
Ansikte mot ansikte är det sätt på vilket vi oftast känner igen och kommunicerar med varandra. Att känna igen enskilda ansikten är bara möjligt eftersom det mänskliga ansiktet är så enormt varierande. Den extrema ansiktslikheten hos enäggstvillingar, som ärver samma versioner av varje gen från var och en av sina föräldrar och därför har identiska genotyper, visar att de olika ansiktsdrag genom vilka vi känner igen människor är nedärvda. Detta innebär att de till största delen bestäms av de särskilda kombinationer av genetiska varianter som ärvts från föräldrarna. Med genetisk variant menas en version av en viss gen som skiljer sig från andra versioner av samma gen vid en viss position i DNA. Det faktum att ansiktsdragen hos enäggstvillingar som vuxit upp åtskilda är lika lika lika som hos enäggstvillingar som vuxit upp tillsammans stöder starkt uppfattningen att miljöeffekter på ansiktsdragen normalt är mycket begränsade.
Ansiktsdrag, såsom näsans form, en tillbakadragen haka eller ”Habsburgska läpparna”, förs ofta vidare i familjer från generation till generation. Vårt mål har varit att identifiera specifika genetiska varianter som bestämmer vissa ansiktsdrag. Vår framgång för att kunna göra detta, vilket inte har gjorts tidigare, har varit beroende av att använda komplicerade statistiska förfaranden för att analysera ansiktsbilder av frivilliga människor.
Vår utgångspunkt var en stor samling tredimensionella ansiktsbilder tagna med en kommersiell högteknologisk kamera. Dessa bilder gav oss, efter viss manipulering, en definition av varje ansikte som 30 000 punkter på ansiktsytan, i praktiken en tredimensionell karta över ansiktet. För att jämföra funktioner i olika ansikten lade vi alla ansiktsbilderna över varandra. Detta görs genom att först överlagra bilderna med avseende på ett antal landmärkespunkter, t.ex. vid näsans spets eller i ögon- eller munhörnen. Detta förfarande är ganska likt det som Francis Galton, en pionjär inom studier av ansikten och tvillingar, använde för nästan 150 år sedan, men nu har vi sofistikerade datorverktyg och högteknologiska kameror som förbättrar den utsträckning i vilken vi kan överlagra alla bilder med varandra enormt.
Vi har använt frivilliga från tre källor: a) 1832 unika frivilliga från vår mycket välkaraktäriserade studie People of the British Isles (PoBI), b) 1567 unika tvillingar från TwinsUK-kohorten, ungefär lika många enäggstvillingar som icke-identiska tvillingar, och c) 33 bilder av östasiater, huvudsakligen kineser.
Då vi hade ansiktsbilderna av tvillingarna blev det möjligt att ta nästa viktiga steg i analysen, nämligen att identifiera de ansiktsdrag som troligen har en hög arvbarhet. Två individer som är enäggstvillingar har samma uppsättning genetiska varianter (DNA-sekvenser). Det är dessa varianter som bestämmer deras ansiktsdrag och resulterar i mycket likartade ansikten. Ansiktsdragen definieras av associerade grupper av punkter i ansiktet, ungefär som kullar och dalar på en
tredimensionell karta.
Positionen av en punkt på en ansiktsbild av den ena medlemmen i ett identiskt tvillingpar bör vara mycket lik positionen av motsvarande punkt på bilden av den andra tvillingen. I vilken utsträckning den skiljer sig kommer att vara ett mått på de icke-genetiska miljöinfluenserna på positionen av denna punkt i ansiktet. Två individer som inte är identiska tvillingar kan däremot ha olika genetiska varianter som bestämmer åtminstone några av deras ansiktsdrag. Läget för samma punkt på en ansiktsbild av en av de enskilda icke-identiska tvillingarna tenderar därför att inte ligga lika nära läget för motsvarande punkt på en bild av den andra tvillingen som om de vore identiska tvillingar. I vilken utsträckning punkterna ligger längre ifrån varandra för de icke-identiska tvillingarna än för de identiska tvillingarna är ett mått på de genetiska influenserna på denna punkt, vilket genetiker kallar ärftlighet. Med hjälp av ytterligare komplicerade statistiska förfaranden kan vi vikta varje punkt i ansiktet med dess arvbarhet mätt på detta sätt.
Effekten av denna viktning kan ses i figur 1, där vi har plottat frekvensen av punkter i ansiktsprofilen som har olika arvbarhet. Graden av ärftlighet för en viss position sträcker sig från 1 om måttet alltid är exakt likadant i par av enäggstvillingar men annorlunda i
icke-identiska tvillingar, till 0 om skillnaderna mellan enäggstvillingar är desamma som mellan icke-identiska tvillingar, och alltså i praktiken alla
icke-genetiska, i första hand miljömässigt betingade. De röda kolumnerna är för de viktade värdena, de blå för de ursprungliga värdena och de lila för överlappningen. Den röda profilen är i genomsnitt klart högre och mycket smalare än den blå, vilket visar den gynnsamma effekten av viktningen.
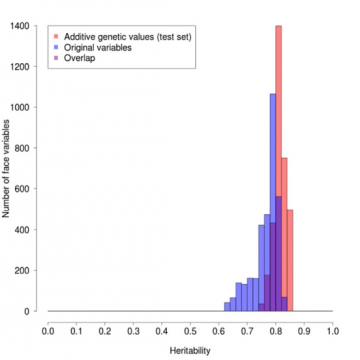
Figur 1: Jämförelse av profilens arvbarheter för ursprungliga respektive arvbarhetsviktade värden.
Nästa utmaning är att definiera de ansiktsdrag som ska användas för den genetiska analysen, baserat på grupper av associerade punkter. För detta använder vi de heritabilitetsviktade punkterna med antagandet att detta kommer att ge en egenskap som totalt sett sannolikt är mer ärftlig än den som erhålls med hjälp av de oviktade punkterna. De viktade punkterna användes för vad statistiker kallar en PCA, som står för Principal Components Analysis (huvudkomponentanalys). Detta är ett sätt att ur data ta fram de egenskaper som är mest variabla. Varje PCA, och det kan finnas upp till 50 eller fler för komplexa data som ansiktsbilderna, är i sig ett mått på ett ansiktsdrag, analogt med avståndet mellan ögonen, men som i praktiken kombinerar olika mätningar baserade på en grupp punkter till ett enda värde.
Här långt har vi vid definitionen av ansiktsdrag inte använt oss av specifik genetisk information. Vi har DNA-baserad genetisk information om cirka 500 000 varianter för var och en av cirka 1 500 individer från våra PoBI-frivilliga för vilka vi har bilder och för ett liknande antal av de frivilliga från TwinsUK som har bilder. Nästa steg var därför att leta efter specifika genetiska varianter som associerades signifikant med våra PCA-baserade ansiktsdrag.
Vår strategi för den genetiska analysen bygger på idén att skillnader i ansiktsdrag bör analyseras som diskreta, individuellt identifierbara egenskaper, inte som ett kvantitativt mått, till exempel en persons längd. Vi kan inte känna igen en person enbart på hans eller hennes längd eller på något enskilt kvantitativt ansiktsdrag, t.ex. avståndet mellan ögonen eller förhållandet mellan ansiktets höjd och bredd. Vi hanterar detta genom att fokusera på de individer som befinner sig i de extrema övre eller nedre 10 % av vart och ett av de värden som ges av PCA och frågar oss om de delar någon eller några av de 500 000 genetiska markörerna i högre grad än de individer som inte befinner sig i dessa extremer. Vi använde oss av volontärerna från People of the British Isles för att välja ut kandidatgenvarianter, av de 500 000 testade, för vidare analys baserat på betydelsen av skillnaden mellan de extrema och de icke-extrema och på storleken av denna skillnad. Vi frågade sedan om någon av dessa kandidateffekter upprepades hos de cirka 1 500 frivilliga från TwinsUK. På detta sätt har vi identifierat tre specifika och replikerade genetiska varianter med relativt stora effekter, två för egenskaper i ansiktsprofiler och en för området runt ögonen. Var och en av dessa tre varianter har
en partner med en annan DNA-sekvens på samma kritiska position, och i varje fall har den positivt associerade varianten en PoBI-populationsfrekvens på cirka 10 %, där partnern har en högre frekvens på cirka 90 %. Vi kallar den associerade varianten för a och dess partner för A, och eftersom gener kommer i par finns det tre kombinationer av dessa varianter, aa, Aa och AA.
Den första av dessa varianter, som återfinns i en gen som kallas PCDH15, ökade chansen att ha de kvinnliga egenskaperna som visas i figur 2C med en faktor på mer än 7 hos de brittiska kvinnor som bar båda kopiorna av varianten (aa), jämfört med dem som bara hade en (Aa) eller ingen kopia (AA) av varianten. Denna variant är också förknippad med egenskaper som skiljer sig åt mellan de brittiska och de östasiatiska kvinnliga volontärerna. Lägg märke till den uppåtvända änden av näsan och överläppen och den tillbakadragna hakan i figur 2A, som är genomsnittet av de kinesiska ansiktena, och i figur 2B, den mer kinesiska gruppen av PoBI-individerna, och kontrastera detta med figur 2C. Produkten av PCDH15-genen finns i luktcellerna och brosket i näsan hos möss under utveckling, vilket stämmer överens med
en möjlig effekt på näsan av den variant vi har funnit hos människor.
Den andra varianten, i genen som kallas MBTPS1, är förknippad med den ansiktsskillnad som visas i figur 3. Denna skillnad observerades hos kvinnor, och den utmärkande undergruppen av ansikten bar båda kopiorna av varianten (aa). I det här fallet finns den genetiska variant som är förknippad med den övre extrema fenotypen (figur 3A) (förmodligen som aa) hos den afrikanska gröna apan, makaken och olivbabianen, medan dess partner, den vanliga varianten, finns (förmodligen som AA) hos orangutangen, gorillan, schimpansen och mårdhunden, vilket tyder på att denna variantskillnad kan vara förknippad med ansiktsskillnaderna mellan dessa primatgrupper.
Den tredje varianten, i genen som kallas TMEM163, är förknippad hos båda könen med en skillnad i ögonen, vilket visas i figur 4. En defekt version av denna gen har en potentiell roll i en sjukdom som kallas mukolipidos typ IV, ett tillstånd som ibland åtföljs av ansiktsavvikelser, särskilt runt ögonlocken. I våra studier är det den undergrupp av individer som bär på båda kopiorna av varianten (aa) som är förknippad med den övre ytterligheten, som visas i figur 4A. Observera att ögonbredden och ögonhöjden (från ögonbrynets nedre del till ögonlockets övre del) båda är större i den övre extremen än i den nedre extremen.
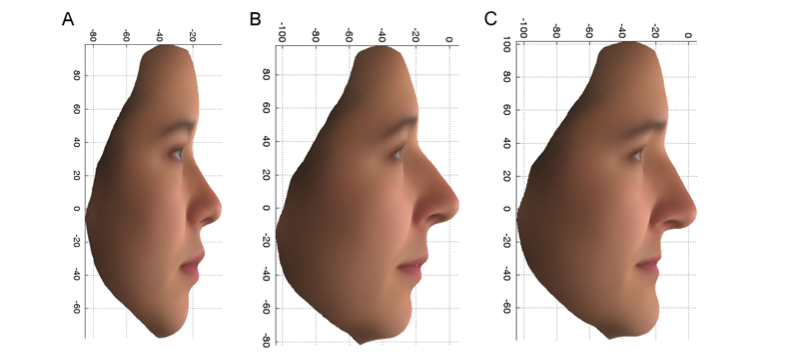
Figur 2: PC2-profil: Genomsnittliga ansikten, med hjälp av de ursprungliga variablerna, för 14 östasiatiska kvinnor (A) och de övre 10 % (mer östasiatiska) (B) och nedre 10 % (mer europeiska) (C) ytterligheterna av PoBI-kvinnorna.
Var och en av de tre genetiska varianter som vi har kunnat associera med ett specifikt ansiktsdrag ökar chansen att ha det specifika draget med
en faktor på mer än 7 hos de brittiska frivilliga som bär på båda kopiorna (aa) av varianten, jämfört med dem som bara har en (Aa) eller ingen (AA) kopia av varianten.

Figur 3: PC7-profil: Genomsnittliga profiler av kvinnliga ansikten, med hjälp av de ursprungliga variablerna, för den övre varianten tillhörande 10 % (A) och den nedre 10 % (C) ytterligheterna och det totala genomsnittet (B).

Figur 4: PC1-ögon: Genomsnittliga ögonfenotyper, med hjälp av de ursprungliga variablerna, för de övre 10 % (A), de nedre 10 % (C) extremerna och det totala genomsnittet (B).
Vår framgång när det gäller att hitta dessa genetiska varianter beror till stor del på vår förmåga att identifiera ansiktsdrag som har hög ärftlighet baserat på tvillingdata och på valet av extremer för att studera sambanden mellan de genetiska varianterna. Det verkar troligt att många fler specifika och relativt stora effekter av genetiska varianter på mänskliga ansiktsdrag kommer att hittas i framtiden med hjälp av tillvägagångssätt som vi har beskrivit. Detta banar väg för att avslöja de molekylära mekanismer genom vilka genetiska varianter bestämmer den extraordinära variabiliteten i människans ansiktsutseende.