
Det första vi behöver förstå är variablernas karaktär och hur variabler används i en studie för att besvara studiens frågor. I det här kapitlet lär du dig:
- olika typer av variabler i kvantitativa studier,
- frågor kring analysenhetsfrågan.
Förståelse av kvantitativa variabler
Röten till ordet variabel är relaterad till ordet ”variera”, vilket bör hjälpa oss att förstå vad variabler kan vara. Variabler är element, enheter eller faktorer som kan förändras (variera); till exempel är utomhustemperaturen, bensinkostnaden per gallon, en persons vikt och humöret hos personer i din storfamilj alla variabler. De kan med andra ord ha olika värden under olika förhållanden eller för olika personer.
Vi använder variabler för att beskriva egenskaper eller faktorer av intresse. Exempel kan vara antalet medlemmar i olika hushåll, avståndet till hälsosamma livsmedelskällor i olika stadsdelar, förhållandet mellan lärare i socialt arbete och studenter i ett BSW- eller MSW-program, andelen personer från olika ras-/etniska grupper som sitter i fängelse, transportkostnaden för att ta emot tjänster från ett program för socialt arbete eller spädbarnsdödligheten i olika län. I forskning om interventioner inom socialt arbete kan variablerna omfatta egenskaper hos interventionen (intensitet, frekvens, varaktighet) och resultat i samband med interventionen.
Demografiska variabler. Socialarbetare är ofta intresserade av vad vi kallar demografiska variabler. Demografiska variabler används för att beskriva egenskaper hos en population, en grupp eller ett urval av befolkningen. Exempel på ofta använda demografiska variabler är
- ålder,
- etnicitet,
- nationellt ursprung,
- religiös tillhörighet,
- genus,
- sexuell läggning,
- äktenskaplig status/relationsstatus,
- arbetsstatus,
- politisk tillhörighet,
- geografisk plats,
- utbildningsnivå och
- inkomst.
På en mer makroekonomisk nivå omfattar demografin för ett samhälle eller en organisation ofta dess storlek; organisationer mäts ofta i termer av deras totala budget.
Oberoende och beroende variabler. Ett sätt som utredare tänker på studiens variabler har viktiga konsekvenser för studiens utformning. Utredare fattar beslut om att de ska fungera antingen som oberoende variabler eller som beroende variabler. Denna distinktion är inte något som är inneboende i en variabel, utan baseras på hur utredaren väljer att definiera varje variabel. Oberoende variabler är de som man kan tänka sig som manipulerade ”ingångsvariabler”, medan de beroende variablerna är de variabler där effekten eller ”utfallet” av denna ingångsvariation skulle observeras.
Det är inte alltid fråga om avsiktlig manipulering av ”ingångsvariabeln” (den oberoende variabeln). Tänk på exemplet med en studie som genomfördes i Sverige och som undersökte sambandet mellan att ha varit offer för barnmisshandel och senare frånvaro från gymnasiet: ingen manipulerade avsiktligt huruvida barnen skulle bli offer för barnmisshandel (Hagborg, Berglund, & Fahlke, 2017). Forskarna antog att naturligt förekommande skillnader i ingångsvariabeln (barnmisshandelshistoria) skulle vara förknippade med systematisk variation i en specifik utfallsvariabel (skolfrånvaro). I det här fallet var den oberoende variabeln en historia av att vara offer för barnmisshandel, och den beroende variabeln var resultatet av skolfrånvaro. Med andra ord antar utredaren att den oberoende variabeln orsakar variation eller förändring i den beroende variabeln. Så här kan det se ut i ett diagram där ”x” är den oberoende variabeln och ”y” är den beroende variabeln (observera: du såg denna beteckning tidigare, i kapitel 3, när vi diskuterade logik för orsak och verkan):

För ett annat exempel kan man tänka på forskning som tyder på att det är förknippat med en högre risk för substansanvändning under ungdomsåren att vara offer för barnmisshandel (Yoon, Kobulsky, Yoon, & Kim, 2017). Den oberoende variabeln i denna modell skulle vara att ha en historia av barnmisshandel. Den beroende variabeln skulle vara risken för substansanvändning under tonåren. Detta exempel är ännu mer genomarbetat eftersom det specificerar den väg genom vilken den oberoende variabeln (misshandel av barn) kan påföra sina effekter på den beroende variabeln (substansanvändning i tonåren). Författarna till studien visade att posttraumatisk stress (PTS) var en länk mellan barndomsmisshandel (fysisk och sexuell) och substansanvändning under tonåren.

Ta en stund för att slutföra följande aktivitet.
Typer av kvantitativa variabler
Det finns också andra meningsfulla sätt att tänka på variabler av intresse. Låt oss överväga olika egenskaper hos variabler som används i kvantitativa forskningsstudier. Här utforskar vi kvantitativa variabler som är kategoriska, ordinal- eller intervallvariabler. Dessa egenskaper har konsekvenser för både mätning och dataanalys.
Kategoriska variabler. Vissa variabler kan anta värden som varierar, men inte på ett meningsfullt numeriskt sätt. Istället kan de definieras i termer av de kategorier som är möjliga. Logiskt sett kallas dessa för kategoriska variabler. Statistiska programvaror och läroböcker hänvisar ibland till variabler med kategorier som nominella variabler. Nominella variabler kan betraktas utifrån den latinska roten ”nom” som betyder ”namn” och bör inte förväxlas med antal. Nominell betyder samma sak som kategorisk när det gäller att beskriva variabler. Med andra ord identifieras kategoriska eller nominella variabler med namnen eller etiketterna på de representerade kategorierna. Exempelvis skulle färgen på den senaste bilen du åkte i vara en kategorisk variabel: blå, svart, silver, vit, röd, grön, gul eller annan är kategorier av variabeln som vi kan kalla bilfärg.
Vad som är viktigt med kategoriska variabler är att dessa kategorier inte har någon relevant numerisk sekvens eller ordning. Det finns ingen numerisk skillnad mellan de olika bilfärgerna, eller skillnad mellan ”ja” eller ”nej” som kategorier för att svara på om du åkte i en blå bil. Det finns ingen underförstådd ordning eller hierarki för kategorierna ”Hispanic or Latino” och ”Not Hispanic or Latino” i en etnicitetsvariabel, och det finns inte heller någon relevant ordning för kategorier av variabler som kön, delstaten eller den geografiska regionen där en person är bosatt, eller om en persons bostad är ägd eller hyrd.
Om en forskare beslutar sig för att använda siffror som symboler relaterade till kategorierna i en sådan här variabel, så är siffrorna godtyckliga – varje siffra är i princip bara ett annat, kortare namn för varje kategori. Till exempel skulle variabeln kön kunna kodas på följande sätt och det skulle inte göra någon skillnad, så länge koden tillämpades konsekvent.
| Kodningsalternativ A | Variabelkategorier | Kodningsalternativ B |
|---|---|---|
| 1 | man | 2 |
| 2 | kvinna | 1 |
| 3 | annat än man eller kvinna ensam | 4 |
| 4 | föredrar att inte svara | 3 |
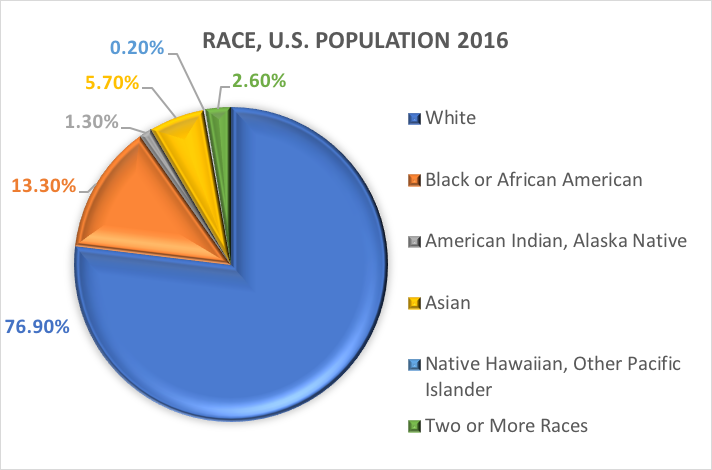
Ras och etnicitet.En av de mest utforskade kategoriska variablerna inom socialt arbete och samhällsvetenskaplig forskning är den demografiska som hänvisar till en persons ras och/eller etniska bakgrund. Många studier använder sig av de kategorier som anges i tidigare rapporter från U.S. Census Bureau. Här är vad U.S. Census Bureau har att säga om de två olika demografiska variablerna ras och etnicitet (https://www.census.gov/mso/www/training/pdf/race-ethnicity-onepager.pdf):
Vad är ras? Census Bureau definierar ras som en persons självidentifikation med en eller flera sociala grupper. En person kan rapportera som vit, svart eller afroamerikan, asiat, indian och Alaska Native, Native Hawaiian and Other Pacific Islander, eller någon annan ras. De som svarar på enkäten kan ange flera olika raser.
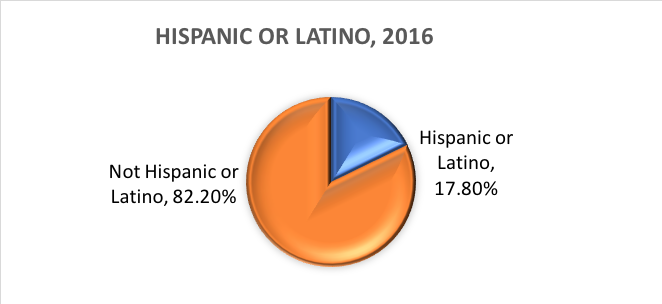
Vad är etnicitet? Etnicitet avgör om en person är av latinamerikanskt ursprung eller inte. Av denna anledning delas etnicitet upp i två kategorier, Hispanic or Latino (latinamerikansk eller latinamerikansk) och Not Hispanic or Latino (ej latinamerikansk eller latinamerikansk). Hispanics kan rapportera som vilken ras som helst.
Med andra ord definierar Census Bureau två kategorier för den variabel som kallas etnicitet (Hispanic or Latino och Not Hispanic or Latino) och sju kategorier för den variabel som kallas ras. Även om dessa variabler och kategorier ofta tillämpas inom samhällsvetenskaplig forskning och socialt arbete är de inte utan kritik.
Baserat på dessa kategorier är det här vad som uppskattas gälla för den amerikanska befolkningen 2016:
Dichotoma variabler: Det finns en särskild kategori kategoriska variabler som har betydelse för vissa statistiska analyser. Kategoriska variabler som består av exakt två alternativ, varken fler eller färre, kallas dikotoma variabler. Ett exempel är U.S. Census Bureau dikotomi av spansktalande/latino- och icke-spansktalande/icke-latino-etnicitet. Ett annat exempel är att utredare kanske vill jämföra personer som fullföljer behandlingen med dem som hoppar av innan de fullföljer behandlingen. Med de två kategorierna, avslutad eller inte avslutad, är denna variabel för avslutad behandling inte bara kategorisk utan också dikotomisk. Variabler där individer svarar ”ja” eller ”nej” är också dikotoma till sin natur.
Den tidigare traditionen att behandla kön som antingen manligt eller kvinnligt är ett annat exempel på en dikotom variabel. Det finns dock mycket starka argument för att inte längre behandla kön på detta dikotoma sätt: en större variation av könsidentiteter är bevisligen relevant i socialt arbete för personer vars identitet inte stämmer överens med de dikotoma (även kallade binära) kategorierna man/kvinna eller man/kvinna. Dessa inkluderar kategorier som agender, androgyn, bigender, cisgender, gender expansive, gender fluid, gender questioning, queer, transgender och andra.
Ordinella variabler. Till skillnad från dessa kategoriska variabler har variabelns kategorier ibland en logisk numerisk sekvens eller ordning. Ordinarie avser per definition en position i en serie. Variabler med numeriskt relevanta kategorier kallas ordinala variabler. Det finns t.ex. en implicit ordning av kategorierna från minst till mest med variabeln utbildningsnivå. USA. Census datakategorier för denna ordinala variabel är:
- ingen
- 1st-4thgrade
- 5th-6thgrade
- 7th-8thgrade
- 9thgrade
- 10thgrade
- 11thgrade
- high school graduate
- some college, ingen examen
- med en examen, occupational
- associate’s degree academic
- bachelor’s degree
- master’s degree
- professional degree
- doctoral degree
Om vi tittar på Census Bureau:s uppskattning av 2016 års uppgifter för denna variabel kan vi se att kvinnorna är fler än männen i kategorin som har en kandidatexamen: Av de 47 718 000 personerna i denna kategori var 22 485 000 män och 25 234 000 kvinnor. Medan detta könsmönster gällde för dem som avlagt magisterexamen, var mönstret omvänt för dem som avlagt doktorsexamen: fler män än kvinnor avlade denna högsta utbildningsnivå. Det är också intressant att notera att kvinnorna var fler än männen i den lägre delen av spektrumet: 441 000 kvinnor rapporterade ingen utbildning jämfört med 374 000 män.
Här är ett annat exempel på användning av ordinalvariabler i forskning om socialt arbete: när personer söker behandling för ett problem med alkoholmissbruk kan socialarbetarna vilja veta om detta är deras första, andra, tredje eller vad som är deras första, andra, tredje eller vad som helst andra seriösa försök att förändra sitt alkoholbeteende. Deltagare som deltog i en studie som jämförde behandlingsmetoder för alkoholmissbruk rapporterade att interventionsstudien var någonstans mellan deras första och elfte betydande förändringsförsök (Begun, Berger, Salm-Ward, 2011). Denna variabel för förändringsförsök har konsekvenser för hur socialarbetare kan tolka data som utvärderar en intervention som inte var det första försöket för alla inblandade.
Bedömningsskalor. Tänk på en annan men vanligt förekommande typ av ordinalvariabel: betygsskalor. Undersökare inom socialt arbete, beteendeforskning och socialt arbete ber ofta studiedeltagarna att använda en betygsskala för att beskriva sina kunskaper, attityder, övertygelser, åsikter, färdigheter eller beteenden. Eftersom kategorierna på en sådan skala är ordnade (mest till minst eller minst till mest) kallar vi dessa för ordinala variabler.

Exempel inkluderar att låta deltagarna betygsätta:
- hur mycket de håller med eller inte håller med om vissa påståenden (inte alls till extremt mycket);
- hur ofta de ägnar sig åt vissa beteenden (aldrig till alltid);
- hur ofta de ägnar sig åt vissa beteenden (timme för timme, dagligen, veckovis, månadsvis, årligen eller mindre ofta);
- kvaliteten på någons prestation (dålig till utmärkt)
- hur nöjda de var med sin behandling (mycket missnöjd till mycket nöjd)
- deras nivå av förtroende (mycket låg till mycket hög).
Intervallvariabler. Ytterligare andra variabler antar värden som varierar på ett meningsfullt numeriskt sätt. Från vår lista över demografiska variabler är ålder ett vanligt exempel. Det numeriska värde som tilldelas en enskild person anger antalet år sedan personen föddes (när det gäller spädbarn kan det numeriska värdet ange dagar, veckor eller månader sedan födseln). Här är de möjliga värdena för variabeln ordnade, liksom ordinala variabler, men en stor skillnad införs: arten av intervallen mellan de möjliga värdena. Med intervallvariabler är ”avståndet” mellan intilliggande möjliga värden lika stort. Vissa statistiska programpaket och läroböcker använder termen skalvariabel: detta är exakt samma sak som det vi kallar en intervallvariabel.
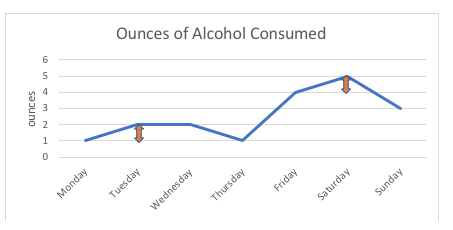
I grafen nedan är t.ex. skillnaden på 1 uns mellan att den här personen konsumerar 1 uns eller 2 uns alkohol (måndag, tisdag) exakt densamma som skillnaden på 1 uns mellan att konsumera 4 uns eller 5 uns (fredag, lördag). Om vi skulle rita de möjliga punkterna på skalan skulle de alla vara lika långt ifrån varandra; intervallet mellan två punkter mäts i standardenheter (ounces, i det här exemplet).
Med ordinala variabler, t.ex. betygsskalor, kan ingen med säkerhet säga att ”avståndet” mellan svarsalternativen ”aldrig” och ”ibland” är detsamma som ”avståndet” mellan ”ibland” och ”ofta”, även om vi använde siffror för att ordna dessa svarsalternativ. Betygsskalan förblir alltså ordinal, inte intervall.
Det som kan bli lite förvirrande är att vissa statistiska program, som SPSS, hänvisar till en intervallvariabel som en ”skalvariabel”. Många variabler som används i forskning om socialt arbete är både ordnade och har lika långa avstånd mellan punkterna. Tänk till exempel på variabeln födelseordning. Denna variabel är en intervallvariabel eftersom:
- de möjliga värdena är ordnade (t.ex. kom det tredje födda barnet efter det förstfödda och det andra födda barnet och före det fjärde födda barnet), och
- ”avstånden” eller intervallen mäts i likvärdiga enheter för en person.
Kontinuerliga variabler. Det finns en speciell typ av numeriska intervallvariabler som vi kallar kontinuerliga variabler. En variabel som ålder kan behandlas som en kontinuerlig variabel. Ålder är ordinal till sin natur, eftersom högre tal betyder något i förhållande till mindre tal. Ålder uppfyller också våra kriterier för att vara en intervallvariabel om vi mäter den i år (eller månader, veckor eller dagar) eftersom den är ordinal och det finns samma ”avstånd” mellan att vara 15 och 30 år gammal som det finns mellan att vara 40 och 55 år gammal (15 kalenderår). Det som gör detta till en kontinuerlig variabel är att det också finns möjliga, meningsfulla ”bråkpunkter” mellan två intervall. En person kan till exempel vara 20½ (20,5) eller 20¼ (20,25) eller 20¾ (20,75) år gammal; vi är inte begränsade till bara hela tal för ålder. När vi däremot tittade på födelseordning kan vi inte ha en meningsfull bråkdel av en person mellan två positioner på skalan.
Det speciella fallet med inkomst. En av de mest missbrukade variablerna inom samhällsvetenskapen och forskningen om socialt arbete är den variabel som har med inkomst att göra. Tänk på ett exempel om hushållsinkomst (oavsett hur många personer som ingår i hushållet). Denna variabel kan vara kategorisk (nominell), ordinal eller intervall (skala) beroende på hur den hanteras.
Kategoriskt exempel: Beroende på forskningsfrågornas karaktär kan en utredare helt enkelt välja att använda de dikotoma kategorierna ”tillräckligt med resurser” och ”otillräckligt med resurser” för att klassificera hushållen, baserat på någon standardberäkningsmetod. Dessa kan kallas ”fattiga” och ”inte fattiga” om en fattigdomsgräns används för att kategorisera hushållen. Dessa olika kategorier av inkomstvariabler är inte meningsfullt ordnade på ett numeriskt sätt, så det är en kategorisk variabel.
Ordinellt exempel: Kategorier för klassificering av hushåll kan vara ordnade från låg till hög. Dessa kategorier för årsinkomst är till exempel vanliga i marknadsundersökningar:
- Mindre än 25 000 dollar.
- 25 000 till 34 999 dollar.
- 35 000 till 49 999 dollar.
- 50 000 till 74 999 dollar.
- 75 000 till 99 999 dollar.
- $100 000 till 149 999 dollar.
- $150 000 till 199 999 dollar.
- $200 000 dollar eller mer.
Bemärk att kategorierna inte är lika stora – ”avståndet” mellan par av kategorier är inte alltid detsamma. De börjar med ett intervall på ungefär 10 000 dollar, övergår till ett intervall på 25 000 dollar och slutar med ett intervall på ungefär 50 000 dollar.
Intervall exempel. Om en undersökare bad studiedeltagarna att rapportera ett faktiskt dollarbelopp för hushållsinkomsten skulle vi se en intervallvariabel. De möjliga värdena är ordnade och intervallet mellan alla möjliga intilliggande enheter är 1 dollar (så länge dollarfraktioner eller cent inte används). En inkomst på 10 452 dollar är alltså samma avstånd på ett kontinuum från 9 452 dollar och 11 452 dollar – 1 000 dollar åt båda hållen.

The Special Case of Age. Liksom inkomst kan ”ålder” betyda olika saker i olika studier. Ålder är vanligtvis en indikator på ”tid sedan födseln”. Vi kan beräkna en persons ålder genom att subtrahera en variabel för födelsedatum från mätdatumet (dagens datum minus födelsedatum). För vuxna mäts åldern vanligtvis i år där intilliggande möjliga värden är distanserade i 1-årsenheter: 18, 19, 20, 21, 22 och så vidare. Åldersvariabeln kan således vara en kontinuerlig typ av intervallvariabel.
En utredare kan emellertid vilja sammanfatta åldersdata i ordnade kategorier eller åldersgrupper. Dessa skulle fortfarande vara ordinala, men kanske inte längre vara intervallvariabler om ökningarna mellan möjliga värden inte är likvärdiga enheter. Om vi till exempel är mer intresserade av ålder som representerar specifika mänskliga utvecklingsperioder, kanske åldersintervallen inte är lika stora i spännvidd mellan ålderskriterierna. Eventuellt kan de vara det:
- Spädbarn (födelse till 18 månader)
- Vagabond (18 månader till 2 ½ år)
- Förskola (2 ½ till 5 år)
- Skolålder (6 till 11 år)
- Ungdom (12 till 17 år)
- Skedeålder (18 till 25 år)
- Mellanstadieålder (26 till 45 år)
- Mellanstadieålder (46 till 60 år)
- Ungdomsålder (26 till 45 år)
- Ungdomsålder (46 till 60 år)
- Old Adulthood (60 till 74 år)
- Middle-Old Adulthood (75 till 84 år)
- Old-Old Adulthood (85 eller fler år)
Ålder kan till och med behandlas som en strikt kategorisk (icke-ordinal) variabel. Till exempel om variabeln av intresse är om någon har laglig ålder för att dricka alkohol (21 år eller äldre) eller inte. Vi har två kategorier – uppfyller eller inte uppfyller kriterierna för laglig ålder för att dricka alkohol i USA – och den ena kategorin kan kodas med ”1” och den andra med antingen ”0” eller ”2” utan någon skillnad i betydelse.
Vad är det ”rätta” svaret på hur man ska mäta ålder (eller inkomst)? Svaret är ”det beror på”. Vad det beror på är forskningsfrågans karaktär: vilken konceptualisering av ålder (eller inkomst) som är mest relevant för den studie som utformas.
Alfanumeriska variabler. Slutligen finns det uppgifter som inte passar in i någon av dessa klassificeringar. Ibland är den information vi känner till i form av en adress eller ett telefonnummer, ett för- eller efternamn, ett postnummer eller andra fraser. Denna typ av information kallas ibland för alfanumeriska variabler. Tänk till exempel på variabeln ”adress”: en persons adress kan bestå av numeriska tecken (husnumret) och bokstavstecken (gatu-, stads- och delstatsnamn), t.ex. 1600 Pennsylvania Ave. NW, Washington, DC, 20500.

I själva verket har vi flera variabler i detta adressexempel:
- gatuadressen: 1600 Pennsylvania Ave.
- staden (och ”delstaten”): Washington, DC
- postnummer: 20500.
Denna typ av information representerar inte specifika kvantitativa kategorier eller värden med systematisk betydelse i uppgifterna. Dessa variabler kallas också ibland för ”strängvariabler” i vissa programvarupaket eftersom de består av en sträng av symboler. För att vara användbar för en undersökare måste en sådan variabel omvandlas eller kodas om till meningsfulla värden.
En anmärkning om analysenhet
En viktig sak att tänka på när man tänker på variabler är att data kan samlas in på många olika observationsnivåer. De element som studeras kan vara enskilda celler, organsystem eller personer. Eller så kan observationsnivån vara par av individer, t.ex. par, bröder och systrar eller föräldra-barn-dyader. I detta fall kan undersökaren samla in information om paret från varje individ, men tittar på varje pars data. Vi skulle alltså säga att analysenheten är paret eller dyaden, inte varje enskild person. Analysenheten kan också vara en större grupp: till exempel kan uppgifter samlas in från varje elev i hela klassrum där analysenheten är klassrummen i en skola eller ett skolsystem. Eller så kan analysenheten vara på grannskapsnivå, program, organisationer, län, stater eller till och med nationer. Många av de variabler som används som indikatorer på livsmedelstrygghet på samhällsnivå, till exempel överkomlighet och tillgänglighet, bygger till exempel på uppgifter som samlas in från enskilda hushåll (Kaiser, 2017). Analysenheten i studier som använder dessa indikatorer skulle vara de samhällen som jämförs. Denna distinktion har viktiga konsekvenser för mätning och dataanalys.
En påminnelse om variabler kontra variabelnivåer
En studie kan beskrivas i termer av antalet variabla kategorier, eller nivåer, som jämförs. Du kan till exempel se en studie som beskrivs som en 2 X 2-design – uttalat som en två gånger två-design. Det betyder att det finns två möjliga kategorier för den första variabeln och två möjliga kategorier för den andra variabeln – båda är dikotoma variabler. En studie som jämför 2 kategorier av variabeln ”alkoholmissbruk” (kategorier för uppfyller kriterierna, ja eller nej) med 2 kategorier av variabeln ”missbruk av illegala substanser” (kategorier för uppfyller kriterierna, ja eller nej) skulle ha 4 möjliga utfall (matematiskt sett skulle 2 x 2=4) och skulle kunna schemaläggas på följande sätt (uppgifter baserade på proportioner från NSDUH-undersökningen från 2016, presenterade i SAMHSA, 2017):
| Syndrom vid användning av illegala substanser (SUD) | |||
|---|---|---|---|
|
Syndrom vid användning av alkohol (AUD) |
Nej | Ja | |
| Nej | 500 | 10 | |
| Ja | 26 | 4 | |
Läsning av de fyra cellerna i denna 2 X 2 tabell berättar att i denna (hypotetiska) undersökning av 540 individer, 500 inte uppfyllde kriterierna för en alkohol- eller drogmissbrukssyndrom (Nej, Nej); 26 uppfyllde kriterierna för enbart alkohol (Ja, Nej), 10 uppfyllde kriterierna för enbart illegala substanser (Nej, Ja) och 4 uppfyllde kriterierna för både alkohol och illegala substanser (Ja, Ja). Med lite matematik kan vi dessutom se att totalt 30 personer hade en alkoholmissbrukssyndrom (26 + 4) och 14 personer hade ett missbruk av illegala substanser (10 + 4). Och vi kan se att 40 hade någon form av substansanvändningsstörning (26 + 10 + 4).
 För att göra denna distinktion mellan variabler och variabla nivåer eller kategorier kristallklar, låt oss betrakta ytterligare ett exempel: en 2 X 3-studieplan. Om vi först räknar på det, bör vi se 6 möjliga utfall (celler). För det andra vet vi att den första variabeln (åldersgrupp) har 2 kategorier (under 30 år, 30 år eller äldre) och att den andra variabeln (sysselsättningsstatus) har 3 kategorier (fullt sysselsatt, delvis sysselsatt, arbetslös). Den här gången är de 6 cellerna i vår design tomma eftersom vi väntar på uppgifterna.
För att göra denna distinktion mellan variabler och variabla nivåer eller kategorier kristallklar, låt oss betrakta ytterligare ett exempel: en 2 X 3-studieplan. Om vi först räknar på det, bör vi se 6 möjliga utfall (celler). För det andra vet vi att den första variabeln (åldersgrupp) har 2 kategorier (under 30 år, 30 år eller äldre) och att den andra variabeln (sysselsättningsstatus) har 3 kategorier (fullt sysselsatt, delvis sysselsatt, arbetslös). Den här gången är de 6 cellerna i vår design tomma eftersom vi väntar på uppgifterna.
| Arbetslöshetsstatus | |||||
|---|---|---|---|---|---|
|
Åldersgrupp |
Fullständigt anställd | Delvis anställd. | Arbetslös | Arbetslös | |
| <30 | |||||
| ≥30 | |||||
Då, När du ser en beskrivning av studiedesignen som ser ut som två tal som multipliceras, är det i huvudsak en uppgift om hur många kategorier eller nivåer av varje variabel det finns och leder till att du förstår hur många celler eller möjliga resultat som finns. En 3 X 3-design har 9 celler, en 3 X 4-design har 12 celler och så vidare. Denna fråga blir viktig igen när vi diskuterar urvalsstorlek i kapitel 6.
Förklara följande arbetsboksaktivitet:
- SWK 3401.3-4.1 Begynnande datainmatning
Kapitelsammanfattning
Sammanfattningsvis utformar utredare många av sina kvantitativa studier för att testa hypoteser om sambanden mellan variabler. Att förstå karaktären på de inblandade variablerna hjälper till att förstå och utvärdera den utförda forskningen. Att förstå skillnaderna mellan olika typer av variabler, liksom mellan variabler och kategorier, har viktiga konsekvenser för studiedesign, mätning och urval. I nästa kapitel utforskas bland annat skärningspunkten mellan karaktären på de variabler som studeras i kvantitativ forskning och hur utredare går tillväga för att mäta dessa variabler.
Ta en stund för att genomföra följande aktivitet.