
Resursallokering är en viktig aspekt under utförandet av ett Spark-jobb. Om det inte konfigureras korrekt kan ett sparkjobb förbruka hela klusterresurser och få andra program att svälta efter resurser.
Den här bloggen hjälper till att förstå det grundläggande flödet i en Spark-applikation och sedan hur man konfigurerar antalet exekutorer, minnesinställningar för varje exekutor och antalet kärnor för ett Sparkjobb. Det finns några faktorer som vi måste ta hänsyn till för att bestämma de optimala siffrorna för ovanstående tre, som t.ex:
- Mängden data
- Tiden inom vilken ett jobb måste slutföras
- Statisk eller dynamisk allokering av resurser
- Över- eller underströmsapplikation
Introduktion
Låt oss börja med några grundläggande definitioner av termerna som används vid hantering av Spark-applikationer.
Partitioner : En partition är en liten del av en stor distribuerad datamängd. Spark hanterar data med hjälp av partitioner som hjälper till att parallellisera databehandling med minimal datamixning mellan utförarna.
Task : En uppgift är en arbetsenhet som kan köras på en partition av en distribuerad datamängd och som utförs på en enda utförare. Enheten för parallell exekvering är på uppgiftsnivå.Alla uppgifter inom ett enda steg kan exekveras parallellt
Exekutor : En exekutor är en enskild JVM-process som startas för ett program på en arbetarnod. Exekutor kör uppgifter och håller data i minnet eller disklagring över dem. Varje program har sina egna exekutorer. En enda nod kan köra flera exekutorer och exekutorer för ett program kan sträcka sig över flera arbetsnoder. En exekutor är igång under Spark-applikationens
varaktighet och kör uppgifterna i flera trådar. Antalet exekutorer för en Spark-applikation kan anges inne i SparkConf eller via flaggan -num-executors från kommandoraden.
Cluster Manager : En extern tjänst för att förvärva resurser i klustret (t.ex. fristående manager, Mesos, YARN). Spark är agnostisk till en klusterhanterare så länge den kan förvärva exekutorprocesser och dessa kan kommunicera med varandra. vi är främst intresserade av Yarn som klusterhanterare. Ett spark-kluster kan köras i antingen yarn cluster- eller yarn-client-läge:
yarn-client-läge – En drivrutin körs på klientprocessen, Application Master används endast för att begära resurser från YARN.
yarn-cluster-läge – En drivrutin körs inne i Application Master-processen, klienten försvinner när applikationen är initialiserad
Kärnor: En kärna är en grundläggande beräkningsenhet i en CPU och en CPU kan ha en eller flera kärnor för att utföra uppgifter vid en viss tidpunkt. Ju fler kärnor vi har, desto mer arbete kan vi utföra. I Spark styr detta antalet parallella uppgifter som en exekutor kan köra.
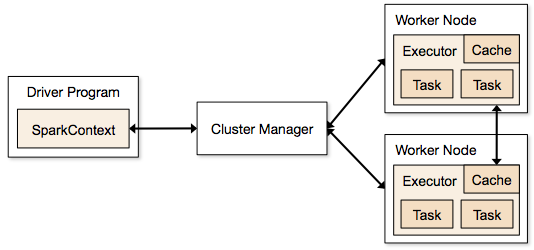
Steg som ingår i klusterläge för ett Spark-jobb
- Från drivrutinskoden ansluter SparkContext till klusterhanteraren (standalone/Mesos/YARN).
- Clusterhanteraren allokerar resurser till de andra programmen. Vilken klusterhanterare som helst kan användas så länge som exekutorprocesserna körs och de kommunicerar med varandra.
- Spark förvärvar exekutorer på noder i klustret. Här får varje applikation sina egna exekutorprocesser.
- Applikationskod (jar/python-filer/python-ägg-filer) skickas till exekutorer
- Uppgifter skickas av SparkContext till exekutorerna.
Från ovanstående steg framgår det tydligt att antalet exekutorer och deras minnesinställning spelar en stor roll för ett Spark-arbete. Att köra exekutorer med för mycket minne resulterar ofta i överdrivna garbage collection-fördröjningar
Nu försöker vi förstå, hur man konfigurerar den bästa uppsättningen av värden för att optimera ett spark-jobb.
Det finns två sätt på vilka vi konfigurerar exekutorn och core-detaljerna till Spark-jobbet. De är:
- Statisk allokering – Värdena ges som en del av spark-submit
- Dynamisk allokering – Värdena plockas upp baserat på kravet (datastorlek, mängd beräkningar som behövs) och släpps efter användning. Detta bidrar till att resurserna kan återanvändas för andra tillämpningar.
Statisk allokering
Differenta fall diskuteras genom att variera olika parametrar och komma fram till olika kombinationer beroende på användarens/datakrav.
Fall 1 Hårdvara – 6 noder och varje nod har 16 kärnor, 64 GB RAM
Först på varje nod behövs 1 kärna och 1 GB för operativsystemet och Hadoop Daemons, så vi har 15 kärnor, 63 GB RAM för varje nod
Vi börjar med hur man väljer antal kärnor:
Antal kärnor = samtidiga uppgifter som en exekutor kan köra
Så vi kan tro att fler samtidiga uppgifter för varje exekutor ger bättre prestanda. Men forskningen visar att alla tillämpningar med mer än fem samtidiga uppgifter leder till en dålig prestanda. Så det optimala värdet är 5.
Denna siffra kommer från en utförares förmåga att köra parallella uppgifter och inte från hur många kärnor ett system har. Så siffran 5 förblir densamma även om vi har dubbla (32) kärnor i CPU:
Antal utförare:
När vi kommer till nästa steg, med 5 som kärnor per utförare och 15 som totala tillgängliga kärnor i en nod (CPU) – kommer vi till 3 utförare per nod vilket är 15/5. Vi måste beräkna antalet utförare på varje nod och sedan få fram det totala antalet för jobbet.
Så med 6 noder och 3 utförare per nod får vi totalt 18 utförare. Av de 18 behöver vi 1 exekutor (java-process) för Application Master i YARN. Så det slutliga antalet är 17 exekutorer
Detta 17 är det antal vi ger till spark med hjälp av -num-executors när vi kör från shellkommandot spark-submit
Historia för varje exekutor:
Från ovanstående steg har vi 3 exekutorer per nod. Och tillgängligt RAM-minne på varje nod är 63 GB
Så minnet för varje exekutor i varje nod är 63/3 = 21 GB.
Det behövs dock också ett litet överskottsminne för att bestämma den fullständiga minnesförfrågan till YARN för varje exekutor.
Formeln för denna overhead är max(384, .07 * spark.executor.memory)
Beräkna denna overhead: .07 * 21 (Här beräknas 21 på samma sätt som ovan 63/3) = 1,47
Då 1,47 GB > 384 MB, är overhead 1.47
Tag ovanstående från varje 21 ovan => 21 – 1,47 ~ 19 GB
Så exekutorminne – 19 GB
Finalsiffror – Exekutorer – 17, Kärnor 5, Exekutorminne – 19 GB
Fall 2 Hårdvara – 6 noder och varje nod har 32 Kärnor, 64 GB
Antalet Kärnor 5 är detsamma för god samtidighet som förklaras ovan.
Antal utförare för varje nod = 32/5 ~ 6
Så totalt antal utförare = 6 * 6 noder = 36. Då är det slutliga antalet 36 – 1(för AM) = 35
Minnet för utförare:
6 utförare för varje nod. 63/6 ~ 10. Kostnaden är 0,07 * 10 = 700 MB. Genom att avrunda till 1 GB som overhead får vi 10-1 = 9 GB
Slutsiffror – Exekutor – 35, kärnor 5, exekutorminne – 9 GB
Fall 3 – När mer minne inte krävs för exekutorerna
Ovanstående scenarier börjar med att acceptera antalet kärnor som fast och övergår sedan till antalet exekutorerna och minnet.
Nu för det första fallet, om vi tror att vi inte behöver 19 GB och att det räcker med 10 GB baserat på datastorlek och beräkningar, så är följande siffror:
Kärnor: 5
Antal exekutorer för varje nod = 3. Fortfarande 15/5 enligt beräkningen ovan.
I detta skede skulle detta leda till 21 GB, och sedan 19 enligt vår första beräkning. Men eftersom vi ansåg att 10 är okej (antar lite overhead) kan vi inte ändra antalet utförare per nod till 6 (som 63/10). Med 6 utförare per nod och 5 kärnor blir det 30 kärnor per nod, när vi bara har 16 kärnor. Så vi måste också ändra antalet kärnor för varje exekutor.
Så genom att räkna igen,
Det magiska talet 5 blir 3 (vilket tal som helst som är mindre än eller lika med 5). Så med 3 kärnor och 15 tillgängliga kärnor får vi 5 utförare per nod, 29 utförare (vilket är (5*6 -1)) och minnet är 63/5 ~ 12.
Overhead är 12*.07=.84. Så utförarminnet är 12 – 1 GB = 11 GB
De slutliga siffrorna är 29 utförare, 3 kärnor, utförarminnet är 11 GB
Sammanfattningstabell
Dynamisk allokering
Anmärkningar: Övre gräns för antalet utförare om dynamisk allokering är aktiverad är oändligt. Detta säger alltså att gnistprogrammet kan äta upp alla resurser om det behövs. I ett kluster där vi har andra program som körs och som också behöver kärnor för att utföra uppgifterna måste vi se till att vi tilldelar kärnorna på klusternivå.
Detta innebär att vi kan tilldela ett specifikt antal kärnor för YARN-baserade applikationer baserat på användaråtkomst. Vi kan alltså skapa en spark_user och sedan ge kärnor (min/max) för den användaren. Dessa gränser är till för delning mellan spark och andra program som körs på YARN.
För att förstå dynamisk allokering måste vi ha kunskap om följande egenskaper:
spark.dynamicAllocation.enabled – när detta är satt till true behöver vi inte nämna exekutorer. Anledningen är nedan:
De statiska parameternummer som vi anger vid spark-submit gäller för hela jobbets varaktighet. Men om dynamisk allokering kommer in i bilden skulle det finnas olika steg som följande:
Vad är antalet exekutorer att börja med:
Initialt antal exekutorer (spark.dynamicAllocation.initialExecutors) att börja med
Kontrollera antalet exekutorer dynamiskt:
Därefter baserat på belastning (uppgifter som är väntande) hur många exekutorer som ska begäras. Detta skulle så småningom vara det antal som vi ger i spark-submit på ett statiskt sätt. Så när det ursprungliga antalet utförare har fastställts, går vi till min (spark.dynamicAllocation.minExecutors) och max (spark.dynamicAllocation.maxExecutors) antal.
När ska vi be om nya utförare eller ge bort nuvarande utförare:
När vi begär nya utförare (spark.dynamicAllocation.schedulerBacklogTimeout) – Det betyder att det har funnits väntande uppgifter under så här lång tid. Så begäran om antalet utförare som begärs i varje omgång ökar exponentiellt från föregående omgång. Ett program kommer till exempel att lägga till 1 exekutor i den första omgången och sedan 2, 4, 8 och så vidare exekutorer i de efterföljande omgångarna. Vid en viss punkt kommer ovanstående egenskap max in i bilden.
När vi ger bort en exekutor ställs in med hjälp av spark.dynamicAllocation.executorIdleTimeout.
För att dra en slutsats, om vi behöver mer kontroll över jobbets exekveringstid, övervaka jobbet för oväntad datavolym skulle de statiska siffrorna hjälpa till. Genom att gå över till dynamisk skulle resurserna användas i bakgrunden och jobb med oväntade volymer skulle kunna påverka andra program.