
- O scurtă trecere în revistă a celor mai bune lucrări pentru clasificarea imaginilor într-un deceniu pentru a vă începe învățarea de viziune computerizată
- 1998: LeNet
- 2012: AlexNet
- 2014: VGG
- 2014: GoogLeNet
- 2015: Batch Normalization
- 2015: ResNet
- 2016: Xception
- 2017: MobileNet
- 2017: NASNet
- 2019: EfficientNet
- 2014: SPPNet
- 2016: DenseNet
- 2017: SENet
- 2017: ShuffleNet
- 2018: Bag of Tricks
- Concluzie
O scurtă trecere în revistă a celor mai bune lucrări pentru clasificarea imaginilor într-un deceniu pentru a vă începe învățarea de viziune computerizată

Viziunea computerizată este un subiect pentru a converti imaginile și videoclipurile în mașini desemnale inteligibile de către mașini. Cu aceste semnale, programatorii pot controla mai departe comportamentul mașinii pe baza acestei înțelegeri de nivel înalt. Printre numeroasele sarcini de viziune pe calculator, clasificarea imaginilor este una dintre cele mai fundamentale. Aceasta nu numai că poate fi utilizată în multe produse reale, cum ar fi etichetarea Google Photo și moderarea conținutului prin inteligență artificială, dar deschide, de asemenea, calea pentru o mulțime de sarcini de viziune mai avansate, cum ar fi detectarea obiectelor și înțelegerea videoclipurilor. Din cauza schimbărilor rapide din acest domeniu de la descoperirea învățării profunde, începătorii consideră adesea că învățarea este prea copleșitoare pentru începători. Spre deosebire de subiectele tipice de inginerie software, nu există multe cărți bune despre clasificarea imaginilor cu ajutorul DCNN, iar cel mai bun mod de a înțelege acest domeniu este prin citirea lucrărilor academice. Dar ce lucrări să citim? De unde să încep? În acest articol, voi prezenta 10 cele mai bune lucrări de citit pentru începători. Cu aceste lucrări, putem vedea cum evoluează acest domeniu și cum cercetătorii au adus idei noi pe baza rezultatelor cercetărilor anterioare. Cu toate acestea, este totuși util pentru dvs. să vă faceți o imagine de ansamblu, chiar dacă ați lucrat deja în acest domeniu pentru o vreme. Așadar, haideți să începem.
1998: LeNet
Gradient-based Learning Applied to Document Recognition

Introdus în 1998, LeNet stabilește o bază pentru viitoarele cercetări de clasificare a imaginilor care utilizează rețeaua neuronală de convoluție. Multe tehnici CNN clasice, cum ar fi straturile de punere în comun, straturile complet conectate, straturile de umplutură și straturile de activare, sunt utilizate pentru a extrage caracteristici și a face o clasificare. Cu o funcție de pierdere de eroare medie pătratică și 20 de epoci de formare, această rețea poate atinge o precizie de 99,05% pe setul de testare MNIST. Chiar și după 20 de ani, multe rețele de clasificare de ultimă generație încă urmează acest model în general.
2012: AlexNet
ImageNet Classification with Deep Convolutional Neural Networks

.
Deși LeNet a obținut un rezultat excelent și a arătat potențialul CNN, dezvoltarea în acest domeniu a stagnat timp de un deceniu din cauza puterii de calcul limitate și a cantității de date. Se părea că CNN poate rezolva doar unele sarcini ușoare, cum ar fi recunoașterea cifrelor, dar pentru caracteristici mai complexe, cum ar fi fețele și obiectele, un extractor de caracteristici HarrCascade sau SIFT cu un clasificator SVM era o abordare mai preferată.
Cu toate acestea, în 2012 ImageNet Large Scale Visual Recognition Challenge, Alex Krizhevsky a propus o soluție bazată pe CNN pentru această provocare și a crescut drastic precizia top-5 a setului de testare ImageNet de la 73,8% la 84,7%. Abordarea lor moștenește ideea CNN cu mai multe straturi de la LeNet, dar a crescut mult dimensiunea CNN-ului. După cum puteți vedea în diagrama de mai sus, intrarea este acum de 224×224, față de 32×32 în cazul LeNet, de asemenea, mai multe nuclee de convoluție au 192 de canale, față de cele 6 ale LeNet. Deși designul nu s-a schimbat prea mult, cu sute de ori mai mulți parametri, capacitatea rețelei de a capta și reprezenta caracteristici complexe s-a îmbunătățit și ea de sute de ori. Pentru a antrena un model atât de mare, Alex a folosit două GPU GTX 580 cu câte 3 GB de RAM pentru fiecare, ceea ce a deschis o nouă tendință de antrenament pe GPU. De asemenea, utilizarea neliniarității ReLU a ajutat, de asemenea, la reducerea costului de calcul.
Pe lângă faptul că a adus mult mai mulți parametri pentru rețea, a explorat, de asemenea, problema de supraadaptare adusă de o rețea mai mare prin utilizarea unui strat Dropout. Metoda sa de normalizare a răspunsului local nu a obținut prea multă popularitate ulterior, dar a inspirat alte tehnici importante de normalizare, cum ar fi BatchNorm, pentru a combate problema saturației gradientului. În concluzie, AlexNet a definit cadrul de facto al rețelelor de clasificare pentru următorii 10 ani: o combinație de Convoluție, activare neliniară ReLu, MaxPooling și strat Dense.
2014: VGG
Rețele convoluționale foarte profunde pentru rețele de clasificare de mari dimensiuni.Scale Image Recognition
Cu un succes atât de mare al utilizării CNN pentru recunoașterea vizuală, întreaga comunitate de cercetare a explodat și toți au început să cerceteze de ce funcționează atât de bine această rețea neuronală. De exemplu, în „Visualizing and Understanding Convolutional Networks” din 2013, Matthew Zeiler a discutat despre modul în care CNN preia caracteristicile și a vizualizat reprezentările intermediare. Și, dintr-o dată, toată lumea a început să realizeze că CNN este viitorul vederii computerizate începând cu 2014. Dintre toți acești adepți imediați, rețeaua VGG de la Visual Geometry Group este cea care atrage cel mai mult atenția. A obținut un rezultat remarcabil de 93,2 % de acuratețe de top 5 și 76,3 % de acuratețe de top 1 pe setul de testare ImageNet.
După proiectarea AlexNet, rețeaua VGG are două actualizări majore: 1) VGG nu numai că a folosit o rețea mai largă ca AlexNet, dar și mai profundă. VGG-19 are 19 straturi de convoluție, în comparație cu cele 5 de la AlexNet. 2) VGG a demonstrat, de asemenea, că câteva filtre mici de convoluție 3×3 pot înlocui un singur filtru 7×7 sau chiar 11×11 din AlexNet, obținând performanțe mai bune și reducând în același timp costul de calcul. Datorită acestui design elegant, VGG a devenit, de asemenea, rețeaua de bază a multor rețele de pionierat în alte sarcini de viziune pe calculator, cum ar fi FCN pentru segmentarea semantică și Faster R-CNN pentru detectarea obiectelor.
Cu o rețea mai profundă, dispariția gradientului din back-propagarea multistraturi devine o problemă mai mare. Pentru a face față acesteia, VGG a discutat, de asemenea, despre importanța pre-antrenării și a inițializării ponderilor. Această problemă limitează cercetătorii să continue să adauge mai multe straturi, altfel, rețeaua va fi foarte greu de convergent. Dar vom vedea o soluție mai bună pentru aceasta după doi ani.
2014: GoogLeNet
Going Deeper with Convolutions

VGG are o structură arătoasă și ușor de înțeles, dar performanța sa nu este cea mai bună dintre toate finalistele competițiilor ImageNet 2014. GoogLeNet, cunoscut sub numele de InceptionV1, a câștigat premiul final. La fel ca VGG, una dintre principalele contribuții ale GoogLeNet este împingerea limitei de adâncime a rețelei cu o structură de 22 de straturi. Acest lucru a demonstrat din nou că a merge mai adânc și mai larg este într-adevăr direcția corectă pentru a îmbunătăți acuratețea.
Dincolo de VGG, GoogLeNet a încercat să abordeze direct problemele de calcul și de diminuare a gradientului, în loc să propună o soluție de rezolvare cu o mai bună inițializare a schemelor și a greutăților preinstruite.

În primul rând, a explorat ideea de proiectare asimetrică a rețelei folosind un modul numit Inception (vezi diagrama de mai sus). În mod ideal, ar dori să urmărească convoluții rare sau straturi dense pentru a îmbunătăți eficiența funcțiilor, dar designul hardware modern nu a fost adaptat pentru acest caz. Astfel, ei au crezut că o sparsity la nivelul topologiei rețelei ar putea, de asemenea, să ajute la fuziunea caracteristicilor, utilizând în același timp capacitățile hardware existente.
În al doilea rând, atacă problema costurilor ridicate de calcul prin împrumutarea unei idei dintr-o lucrare numită „Network in Network”. Practic, se introduce un filtru de convoluție 1×1 pentru a reduce dimensiunile caracteristicilor înainte de a trece prin operații de calcul grele precum un nucleu de convoluție 5×5. Această structură se numește ulterior „Bottleneck” și este utilizată pe scară largă în multe rețele următoare. Similar cu „Rețeaua în rețea”, a folosit, de asemenea, un strat de punere în comun a mediei pentru a înlocui stratul final complet conectat pentru a reduce și mai mult costurile.
În al treilea rând, pentru a ajuta gradienții să circule către straturile mai profunde, GoogLeNet a folosit, de asemenea, supravegherea pe unele ieșiri ale straturilor intermediare sau ieșiri auxiliare. Acest design nu este destul de popular mai târziu în rețeaua de clasificare a imaginilor din cauza complexității, dar devine mai popular în alte domenii ale vederii computerizate, cum ar fi rețeaua Hourglass în estimarea poziției.
Ca urmare, această echipă Google a scris mai multe lucrări pentru această serie Inception. „Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift” reprezintă InceptionV2. „Rethinking the Inception Architecture for Computer Vision” din 2015 reprezintă InceptionV3. Iar „Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning” din 2015 reprezintă InceptionV4. Fiecare lucrare a adăugat mai multe îmbunătățiri față de rețeaua Inception originală și a obținut un rezultat mai bun.
2015: Batch Normalization
Batch Normalization: Accelerarea formării rețelelor profunde prin reducerea deplasării covariatelor interne
Rețeaua Inception i-a ajutat pe cercetători să atingă o precizie supraomenească pe setul de date ImageNet. Cu toate acestea, ca metodă de învățare statistică, CNN este foarte mult constrânsă de natura statistică a unui set de date de instruire specific. Prin urmare, pentru a obține o acuratețe mai bună, trebuie, de obicei, să calculăm în prealabil media și abaterea standard a întregului set de date și să le folosim pentru a ne normaliza mai întâi datele de intrare pentru a ne asigura că majoritatea intrărilor de strat din rețea sunt apropiate, ceea ce se traduce printr-o mai bună reacție de activare. Această abordare aproximativă este foarte greoaie și, uneori, nu funcționează deloc pentru o nouă structură de rețea sau pentru un nou set de date, astfel încât modelul de învățare profundă este în continuare considerat dificil de antrenat. Pentru a rezolva această problemă, Sergey Ioffe și Chritian Szegedy, cel care a creat GoogLeNet, au decis să inventeze ceva mai inteligent numit Batch Normalization.

Ideea de normalizare a loturilor nu este dificilă: Putem folosi statisticile unei serii de mini loturi pentru a aproxima statisticile întregului set de date, atâta timp cât ne antrenăm pentru un timp suficient de lung. De asemenea, în loc să calculăm manual statisticile, putem introduce încă doi parametri învățabili „scale” și „shift” pentru ca rețeaua să învețe singură cum să normalizeze fiecare strat.
Diagrama de mai sus a arătat procesul de calcul al valorilor de normalizare pe loturi. După cum putem vedea, luăm media întregului mini-lot și calculăm și varianța. Apoi, putem normaliza intrarea cu această medie și varianță a mini-lotului. În cele din urmă, cu un parametru de scară și unul de deplasare, rețeaua va învăța să adapteze rezultatul normalizat al lotului pentru a se potrivi cel mai bine următoarelor straturi, de obicei ReLU. Un avertisment este că nu dispunem de informații despre mini-lot în timpul inferenței, așa că o soluție este să calculăm o medie și o varianță medie mobilă în timpul antrenamentului și apoi să folosim aceste medii mobile în calea inferenței. Această mică inovație are un impact atât de mare, iar toate rețelele ulterioare încep să o folosească imediat.
2015: ResNet
Deep Residual Learning for Image Recognition
2015 poate fi cel mai bun an pentru viziunea computerizată din ultimul deceniu, am văzut atât de multe idei grozave apărând nu numai în clasificarea imaginilor, ci și în tot felul de sarcini de viziune computerizată, cum ar fi detectarea obiectelor, segmentarea semantică etc. Cel mai mare progres al anului 2015 aparține unei noi rețele numite ResNet, sau rețele reziduale, propusă de un grup de cercetători chinezi de la Microsoft Research Asia.

După cum am discutat mai devreme pentru rețeaua VGG, cel mai mare obstacol pentru a deveni și mai profundă este problema dispariției gradientului, adică.adică, derivatele devin din ce în ce mai mici atunci când se propagă înapoi prin straturi mai adânci și, în cele din urmă, ajunge la un punct pe care arhitectura modernă a calculatoarelor nu îl poate reprezenta în mod semnificativ. GoogLeNet a încercat să atace acest aspect prin utilizarea supravegherii auxiliare și a modulului de incipiență asimetrică, dar nu ameliorează problema decât într-o mică măsură. Dacă dorim să folosim 50 sau chiar 100 de straturi, va exista o modalitate mai bună pentru ca gradientul să curgă prin rețea? Răspunsul de la ResNet este de a utiliza un modul rezidual.

ResNet a adăugat o scurtătură de identitate la ieșire, astfel încât fiecare modul rezidual să nu poată prezice cel puțin ceea ce este intrarea, fără să se piardă în sălbăticie. Un lucru și mai important este că, în loc de a spera ca fiecare strat să se potrivească direct la cartografierea caracteristicilor dorite, modulul rezidual încearcă să învețe diferența dintre ieșire și intrare, ceea ce face sarcina mult mai ușoară, deoarece câștigul de informație necesar este mai mic. Imaginați-vă că învățați matematică, pentru fiecare problemă nouă, vi se oferă o soluție a unei probleme similare, așa că tot ce trebuie să faceți este să extindeți această soluție și să încercați să o faceți să funcționeze. Acest lucru este mult mai ușor decât să te gândești la o soluție complet nouă pentru fiecare problemă pe care o întâlnești. Sau, așa cum spunea Newton, putem sta pe umerii uriașilor, iar intrarea de identitate este acel uriaș pentru modulul rezidual.
În plus față de cartografierea identității, ResNet a împrumutat, de asemenea, gâturile de îmbulzeală și normalizarea loturilor de la rețelele Inception. În cele din urmă, a reușit să construiască o rețea cu 152 de straturi de convoluție și a obținut o precizie de top 1 de 80,72% pe ImageNet. Abordarea reziduală devine, de asemenea, o opțiune implicită pentru multe alte rețele ulterioare, cum ar fi Xception, Darknet etc. De asemenea, datorită designului său simplu și frumos, este încă utilizat pe scară largă în multe sisteme de recunoaștere vizuală de producție din zilele noastre.
Există multe alte invariante apărute ca urmare a succesului înregistrat de rețeaua reziduală. În „Identity Mappings in Deep Residual Networks”, autorul original al ResNet a încercat să pună activarea înaintea modulului rezidual și a obținut un rezultat mai bun, iar acest design este numit ulterior ResNetV2. De asemenea, într-o lucrare din 2016 „Aggregated Residual Transformations for Deep Neural Networks” (Transformări reziduale agregate pentru rețele neuronale profunde), cercetătorii au propus ResNeXt care a adăugat ramuri paralele pentru modulele reziduale pentru a agrega ieșirile diferitelor transformări.
2016: Xception
Xception: Deep Learning with Depthwise Separable Convolutions

Cu ocazia lansării ResNet, se părea că cele mai multe dintre fructele cu potențial scăzut din clasificatorul de imagini au fost deja prinse. Cercetătorii au început să se gândească la care este mecanismul intern al magiei CNN. Deoarece convoluția încrucișată introduce de obicei o tonă de parametri, rețeaua Xception a ales să investigheze această operațiune pentru a înțelege o imagine completă a efectului său.
Ca și numele său, Xception provine din rețeaua Inception. În modulul Inception, mai multe ramuri ale diferitelor transformări sunt agregate împreună pentru a obține o dispersie a topologiei. Dar de ce a funcționat această sparsity? Autorul Xception, care este și autorul cadrului Keras, a extins această idee la un caz extrem în care un fișier de convoluție 3×3 corespunde unui singur canal de ieșire înainte de o concatenare finală. În acest caz, aceste nuclee de convoluție paralele formează de fapt o nouă operație numită convoluție în funcție de adâncime.

Cum se arată în diagrama de mai sus, spre deosebire de convoluția tradițională în care toate canalele sunt incluse pentru un singur calcul, convoluția în profunzime calculează doar convoluția pentru fiecare canal în parte și apoi concatenează rezultatul împreună. Acest lucru reduce schimbul de caracteristici între canale, dar reduce, de asemenea, o mulțime de conexiuni, rezultând astfel un strat cu mai puțini parametri. Cu toate acestea, această operațiune va produce același număr de canale ca și intrarea (sau un număr mai mic de canale dacă grupați două sau mai multe canale). Prin urmare, odată ce ieșirile canalelor sunt unite, avem nevoie de un alt filtru obișnuit 1×1, sau de o convoluție punctuală, pentru a crește sau a reduce numărul de canale, la fel ca și convoluția obișnuită.
Această idee nu provine inițial de la Xception. Este descrisă într-o lucrare intitulată „Learning visual representations at scale” (Învățarea reprezentărilor vizuale la scară) și este folosită ocazional și în InceptionV2. Xception a făcut un pas mai departe și a înlocuit aproape toate convoluțiile cu acest nou tip. Iar rezultatul experimentului s-a dovedit a fi destul de bun. Depășește ResNet și InceptionV3 și a devenit o nouă metodă SOTA pentru clasificarea imaginilor. Acest lucru a dovedit, de asemenea, că cartografierea corelațiilor între canale și a corelațiilor spațiale în CNN poate fi complet decuplabilă. În plus, împărtășind aceeași virtute cu ResNet, Xception are, de asemenea, un design simplu și frumos, astfel încât ideea sa este utilizată în multe alte cercetări ulterioare, cum ar fi MobileNet, DeepLabV3 etc.
2017: MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
Xception a obținut o acuratețe de top-1 de 79% și o acuratețe de top-5 de 94,5% pe ImageNet, dar aceasta este o îmbunătățire de numai 0,8% și, respectiv, 0,4% în comparație cu SOTA InceptionV3 anterioară. Câștigul marginal al unei noi rețele de clasificare a imaginilor devine din ce în ce mai mic, astfel încât cercetătorii încep să își îndrepte atenția către alte domenii. Iar MobileNet a condus un impuls semnificativ în ceea ce privește clasificarea imaginilor într-un mediu cu resurse limitate.

Similar cu Xception, MobileNet a folosit același modul de convoluție separabilă în profunzime, așa cum se arată mai sus, și a pus accentul pe eficiența ridicată și pe mai puțini parametri.
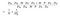
Numeratorul din formula de mai sus este numărul total de parametri necesari pentru o convoluție separabilă în profunzime. Iar numitorul este numărul total de parametri ai unei convoluții regulate similare. Aici D este dimensiunea nucleului de convoluție, D este dimensiunea hărții de caracteristici, M este numărul de canale de intrare, N este numărul de canale de ieșire. Deoarece am separat calculul canalului și al caracteristicii spațiale, putem transforma înmulțirea într-o adunare, care este cu o mărime mai mică. Chiar mai bine, după cum putem vedea din acest raport, cu cât numărul de canale de ieșire este mai mare, cu atât mai mult calcul am economisit din utilizarea acestei noi convoluții.
O altă contribuție a MobileNet este multiplicatorul de lățime și rezoluție. Echipa MobileNet a dorit să găsească un mod canonic de a micșora dimensiunea modelului pentru dispozitivele mobile, iar cel mai intuitiv mod este de a reduce numărul de canale de intrare și de ieșire, precum și rezoluția imaginii de intrare. Pentru a controla acest comportament, un raport alpha este înmulțit cu canalele, iar un raport rho este înmulțit cu rezoluția de intrare (care afectează, de asemenea, dimensiunea hărții de caracteristici). Așadar, numărul total de parametri poate fi reprezentat în următoarea formulă:

Deși această modificare pare naivă din punct de vedere al inovației, ea are o mare valoare inginerească, deoarece este prima dată când cercetătorii concluzionează o abordare canonică pentru a ajusta rețeaua pentru diferite constrângeri de resurse. De asemenea, a cam rezumat soluția finală de îmbunătățire a rețelei neuronale: o intrare mai largă și de înaltă rezoluție duce la o precizie mai bună, o intrare mai subțire și de joasă rezoluție duce la o precizie mai slabă.
Mai târziu, în 2018 și 2019, echipa MobiletNet a lansat, de asemenea, „MobileNetV2: Inverted Residuals and Linear Bottlenecks” și „Searching for MobileNetV3”. În MobileNetV2, se utilizează o structură de gâtuială reziduală inversată. Iar în MobileNetV3, a început să caute combinația optimă de arhitectură folosind tehnologia Neural Architecture Search, pe care o vom aborda în continuare.
2017: NASNet
Learning Transferable Architectures for Scalable Image Recognition
La fel ca și clasificarea imaginilor pentru un mediu cu resurse limitate, căutarea arhitecturii neuronale este un alt domeniu care a apărut în jurul anului 2017. Cu ResNet, Inception și Xception, se pare că am ajuns la o topologie de rețea optimă pe care oamenii o pot înțelege și proiecta, dar ce se întâmplă dacă există o combinație mai bună și mult mai complexă care depășește cu mult imaginația umană? O lucrare din 2016 intitulată „Neural Architecture Search with Reinforcement Learning” (Căutarea arhitecturii neuronale cu învățare prin întărire) a propus o idee de a căuta combinația optimă într-un spațiu de căutare predefinit prin utilizarea învățării prin întărire. După cum știm, învățarea prin întărire este o metodă de a găsi cea mai bună soluție cu un obiectiv și o recompensă clară pentru agentul de căutare. Cu toate acestea, limitată de puterea de calcul, această lucrare a discutat doar aplicarea într-un mic set de date CIFAR.

Cu scopul de a găsi o structură optimă pentru un set de date de mari dimensiuni precum ImageNet, NASNet a realizat un spațiu de căutare care este adaptat pentru ImageNet. Acesta speră să proiecteze un spațiu de căutare special astfel încât rezultatul căutat pe CIFAR să poată funcționa bine și pe ImageNet. În primul rând, NASNet pornește de la premisa că modulul artizanal comun din rețele bune precum ResNet și Xception este încă util la căutare. Astfel, în loc să caute conexiuni și operații aleatorii, NASNet caută combinația acestor module care s-au dovedit a fi deja utile în ImageNet. În al doilea rând, căutarea efectivă se efectuează în continuare pe setul de date CIFAR cu o rezoluție de 32×32, astfel încât NASNet caută numai module care nu sunt afectate de dimensiunea de intrare. Pentru ca al doilea punct să funcționeze, NASNet a predefinit două tipuri de șabloane de module: Reducere și Normal. Celula de reducere ar putea avea o hartă a caracteristicilor redusă în comparație cu cea de intrare, iar pentru celula normală ar fi aceeași.

Deși NASNet are parametri mai buni decât rețelele proiectate manual, suferă, de asemenea, de câteva neajunsuri. Costul de căutare a unei structuri optime este foarte ridicat, care este accesibil doar companiilor mari precum Google și Facebook. De asemenea, structura finală nu are prea mult sens pentru oameni, prin urmare este mai greu de întreținut și de îmbunătățit într-un mediu de producție. Mai târziu, în 2018, „MnasNet: Platform-Aware Neural Architecture Search for Mobile” extinde și mai mult această idee NASNet prin limitarea etapei de căutare cu o structură predefinită de blocuri înlănțuite. De asemenea, prin definirea unui factor de ponderare, mNASNet a oferit un mod mai sistematic de a căuta modelul dat de constrângerile specifice de resurse, în loc să evalueze doar pe baza FLOP-urilor.
2019: EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
În 2019, se pare că nu mai există idei interesante pentru clasificarea supravegheată a imaginilor cu CNN. O schimbare drastică în structura rețelei oferă, de obicei, doar o mică îmbunătățire a acurateței. Chiar mai rău, atunci când aceeași rețea este aplicată la diferite seturi de date și sarcini, trucurile afirmate anterior nu par să funcționeze, ceea ce a dus la critici care susțin că dacă aceste îmbunătățiri sunt doar supraadaptare pe setul de date ImageNet. Pe de altă parte, există un truc care nu dezamăgește niciodată așteptările noastre: utilizarea unei rezoluții mai mari a datelor de intrare, adăugarea mai multor canale pentru straturile de convoluție și adăugarea mai multor straturi. Deși este o forță foarte brutală, se pare că există o modalitate principială de a scala rețeaua la cerere. MobileNetV1 a sugerat oarecum acest lucru în 2017, dar accentul a fost mutat mai târziu pe o proiectare mai bună a rețelei.

După NASNet și mNASNet, cercetătorii și-au dat seama că, chiar și cu ajutorul unui calculator, o schimbare a arhitecturii nu aduce atât de multe beneficii. Așa că au început să revină la scalarea rețelei. EfficientNet este pur și simplu construită pe baza acestei ipoteze. Pe de o parte, utilizează blocul de construcție optim din mNASNet pentru a se asigura o bază bună pentru început. Pe de altă parte, a definit trei parametri alfa, beta și rho pentru a controla adâncimea, lățimea și rezoluția rețelei în mod corespunzător. Procedând astfel, chiar dacă nu dispun de un fond mare de GPU pentru a căuta o structură optimă, inginerii se pot baza în continuare pe acești parametri de principiu pentru a regla rețeaua în funcție de diferitele lor cerințe. În final, EfficientNet a oferit 8 variante diferite cu diferite rapoarte de lățime, adâncime și rezoluție și a obținut performanțe bune atât pentru modelele mici, cât și pentru cele mari. Cu alte cuvinte, dacă doriți o precizie ridicată, optați pentru un EfficientNet-B7 cu parametri de 600×600 și 66M. Dacă doriți o latență scăzută și un model mai mic, optați pentru un EfficientNet-B0 de 224×224 și 5,3M parametri. Problemă rezolvată.
Dacă ați terminat de citit cele 10 lucrări de mai sus, ar trebui să aveți o înțelegere destul de bună a istoriei clasificării imaginilor cu ajutorul CNN. Dacă vă place să continuați să învățați acest domeniu, am enumerat și alte lucrări interesante de citit. Deși nu sunt incluse în lista primilor 10, toate aceste lucrări sunt celebre în domeniul lor și au inspirat mulți alți cercetători din lume.
2014: SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPPNet împrumută ideea de piramidă de caracteristici de la extragerea tradițională a caracteristicilor de viziune pe calculator. Această piramidă formează un sac de cuvinte de caracteristici cu scări diferite, astfel încât se poate adapta la diferite dimensiuni de intrare și poate scăpa de stratul complet conectat de dimensiuni fixe. Această idee a inspirat, de asemenea, modulul ASPP din DeepLab și, de asemenea, FPN pentru detectarea obiectelor.
2016: DenseNet
Rețele convoluționale dens conectate
DenseNet de la Cornell extinde și mai mult ideea din ResNet. Nu numai că oferă conexiuni de salt între straturi, dar are și conexiuni de salt de la toate straturile anterioare.
2017: SENet
Rețele de comprimare și excitare
Rețeaua Xception a demonstrat că corelația între canale nu are prea mult de-a face cu corelația spațială. Cu toate acestea, în calitate de campion al ultimei competiții ImageNet, SENet a conceput un bloc Squeeze-and-Excitation și a spus o poveste diferită. Blocul SE stoarce mai întâi toate canalele în mai puține canale folosind o grupare globală, aplică o transformare complet conectată și apoi le „excită” înapoi la numărul inițial de canale folosind un alt strat complet conectat. Deci, în esență, stratul FC a ajutat rețeaua să învețe atenții pe harta caracteristicilor de intrare.
2017: ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Built on top of MobileNetV2’s inverted bottleneck module, ShuffleNet consideră că convoluția punctuală în convoluția separabilă în profunzime sacrifică acuratețea în schimbul unui calcul mai mic. Pentru a compensa acest lucru, ShuffleNet a adăugat o operațiune suplimentară de amestecare a canalelor pentru a se asigura că convoluția punctuală nu va fi întotdeauna aplicată aceluiași „punct”. Iar în ShuffleNetV2, acest mecanism de amestecare a canalelor este extins în continuare și la o ramură de cartografiere a identității ResNet, astfel încât o parte din caracteristica de identitate va fi, de asemenea, utilizată pentru amestecare.
2018: Bag of Tricks
Bag of Tricks for Image Classification with Convolutional Neural Networks
Bag of Tricks se axează pe trucuri comune utilizate în domeniul clasificării imaginilor. Servește ca o bună referință pentru ingineri atunci când trebuie să îmbunătățească performanța de referință. Este interesant faptul că aceste trucuri, cum ar fi augmentarea amestecului și rata de învățare a cosinusului, pot obține uneori o îmbunătățire mult mai bună decât o nouă arhitectură de rețea.
Concluzie
Cu lansarea EfficientNet, se pare că benchmark-ul de clasificare ImageNet se apropie de sfârșit. Cu abordarea de învățare profundă existentă, nu va exista niciodată o zi în care să putem atinge o precizie de 99,999% pe ImageNet, cu excepția cazului în care s-a produs o altă schimbare de paradigmă. Prin urmare, cercetătorii analizează în mod activ unele domenii noi, cum ar fi învățarea autosupravegheată sau semisupravegheată pentru recunoașterea vizuală la scară largă. Între timp, cu metodele existente, a devenit mai mult o problemă pentru ingineri și antreprenori de a găsi o aplicație în lumea reală a acestei tehnologii neperfecte. În viitor, voi scrie, de asemenea, un sondaj pentru a analiza acele aplicații reale de viziune computerizată bazate pe clasificarea imaginilor, așa că vă rog să rămâneți cu noi! Dacă credeți că există și alte lucrări importante de citit pentru clasificarea imaginilor, vă rugăm să lăsați un comentariu mai jos și să ne anunțați.
Publicat inițial la http://yanjia.li pe 31 iulie 2020
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based Learning Applied to Document Recognition
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
- Sergey Ioffe, Christian Szegedy, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition
- François Chollet, Xception: Deep Learning with Depthwise Separable Convolutions
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
- Mingxing Tan, Quoc V. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Connected Convolutional Networks
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Bag of Tricks for Image Classification with Convolutional Neural Networks
.