
Pierwszą rzeczą, którą musimy zrozumieć, jest natura zmiennych i to, jak zmienne są wykorzystywane w projekcie badania, aby odpowiedzieć na pytania badawcze. W tym rozdziale poznasz:
- różne rodzaje zmiennych w badaniach ilościowych,
- kwestie związane z pytaniem o jednostkę analizy.
Zrozumienie zmiennych ilościowych
Rodzeń słowa zmienna jest związany ze słowem „różnić się”, co powinno pomóc nam zrozumieć, czym mogą być zmienne. Zmienne to elementy, jednostki lub czynniki, które mogą się zmieniać (vary); na przykład, temperatura na zewnątrz, koszt benzyny za galon, waga osoby i nastrój osób w twojej dalszej rodzinie są zmienne. Innymi słowy, mogą one mieć różne wartości w różnych warunkach lub dla różnych ludzi.
Używamy zmiennych do opisania cech lub czynników zainteresowania. Przykłady mogą obejmować liczbę członków w różnych gospodarstwach domowych, odległość do źródeł zdrowej żywności w różnych dzielnicach, stosunek liczby wykładowców pracy socjalnej do liczby studentów w programie BSW lub MSW, odsetek osób z różnych grup rasowych/etnicznych przebywających w więzieniu, koszt transportu w celu otrzymania usług w ramach programu pracy socjalnej lub wskaźnik śmiertelności niemowląt w różnych hrabstwach. W badaniach interwencji w pracy socjalnej, zmienne mogą obejmować charakterystykę interwencji (intensywność, częstotliwość, czas trwania) i wyniki związane z interwencją.
Zmienne demograficzne. Pracownicy socjalni są często zainteresowani tym, co nazywamy zmiennymi demograficznymi. Zmienne demograficzne są używane do opisywania cech populacji, grupy lub próbki populacji. Przykłady często stosowanych zmiennych demograficznych to
- wiek,
- etniczność,
- pochodzenie narodowe,
- przynależność religijna,
- płeć,
- orientacja seksualna,
- stan cywilny/związek,
- stan zatrudnienia,
- przynależność polityczna,
- położenie geograficzne,
- poziom wykształcenia, i
- dochód.
Na poziomie bardziej makro, demografia społeczności lub organizacji często obejmuje jej wielkość; organizacje są często mierzone pod względem ich ogólnego budżetu.
Zmienne niezależne i zmienne zależne. Sposób, w jaki badacze myślą o zmiennych badania, ma ważne implikacje dla projektu badania. Badacze podejmują decyzje o tym, czy mają one służyć jako zmienne niezależne czy zmienne zależne. To rozróżnienie nie jest czymś nieodłącznie związanym ze zmienną, ale opiera się na tym, jak badacz decyduje się zdefiniować każdą zmienną. Niezależne zmienne to te, o których można myśleć jako o manipulowanych zmiennych „wejściowych”, podczas gdy zmienne zależne to te, w których wpływ lub „wyjście” tej zmiennej wejściowej będzie obserwowane.
Celowa manipulacja zmienną „wejściową” (niezależną) nie zawsze jest zaangażowana. Rozważmy przykład badania przeprowadzonego w Szwecji, w którym badano związek między byciem ofiarą maltretowania dzieci a późniejszą absencją w szkole średniej: nikt celowo nie manipulował tym, czy dzieci będą ofiarami maltretowania dzieci (Hagborg, Berglund, & Fahlke, 2017). Badacze postawili hipotezę, że naturalnie występujące różnice w zmiennej wejściowej (historia maltretowania dzieci) będą związane z systematyczną zmiennością w określonej zmiennej wynikowej (absencja szkolna). W tym przypadku zmienną niezależną była historia bycia ofiarą maltretowania dzieci, a zmienną zależną wynik absencji szkolnej. Innymi słowy, badacz stawia hipotezę, że zmienna niezależna powoduje wariację lub zmianę zmiennej zależnej. Oto jak może to wyglądać w schemacie, w którym „x” jest zmienną niezależną, a „y” zmienną zależną (uwaga: widziałeś to oznaczenie wcześniej, w Rozdziale 3, kiedy omawialiśmy logikę przyczynowo-skutkową):

Dla innego przykładu, rozważ badania wskazujące, że bycie ofiarą maltretowania dziecka jest związane z wyższym ryzykiem używania substancji w okresie dojrzewania (Yoon, Kobulsky, Yoon, & Kim, 2017). Zmienną niezależną w tym modelu byłoby posiadanie historii maltretowania dzieci. Zmienną zależną byłoby ryzyko używania substancji w okresie adolescencji. Ten przykład jest jeszcze bardziej rozbudowany, ponieważ precyzuje ścieżkę, za pomocą której zmienna niezależna (child maltreatment) może narzucić swój wpływ na zmienną zależną (używanie substancji w okresie adolescencji). Autorzy badania wykazali, że stres pourazowy (PTS) stanowił związek między wykorzystywaniem w dzieciństwie (fizycznym i seksualnym) a używaniem substancji w okresie dorastania.

Poświęć chwilę na wykonanie poniższego zadania.
Typy zmiennych ilościowych
Istnieją również inne znaczące sposoby myślenia o zmiennych zainteresowania. Rozważmy różne cechy zmiennych używanych w badaniach ilościowych. Tutaj badamy zmienne ilościowe jako kategoryczne, porządkowe lub przedziałowe w naturze. Cechy te mają wpływ zarówno na pomiar, jak i analizę danych.
Zmienne kategoryczne. Niektóre zmienne mogą przyjmować wartości, które się zmieniają, ale nie w znaczący sposób liczbowy. Zamiast tego, mogą one być zdefiniowane w kategoriach, które są możliwe. Logicznie rzecz biorąc, są one nazywane zmiennymi kategorycznymi. Oprogramowanie statystyczne i podręczniki czasami odnoszą się do zmiennych z kategoriami jako zmiennych nominalnych. O nominalnych można myśleć w kategoriach łacińskiego rdzenia „nom”, który oznacza „nazwę” i nie należy go mylić z liczbą. Nominalne oznacza to samo, co kategoryczne w opisywaniu zmiennych. Innymi słowy, zmienne kategoryczne lub nominalne są identyfikowane przez nazwy lub etykiety reprezentowanych kategorii. Na przykład kolor ostatniego samochodu, w którym jechałeś, byłby zmienną kategoryczną: niebieski, czarny, srebrny, biały, czerwony, zielony, żółty lub inny to kategorie zmiennej, którą moglibyśmy nazwać kolorem samochodu.
To, co jest ważne w przypadku zmiennych kategorycznych, to fakt, że kategorie te nie mają odpowiedniej numerycznej sekwencji lub kolejności. Nie ma żadnej numerycznej różnicy między różnymi kolorami samochodów, lub różnica między „tak” lub „nie” jako kategorie w odpowiedzi, czy jechałeś w niebieskim samochodzie. Nie ma żadnego dorozumianego porządku ani hierarchii kategorii „Latynos lub Latynoska” i „Nie Latynos lub Latynoska” w zmiennej dotyczącej pochodzenia etnicznego; nie ma też żadnego istotnego porządku w kategoriach zmiennych takich jak płeć, stan lub region geograficzny, w którym dana osoba mieszka, lub czy miejsce zamieszkania danej osoby jest własnością czy jest wynajmowane.
Jeśli badacz zdecydował się użyć liczb jako symboli związanych z kategoriami w takiej zmiennej, liczby są arbitralne – każda liczba jest zasadniczo tylko inną, krótszą nazwą dla każdej kategorii. Na przykład, zmienna płeć może być zakodowana w następujący sposób i nie stanowiłoby to żadnej różnicy, o ile kod byłby konsekwentnie stosowany.
| Opcja kodowania A | Kategorie zmiennych | Opcja kodowania B |
|---|---|---|
| 1 | mężczyzna | 2 |
| 2 | kobieta | 1 |
| 3 | inne niż samiec lub sama kobieta | 4 |
| 4 | prefer to answer | 3 |
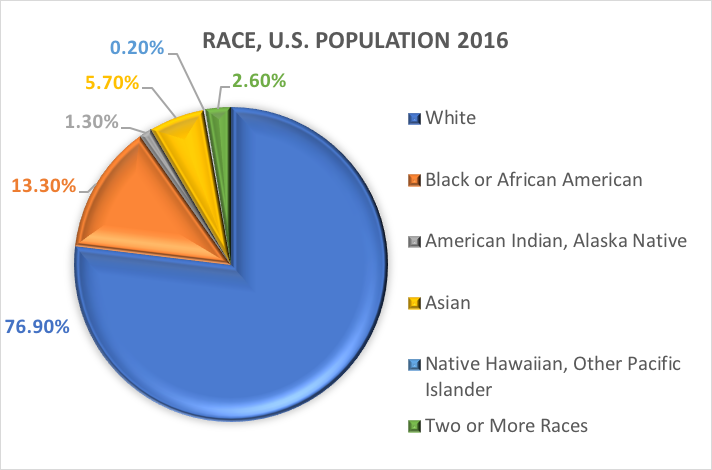
Rasa i pochodzenie etniczne.Jedną z najczęściej eksplorowanych zmiennych kategorycznych w pracy socjalnej i badaniach z zakresu nauk społecznych jest zmienna demograficzna odnosząca się do pochodzenia rasowego i/lub etnicznego danej osoby. Wiele badań wykorzystuje kategorie określone w poprzednich raportach U.S. Census Bureau. Oto co U.S. Census Bureau ma do powiedzenia na temat dwóch odrębnych zmiennych demograficznych, rasy i pochodzenia etnicznego (https://www.census.gov/mso/www/training/pdf/race-ethnicity-onepager.pdf):
Co to jest rasa? Census Bureau definiuje rasę jako samoidentyfikację osoby z jedną lub więcej grup społecznych. Osoba może zgłosić się jako biały, czarny lub afroamerykanin, Azjata, Indianin amerykański i rdzenny mieszkaniec Alaski, rdzenny Hawajczyk i inny mieszkaniec Wysp Pacyfiku lub innej rasy. Respondenci ankiety mogą zgłaszać wiele ras.
Co to jest etniczność? Etniczność określa czy dana osoba jest pochodzenia latynoskiego czy nie. Z tego powodu, pochodzenie etniczne jest podzielone na dwie kategorie, Latynos lub Latynoska i Nie Latynos lub Latynoska. Latynosi mogą zgłaszać się jako przedstawiciele dowolnej rasy.
Innymi słowy, Census Bureau definiuje dwie kategorie dla zmiennej zwanej pochodzeniem etnicznym (Latynos lub Latynos oraz Nie Latynos lub Latynos) oraz siedem kategorii dla zmiennej zwanej rasą. Chociaż te zmienne i kategorie są często stosowane w badaniach z zakresu nauk społecznych i pracy socjalnej, nie są one pozbawione krytyki.
W oparciu o te kategorie, oto co szacuje się, że jest prawdą o populacji Stanów Zjednoczonych w 2016 roku:
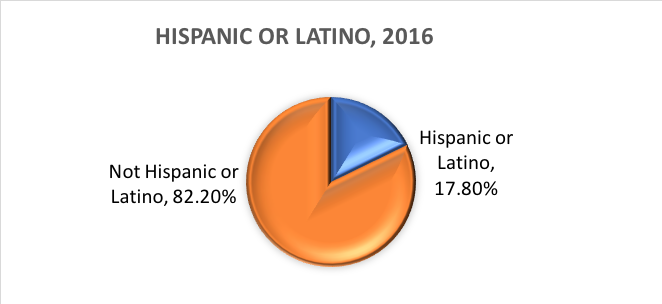
Zmienne dychotomiczne.Istnieje specjalna kategoria zmiennej kategorycznej z implikacjami dla pewnych analiz statystycznych. Zmienne kategoryczne składające się z dokładnie dwóch opcji, nie więcej i nie mniej nazywane są zmiennymi dychotomicznymi. Jednym z przykładów była dychotomia U.S. Census Bureau Hispanic/Latino i Non-Hispanic/Non-Latino ethnicity. Na przykład, badacze mogą chcieć porównać ludzi, którzy ukończyli leczenie z tymi, którzy przerwali leczenie przed jego ukończeniem. Ze względu na dwie kategorie, ukończone lub nieukończone, ta zmienna dotycząca ukończenia leczenia jest nie tylko kategoryczna, ale również dychotomiczna. Zmienne, w których jednostki odpowiadają „tak” lub „nie” są również dychotomiczne w naturze.
Przeszła tradycja traktowania płci jako męskiej lub żeńskiej jest innym przykładem zmiennej dychotomicznej. Istnieją jednak bardzo mocne argumenty za tym, by przestać traktować płeć w ten dychotomiczny sposób: większa różnorodność tożsamości płciowych jest ewidentnie istotna w pracy socjalnej w przypadku osób, których tożsamość nie pokrywa się z dychotomicznymi (zwanymi też binarnymi) kategoriami mężczyzna/kobieta lub mężczyzna/kobieta. Obejmują one takie kategorie jak agender, androgyniczny, bigender, cisgender, gender expansive, gender fluid, gender questioning, queer, transgender i inne.
Zmienne porządkowe. W przeciwieństwie do zmiennych kategorycznych, czasami kategorie zmiennej mają logiczną sekwencję numeryczną lub porządek. Porządkowe, z definicji, odnosi się do pozycji w serii. Zmienne z numerycznie istotnymi kategoriami nazywane są zmiennymi porządkowymi. Na przykład, istnieje implikowany porządek kategorii od najmniejszej do największej w przypadku zmiennej zwanej poziomem wykształcenia. Kategorie danych U.S. Kategorie danych spisu powszechnego dla tej zmiennej porządkowej to:
- brak
- 1st-4thgrade
- 5th-6thgrade
- 7th-8thgrade
- 9thgrade
- 10thgrade
- 11thgrade
- high school graduate
- some college, bez wykształcenia
- stopień naukowy, zawodowy
- associate’s degree akademicki
- bachelor’s degree
- master’s degree
- professional degree
- doctoral degree
Patrząc na dane szacunkowe 2016 Census Bureau dla tej zmiennej, możemy zauważyć, że kobiety przeważają nad mężczyznami w kategorii posiadania tytułu licencjata: z 47 718 000 osób w tej kategorii, 22 485 000 to mężczyźni, a 25 234 000 to kobiety. Podczas gdy ten wzorzec płci utrzymywał się dla osób otrzymujących tytuł magistra, wzorzec ten był odwrotny dla osób otrzymujących tytuł doktora: więcej mężczyzn niż kobiet uzyskało ten najwyższy poziom wykształcenia. Interesujące jest również to, że kobiety przeważały nad mężczyznami w dolnej części spektrum: 441 000 kobiet zgłosiło brak wykształcenia w porównaniu z 374 000 mężczyzn.
Jest to kolejny przykład zastosowania zmiennych porządkowych w badaniach w pracy socjalnej: kiedy osoby szukają leczenia w związku z problemem nadużywania alkoholu, pracownicy socjalni mogą chcieć wiedzieć, czy jest to ich pierwsza, druga, trzecia lub jakakolwiek inna ponumerowana poważna próba zmiany zachowań związanych z piciem. Uczestnicy włączeni do badania porównującego metody leczenia zaburzeń związanych z używaniem alkoholu podali, że badanie interwencyjne było dla nich od pierwszej do jedenastej znaczącej próby zmiany (Begun, Berger, Salm-Ward, 2011). Ta zmienna próby zmiany ma wpływ na to, jak pracownicy socjalni mogą interpretować dane oceniające interwencję, która nie była pierwszą próbą dla wszystkich zaangażowanych w nią osób.
Skale ocen. Rozważmy inny, ale powszechnie stosowany rodzaj zmiennej porządkowej: skale ocen. Osoby zajmujące się badaniami społecznymi, behawioralnymi i pracą socjalną często proszą uczestników badania o zastosowanie skali ocen w celu opisania ich wiedzy, postaw, przekonań, opinii, umiejętności lub zachowań. Ponieważ kategorie na takiej skali są uporządkowane w kolejności (od największej do najmniejszej lub od najmniejszej do największej), nazywamy je zmiennymi porządkowymi.

Przykłady obejmują posiadanie uczestników oceniających:
- jak bardzo zgadzają się lub nie zgadzają z pewnymi stwierdzeniami (wcale do bardzo);
- jak często angażują się w pewne zachowania (nigdy do zawsze);
- jak często angażują się w pewne zachowania (godzinowo, codziennie, tygodniowo, miesięcznie, rocznie lub rzadziej);
- jakość czyjegoś działania (słaba do doskonałej);
- jak bardzo byli zadowoleni ze swojego leczenia (bardzo niezadowoleni do bardzo zadowoleni)
- ich poziom zaufania (bardzo niski do bardzo wysokiego).
Zmienne interwałowe. Jeszcze inne zmienne przybierają wartości, które zmieniają się w znaczący sposób liczbowy. Z naszej listy zmiennych demograficznych, wiek jest częstym przykładem. Wartość liczbowa przypisana do indywidualnej osoby wskazuje liczbę lat, od kiedy dana osoba się urodziła (w przypadku niemowląt wartość liczbowa może wskazywać dni, tygodnie lub miesiące od urodzenia). Tutaj możliwe wartości zmiennej są uporządkowane, tak jak w przypadku zmiennych porządkowych, ale wprowadzona jest duża różnica: charakter odstępów pomiędzy możliwymi wartościami. W przypadku zmiennych przedziałowych „odległość” pomiędzy sąsiednimi możliwymi wartościami jest równa. Niektóre pakiety oprogramowania statystycznego i podręczniki używają terminu zmienna skalarna: jest to dokładnie to samo, co nazywamy zmienną interwałową.
Na przykład na poniższym wykresie różnica 1 uncji między spożyciem przez tę osobę 1 uncji lub 2 uncji alkoholu (poniedziałek, wtorek) jest dokładnie taka sama jak różnica 1 uncji między spożyciem 4 uncji lub 5 uncji (piątek, sobota). Gdybyśmy mieli narysować wykres możliwych punktów na skali, wszystkie byłyby jednakowo odległe; odstęp między dowolnymi dwoma punktami jest mierzony w standardowych jednostkach (w tym przykładzie są to uncje).
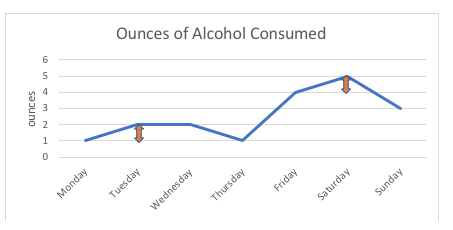
W przypadku zmiennych porządkowych, takich jak skala ocen, nikt nie może powiedzieć na pewno, że „odległość” między opcjami odpowiedzi „nigdy” i „czasami” jest taka sama jak „odległość” między „czasami” i „często”, nawet jeśli użyliśmy liczb do sekwencjonowania tych opcji odpowiedzi. Tak więc, skala ocen pozostaje porządkowa, a nie interwałowa.
To, co może stać się nieco mylące, to fakt, że niektóre programy statystyczne, takie jak SPSS, odnoszą się do zmiennej interwałowej jako zmiennej „skali”. Wiele zmiennych używanych w badaniach pracy socjalnej jest zarówno uporządkowanych, jak i ma równe odległości między punktami. Rozważmy na przykład zmienną kolejności urodzenia. Ta zmienna jest przedziałowa, ponieważ:
- możliwe wartości są uporządkowane (np. trzecie urodzone dziecko przyszło po pierwszym i drugim urodzeniu, a przed czwartym urodzeniem), a
- „odległości” lub przedziały są mierzone w równoważnych jednostkach jednoosobowych.
Zmienne ciągłe. Istnieje specjalny rodzaj liczbowych zmiennych interwałowych, które nazywamy zmiennymi ciągłymi. Zmienna taka jak wiek może być traktowana jako zmienna ciągła. Wiek jest porządkowy w naturze, ponieważ wyższe liczby oznaczają coś w stosunku do mniejszych liczb. Wiek spełnia również nasze kryteria zmiennej interwałowej, jeśli mierzymy go w latach (lub miesiącach, tygodniach lub dniach), ponieważ jest on porządkowy i istnieje taka sama „odległość” między 15 a 30 rokiem życia, jak między 40 a 55 rokiem życia (15 lat kalendarzowych). To, co sprawia, że jest to zmienna ciągła, to fakt, że istnieją również możliwe, znaczące punkty „frakcji” między dowolnymi dwoma przedziałami. Na przykład, osoba może mieć 20½ (20,5) lub 20¼ (20,25) lub 20¾ (20,75) lat; nie jesteśmy ograniczeni tylko do liczb całkowitych dla wieku. Przez kontrast, kiedy spojrzeliśmy na kolejność urodzenia, nie możemy mieć znaczącej frakcji osoby pomiędzy dwoma pozycjami na skali.
Specjalny przypadek dochodu. Jedną z najbardziej nadużywanych zmiennych w badaniach z zakresu nauk społecznych i pracy socjalnej jest zmienna związana z dochodem. Rozważmy przykład dotyczący dochodu gospodarstwa domowego (niezależnie od tego, ile osób jest w tym gospodarstwie). Zmienna ta może być kategoryczna (nominalna), porządkowa lub interwałowa (skala) w zależności od tego, jak jest traktowana.
Przykład kategoryczny: W zależności od charakteru pytań badawczych, badacz może po prostu wybrać dychotomiczne kategorie „wystarczająco zasobne” i „niewystarczająco zasobne” do klasyfikacji gospodarstw domowych, w oparciu o jakąś standardową metodę obliczeniową. Można je nazwać „ubogimi” i „nieubogimi”, jeśli do kategoryzacji gospodarstw domowych stosuje się próg granicy ubóstwa. Te odrębne kategorie zmiennej dochodu nie są sensownie uporządkowane w sposób numeryczny, więc jest to zmienna kategoryczna.
Przykład porządkowy: Kategorie do klasyfikacji gospodarstw domowych mogą być uporządkowane od niskich do wysokich. Na przykład, te kategorie rocznego dochodu są powszechne w badaniach rynku:
- Mniej niż 25 000 dolarów.
- $25 000 do 34 999 dolarów.
- $35 000 do 49 999 dolarów.
- $50 000 do 74 999 dolarów.
- $75 000 do 99 999 dolarów.
- $100,000 do $149,999.
- $150,000 do $199,999.
- $200,000 lub więcej.
Zauważ, że kategorie nie są jednakowej wielkości – „odległość” między parami kategorii nie zawsze jest taka sama. Zaczynają się od około 10 000 dolarów, przechodzą do 25 000 dolarów, a kończą na około 50 000 dolarów.
Przykład interwałowy. Jeśli badacz poprosił uczestników badania o podanie rzeczywistej kwoty w dolarach dla dochodu gospodarstwa domowego, zobaczylibyśmy zmienną interwałową. Możliwe wartości są uporządkowane, a przedział między dowolnymi możliwymi sąsiednimi jednostkami wynosi $1 (o ile nie są używane ułamki dolara lub centy). Tak więc, dochód $10,452 jest w tej samej odległości na kontinuum od $9,452 i $11,452-$1,000 w obie strony.

Specjalny przypadek wieku. Podobnie jak w przypadku dochodu, „wiek” może oznaczać różne rzeczy w różnych badaniach. Wiek jest zazwyczaj wskaźnikiem „czasu od urodzenia”. Możemy obliczyć wiek osoby poprzez odjęcie zmiennej daty urodzenia od daty pomiaru (dzisiejsza data minus data urodzenia). Dla dorosłych, wiek jest zwykle mierzony w latach, gdzie sąsiednie możliwe wartości są oddalone o 1 rok: 18, 19, 20, 21, 22, i tak dalej. Tak więc zmienna wieku może być ciągłym typem zmiennej interwałowej.
Jednakże badacz może chcieć rozbić dane dotyczące wieku na uporządkowane kategorie lub grupy wiekowe. Te nadal będą porządkowe, ale mogą już nie być przedziałowe, jeśli przyrosty między możliwymi wartościami nie są równoważnymi jednostkami. Na przykład, jeżeli jesteśmy bardziej zainteresowani wiekiem reprezentującym określone okresy rozwoju człowieka, przedziały wiekowe mogą nie być równe pod względem rozpiętości między kryteriami wieku. Ewentualnie mogą to być:
- Niemowlęctwo (od urodzenia do 18 miesięcy)
- Toddlerhood (od 18 miesięcy do 2 ½ lat)
- Preschool (od 2 ½ do 5 lat)
- Wiek szkolny (od 6 do 11 lat)
- Dorosłość (od 12 do 17 lat)
- Wchodząca dorosłość (od 18 do 25 lat)
- Dorosłość (od 26 do 45 lat)
- Średnia dorosłość (od 46 do 60 lat)
- Młoda-Stara dorosłość (60 do 74 lat)
- Średnia dorosłość (75 do 84 lat)
- Stara dorosłość (85 lub więcej lat)
.
Wiek może być nawet traktowany jako zmienna ściśle kategoryczna (nie-ordinalna). Na przykład, jeśli zmienną zainteresowania jest to, czy ktoś jest w wieku legalnego picia alkoholu (21 lat lub starszy), czy nie. Mamy dwie kategorie – spełnia lub nie spełnia kryteriów legalnego wieku picia w Stanach Zjednoczonych – i każda z nich może być zakodowana jako „1”, a druga jako „0” lub „2” bez różnicy w znaczeniu.
Jaka jest „właściwa” odpowiedź na pytanie, jak mierzyć wiek (lub dochód)? Odpowiedź brzmi: „to zależy”. To, co zależy, to charakter pytania badawczego: która konceptualizacja wieku (lub dochodu) jest najbardziej odpowiednia dla projektowanego badania.
Zmienne alfanumeryczne. Wreszcie, istnieją dane, które nie pasują do żadnej z tych klasyfikacji. Czasami informacje, które znamy, są w postaci adresu lub numeru telefonu, imienia lub nazwiska, kodu pocztowego lub innych fraz. Tego rodzaju informacje są czasami nazywane zmiennymi alfanumerycznymi. Rozważmy na przykład zmienną „adres”: adres danej osoby może składać się ze znaków numerycznych (numer domu) i literowych (pisownia nazwy ulicy, miasta i stanu), np. 1600 Pennsylvania Ave. NW, Washington, DC, 20500.

W rzeczywistości w tym przykładzie adresu występuje kilka zmiennych:
- adres ulicy: 1600 Pennsylvania Ave.
- miasto (i „stan”): Washington, DC
- kod pocztowy: 20500.
Ten typ informacji nie reprezentuje określonych kategorii ilościowych lub wartości o systematycznym znaczeniu w danych. Są one również czasami nazywane zmiennymi „łańcuchowymi” w niektórych pakietach oprogramowania, ponieważ składają się z ciągu symboli. Aby być użytecznym dla badacza, taka zmienna musiałaby być przekształcona lub przekodowana na znaczące wartości.
Uwaga o jednostce analizy
Ważną rzeczą, o której należy pamiętać w myśleniu o zmiennych jest to, że dane mogą być zbierane na wielu różnych poziomach obserwacji. Badane elementy mogą być indywidualnymi komórkami, systemami organów lub osobami. Lub, poziom obserwacji może być parami osób, takich jak pary, braci i sióstr, lub rodziców i dzieci. W tym przypadku badacz może zbierać informacje o parze od każdej osoby, ale patrzy na dane każdej pary. Tak więc powiedzielibyśmy, że jednostką analizy jest para lub dyada, a nie każda indywidualna osoba. Jednostką analizy może być również większa grupa: na przykład, dane mogą być zbierane od każdego z uczniów w całej klasie, gdzie jednostką analizy są klasy w szkole lub systemie szkolnym. Jednostka analizy może też być na poziomie dzielnic, programów, organizacji, hrabstw, państw, a nawet narodów. Na przykład, wiele zmiennych wykorzystywanych jako wskaźniki bezpieczeństwa żywnościowego na poziomie społeczności, takich jak przystępność cenowa i dostępność, opiera się na danych zebranych z poszczególnych gospodarstw domowych (Kaiser, 2017). Jednostką analizy w badaniach wykorzystujących te wskaźniki byłyby porównywane społeczności. To rozróżnienie ma ważne implikacje dotyczące pomiaru i analizy danych.
Przypomnienie o zmiennych versus poziomach zmiennych
Badanie można opisać pod względem liczby kategorii zmiennych, lub poziomów, które są porównywane. Na przykład, można zobaczyć badanie opisane jako projekt 2 X 2 – wymawiane jako projekt dwa na dwa. Oznacza to, że istnieją 2 możliwe kategorie dla pierwszej zmiennej i 2 możliwe kategorie dla drugiej zmiennej – obie są zmiennymi dychotomicznymi. Badanie porównujące 2 kategorie zmiennej „zaburzenia związane z używaniem alkoholu” (kategorie dla spełniających kryteria, tak lub nie) z 2 kategoriami zmiennej „zaburzenia związane z używaniem substancji nielegalnych” (kategorie dla spełniających kryteria, tak lub nie) miałoby 4 możliwe wyniki (matematycznie, 2 x 2=4) i mogłoby być diagramowane w ten sposób (dane oparte na proporcjach z badania NSDUH z 2016 roku, przedstawione w SAMHSA, 2017):
| Zaburzenia związane z używaniem substancji nielegalnych (SUD) | |||
|---|---|---|---|
|
Zaburzenia związane z używaniem alkoholu (AUD) |
Nie | Tak | |
| Nie | 500 | 10 | |
| Tak | 26 | 4 | |
Odczytanie 4 komórek w tej tabeli 2 X 2 mówi nam, że w tym (hipotetycznym) badaniu 540 osób, 500 nie spełniało kryteriów dla zaburzeń związanych z używaniem alkoholu lub substancji nielegalnych (Nie, Nie); 26 spełniało kryteria tylko zaburzenia używania alkoholu (Tak, Nie); 10 spełniało kryteria tylko zaburzenia używania substancji nielegalnych (Nie, Tak), a 4 spełniały kryteria zarówno zaburzenia używania alkoholu, jak i substancji nielegalnych (Tak, Tak). Ponadto, przy zastosowaniu odrobiny matematyki, możemy zauważyć, że łącznie 30 osób miało zaburzenia związane z używaniem alkoholu (26 + 4), a 14 osób miało zaburzenia związane z używaniem substancji nielegalnych (10 + 4). I, możemy zobaczyć, że 40 miał jakiś rodzaj zaburzenia używania substancji (26 + 10 + 4).
 Aby to rozróżnienie między zmiennymi i poziomami zmiennych lub kategorii krystalicznie jasne, rozważmy jeszcze jeden przykład: projekt badania 2 X 3. Po pierwsze, robiąc matematykę, powinniśmy zobaczyć 6 możliwych wyników (komórek). Po drugie, wiemy, że pierwsza zmienna (grupa wiekowa) ma 2 kategorie (poniżej 30 roku życia, 30 lub więcej lat), a druga zmienna (status zatrudnienia) ma 3 kategorie (w pełni zatrudniony, częściowo zatrudniony, bezrobotny). Tym razem 6 komórek naszego projektu jest pustych, ponieważ czekamy na dane.
Aby to rozróżnienie między zmiennymi i poziomami zmiennych lub kategorii krystalicznie jasne, rozważmy jeszcze jeden przykład: projekt badania 2 X 3. Po pierwsze, robiąc matematykę, powinniśmy zobaczyć 6 możliwych wyników (komórek). Po drugie, wiemy, że pierwsza zmienna (grupa wiekowa) ma 2 kategorie (poniżej 30 roku życia, 30 lub więcej lat), a druga zmienna (status zatrudnienia) ma 3 kategorie (w pełni zatrudniony, częściowo zatrudniony, bezrobotny). Tym razem 6 komórek naszego projektu jest pustych, ponieważ czekamy na dane.
| Stan zatrudnienia | ||||
|---|---|---|---|---|
|
Grupa wiekowa |
W pełni zatrudniony | Częściowo Employed | Unemployed | |
| <30 | ||||
| ≥30 | ||||
Tym samym, Kiedy widzisz opis projektu badania, który wygląda jak dwie liczby pomnożone, jest to zasadniczo informacja o tym, ile kategorii lub poziomów każdej zmiennej istnieje i prowadzi do zrozumienia, ile komórek lub możliwych wyników istnieje. 3 X 3 projekt ma 9 komórek, 3 X 4 projekt ma 12 komórek, i tak dalej. Ta kwestia staje się ważna ponownie, gdy omawiamy wielkość próby w Rozdziale 6.
Wykonaj następujące ćwiczenie w podręczniku:
- SWK 3401.3-4.1 Rozpoczynanie wprowadzania danych
Podsumowanie rozdziału
Podsumowując, badacze projektują wiele swoich badań ilościowych, aby przetestować hipotezy dotyczące związków między zmiennymi. Zrozumienie natury zaangażowanych zmiennych pomaga w zrozumieniu i ocenie przeprowadzonych badań. Zrozumienie rozróżnienia pomiędzy różnymi typami zmiennych, jak również pomiędzy zmiennymi i kategoriami, ma ważne implikacje dla projektu badania, pomiaru i prób. W następnym rozdziale przeanalizujemy, między innymi, zależności między naturą zmiennych badanych w badaniach ilościowych a tym, jak badacze podchodzą do pomiaru tych zmiennych.
Poświęć chwilę na wykonanie poniższego zadania.
.