
Lo primero que debemos entender es la naturaleza de las variables y cómo se utilizan las variables en el diseño de un estudio para responder a las preguntas del mismo. En este capítulo aprenderá:
- diferentes tipos de variables en los estudios cuantitativos,
- cuestiones en torno a la pregunta de la unidad de análisis.
Comprensión de las variables cuantitativas
La raíz de la palabra variable está relacionada con la palabra «variar», lo que debería ayudarnos a entender qué pueden ser las variables. Las variables son elementos, entidades o factores que pueden cambiar (variar); por ejemplo, la temperatura exterior, el costo de la gasolina por galón, el peso de una persona y el estado de ánimo de las personas de su familia extendida son todas variables. En otras palabras, pueden tener diferentes valores bajo diferentes condiciones o para diferentes personas.
Usamos variables para describir características o factores de interés. Los ejemplos podrían incluir el número de miembros en diferentes hogares, la distancia a las fuentes de alimentos saludables en diferentes vecindarios, la proporción de profesores de trabajo social con respecto a los estudiantes en un programa de BSW o MSW, la proporción de personas de diferentes grupos raciales/étnicos encarcelados, el costo del transporte para recibir servicios de un programa de trabajo social, o la tasa de mortalidad infantil en diferentes condados. En la investigación de la intervención del trabajo social, las variables podrían incluir características de la intervención (intensidad, frecuencia, duración) y resultados asociados con la intervención.
Variables demográficas. Los trabajadores sociales suelen estar interesados en lo que llamamos variables demográficas. Las variables demográficas se utilizan para describir las características de una población, grupo o muestra de la población. Ejemplos de variables demográficas aplicadas con frecuencia son
- la edad,
- la etnia,
- el origen nacional,
- la afiliación religiosa,
- el género,
- la orientación sexual,
- estado civil/relacional,
- estado laboral,
- afiliación política,
- ubicación geográfica,
- nivel de educación y
- ingresos.
A un nivel más macro, la demografía de una comunidad u organización suele incluir su tamaño; las organizaciones suelen medirse en términos de su presupuesto global.
Variables independientes y dependientes. La forma en que los investigadores piensan en las variables del estudio tiene importantes implicaciones para el diseño del estudio. Los investigadores toman decisiones sobre si deben servir como variables independientes o como variables dependientes. Esta distinción no es algo inherente a una variable, sino que se basa en la forma en que el investigador decide definir cada variable. Las variables independientes son las que se podrían considerar como variables de «entrada» manipuladas, mientras que las variables dependientes son aquellas en las que se observaría el impacto o la «salida» de esa variación de entrada.
La manipulación intencionada de la variable de «entrada» (independiente) no siempre está implicada. Consideremos el ejemplo de un estudio realizado en Suecia que examinaba la relación entre haber sido víctima de maltrato infantil y el posterior absentismo escolar: nadie manipuló intencionadamente si los niños serían víctimas de maltrato infantil (Hagborg, Berglund, & Fahlke, 2017). Los investigadores plantearon la hipótesis de que las diferencias que se producen de forma natural en la variable de entrada (historial de maltrato infantil) se asociarían con una variación sistemática en una variable de resultado específica (absentismo escolar). En este caso, la variable independiente era la historia de ser víctima de maltrato infantil, y la variable dependiente era el resultado de absentismo escolar. En otras palabras, el investigador tiene la hipótesis de que la variable independiente provoca una variación o un cambio en la variable dependiente. Esto es lo que podría parecer en un diagrama en el que «x» es la variable independiente e «y» es la variable dependiente (nota: usted vio esta designación antes, en el capítulo 3, cuando discutimos la lógica de causa y efecto):

Para otro ejemplo, considere la investigación que indica que ser víctima de maltrato infantil se asocia con un mayor riesgo de consumo de sustancias durante la adolescencia (Yoon, Kobulsky, Yoon, & Kim, 2017). La variable independiente en este modelo sería tener una historia de maltrato infantil. La variable dependiente sería el riesgo de consumo de sustancias durante la adolescencia. Este ejemplo es aún más elaborado porque especifica la vía por la que la variable independiente (el maltrato infantil) podría imponer sus efectos sobre la variable dependiente (el consumo de sustancias en la adolescencia). Los autores del estudio demostraron que el estrés postraumático (TEP) era un vínculo entre el maltrato infantil (físico y sexual) y el consumo de sustancias durante la adolescencia.

Tómese un momento para completar la siguiente actividad.
Tipos de variables cuantitativas
También hay otras formas significativas de pensar en las variables de interés. Consideremos diferentes características de las variables utilizadas en los estudios de investigación cuantitativa. Aquí exploramos las variables cuantitativas como de naturaleza categórica, ordinal o de intervalo. Estas características tienen implicaciones tanto para la medición como para el análisis de datos.
Variables categóricas. Algunas variables pueden tomar valores que varían, pero no de forma numérica significativa. En su lugar, pueden definirse en términos de las categorías que son posibles. Lógicamente, se denominan variables categóricas. El software estadístico y los libros de texto a veces se refieren a las variables con categorías como variables nominales. Nominal puede pensarse en términos de la raíz latina «nom», que significa «nombre», y no debe confundirse con número. Nominal significa lo mismo que categórico en la descripción de variables. En otras palabras, las variables categóricas o nominales se identifican por los nombres o etiquetas de las categorías representadas. Por ejemplo, el color del último coche en el que se montó sería una variable categórica: azul, negro, plateado, blanco, rojo, verde, amarillo u otro son categorías de la variable que podríamos llamar color del coche.
Lo importante de las variables categóricas es que estas categorías no tienen una secuencia u orden numérico relevante. No hay ninguna diferencia numérica entre los diferentes colores de los coches, o diferencia entre «sí» o «no» como las categorías en la respuesta de si usted montó en un coche azul. No hay ningún orden o jerarquía implícita en las categorías «hispano o latino» y «no hispano o latino» en una variable de etnicidad; tampoco hay ningún orden relevante en las categorías de variables como el género, el estado o la región geográfica en la que reside una persona, o si la residencia de una persona es propia o alquilada.
Si un investigador decidiera utilizar números como símbolos relacionados con las categorías en una variable de este tipo, los números son arbitrarios-cada número es esencialmente sólo un nombre diferente y más corto para cada categoría. Por ejemplo, la variable género podría codificarse de las siguientes maneras, y no habría ninguna diferencia, siempre que el código se aplicara de forma coherente.
| Opción de codificación A | Categorías de variables | Opción de codificación B |
|---|---|---|
| 1 | hombre | 2 |
| 2 | mujer | 1 |
| 3 | que no sea sólo hombre o mujer | 4 |
| 4 | prefiero no contestar | 3 |
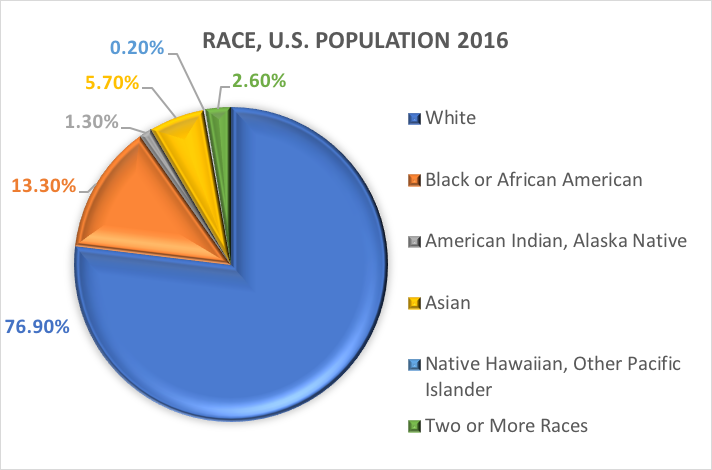
Raza y etnia.Una de las variables categóricas más exploradas en la investigación sobre trabajo social y ciencias sociales es la demográfica referida al origen racial y/o étnico de una persona. Muchos estudios utilizan las categorías especificadas en los informes anteriores de la Oficina del Censo de los Estados Unidos. Esto es lo que la Oficina del Censo de EE.UU. tiene que decir sobre las dos variables demográficas distintas, la raza y la etnia (https://www.census.gov/mso/www/training/pdf/race-ethnicity-onepager.pdf):
¿Qué es la raza? La Oficina del Censo define la raza como la autoidentificación de una persona con uno o más grupos sociales. Un individuo puede declararse como blanco, negro o afroamericano, asiático, indio americano y nativo de Alaska, nativo de Hawai y otras islas del Pacífico, o de alguna otra raza. Los encuestados pueden declarar varias razas.
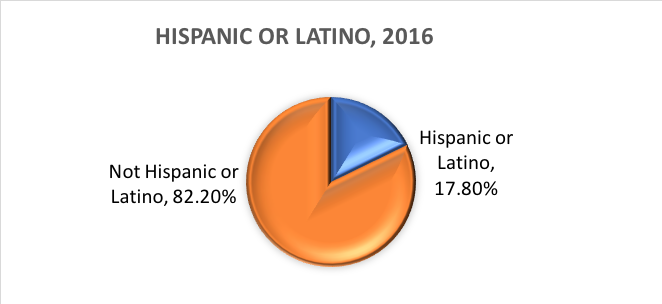
¿Qué es la etnia? El origen étnico determina si una persona es de origen hispano o no. Por esta razón, el origen étnico se divide en dos categorías, hispano o latino y no hispano o latino. Los hispanos pueden declararse de cualquier raza.
En otras palabras, la Oficina del Censo define dos categorías para la variable llamada etnia (hispano o latino y no hispano o latino), y siete categorías para la variable llamada raza. Aunque estas variables y categorías se aplican a menudo en la investigación de las ciencias sociales y el trabajo social, no están exentas de críticas.
A partir de estas categorías, esto es lo que se estima que ocurre con la población estadounidense en 2016:
Variables dicotómicas.Existe una categoría especial de variable categórica con implicaciones para determinados análisis estadísticos. Las variables categóricas que constan de exactamente dos opciones, ni más ni menos, se denominan variables dicotómicas. Un ejemplo es la dicotomía de la Oficina del Censo de EE.UU. de etnia hispana/latina y no hispana/no latina. Otro ejemplo es que los investigadores deseen comparar a las personas que completan el tratamiento con las que lo abandonan antes de completarlo. Con las dos categorías, completado o no completado, esta variable de finalización del tratamiento no sólo es categórica, sino dicotómica. Las variables en las que los individuos responden «sí» o «no» también son dicotómicas por naturaleza.
La tradición pasada de tratar el género como masculino o femenino es otro ejemplo de variable dicotómica. Sin embargo, existen argumentos muy sólidos para dejar de tratar el género de esta manera dicotómica: una mayor variedad de identidades de género son demostrablemente relevantes en el trabajo social para las personas cuya identidad no se alinea con las categorías dicotómicas (también llamadas binarias) de hombre/mujer u hombre/mujer. Estas incluyen categorías como agénero, andrógino, bigénero, cisgénero, género expansivo, género fluido, género cuestionado, queer, transgénero y otras.
Variables ordinales. A diferencia de las variables categóricas, a veces las categorías de una variable tienen una secuencia numérica lógica o un orden. Ordinal, por definición, se refiere a una posición en una serie. Las variables con categorías numéricas relevantes se denominan variables ordinales. Por ejemplo, existe un orden implícito de categorías de menor a mayor con la variable denominada nivel educativo. Las categorías de los datos del Las categorías de los datos del censo para esta variable ordinal son:
- ninguno
- 1er-4º grado
- 5º-6º grado
- 7º-8º grado
- 9º grado
- 10º grado
- 11º grado
- graduado de secundaria
- algunos estudios universitarios, sin título
- título de asociado, ocupacional
- título de asociado académico
- licenciatura
- máster
- título profesional
- doctorado
Al observar los datos estimados de la Oficina del Censo de 2016 para esta variable, podemos ver que las mujeres superan a los hombres en la categoría de haber obtenido una licenciatura: de las 47.718.000 personas en esta categoría, 22.485.000 eran hombres y 25.234.000 eran mujeres. Mientras que este patrón de género se mantuvo para los que recibieron títulos de máster, el patrón se invirtió para recibir títulos de doctorado: más hombres que mujeres obtuvieron este nivel más alto de educación. También es interesante observar que las mujeres superaron a los hombres en el extremo inferior del espectro: 441.000 mujeres declararon no tener estudios en comparación con 374.000 hombres.
Aquí hay otro ejemplo de uso de variables ordinales en la investigación del trabajo social: cuando las personas buscan tratamiento para un problema de abuso de alcohol, los trabajadores sociales pueden querer saber si es su primer, segundo, tercer o cualquier otro intento serio de cambiar su conducta de consumo de alcohol. Los participantes inscritos en un estudio que compara los enfoques de tratamiento para los trastornos por consumo de alcohol informaron que el estudio de intervención fue en cualquier lugar de su primer a undécimo intento de cambio significativo (Begun, Berger, Salm-Ward, 2011). Esta variable de intento de cambio tiene implicaciones sobre cómo los trabajadores sociales podrían interpretar los datos que evalúan una intervención que no fue el primer intento para todos los involucrados.
Escalas de valoración. Consideremos un tipo diferente pero comúnmente utilizado de variable ordinal: las escalas de calificación. Los investigadores sociales, de comportamiento y de trabajo social suelen pedir a los participantes en el estudio que apliquen una escala de valoración para describir sus conocimientos, actitudes, creencias, opiniones, habilidades o comportamientos. Dado que las categorías de dicha escala están secuenciadas (de mayor a menor o de menor a mayor), las llamamos variables ordinales.

Los ejemplos incluyen que los participantes califiquen:
- en qué medida están de acuerdo o en desacuerdo con ciertas afirmaciones (de nada a extremadamente);
- con qué frecuencia realizan ciertos comportamientos (de nunca a siempre);
- con qué frecuencia realizan ciertos comportamientos (cada hora, cada día, cada semana, cada mes, cada año o con menos frecuencia);
- la calidad de la actuación de alguien (de mala a excelente);
- el grado de satisfacción con el trato recibido (de muy insatisfecho a muy satisfecho)
- su nivel de confianza (de muy bajo a muy alto).
Variables de intervalo. Otras variables adquieren valores que varían de forma numérica significativa. De nuestra lista de variables demográficas, la edad es un ejemplo común. El valor numérico asignado a una persona individual indica el número de años desde que nació (en el caso de los bebés, el valor numérico puede indicar días, semanas o meses desde el nacimiento). Aquí los posibles valores de la variable están ordenados, como las variables ordinales, pero se introduce una gran diferencia: la naturaleza de los intervalos entre los posibles valores. Con las variables de intervalo, la «distancia» entre los valores posibles adyacentes es igual. Algunos paquetes de software estadístico y libros de texto utilizan el término variable de escala: esto es exactamente lo mismo que lo que llamamos una variable de intervalo.
Por ejemplo, en el gráfico siguiente, la diferencia de 1 onza entre que esta persona consuma 1 onza o 2 onzas de alcohol (lunes, martes) es exactamente la misma que la diferencia de 1 onza entre que consuma 4 onzas o 5 onzas (viernes, sábado). Si hiciéramos un diagrama de los posibles puntos de la escala, todos serían equidistantes; el intervalo entre dos puntos cualquiera se mide en unidades estándar (onzas, en este ejemplo).
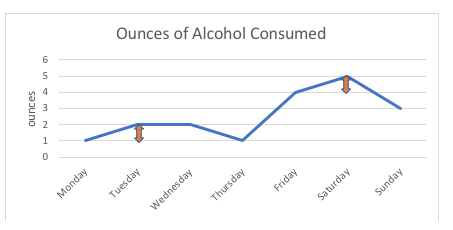
Con las variables ordinales, como las escalas de valoración, nadie puede decir con certeza que la «distancia» entre las opciones de respuesta de «nunca» y «a veces» es la misma que la «distancia» entre «a veces» y «a menudo», incluso si utilizamos números para secuenciar estas opciones de respuesta. Por tanto, la escala de valoración sigue siendo ordinal, no de intervalo.
Lo que puede resultar un poco confuso es que ciertos programas de software estadístico, como el SPSS, se refieren a una variable de intervalo como una variable de «escala». Muchas variables utilizadas en la investigación del trabajo social están ordenadas y tienen distancias iguales entre los puntos. Consideremos, por ejemplo, la variable de orden de nacimiento. Esta variable es de intervalo porque:
- los posibles valores están ordenados (por ejemplo, el tercer hijo nació después del primero y del segundo y antes del cuarto), y
- las «distancias» o intervalos se miden en unidades equivalentes de una persona.
Variables continuas. Existe un tipo especial de variable numérica de intervalo que llamamos variables continuas. Una variable como la edad puede ser tratada como una variable continua. La edad es de naturaleza ordinal, ya que los números más altos significan algo en relación con los números más pequeños. La edad también cumple nuestro criterio de ser una variable de intervalo si la medimos en años (o meses o semanas o días) porque es ordinal y hay la misma «distancia» entre tener 15 y 30 años que entre tener 40 y 55 años (15 años naturales). Lo que hace que sea una variable continua es que también hay puntos de «fracción» posibles y significativos entre dos intervalos cualesquiera. Por ejemplo, una persona puede tener 20½ (20,5) o 20¼ (20,25) o 20¾ (20,75) años; no estamos limitados a los números enteros para la edad. En cambio, cuando miramos el orden de nacimiento, no podemos tener una fracción significativa de una persona entre dos posiciones de la escala.
El caso especial de los ingresos. Una de las variables de las que más se abusa en la investigación en ciencias sociales y trabajo social es la relativa a la renta. Consideremos un ejemplo sobre los ingresos del hogar (independientemente del número de personas que lo componen). Esta variable podría ser categórica (nominal), ordinal o de intervalo (escala) dependiendo de cómo se maneje.
Ejemplo categórico: Dependiendo de la naturaleza de las preguntas de la investigación, un investigador podría optar simplemente por utilizar las categorías dicotómicas de «suficientes recursos» e «insuficientes recursos» para clasificar los hogares, basándose en algún método de cálculo estándar. Estos podrían denominarse «pobres» y «no pobres» si se utiliza un umbral de pobreza para clasificar los hogares. Estas distintas categorías de la variable de ingresos no tienen una secuencia numérica significativa, por lo que es una variable categórica.
Ejemplo ordinal: Las categorías para clasificar a los hogares podrían estar ordenadas de menor a mayor. Por ejemplo, estas categorías de ingresos anuales son comunes en los estudios de mercado:
- Menos de 25.000 dólares.
- De 25.000 a 34.999 dólares.
- De 35.000 a 49.999 dólares.
- De 50.000 a 74.999 dólares.
- De 75.000 a 99.999 dólares.
- De 100.000 a 149.999 dólares.
- De 150.000 a 199.999 dólares.
- De 200.000 dólares o más.
Nótese que las categorías no tienen el mismo tamaño: la «distancia» entre pares de categorías no es siempre la misma. Empiezan en incrementos de unos 10.000 dólares, pasan a incrementos de 25.000 dólares y terminan en incrementos de unos 50.000 dólares.
Ejemplo de intervalo. Si un investigador pidiera a los participantes del estudio que informaran de una cantidad real en dólares para los ingresos del hogar, veríamos una variable de intervalo. Los valores posibles están ordenados y el intervalo entre cualquier unidad adyacente posible es de 1 dólar (siempre que no se utilicen fracciones de dólar o céntimos). Así, un ingreso de 10.452 dólares es la misma distancia en un continuo desde 9.452 dólares y 11.452 dólares – 1.000 dólares en cualquier dirección.

El caso especial de la edad. Al igual que los ingresos, la «edad» puede significar cosas diferentes en distintos estudios. La edad suele ser un indicador del «tiempo desde el nacimiento». Podemos calcular la edad de una persona restando una variable de fecha de nacimiento de la fecha de medición (la fecha actual menos la fecha de nacimiento). En el caso de los adultos, las edades suelen medirse en años, donde los posibles valores adyacentes se distancian en unidades de 1 año: 18, 19, 20, 21, 22, etc. Por lo tanto, la variable de edad podría ser una variable de intervalo de tipo continuo.
Sin embargo, un investigador podría desear colapsar los datos de edad en categorías ordenadas o grupos de edad. Estos seguirían siendo ordinales, pero podrían dejar de ser de intervalo si los incrementos entre los posibles valores no son unidades equivalentes. Por ejemplo, si estamos más interesados en que la edad represente periodos específicos del desarrollo humano, los intervalos de edad podrían no ser iguales en cuanto a los criterios de edad. Posiblemente podrían ser:
- Infancia (nacimiento a 18 meses)
- Niñez (18 meses a 2 ½ años)
- Preescolar (2 ½ a 5 años)
- Edad escolar (6 a 11 años)
- Adolescencia (12 a 17 años)
- Adultez emergente (18 a 25 años)
- Adultez (26 a 45 años)
- Adultez media (46 a 60 años)
- Joven-Edad avanzada (60 a 74 años)
- Adultez media (75 a 84 años)
- Adultez avanzada (85 o más años)
La edad puede incluso tratarse como una variable estrictamente categórica (no ordinal). Por ejemplo, si la variable de interés es si alguien tiene la edad legal para beber (21 años o más), o no. Tenemos dos categorías -cumple o no cumple los criterios de la edad legal para beber en Estados Unidos- y cualquiera de ellas podría codificarse con un «1» y la otra con un «0» o un «2» sin ninguna diferencia de significado.
¿Cuál es la respuesta «correcta» en cuanto a cómo medir la edad (o los ingresos)? La respuesta es «depende». De lo que depende es de la naturaleza de la pregunta de investigación: qué conceptualización de la edad (o de los ingresos) es más relevante para el estudio que se está diseñando.
Variables alfanuméricas. Por último, hay datos que no encajan en ninguna de estas clasificaciones. A veces la información que conocemos tiene la forma de una dirección o un número de teléfono, un nombre o un apellido, un código postal u otras frases. Este tipo de información se denomina a veces variable alfanumérica. Por ejemplo, la variable «dirección»: la dirección de una persona puede estar formada por caracteres numéricos (el número de la casa) y caracteres alfanuméricos (los nombres de la calle, la ciudad y el estado), como 1600 Pennsylvania Ave. NW, Washington, DC, 20500.

En realidad, tenemos varias variables presentes en este ejemplo de dirección:
- la dirección de la calle: 1600 Pennsylvania Ave.
- la ciudad (y «estado»): Washington, DC
- el código postal: 20500.
Este tipo de información no representa categorías cuantitativas específicas o valores con significado sistemático en los datos. A veces también se denominan variables «de cadena» en ciertos paquetes de software porque están formadas por una cadena de símbolos. Para ser útil para un investigador, una variable de este tipo tendría que ser convertida o recodificada en valores significativos.
Una nota sobre la unidad de análisis
Una cosa importante a tener en cuenta al pensar en las variables es que los datos pueden ser recogidos en muchos niveles diferentes de observación. Los elementos estudiados pueden ser células individuales, sistemas de órganos o personas. O bien, el nivel de observación puede ser parejas de individuos, como parejas, hermanos y hermanas, o díadas de padres e hijos. En este caso, el investigador puede recoger información sobre la pareja de cada individuo, pero está observando los datos de cada pareja. Por tanto, diríamos que la unidad de análisis es la pareja o la díada, no cada persona individual. La unidad de análisis también podría ser un grupo más amplio: por ejemplo, se podrían recoger datos de cada uno de los alumnos de aulas enteras cuando la unidad de análisis son las aulas de un colegio o sistema escolar. O bien, la unidad de análisis podría ser a nivel de barrios, programas, organizaciones, condados, estados o incluso naciones. Por ejemplo, muchas de las variables utilizadas como indicadores de seguridad alimentaria a nivel de comunidades, como la asequibilidad y la accesibilidad, se basan en datos recogidos de hogares individuales (Kaiser, 2017). La unidad de análisis en los estudios que utilizan estos indicadores serían las comunidades que se comparan. Esta distinción tiene importantes implicaciones de medición y análisis de datos.
Un recordatorio sobre las variables frente a los niveles de las variables
Un estudio podría describirse en términos del número de categorías de variables, o niveles, que se están comparando. Por ejemplo, puede ver un estudio descrito como un diseño 2 X 2, pronunciado como un diseño de dos en dos. Esto significa que hay 2 categorías posibles para la primera variable y 2 categorías posibles para la otra variable; ambas son variables dicotómicas. Un estudio que compare 2 categorías de la variable «trastorno por consumo de alcohol» (categorías para cumplir los criterios, sí o no) con 2 categorías de la variable «trastorno por consumo de sustancias ilícitas» (categorías para cumplir los criterios, sí o no) tendría 4 resultados posibles (matemáticamente, 2 x 2=4) y podría diagramarse así (datos basados en proporciones de la encuesta NSDUH de 2016, presentados en SAMHSA, 2017):
| Trastorno por uso de sustancias ilícitas (SUD) | |||
|---|---|---|---|
|
Trastorno por uso de alcohol (AUD) |
No | Sí | |
| No | 500 | 10 | |
| Sí | 26 | 4 | |
La lectura de las 4 casillas de esta tabla de 2 X 2 nos dice que en esta encuesta (hipotética) de 540 individuos, 500 no cumplían los criterios de un trastorno por consumo de alcohol o de sustancias ilícitas (No, No); 26 cumplían los criterios de un trastorno por consumo de alcohol únicamente (Sí, No); 10 cumplían los criterios de un trastorno por consumo de sustancias ilícitas únicamente (No, Sí), y 4 cumplían los criterios de un trastorno por consumo de alcohol y de sustancias ilícitas (Sí, Sí). Además, aplicando un poco de matemáticas, podemos ver que un total de 30 tenían un trastorno por consumo de alcohol (26 + 4) y 14 tenían un trastorno por consumo de sustancias ilícitas (10 + 4). Y, podemos ver que 40 tenían algún tipo de trastorno por consumo de sustancias (26 + 10 + 4).
 Para que esta distinción entre las variables y los niveles o categorías de las variables quede muy clara, consideremos un ejemplo más: un diseño de estudio 2 X 3. En primer lugar, haciendo las cuentas, deberíamos ver 6 posibles resultados (celdas). En segundo lugar, sabemos que la primera variable (grupo de edad) tiene 2 categorías (menos de 30 años, 30 años o más) y la otra variable (situación laboral) tiene 3 categorías (totalmente empleado, parcialmente empleado, desempleado). Esta vez las 6 celdas de nuestro diseño están vacías porque estamos esperando los datos.
Para que esta distinción entre las variables y los niveles o categorías de las variables quede muy clara, consideremos un ejemplo más: un diseño de estudio 2 X 3. En primer lugar, haciendo las cuentas, deberíamos ver 6 posibles resultados (celdas). En segundo lugar, sabemos que la primera variable (grupo de edad) tiene 2 categorías (menos de 30 años, 30 años o más) y la otra variable (situación laboral) tiene 3 categorías (totalmente empleado, parcialmente empleado, desempleado). Esta vez las 6 celdas de nuestro diseño están vacías porque estamos esperando los datos.
| Estado de empleo | ||||
|---|---|---|---|---|
|
Grupo de edad |
Totalmente empleado | Parcialmente Empleado | Desempleado | |
| <30 | ||||
| ≥30 | ||||
Así, cuando vea la descripción de un diseño de estudio que parezca que se multiplican dos números, eso le está diciendo esencialmente cuántas categorías o niveles de cada variable hay y le lleva a entender cuántas celdas o resultados posibles existen. Un diseño 3 X 3 tiene 9 celdas, un diseño 3 X 4 tiene 12 celdas, y así sucesivamente. Esta cuestión vuelve a ser importante cuando analizamos el tamaño de la muestra en el capítulo 6.
Complete la siguiente actividad del cuaderno de trabajo:
- SWK 3401.3-4.1 Inicio de la introducción de datos
Resumen del capítulo
En resumen, los investigadores diseñan muchos de sus estudios cuantitativos para probar hipótesis sobre las relaciones entre variables. Comprender la naturaleza de las variables involucradas ayuda a entender y evaluar la investigación realizada. Comprender las distinciones entre los diferentes tipos de variables, así como entre las variables y las categorías, tiene importantes implicaciones para el diseño del estudio, la medición y las muestras. Entre otros temas, el siguiente capítulo explora la intersección entre la naturaleza de las variables estudiadas en la investigación cuantitativa y la forma en que los investigadores se disponen a medir esas variables.
Tómese un momento para completar la siguiente actividad.