
Alokacja zasobów jest ważnym aspektem podczas wykonywania każdego zadania spark. Jeśli nie jest skonfigurowany poprawnie, zadanie iskry może pochłonąć całe zasoby klastra i sprawić, że inne aplikacje będą głodować o zasoby.
Ten blog pomaga zrozumieć podstawowy przepływ w aplikacji Spark, a następnie jak skonfigurować liczbę executorów, ustawienia pamięci każdego executora i liczbę rdzeni dla zadania Spark. Istnieje kilka czynników, które musimy wziąć pod uwagę, aby zdecydować o optymalnych liczbach dla powyższych trzech, takich jak:
- Ilość danych
- Czas, w którym zadanie musi się zakończyć
- Statyczne lub dynamiczne przydzielanie zasobów
- Upstream lub downstream aplikacji
Wprowadzenie
Zacznijmy od kilku podstawowych definicji terminów używanych w obsłudze aplikacji Spark.
Partycje : Partycja to mały wycinek dużego rozproszonego zbioru danych. Spark zarządza danymi za pomocą partycji, co pomaga w równoległym przetwarzaniu danych z minimalnym przemieszaniem danych pomiędzy executorami.
Zadanie : Zadanie jest jednostką pracy, która może być uruchomiona na partycji rozproszonego zbioru danych i jest wykonywana na pojedynczym executorze. Wszystkie zadania w jednym etapie mogą być wykonywane równolegle
Wykonawca: Wykonawca jest pojedynczym procesem JVM, który jest uruchamiany dla aplikacji na węźle robotniczym. Executor uruchamia zadania i przechowuje dane w pamięci lub na dysku przez cały czas ich trwania. Każda aplikacja ma swoje własne executory. Pojedynczy węzeł może uruchomić wiele executorów, a executory dla aplikacji mogą obejmować wiele węzłów robotniczych. Egzekutor pozostaje włączony przez
czas trwania aplikacji Spark i wykonuje zadania w wielu wątkach. Liczba executorów dla aplikacji Spark może być określona wewnątrz SparkConf lub poprzez flagę -num-executors z wiersza poleceń.
Cluster Manager : Zewnętrzna usługa do pozyskiwania zasobów na klastrze (np. samodzielny menedżer, Mesos, YARN). Spark jest agnostykiem dla menedżera klastra tak długo, jak może pozyskać procesy wykonawcze, a te mogą komunikować się ze sobą.Jesteśmy głównie zainteresowani Yarn jako menedżerem klastra. Klaster spark może działać w trybie yarn cluster lub yarn-client:
yarn-client mode – Sterownik działa na procesie klienta, Application Master jest używany tylko do żądania zasobów od YARN.
yarn-cluster mode – Sterownik działa wewnątrz procesu application master, klient odchodzi po zainicjalizowaniu aplikacji
Rdzenie : Rdzeń jest podstawową jednostką obliczeniową procesora, a procesor może mieć jeden lub więcej rdzeni do wykonywania zadań w danym czasie. Im więcej rdzeni mamy, tym więcej pracy możemy wykonać. W iskrze kontroluje to liczbę równoległych zadań, które może uruchomić executor.
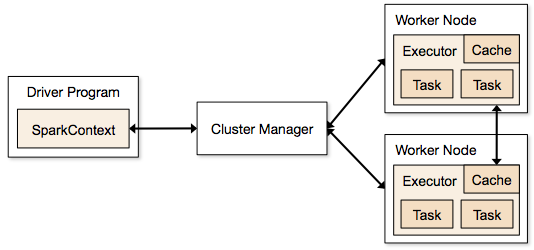
Kroki związane z trybem klastrowym dla zadania Spark
- Z kodu sterownika, SparkContext łączy się z menedżerem klastra (standalone/Mesos/YARN).
- Menedżer klastra przydziela zasoby innym aplikacjom. Każdy menedżer klastra może być użyty tak długo, jak procesy wykonawcze są uruchomione i komunikują się ze sobą.
- Spark pozyskuje wykonawców na węzłach w klastrze. Tutaj każda aplikacja otrzyma swoje własne procesy wykonawcze.
- Kod aplikacji (pliki jar/python/python egg files) jest wysyłany do executorów
- Zadania są wysyłane przez SparkContext do executorów.
Z powyższych kroków jasno wynika, że liczba executorów i ich ustawienie pamięci odgrywają główną rolę w zadaniu spark. Uruchamianie executorów ze zbyt dużą ilością pamięci często powoduje nadmierne opóźnienia w zbieraniu śmieci
Teraz spróbujemy zrozumieć, jak skonfigurować najlepszy zestaw wartości, aby zoptymalizować zadanie spark.
Istnieją dwa sposoby, w jaki konfigurujemy executory i szczegóły rdzenia do zadania Spark. Są to:
- Alokacja statyczna – Wartości są podawane jako część spark-submit
- Alokacja dynamiczna – Wartości są pobierane w oparciu o wymagania (rozmiar danych, ilość potrzebnych obliczeń) i uwalniane po użyciu. Pomaga to w ponownym wykorzystaniu zasobów dla innych aplikacji.
Alokacja statyczna
Różne przypadki są omawiane zmieniając różne parametry i dochodząc do różnych kombinacji zgodnie z wymaganiami użytkownika/danych.
Przypadek 1 Sprzęt – 6 węzłów i każdy węzeł ma 16 rdzeni, 64 GB RAM
Po pierwsze na każdym węźle, 1 rdzeń i 1 GB jest potrzebny dla systemu operacyjnego i demonów Hadoop, więc mamy 15 rdzeni, 63 GB RAM dla każdego węzła
Zaczynamy od tego jak wybrać liczbę rdzeni:
Liczba rdzeni = Współbieżne zadania, które może uruchomić executor
Możemy więc pomyśleć, że więcej współbieżnych zadań dla każdego executora da lepszą wydajność. Ale badania pokazują, że każda aplikacja z więcej niż 5 współbieżnymi zadaniami, doprowadzi do złego pokazu. Tak więc optymalną wartością jest 5.
Liczba ta pochodzi od zdolności executora do uruchamiania równoległych zadań, a nie od tego ile rdzeni posiada system. Tak więc liczba 5 pozostaje taka sama nawet jeśli mamy podwójne (32) rdzenie w CPU
Liczba executorów:
Przechodząc do następnego kroku, z 5 jako rdzeniami na executor, i 15 jako całkowitą dostępną liczbą rdzeni w jednym węźle (CPU) – otrzymujemy 3 executory na węzeł, co stanowi 15/5. Musimy obliczyć liczbę jednostek wykonawczych na każdym węźle, a następnie uzyskać całkowitą liczbę dla zadania.
Więc z 6 węzłami i 3 jednostkami wykonawczymi na węzeł – otrzymujemy w sumie 18 jednostek wykonawczych. Z 18 potrzebujemy 1 executora (proces java) dla Application Master w YARN. Więc ostateczna liczba to 17 executorów
To 17 to liczba, którą podajemy iskrze używając -num-executors podczas uruchamiania z polecenia powłoki spark-submit
Pamięć dla każdego executora:
Z powyższego kroku wynika, że mamy 3 executory na węzeł. A dostępna pamięć RAM na każdym węźle wynosi 63 GB
Więc pamięć dla każdego executora w każdym węźle wynosi 63/3 = 21GB.
Jednakże niewielka pamięć nadrzędna jest również potrzebna do określenia pełnego żądania pamięci do YARN dla każdego executora.
Wzór na ten narzut to max(384, .07 * spark.executor.memory)
Obliczając ten narzut: .07 * 21 (tutaj 21 jest obliczane jak powyżej 63/3) = 1.47
Ponieważ 1.47 GB > 384 MB, narzut wynosi 1.47
Odjąć powyższe od każdego 21 powyżej => 21 – 1.47 ~ 19 GB
Więc pamięć executora – 19 GB
Final numbers – Executors – 17, Cores 5, Executor Memory – 19 GB
Case 2 Hardware – 6 Nodes and Each node have 32 Cores, 64 GB
Number of cores of 5 is same for good concurrency as explained above.
Liczba jednostek wykonawczych dla każdego węzła = 32/5 ~ 6
Więc całkowita liczba jednostek wykonawczych = 6 * 6 węzłów = 36. Wtedy ostateczna liczba to 36 – 1(dla AM) = 35
Pamięć wykonawcza:
6 wykonawców dla każdego węzła. 63/6 ~ 10. Koszty ogólne to .07 * 10 = 700 MB. Więc zaokrąglając do 1 GB jako narzut, otrzymujemy 10-1 = 9 GB
Final numbers – Executors – 35, Cores 5, Executor Memory – 9 GB
Case 3 – When more memory is not required for the executors
Powyższe scenariusze zaczynają się od przyjęcia liczby rdzeni jako stałej i przechodzą do liczby executorów i pamięci.
Teraz dla pierwszego przypadku, jeśli uważamy, że nie potrzebujemy 19 GB, a tylko 10 GB jest wystarczające w oparciu o rozmiar danych i wykonywane obliczenia, to następujące liczby:
Rdzenie: 5
Liczba executorów dla każdego węzła = 3. Nadal 15/5 zgodnie z obliczeniami powyżej.
Na tym etapie doprowadziłoby to do 21 GB, a następnie 19 zgodnie z naszymi pierwszymi obliczeniami. Ale ponieważ myśleliśmy, że 10 jest w porządku (zakładamy mały narzut), to nie możemy zmienić liczby executorów na węzeł na 6 (jak 63/10). Ponieważ przy 6 executorach na węzeł i 5 rdzeniach wychodzi 30 rdzeni na węzeł, podczas gdy my mamy tylko 16 rdzeni. Tak więc musimy również zmienić liczbę rdzeni dla każdego executora.
Więc obliczając ponownie,
Magiczna liczba 5 dochodzi do 3 (każda liczba mniejsza lub równa 5). Tak więc z 3 rdzeniami i 15 dostępnymi rdzeniami – otrzymujemy 5 executorów na węzeł, 29 executorów (czyli (5*6 -1)) i pamięć 63/5 ~ 12.
Overhead to 12*.07=.84. Więc pamięć executora to 12 – 1 GB = 11 GB
Final Numbers are 29 executors, 3 cores, executor memory is 11 GB
Summary Table
Dynamic Allocation
Note: Upper bound for the number of executors if dynamic allocation is enabled is infinity. Więc to mówi, że aplikacja spark może zjeść wszystkie zasoby, jeśli zajdzie taka potrzeba. W klastrze, w którym mamy uruchomione inne aplikacje i one również potrzebują rdzeni do wykonywania zadań, musimy upewnić się, że przydzielamy rdzenie na poziomie klastra.
To oznacza, że możemy przydzielić określoną liczbę rdzeni dla aplikacji opartych na YARN w oparciu o dostęp użytkownika. Możemy więc stworzyć spark_user, a następnie nadać rdzenie (min/max) dla tego użytkownika. Limity te są przeznaczone do współdzielenia pomiędzy spark i innymi aplikacjami, które działają na YARN.
Aby zrozumieć dynamiczną alokację, musimy posiadać wiedzę na temat następujących właściwości:
spark.dynamicAllocation.enabled – kiedy jest to ustawione na true nie musimy wspominać o executorach. Powód jest następujący:
Statyczne numery parametrów, które podajemy w spark-submit są dla całego czasu trwania zadania. Jeśli jednak dojdzie do alokacji dynamicznej, będą różne etapy, takie jak poniższe:
Jaka jest liczba wykonawców na początek:
Inicjalna liczba wykonawców (spark.dynamicAllocation.initialExecutors) na początek
Kontrolowanie liczby wykonawców dynamicznie:
Następnie w oparciu o obciążenie (zadania oczekujące) ile wykonawców zażądać. Byłby to ostatecznie numer, który podajemy w spark-submit w sposób statyczny. Tak więc po ustawieniu początkowych numerów executorów, przechodzimy do numerów min (spark.dynamicAllocation.minExecutors) i max (spark.dynamicAllocation.maxExecutors).
Kiedy poprosić o nowe executory lub oddać obecne executory:
Kiedy poprosić o nowe executory (spark.dynamicAllocation.schedulerBacklogTimeout) – Oznacza to, że przez tyle czasu były oczekujące zadania. Tak więc żądanie liczby executorów żądanych w każdej rundzie wzrasta wykładniczo z poprzedniej rundy. Na przykład, aplikacja doda 1 executor w pierwszej rundzie, a następnie 2, 4, 8 i tak dalej executorów w kolejnych rundach. W pewnym momencie powyższa właściwość max wchodzi w grę.
Kiedy oddajemy executor jest ustawiony przy użyciu spark.dynamicAllocation.executorIdleTimeout.
Podsumowując, jeśli potrzebujemy większej kontroli nad czasem wykonania zadania, monitoruj zadanie pod kątem nieoczekiwanej objętości danych statyczne liczby pomogłyby. Przechodząc na dynamiczne, zasoby byłyby wykorzystywane w tle, a zadania związane z nieoczekiwaną objętością mogłyby wpłynąć na inne aplikacje.
.