
Primul lucru pe care trebuie să îl înțelegem este natura variabilelor și modul în care variabilele sunt folosite în proiectarea unui studiu pentru a răspunde la întrebările studiului. În acest capitol veți învăța:
- diferite tipuri de variabile în studiile cantitative,
- probleme legate de întrebarea privind unitatea de analiză.
Înțelegerea variabilelor cantitative
Rădăcina cuvântului variabilă este legată de cuvântul „variază”, ceea ce ar trebui să ne ajute să înțelegem ce ar putea fi variabilele. Variabilele sunt elemente, entități sau factori care se pot schimba (varia); de exemplu, temperatura exterioară, costul benzinei pe galon, greutatea unei persoane și starea de spirit a persoanelor din familia dumneavoastră extinsă sunt toate variabile. Cu alte cuvinte, acestea pot avea valori diferite în condiții diferite sau pentru persoane diferite.
Utilizăm variabile pentru a descrie caracteristici sau factori de interes. Exemple ar putea include numărul de membri din diferite gospodării, distanța până la surse de hrană sănătoasă în diferite cartiere, raportul dintre profesorii de asistență socială și studenții unui program BSW sau MSW, proporția de persoane din diferite grupuri rasiale/etnice încarcerate, costul transportului pentru a primi servicii de la un program de asistență socială sau rata mortalității infantile în diferite județe. În cercetările privind intervenția în asistența socială, variabilele ar putea include caracteristicile intervenției (intensitate, frecvență, durată) și rezultatele asociate cu intervenția.
Variabile demografice. Asistenții sociali sunt adesea interesați de ceea ce numim variabile demografice. Variabilele demografice sunt folosite pentru a descrie caracteristicile unei populații, ale unui grup sau ale unui eșantion al populației. Exemple de variabile demografice aplicate frecvent sunt
- vârsta,
- etnia,
- originea națională,
- afilierea religioasă,
- sexul,
- orientarea sexuală,
- stare civilă/relațională,
- stare profesională,
- afiliere politică,
- locație geografică,
- nivel de educație și
- venituri.
La un nivel mai macro, datele demografice ale unei comunități sau organizații includ adesea dimensiunea acesteia; organizațiile sunt adesea măsurate în funcție de bugetul lor global.
Variabile independente și dependente. Un mod în care cercetătorii se gândesc la variabilele studiului are implicații importante pentru proiectarea unui studiu. Investigatorii iau decizii pentru ca acestea să servească fie ca variabile independente, fie ca variabile dependente. Această distincție nu este ceva inerent unei variabile, ci se bazează pe modul în care investigatorul alege să definească fiecare variabilă. Variabilele independente sunt cele la care v-ați putea gândi ca fiind variabilele „de intrare” manipulate, în timp ce variabilele dependente sunt cele în care s-ar observa impactul sau „ieșirea” acelei variații de intrare.
Nu întotdeauna este implicată manipularea intenționată a variabilei „de intrare” (independentă). Luați în considerare exemplul unui studiu realizat în Suedia care a examinat relația dintre faptul de a fi fost victima relelor tratamente aplicate copiilor și absenteismul ulterior la liceu: nimeni nu a manipulat în mod intenționat dacă copiii ar fi fost victime ale relelor tratamente aplicate copiilor (Hagborg, Berglund, & Fahlke, 2017). Anchetatorii au emis ipoteza că diferențele care apar în mod natural în variabila de intrare (istoricul de maltratare a copilului) ar fi asociate cu variația sistematică a unei variabile de rezultat specifice (absenteismul școlar). În acest caz, variabila independentă a fost istoricul de victimă a relelor tratamente aplicate copiilor, iar variabila dependentă a fost rezultatul absenteismului școlar. Cu alte cuvinte, investigatorul a emis ipoteza că variabila independentă determină variația sau schimbarea variabilei dependente. Iată cum ar putea arăta într-o diagramă în care „x” este variabila independentă și „y” este variabila dependentă (notă: ați văzut această denumire mai devreme, în capitolul 3, când am discutat despre logica de cauză și efect):

Pentru un alt exemplu, luați în considerare cercetările care indică faptul că a fi victima maltratării copilului este asociat cu un risc mai mare de consum de substanțe în timpul adolescenței (Yoon, Kobulsky, Yoon, & Kim, 2017). Variabila independentă în acest model ar fi faptul de a avea un istoric de maltratare a copilului. Variabila dependentă ar fi riscul de consum de substanțe în timpul adolescenței. Acest exemplu este și mai elaborat, deoarece specifică calea prin care variabila independentă (maltratarea copilului) și-ar putea impune efectele asupra variabilei dependente (consumul de substanțe în adolescență). Autorii studiului au demonstrat că stresul post-traumatic (PTS) a fost o legătură între abuzul din copilărie (fizic și sexual) și consumul de substanțe în timpul adolescenței.

Dispuneți un moment pentru a finaliza următoarea activitate.
Tipuri de variabile cantitative
Există și alte moduri semnificative de a gândi la variabilele de interes. Să luăm în considerare diferite caracteristici ale variabilelor utilizate în studiile de cercetare cantitativă. Aici explorăm variabilele cantitative ca fiind de natură categorială, ordinală sau de interval. Aceste caracteristici au implicații atât pentru măsurare, cât și pentru analiza datelor.
Variabile categoriale. Unele variabile pot lua valori care variază, dar nu într-un mod numeric semnificativ. În schimb, ele pot fi definite în termeni de categorii care sunt posibile. În mod logic, acestea se numesc variabile categorice. Softurile și manualele de statistică se referă uneori la variabilele cu categorii ca fiind variabile nominale. Nominalul poate fi gândit în termenii rădăcinii latine „nom”, care înseamnă „nume”, și nu trebuie confundat cu numărul. Nominal înseamnă același lucru ca și categoric în descrierea variabilelor. Cu alte cuvinte, variabilele categorice sau nominale sunt identificate prin numele sau etichetele categoriilor reprezentate. De exemplu, culoarea ultimei mașini în care ați călătorit ar fi o variabilă categorială: albastru, negru, argintiu, alb, roșu, verde, galben sau altele sunt categorii ale variabilei pe care am putea-o numi culoarea mașinii.
Ceea ce este important în cazul variabilelor categoriale este că aceste categorii nu au o secvență sau o ordine numerică relevantă. Nu există nicio diferență numerică între diferitele culori ale mașinilor sau nicio diferență între „da” sau „nu” ca și categorii în a răspunde dacă ați mers cu o mașină albastră. Nu există nicio ordine sau ierarhie implicită pentru categoriile „hispanic sau latin” și „nu hispanic sau latin” într-o variabilă de etnie; de asemenea, nu există nicio ordine relevantă pentru categoriile unor variabile precum sexul, statul sau regiunea geografică în care locuiește o persoană sau dacă locuința unei persoane este deținută sau închiriată.
Dacă un cercetător a decis să folosească numere ca simboluri legate de categorii într-o astfel de variabilă, numerele sunt arbitrare – fiecare număr este, în esență, doar un nume diferit, mai scurt, pentru fiecare categorie. De exemplu, variabila gen ar putea fi codificată în următoarele moduri și nu ar fi nicio diferență, atâta timp cât codul ar fi aplicat în mod consecvent.
| Opțiune de codificare A | Categorii de variabile | Opțiune de codificare B | |
|---|---|---|---|
| 1 | masculin | 2 | |
| 2 | femei | femeie | 1 |
| 3 | altul decât bărbat sau femeie singur | 4 | |
| 4 | preferă să nu răspundă | 3 |
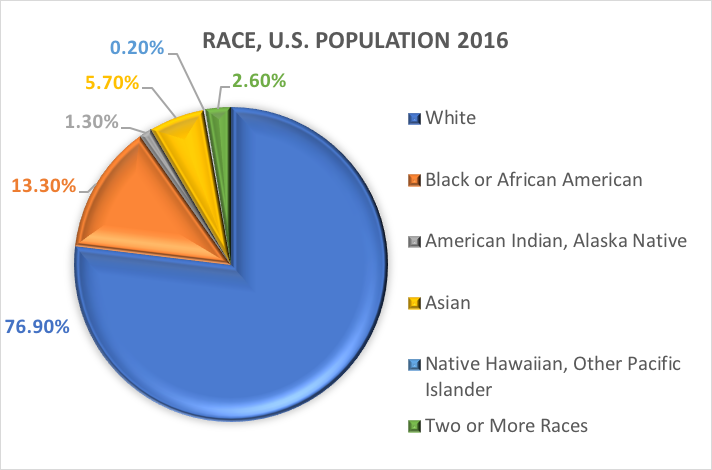
Rasă și etnie.Una dintre cele mai frecvent explorate variabile categorice în cercetarea în domeniul asistenței sociale și al științelor sociale este cea demografică care se referă la originea rasială și/sau etnică a unei persoane. Multe studii utilizează categoriile specificate în rapoartele anterioare ale Biroului de recensământ al SUA. Iată ce are de spus U.S. Census Bureau despre cele două variabile demografice distincte, rasa și etnia (https://www.census.gov/mso/www/training/pdf/race-ethnicity-onepager.pdf):
Ce este rasa? Biroul Recensământului definește rasa ca fiind autoidentificarea unei persoane cu unul sau mai multe grupuri sociale. O persoană se poate raporta ca fiind albă, de culoare sau afro-americană, asiatică, amerindiană și nativă din Alaska, nativă din Hawaii și alte insule din Pacific, sau de altă rasă. Respondenții la sondaj pot raporta mai multe rase.
Ce este etnia? Etnia determină dacă o persoană este sau nu de origine hispanică. Din acest motiv, etnia este împărțită în două categorii, Hispanic sau Latino și Not Hispanic or Latino. Hispanicii se pot declara ca fiind de orice rasă.
Cu alte cuvinte, Census Bureau definește două categorii pentru variabila numită etnie (Hispanic or Latino și Not Hispanic or Latino) și șapte categorii pentru variabila numită rasă. Deși aceste variabile și categorii sunt adesea aplicate în cercetările din domeniul științelor sociale și al asistenței sociale, ele nu sunt lipsite de critici.
Pe baza acestor categorii, iată ce se estimează a fi adevărat în ceea ce privește populația Statelor Unite în 2016:
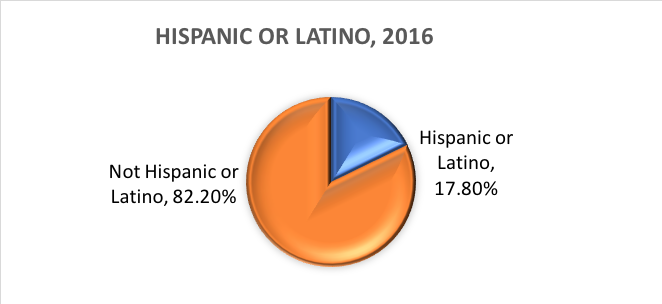
Variabile dichotomice. există o categorie specială de variabile categorice cu implicații pentru anumite analize statistice. Variabilele categoriale compuse din exact două opțiuni, nici mai mult, nici mai puțin, se numesc variabile dicotomice. Un exemplu a fost reprezentat de dihotomia Biroului de recensământ al SUA între etnia hispanică/latină și etnia nehispanică/neolatină. Pentru un alt exemplu, investigatorii ar putea dori să compare persoanele care finalizează tratamentul cu cele care abandonează înainte de a finaliza tratamentul. Cu cele două categorii, finalizat sau nefinalizat, această variabilă de finalizare a tratamentului nu este doar categorică, ci și dihotomică. Variabilele în care indivizii răspund „da” sau „nu” sunt, de asemenea, de natură dihotomică.
Tradiția din trecut de a trata genul ca fiind fie bărbat, fie femeie este un alt exemplu de variabilă dihotomică. Cu toate acestea, există argumente foarte puternice pentru a nu mai trata genul în această manieră dihotomică: o varietate mai mare de identități de gen sunt în mod demonstrabil relevante în activitatea socială pentru persoanele a căror identitate nu se aliniază cu categoriile dihotomice (numite și binare) de bărbat/femeie sau bărbat/femeie. Acestea includ categorii precum agender, androgin, bigender, cisgender, gender expansiv, gender fluid, gender questioning, queer, transgender și altele.
Variabile ordinale. Spre deosebire de aceste variabile categorice, uneori categoriile unei variabile au o secvență sau o ordine numerică logică. Ordinal, prin definiție, se referă la o poziție într-o serie. Variabilele cu categorii relevante din punct de vedere numeric se numesc variabile ordinale. De exemplu, există o ordine implicită a categoriilor de la cel mai mic la cel mai mare în cazul variabilei numite nivel de educație. În Statele Unite. Census din SUA pentru această variabilă ordinală sunt:
- nimic
- 1st-4thgrade
- 5th-6thgrade
- 7th-8thgrade
- 9thgrade
- 10thgrade
- 11thgrade
- high school graduate
- some college, fără diplomă
- diplomă de studii medii, ocupațională
- diplomă asociată academică
- diplomă de licență
- diplomă de master
- diplomă profesională
- diplomă de doctorat
În analizând datele estimative ale Biroului de recensământ din 2016 pentru această variabilă, putem observa că femeile au fost mai numeroase decât bărbații în categoria celor care au obținut o diplomă de licență: din cele 47.718.000 de persoane din această categorie, 22.485.000 erau bărbați și 25.234.000 erau femei. În timp ce acest model de gen s-a menținut în cazul celor care au primit diplome de masterat, modelul a fost inversat în cazul celor care au primit diplome de doctorat: mai mulți bărbați decât femei au obținut acest nivel maxim de educație. Este, de asemenea, interesant de observat că femeile au fost mai numeroase decât bărbații la capătul de jos al spectrului: 441.000 de femei au raportat că nu au avut nicio educație, comparativ cu 374.000 de bărbați.
Iată un alt exemplu de utilizare a variabilelor ordinale în cercetarea în domeniul asistenței sociale: atunci când indivizii solicită tratament pentru o problemă de abuz de alcool, asistenții sociali ar putea dori să știe dacă aceasta este prima, a doua, a treia sau orice altă încercare serioasă numerotată de a-și schimba comportamentul de consum. Participanții înscriși într-un studiu care a comparat abordările de tratament pentru tulburările legate de consumul de alcool au raportat că studiul de intervenție a fost oriunde între prima și a unsprezecea lor încercare de schimbare semnificativă (Begun, Berger, Salm-Ward, 2011). Această variabilă a încercării de schimbare are implicații asupra modului în care lucrătorii sociali ar putea interpreta datele de evaluare a unei intervenții care nu a fost prima încercare pentru toți cei implicați.
Scale de evaluare. Luați în considerare un tip diferit, dar utilizat în mod obișnuit, de variabilă ordinală: scalele de evaluare. Investigatorii din domeniul social, comportamental și al asistenței sociale le cer adesea participanților la studiu să aplice o scală de evaluare pentru a-și descrie cunoștințele, atitudinile, credințele, opiniile, abilitățile sau comportamentul. Deoarece categoriile de pe o astfel de scală sunt ordonate (de la cel mai mult la cel mai puțin sau de la cel mai puțin la cel mai mult), numim aceste variabile ordinale.

Exemplele includ ca participanții să evalueze:
- cât de mult sunt de acord sau nu sunt de acord cu anumite afirmații (deloc până la extrem de mult);
- cât de des se angajează în anumite comportamente (niciodată până la întotdeauna);
- cât de des se angajează în anumite comportamente (din oră în oră, zilnic, săptămânal, lunar, anual sau mai rar);
- calitatea prestației cuiva (de la slab la excelent);
- cât de mulțumiți au fost de tratamentul lor (de la foarte nemulțumit la foarte mulțumit)
- nivelul lor de încredere (de la foarte scăzut la foarte ridicat).
Variabile intermediare. Încă alte variabile capătă valori care variază într-un mod numeric semnificativ. Din lista noastră de variabile demografice, vârsta este un exemplu obișnuit. Valoarea numerică atribuită unei persoane individuale indică numărul de ani de când s-a născut o persoană (în cazul sugarilor, valoarea numerică poate indica zile, săptămâni sau luni de la naștere). În acest caz, valorile posibile ale variabilei sunt ordonate, la fel ca în cazul variabilelor ordinale, dar se introduce o mare diferență: natura intervalelor dintre valorile posibile. În cazul variabilelor de interval, „distanța” dintre valorile posibile adiacente este egală. Unele pachete de software statistic și manuale folosesc termenul de variabilă de scară: acesta este exact același lucru cu ceea ce noi numim variabilă de interval.
De exemplu, în graficul de mai jos, diferența de 1 uncie între această persoană care consumă 1 uncie sau 2 uncii de alcool (luni, marți) este exact aceeași cu diferența de 1 uncie între a consuma 4 uncii sau 5 uncii (vineri, sâmbătă). Dacă ar fi să facem o diagramă a punctelor posibile de pe scală, toate ar fi echidistante; intervalul dintre oricare două puncte este măsurat în unități standard (uncii, în acest exemplu).
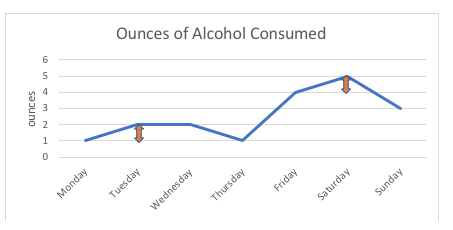
Cu variabile ordinale, cum ar fi o scală de evaluare, nimeni nu poate spune cu certitudine că „distanța” dintre opțiunile de răspuns „niciodată” și „uneori” este aceeași cu „distanța” dintre „uneori” și „adesea”, chiar dacă am folosi numere pentru a secvenția aceste opțiuni de răspuns. Astfel, scara de evaluare rămâne ordinală, nu de interval.
Ceea ce ar putea deveni un pic confuz este faptul că anumite programe de software statistic, cum ar fi SPSS, se referă la o variabilă de interval ca la o variabilă de „scală”. Multe variabile utilizate în cercetarea în domeniul asistenței sociale sunt atât ordonate, cât și au distanțe egale între puncte. Luați în considerare, de exemplu, variabila ordinii de naștere. Această variabilă este de interval deoarece:
- valorile posibile sunt ordonate (de exemplu, al treilea copil născut a venit după primul și al doilea născut și înaintea celui de-al patrulea născut), iar
- „distanțele” sau intervalele sunt măsurate în unități echivalente de o persoană.
Variabile continue. Există un tip special de variabile numerice de interval pe care le numim variabile continue. O variabilă precum vârsta poate fi tratată ca o variabilă continuă. Vârsta este de natură ordinală, deoarece numerele mai mari înseamnă ceva în raport cu numerele mai mici. Vârsta îndeplinește, de asemenea, criteriile noastre pentru a fi o variabilă de interval dacă o măsurăm în ani (sau luni sau săptămâni sau zile), deoarece este ordinală și există aceeași „distanță” între a avea 15 și 30 de ani ca și între a avea 40 și 55 de ani (15 ani calendaristici). Ceea ce face ca aceasta să fie o variabilă continuă este faptul că există, de asemenea, puncte de „fracțiune” posibile și semnificative între oricare două intervale. De exemplu, o persoană poate avea 20½ (20,5) sau 20¼ (20,25) sau 20¾ (20,75) ani; nu ne limităm doar la numerele întregi pentru vârstă. Prin contrast, atunci când ne-am uitat la ordinea nașterii, nu putem avea o fracțiune semnificativă a unei persoane între două poziții pe scală.
Cazul special al venitului. Una dintre cele mai abuzate variabile în cercetarea în domeniul științelor sociale și al asistenței sociale este variabila legată de venit. Luați în considerare un exemplu despre venitul gospodăriei (indiferent de câte persoane sunt în gospodărie). Această variabilă ar putea fi categorică (nominală), ordinală sau de interval (scală) în funcție de modul în care este tratată.
Exemplu categoric: În funcție de natura întrebărilor de cercetare, un investigator ar putea alege pur și simplu să utilizeze categoriile dihotomice „cu resurse suficiente” și „cu resurse insuficiente” pentru clasificarea gospodăriilor, pe baza unei metode standard de calcul. Acestea ar putea fi numite „sărace” și „nu sunt sărace” în cazul în care se utilizează un prag de sărăcie pentru a clasifica gospodăriile. Aceste categorii distincte ale variabilei de venit nu sunt secvențiate în mod semnificativ într-un mod numeric, deci este o variabilă categorială.
Exemplu ordinal: Categoriile pentru clasificarea gospodăriilor ar putea fi ordonate de la mic la mare. De exemplu, aceste categorii pentru venitul anual sunt obișnuite în studiile de piață:
- Mai puțin de 25.000$.
- 25.000$ până la 34.999$.
- 35.000$ până la 49.999$.
- 50.000$ până la 74.999$.
- 75.000$ până la 99.999$.
- 100.000$ până la 149.999$.
- 150.000$ până la 199.999$.
- 200.000$ sau mai mult.
Rețineți că categoriile nu sunt de dimensiuni egale – „distanța” dintre perechile de categorii nu este întotdeauna aceeași. Ele încep cu intervale de aproximativ 10.000 de dolari, trec la intervale de 25.000 de dolari și se termină cu intervale de aproximativ 50.000 de dolari.
Exemplu de interval. Dacă un investigator a cerut participanților la studiu să raporteze o sumă reală în dolari pentru venitul gospodăriei, am vedea o variabilă de interval. Valorile posibile sunt ordonate, iar intervalul dintre orice unități adiacente posibile este de 1 dolar (atâta timp cât nu se folosesc fracțiuni de dolar sau cenți). Astfel, un venit de 10.452 $ este la aceeași distanță pe un continuum de la 9.452 $ și 11.452 $ – 1.000 $ în ambele sensuri.

Cazul special al vârstei. Ca și venitul, „vârsta” poate însemna lucruri diferite în diferite studii. Vârsta este, de obicei, un indicator al „timpului de la naștere”. Putem calcula vârsta unei persoane scăzând o variabilă a datei de naștere din data de măsurare (data de astăzi minus data de naștere). Pentru adulți, vârstele se măsoară de obicei în ani, unde valorile posibile adiacente sunt distanțate în unități de 1 an: 18, 19, 20, 21, 22 și așa mai departe. Astfel, variabila de vârstă ar putea fi un tip continuu de variabilă de interval.
Cu toate acestea, un investigator ar putea dori să comprime datele privind vârsta în categorii ordonate sau grupuri de vârstă. Acestea ar fi tot ordinale, dar ar putea să nu mai fie intervale dacă creșterile dintre valorile posibile nu sunt unități echivalente. De exemplu, dacă ne interesează mai mult ca vârsta să reprezinte perioade specifice de dezvoltare umană, intervalele de vârstă ar putea să nu fie egale în intervalul dintre criteriile de vârstă. Posibil ca acestea să fie egale:
- Infanță (de la naștere până la 18 luni)
- Vârsta preșcolară (de la 18 luni până la 2 ½ ani)
- Vârsta preșcolară (de la 2 ½ la 5 ani)
- Vârsta școlară (de la 6 la 11 ani)
- Adolescența (de la 12 la 17 ani)
- Adulțimea emergentă (de la 18 la 25 de ani)
- Adulțimea (de la 26 la 45 de ani)
- Adulțimea mijlocie (de la 46 la 60 de ani)
- Tânăr.Adultă (60 până la 74 de ani)
- Adulțimea mijlocie (75 până la 84 de ani)
- Adulțimea bătrână (85 de ani sau mai mult)
.
Vârsta ar putea fi tratată chiar ca o variabilă strict categorică (neordinară). De exemplu, dacă variabila de interes este dacă o persoană are vârsta legală de consum de alcool (21 de ani sau mai mult) sau nu. Avem două categorii – îndeplinește sau nu îndeplinește criteriile privind vârsta legală de consum de alcool în Statele Unite – și oricare dintre ele ar putea fi codificată cu „1”, iar cealaltă cu „0” sau „2”, fără nicio diferență de semnificație.
Care este răspunsul „corect” cu privire la modul de măsurare a vârstei (sau a venitului)? Răspunsul este „depinde”. Depinde de natura întrebării de cercetare: ce conceptualizare a vârstei (sau a venitului) este cea mai relevantă pentru studiul care este proiectat.
Variabile alfanumerice. În cele din urmă, există date care nu se încadrează în niciuna dintre aceste clasificări. Uneori, informațiile pe care le cunoaștem se prezintă sub forma unei adrese sau a unui număr de telefon, a unui nume sau prenume, a unui cod poștal sau a altor fraze. Aceste tipuri de informații sunt numite uneori variabile alfanumerice. Să luăm, de exemplu, variabila „adresă”: adresa unei persoane poate fi alcătuită din caractere numerice (numărul casei) și litere (numele străzii, al orașului și al statului), cum ar fi: 1600 Pennsylvania Ave. NW, Washington, DC, 20500.

De fapt, avem mai multe variabile prezente în acest exemplu de adresă:
- adresa străzii: 1600 Pennsylvania Ave.
- orașul (și „statul”): Washington, DC
- cod poștal: 20500.
Acest tip de informații nu reprezintă categorii cantitative specifice sau valori cu semnificație sistematică în cadrul datelor. Acestea sunt, de asemenea, numite uneori variabile „șir” în anumite pachete software, deoarece sunt alcătuite dintr-un șir de simboluri. Pentru a fi utilă pentru un investigator, o astfel de variabilă ar trebui să fie convertită sau recodificată în valori semnificative.
O notă despre unitatea de analiză
Un lucru important de reținut atunci când ne gândim la variabile este faptul că datele pot fi colectate la mai multe niveluri diferite de observare. Elementele studiate pot fi celule individuale, sisteme de organe sau persoane. Sau, nivelul de observare ar putea fi perechi de indivizi, cum ar fi cupluri, frați și surori, sau diade părinte-copil. În acest caz, investigatorul poate colecta informații despre pereche de la fiecare individ în parte, dar analizează datele fiecărei perechi. Astfel, am spune că unitatea de analiză este perechea sau diada, nu fiecare persoană în parte. Unitatea de analiză ar putea fi, de asemenea, un grup mai mare: de exemplu, datele ar putea fi colectate de la fiecare dintre elevii din clase întregi, în cazul în care unitatea de analiză este reprezentată de clasele dintr-o școală sau dintr-un sistem școlar. Sau, unitatea de analiză ar putea fi la nivel de cartiere, programe, organizații, județe, state sau chiar națiuni. De exemplu, multe dintre variabilele utilizate ca indicatori ai securității alimentare la nivelul comunităților, cum ar fi accesibilitatea și accesibilitatea, se bazează pe date colectate de la gospodării individuale (Kaiser, 2017). Unitatea de analiză în studiile care utilizează acești indicatori ar fi comunitățile comparate. Această distincție are implicații importante în ceea ce privește măsurarea și analiza datelor.
Un memento despre variabile versus niveluri de variabile
Un studiu ar putea fi descris în funcție de numărul de categorii de variabile, sau niveluri, care sunt comparate. De exemplu, ați putea vedea un studiu descris ca fiind un design 2 X 2 – pronunțat ca un design doi la doi. Acest lucru înseamnă că există 2 categorii posibile pentru prima variabilă și 2 categorii posibile pentru cealaltă variabilă – ambele sunt variabile dihotomice. Un studiu care compară 2 categorii ale variabilei „tulburare de consum de alcool” (categorii pentru îndeplinește criteriile, da sau nu) cu 2 categorii ale variabilei „tulburare de consum de substanțe ilicite” (categorii pentru îndeplinește criteriile, da sau nu) ar avea 4 rezultate posibile (din punct de vedere matematic, 2 x 2=4) și ar putea fi diagramat astfel (date bazate pe proporțiile din sondajul NSDUH din 2016, prezentate în SAMHSA, 2017):
| Dezordine de consum de substanțe ilicite (SUD) | |||
|---|---|---|---|
|
Dezordine de consum de alcool (AUD) |
Nu | Da | |
| Nu | 500 | 10 | |
| Da | 26 | 4 | |
Citerea celor 4 celule din acest tabel 2 X 2 ne spune că în acest sondaj (ipotetic) de 540 de persoane, 500 nu au îndeplinit criteriile pentru o tulburare de consum de alcool sau de substanțe ilicite (Nu, Nu); 26 au îndeplinit criteriile doar pentru o tulburare legată de consumul de alcool (Da, Nu); 10 au îndeplinit criteriile doar pentru o tulburare legată de consumul de substanțe ilicite (Nu, Da), și 4 au îndeplinit criteriile atât pentru o tulburare legată de consumul de alcool, cât și pentru o tulburare legată de consumul de substanțe ilicite (Da, Da). În plus, cu puțină matematică aplicată, putem vedea că un total de 30 au avut o tulburare de consum de alcool (26 + 4) și 14 au avut o tulburare de consum de substanțe ilicite (10 + 4). Și, putem vedea că 40 au avut un fel de tulburare de consum de substanțe (26 + 10 + 4).
 Pentru a face această distincție între variabile și niveluri sau categorii de variabile foarte clară, să luăm în considerare încă un exemplu: un design de studiu 2 X 3. În primul rând, făcând calculele, ar trebui să vedem 6 rezultate (celule) posibile. În al doilea rând, știm că prima variabilă (grupa de vârstă) are 2 categorii (sub 30 de ani, 30 de ani sau mai mult), iar cealaltă variabilă (statutul de angajare) are 3 categorii (angajat complet, angajat parțial, șomer). De data aceasta, cele 6 celule ale proiectului nostru sunt goale, deoarece așteptăm datele.
Pentru a face această distincție între variabile și niveluri sau categorii de variabile foarte clară, să luăm în considerare încă un exemplu: un design de studiu 2 X 3. În primul rând, făcând calculele, ar trebui să vedem 6 rezultate (celule) posibile. În al doilea rând, știm că prima variabilă (grupa de vârstă) are 2 categorii (sub 30 de ani, 30 de ani sau mai mult), iar cealaltă variabilă (statutul de angajare) are 3 categorii (angajat complet, angajat parțial, șomer). De data aceasta, cele 6 celule ale proiectului nostru sunt goale, deoarece așteptăm datele.
| Situația de ocupare a forței de muncă | |||||||
|---|---|---|---|---|---|---|---|
|
Grupa de vârstă |
Complet angajat | Parțial angajat | . Angajat | Șomer | |||
| <30 | |||||||
| ≥30 | |||||||
Așa, atunci când vedeți o descriere a designului studiului care arată ca două numere înmulțite, aceasta vă spune, în esență, câte categorii sau niveluri există pentru fiecare variabilă și vă conduce să înțelegeți câte celule sau rezultate posibile există. Un design 3 X 3 are 9 celule, un design 3 X 4 are 12 celule și așa mai departe. Această problemă devine din nou importantă atunci când discutăm despre mărimea eșantionului în capitolul 6.
Completați următoarea activitate din caietul de lucru:
- SWK 3401.3-4.1 Începutul introducerii datelor
Rezumat al capitolului
În rezumat, cercetătorii proiectează multe dintre studiile lor cantitative pentru a testa ipoteze despre relațiile dintre variabile. Înțelegerea naturii variabilelor implicate ajută la înțelegerea și evaluarea cercetării efectuate. Înțelegerea distincțiilor dintre diferitele tipuri de variabile, precum și dintre variabile și categorii, are implicații importante pentru proiectarea studiilor, măsurători și eșantioane. Printre alte subiecte, capitolul următor explorează intersecția dintre natura variabilelor studiate în cercetarea cantitativă și modul în care cercetătorii se apucă să măsoare aceste variabile.
Dispuneți un moment pentru a realiza următoarea activitate.