
Alocarea resurselor este un aspect important în timpul executării oricărei sarcini Spark. Dacă nu este configurată corect, o lucrare Spark poate consuma resurse întregi ale clusterului și poate face ca alte aplicații să moară de foame pentru resurse.
Acest blog ajută la înțelegerea fluxului de bază într-o aplicație Spark și apoi la configurarea numărului de executori, a setărilor de memorie ale fiecărui executor și a numărului de nuclee pentru o lucrare Spark. Există câțiva factori pe care trebuie să îi luăm în considerare pentru a decide numerele optime pentru cele trei de mai sus, cum ar fi:
- Cantitatea de date
- Timp în care trebuie să se finalizeze un job
- Alocarea statică sau dinamică a resurselor
- Aplicație în amonte sau în aval
- Introducere
- Etapele implicate în modul cluster pentru un Spark Job
- Alocație statică
- Cazul 1 Hardware – 6 noduri și fiecare nod are 16 nuclee, 64 GB RAM
- Cazul 2 Hardware – 6 noduri și fiecare nod are 32 de nuclee, 64 GB
- Cazul 3 – Când nu este necesară mai multă memorie pentru executori
- Tabel rezumativ
- Alocație dinamică
Introducere
Să începem cu câteva definiții de bază ale termenilor utilizați în gestionarea aplicațiilor Spark.
Partiții : O partiție este o bucată mică dintr-un set mare de date distribuite. Spark gestionează datele folosind partiții care ajută la paralelizarea prelucrării datelor cu o amestecare minimă a datelor între executori.
Task : O sarcină este o unitate de lucru care poate fi executată pe o partiție a unui set de date distribuit și care se execută pe un singur executor. Unitatea de execuție paralelă este la nivel de sarcină.Toate sarcinile dintr-o singură etapă pot fi executate în paralel
Executor: Un executor este un singur proces JVM care este lansat pentru o aplicație pe un nod de lucru. Executorul execută sarcini și păstrează datele în memorie sau pe disc de-a lungul acestora. Fiecare aplicație are propriii săi executori. Un singur nod poate rula mai mulți executori, iar executorii pentru o aplicație pot acoperi mai multe noduri de lucru. Un executor rămâne activ pe durata
durata aplicației Spark și execută sarcinile în mai multe fire de execuție. Numărul de executori pentru o aplicație Spark poate fi specificat în interiorul SparkConf sau prin intermediul steagului -num-executors din linia de comandă.
Cluster Manager : Un serviciu extern pentru achiziționarea de resurse în cluster (de exemplu, un manager independent, Mesos, YARN). Spark este agnostic față de un manager de cluster atâta timp cât poate achiziționa procese de execuție și acestea pot comunica între ele. suntem interesați în primul rând de Yarn ca manager de cluster. Un cluster Spark poate rula fie în modul yarn cluster, fie în modul yarn-client:
modul yarn-client – Un driver rulează în procesul client, Application Master este folosit doar pentru a solicita resurse de la YARN.
modul yarn-cluster – Un driver rulează în interiorul procesului application master, clientul dispare odată ce aplicația este inițializată
Core : Un nucleu este o unitate de calcul de bază a procesorului și un procesor poate avea unul sau mai multe nuclee pentru a efectua sarcini la un moment dat. Cu cât avem mai multe nuclee, cu atât mai multă muncă putem face. În Spark, acesta controlează numărul de sarcini paralele pe care un executor le poate rula.
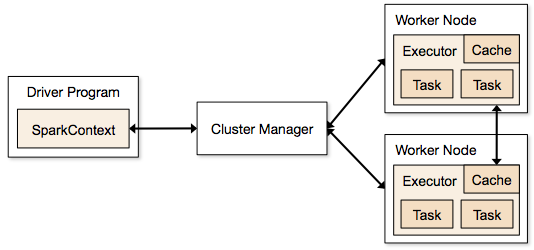
Etapele implicate în modul cluster pentru un Spark Job
- Din codul driverului, SparkContext se conectează la managerul de cluster (standalone/Mesos/YARN).
- Managerul de cluster alocă resurse între celelalte aplicații. Orice manager de cluster poate fi utilizat atâta timp cât procesele executorilor sunt în execuție și comunică între ele.
- Spark achiziționează executori pe nodurile din cluster. Aici, fiecare aplicație va primi propriile sale procese de execuție.
- Codul aplicației (jar/fișiere Python/fișiere Python egg) este trimis către executori
- Tașele sunt trimise de SparkContext către executori.
Din pașii de mai sus, este clar că numărul de executori și setarea memoriei acestora joacă un rol major într-o sarcină Spark. Rularea executorilor cu prea multă memorie duce adesea la întârzieri excesive de colectare a gunoiului
Acum încercăm să înțelegem, cum să configurăm cel mai bun set de valori pentru a optimiza o sarcină Spark.
Există două moduri în care configurăm detaliile executorului și ale nucleului pentru sarcina Spark. Acestea sunt:
- Alocație statică – Valorile sunt date ca parte din spark-submit
- Alocație dinamică – Valorile sunt preluate în funcție de cerințe (dimensiunea datelor, cantitatea de calcule necesare) și eliberate după utilizare. Acest lucru ajută ca resursele să fie reutilizate pentru alte aplicații.
Alocație statică
Se discută diferite cazuri variind diferiți parametri și ajungând la diferite combinații în funcție de cerințele utilizatorului/datelor.
Cazul 1 Hardware – 6 noduri și fiecare nod are 16 nuclee, 64 GB RAM
În primul rând, pe fiecare nod, 1 nucleu și 1 GB sunt necesare pentru sistemul de operare și demonii Hadoop, deci avem 15 nuclee, 63 GB RAM pentru fiecare nod
Începem cu modul de alegere a numărului de nuclee:
Numărul de nuclee = sarcini concurente pe care le poate executa un executor
Așa că ne-am putea gândi că un număr mai mare de sarcini concurente pentru fiecare executor va oferi performanțe mai bune. Dar cercetările arată că orice aplicație cu mai mult de 5 sarcini concurente, ar duce la un spectacol prost. Așadar, valoarea optimă este 5.
Acest număr provine din capacitatea unui executor de a rula sarcini paralele și nu din câte nuclee are un sistem. Așadar, numărul 5 rămâne același chiar dacă avem nuclee duble (32) în CPU
Numărul de executori:
Plecând la pasul următor, cu 5 ca nuclee per executor și 15 ca număr total de nuclee disponibile într-un nod (CPU) – ajungem la 3 executori pe nod, ceea ce înseamnă 15/5. Trebuie să calculăm numărul de executori de pe fiecare nod și apoi să obținem numărul total pentru lucrare.
Atunci, cu 6 noduri și 3 executori pe nod – obținem un total de 18 executori. Din cei 18 avem nevoie de 1 executor (proces java) pentru Application Master în YARN. Așadar, numărul final este de 17 executori
Acest 17 este numărul pe care îl dăm la spark folosind -num-executors în timpul rulării din comanda shell spark-submit
Memorie pentru fiecare executor:
Din pasul de mai sus, avem 3 executori pe nod. Iar memoria RAM disponibilă pe fiecare nod este de 63 GB
Așa că memoria pentru fiecare executor în fiecare nod este de 63/3 = 21GB.
Cu toate acestea, este nevoie și de o mică memorie suplimentară pentru a determina cererea completă de memorie către YARN pentru fiecare executor.
Formula pentru acest overhead este max(384, 0,07 * spark.executor.memory)
Calcularea acestui overhead: 0,07 * 21 (aici 21 se calculează ca mai sus 63/3) = 1,47
Din moment ce 1,47 GB > 384 MB, overhead-ul este 1.47
Tăiați cele de mai sus din fiecare 21 de mai sus => 21 – 1,47 ~ 19 GB
Deci memoria executorului – 19 GB
Numere finale – Executori – 17, nuclee 5, memorie executor – 19 GB
Cazul 2 Hardware – 6 noduri și fiecare nod are 32 de nuclee, 64 GB
Numărul de nuclee de 5 este același pentru o bună concurență, așa cum s-a explicat mai sus.
Numărul de executori pentru fiecare nod = 32/5 ~ 6
Deci numărul total de executori = 6 * 6 Noduri = 36. Atunci numărul final este 36 – 1(pentru AM) = 35
Memoria executorilor:
6 executori pentru fiecare nod. 63/6 ~ 10. Overhead este 0,07 * 10 = 700 MB. Deci, rotunjind la 1 GB ca overhead, obținem 10-1 = 9 GB
Numere finale – Executori – 35, nuclee 5, memorie executor – 9 GB
Cazul 3 – Când nu este necesară mai multă memorie pentru executori
Scenariile de mai sus încep cu acceptarea numărului de nuclee ca fiind fix și trec la numărul de executori și memorie.
Acum, pentru primul caz, dacă ne gândim că nu avem nevoie de 19 GB și că doar 10 GB sunt suficienți pe baza dimensiunii datelor și a calculelor implicate, atunci următoarele sunt numerele:
Core: 5
Numărul de executori pentru fiecare nod = 3. Tot 15/5, așa cum am calculat mai sus.
În acest stadiu, acest lucru ar duce la 21 GB, și apoi la 19, conform primului nostru calcul. Dar, din moment ce am considerat că 10 este în regulă (presupunem puțin overhead), atunci nu putem trece numărul de executori pe nod la 6 (ca 63/10). Deoarece cu 6 executori pe nod și 5 nuclee se ajunge la 30 de nuclee pe nod, când noi avem doar 16 nuclee. Deci trebuie să schimbăm și numărul de nuclee pentru fiecare executor.
Așa că, calculând din nou,
Numărul magic 5 ajunge la 3 (orice număr mai mic sau egal cu 5). Deci, cu 3 nuclee, și 15 nuclee disponibile – obținem 5 executori pe nod, 29 de executori ( care este (5*6 -1)) și memoria este 63/5 ~ 12.
Supraînălțarea este 12*.07=.84. Deci memoria executorului este de 12 – 1 GB = 11 GB
Numele finale sunt 29 de executori, 3 nuclee, memoria executorului este de 11 GB
Tabel rezumativ
Alocație dinamică
Nota: Limita superioară pentru numărul de executori, dacă este activată alocarea dinamică, este infinită. Deci, acest lucru spune că aplicația Spark poate consuma toate resursele dacă este necesar. Într-un cluster în care avem și alte aplicații care rulează și care au nevoie de nuclee pentru a executa sarcinile, trebuie să ne asigurăm că atribuim nucleele la nivel de cluster.
Acest lucru înseamnă că putem aloca un număr specific de nuclee pentru aplicațiile bazate pe YARN în funcție de accesul utilizatorilor. Astfel, putem crea un spark_user și apoi să alocăm nuclee (min/max) pentru acel utilizator. Aceste limite sunt pentru partajarea între spark și alte aplicații care rulează pe YARN.
Pentru a înțelege alocarea dinamică, trebuie să cunoaștem următoarele proprietăți:
spark.dynamicAllocation.enabled – atunci când aceasta este setată la true, nu trebuie să menționăm executori. Motivul este următorul:
Numele parametrilor statici pe care îi dăm la spark-submit sunt pentru întreaga durată a lucrării. Cu toate acestea, dacă intră în scenă alocarea dinamică, ar exista diferite etape, cum ar fi următoarele:
Care este numărul de executori cu care se începe:
Numărul inițial de executori (spark.dynamicAllocation.initialExecutors) cu care se începe
Controlul numărului de executori în mod dinamic:
Apoi, pe baza încărcăturii (sarcini în așteptare), câți executori se solicită. Acesta ar fi în cele din urmă numărul pe care îl dăm la spark-submit în mod static. Deci, odată ce numărul inițial de executori este stabilit, trecem la numerele min (spark.dynamicAllocation.minExecutors) și max (spark.dynamicAllocation.maxExecutors).
Când să cerem noi executori sau să renunțăm la executori actuali:
Când solicităm noi executori (spark.dynamicAllocation.schedulerBacklogTimeout) – Aceasta înseamnă că au existat sarcini în așteptare pentru această durată. Așadar, solicitarea numărului de executori solicitați în fiecare rundă crește exponențial față de runda anterioară. De exemplu, o aplicație va adăuga 1 executor în prima rundă, iar apoi 2, 4, 8 și așa mai departe executori în rundele următoare. La un moment dat, proprietatea max de mai sus intră în scenă.
Când renunțăm la un executor se stabilește folosind spark.dynamicAllocation.executorIdleTimeout.
În concluzie, dacă avem nevoie de mai mult control asupra timpului de execuție a sarcinii, monitorizăm sarcina pentru un volum de date neașteptat, numerele statice ar fi de ajutor. Trecând la dinamic, resursele ar fi utilizate în fundal, iar lucrările care implică volume neașteptate ar putea afecta alte aplicații.
.