonych zasobach, wyszukiwanie architektury neuronowej jest kolejną dziedziną, która pojawiła się około 2017 roku. Z ResNet, Inception i Xception, wydaje się, że osiągnęliśmy optymalną topologię sieci, którą człowiek może zrozumieć i zaprojektować, ale co jeśli istnieje lepsza i znacznie bardziej złożona kombinacja, która znacznie przekracza ludzką wyobraźnię? W pracy z 2016 roku o nazwie „Neural Architecture Search with Reinforcement Learning” zaproponowano pomysł na poszukiwanie optymalnej kombinacji w ramach wcześniej zdefiniowanej przestrzeni poszukiwań poprzez wykorzystanie uczenia wzmacniającego. Jak wiemy, uczenie wzmacniające jest metodą znajdowania najlepszego rozwiązania z jasnym celem i nagrodą dla szukającego agenta. Jednakże, ograniczony mocą obliczeniową, artykuł ten omówił jedynie zastosowanie w małym zbiorze danych CIFAR.

W celu znalezienia optymalnej struktury dla dużego zbioru danych, takiego jak ImageNet, NASNet stworzył przestrzeń wyszukiwania, która jest dostosowana do ImageNet. Ma nadzieję zaprojektować specjalną przestrzeń wyszukiwania tak, że wynik wyszukiwania na CIFAR może również działać dobrze na ImageNet. Po pierwsze, NASNet zakłada, że wspólny ręcznie stworzony moduł w dobrych sieciach, takich jak ResNet i Xception, jest nadal przydatny podczas wyszukiwania. Więc zamiast szukać losowych połączeń i operacji, NASNet szuka kombinacji tych modułów, które okazały się przydatne już w ImageNet. Po drugie, rzeczywiste wyszukiwanie jest nadal wykonywane na zbiorze danych CIFAR o rozdzielczości 32×32, więc NASNet wyszukuje tylko moduły, na które nie ma wpływu rozmiar danych wejściowych. Aby drugi punkt zadziałał, NASNet predefiniował dwa rodzaje szablonów modułów: Reduction i Normal. Komórka Reduction może mieć zmniejszoną mapę funkcji w stosunku do wejściowej, a dla komórki Normal będzie taka sama.

Although NASNet has better metrics than manually design networks, it also suffers from a few drawbacks. Koszt poszukiwania optymalnej struktury jest bardzo wysoki, na co mogą sobie pozwolić tylko duże firmy, takie jak Google czy Facebook. Ponadto, ostateczna struktura nie ma zbyt wiele sensu dla ludzi, stąd trudniej ją utrzymać i poprawić w środowisku produkcyjnym. Później w 2018 roku, „MnasNet: Platform-Aware Neural Architecture Search for Mobile” dalej rozszerza ten pomysł NASNet, ograniczając krok wyszukiwania za pomocą wstępnie zdefiniowanej struktury bloków łańcuchowych. Ponadto, poprzez zdefiniowanie współczynnika wagowego, mNASNet dał bardziej systematyczny sposób wyszukiwania modelu biorąc pod uwagę konkretne ograniczenia zasobów, zamiast po prostu oceniać w oparciu o FLOPs.
2019: EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
W 2019 roku wygląda na to, że nie ma już żadnych ekscytujących pomysłów na nadzorowaną klasyfikację obrazów za pomocą CNN. Drastyczna zmiana struktury sieci zwykle oferuje tylko niewielką poprawę dokładności. Co gorsza, gdy ta sama sieć jest stosowana do różnych zbiorów danych i zadań, wcześniej deklarowane sztuczki nie wydają się działać, co doprowadziło do krytyki, że czy te ulepszenia są po prostu overfitting na zbiorze danych ImageNet. Z drugiej strony, jest jedna sztuczka, która nigdy nie zawodzi naszych oczekiwań: użycie wyższej rozdzielczości danych wejściowych, dodanie większej ilości kanałów dla warstw konwolucji i dodanie większej ilości warstw. Chociaż jest to bardzo brutalna siła, wydaje się, że istnieje sposób na skalowanie sieci na żądanie. MobileNetV1 poniekąd sugerował to w 2017 roku, ale punkt ciężkości został przesunięty na lepszy projekt sieci później.

Po NASNecie i mNASNecie badacze zdali sobie sprawę, że nawet z pomocą komputera zmiana architektury nie przynosi aż tak dużych korzyści. Zaczęli więc wracać do skalowania sieci. EfficientNet jest właśnie zbudowany na tym założeniu. Z jednej strony wykorzystuje optymalny blok konstrukcyjny z mNASNet, aby zapewnić dobry fundament na początek. Z drugiej strony, zdefiniowano trzy parametry alfa, beta i rho, aby odpowiednio kontrolować głębokość, szerokość i rozdzielczość sieci. W ten sposób, nawet bez dużej puli GPU do poszukiwania optymalnej struktury, inżynierowie mogą polegać na tych pryncypialnych parametrach, aby dostroić sieć w oparciu o ich różne wymagania. Ostatecznie, EfficientNet dał 8 różnych wariantów z różnymi współczynnikami szerokości, głębokości i rozdzielczości i uzyskał dobrą wydajność zarówno dla małych, jak i dużych modeli. Innymi słowy, jeśli zależy Ci na wysokiej dokładności, wybierz EfficientNet-B7 o rozdzielczości 600×600 i parametrach 66M. Jeśli chcesz niskiego opóźnienia i mniejszego modelu, wybierz model EfficientNet-B0 o wymiarach 224×224 i parametrach 5.3M. Problem rozwiązany.
Jeśli skończysz czytać powyższe 10 artykułów, powinieneś mieć całkiem niezłe pojęcie o historii klasyfikacji obrazów za pomocą CNN. Jeśli chcesz kontynuować naukę w tej dziedzinie, wymieniłem również kilka innych ciekawych artykułów do przeczytania. Chociaż nie znajdują się one na liście 10 najlepszych, wszystkie te prace są znane w swojej dziedzinie i zainspirowały wielu innych badaczy na świecie.
2014: SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPPNet zapożycza ideę piramidy cech z tradycyjnej ekstrakcji cech w wizji komputerowej. Piramida ta tworzy worek słów cech o różnych skalach, dzięki czemu może dostosować się do różnych rozmiarów danych wejściowych i pozbyć się warstwy w pełni połączonej o stałym rozmiarze. Pomysł ten zainspirował również moduł ASPP w DeepLab, a także FPN do wykrywania obiektów.
2016: DenseNet
Densely Connected Convolutional Networks
DenseNet z Cornell dalej rozszerza pomysł z ResNet. Nie tylko zapewnia pomijanie połączeń między warstwami, ale również posiada pomijanie połączeń ze wszystkich poprzednich warstw.
2017: SENet
Squeeze-and-Excitation Networks
Sieć Xception pokazała, że korelacja międzykanałowa nie ma wiele wspólnego z korelacją przestrzenną. Jednakże, jako mistrz ostatniego konkursu ImageNet, SENet opracował blok Squeeze-and-Excitation i opowiedział inną historię. Blok SE najpierw ściska wszystkie kanały do mniejszej liczby kanałów za pomocą globalnego łączenia, stosuje w pełni połączoną transformatę, a następnie „wzbudza” je z powrotem do pierwotnej liczby kanałów za pomocą innej w pełni połączonej warstwy. Tak więc zasadniczo warstwa FC pomogła sieci nauczyć się uwagi na wejściowej mapie cech.
2017: ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Build on top of MobileNetV2’s inverted bottleneck module, ShuffleNet believes that point-wise convolution in depthwise separable convolution sacrifices accuracy in exchange for less computation. Aby to zrekompensować, ShuffleNet dodał dodatkową operację tasowania kanałów, aby upewnić się, że point-wise convolution nie będzie zawsze stosowany do tego samego „punktu”. A w ShuffleNetV2 ten mechanizm tasowania kanałów jest dalej rozszerzony na gałąź mapowania tożsamości ResNet, jak również, tak, że część cechy tożsamości będzie również używana do tasowania.
2018: Bag of Tricks
Bag of Tricks for Image Classification with Convolutional Neural Networks
Bag of Tricks skupia się na powszechnych sztuczkach stosowanych w obszarze klasyfikacji obrazów. Służy jako dobre odniesienie dla inżynierów, gdy muszą poprawić wydajność benchmarku. Co ciekawe, te sztuczki, takie jak mixup augmentation i cosine learning rate, mogą czasami osiągnąć znacznie lepszą poprawę niż nowa architektura sieci.
Wnioski
Z chwilą wydania EfficientNet, wygląda na to, że benchmark klasyfikacji ImageNet dobiega końca. Przy istniejącym podejściu do głębokiego uczenia, nigdy nie będzie dnia, w którym osiągniemy 99,999% dokładności w ImageNet, chyba że nastąpi inna zmiana paradygmatu. Dlatego też badacze aktywnie poszukują nowych obszarów, takich jak uczenie samonadzorowane lub półnadzorowane dla rozpoznawania wizualnego na dużą skalę. W międzyczasie, z istniejącymi metodami, stało się to bardziej pytaniem dla inżynierów i przedsiębiorców, aby znaleźć zastosowanie w świecie rzeczywistym tej niedoskonałej technologii. W przyszłości, będę również napisać ankietę do analizy tych rzeczywistych zastosowań wizji komputerowej napędzany przez klasyfikacji obrazu, więc proszę być na bieżąco! Jeśli uważasz, że są też inne ważne prace do przeczytania dla klasyfikacji obrazów, proszę zostaw komentarz poniżej i daj nam znać.
Originally published at http://yanjia.li on July 31, 2020
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based Learning Applied to Document Recognition
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
- Sergey Ioffe, Christian Szegedy, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition
- François Chollet, Xception: Deep Learning with Depthwise Separable Convolutions
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
- Mingxing Tan, Quoc V. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Connected Convolutional Networks
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Bag of Tricks for Image Classification with Convolutional Neural Networks
.