
- Uma rápida caminhada dos melhores artigos para classificação de imagens em uma década para começar o seu aprendizado de visão por computador
- 1998: LeNet
- 2012: AlexNet
- 2014: VGG
- 2014: GoogLeNet
- 2015: Batch Normalization
- 2015: ResNet
- 2016: Xception
- 2017: MobileNet
- 2017: NASNet
- 2019: EfficientNet
- 2014: SPPNet
- 2016: DenseNet
- 2017: SENet
- 2017: ShuffleNet
- 2018: Bag of Tricks
- Conclusion
Uma rápida caminhada dos melhores artigos para classificação de imagens em uma década para começar o seu aprendizado de visão por computador

Visão por computador é um assunto para converter imagens e vídeos em máquina-sinais compreensíveis. Com estes sinais, os programadores podem controlar ainda mais o comportamento da máquina com base neste entendimento de alto nível. Entre muitas tarefas de visão por computador, a classificação da imagem é uma das mais fundamentais. Ela não só pode ser usada em muitos produtos reais como a marcação do Google Photo e a moderação do conteúdo de IA, mas também abre uma porta para muitas tarefas de visão mais avançadas, como a detecção de objetos e a compreensão de vídeo. Devido às rápidas mudanças neste campo desde a descoberta do Deep Learning, os principiantes muitas vezes acham que é demasiado avassalador para aprender. Ao contrário das disciplinas típicas de engenharia de software, não existem muitos livros excelentes sobre classificação de imagens usando DCNN, e a melhor maneira de entender este campo é através da leitura de trabalhos acadêmicos. Mas que trabalhos a ler? Por onde eu começo? Neste artigo, vou apresentar 10 melhores trabalhos para os iniciantes lerem. Com estes artigos, podemos ver como este campo evolui, e como os pesquisadores levantaram novas idéias com base em resultados de pesquisas anteriores. No entanto, ainda assim, é útil para você resolver o quadro geral, mesmo que você já tenha trabalhado nesta área por algum tempo. Então, vamos começar.
1998: LeNet
>
Aprendizagem Aplicada ao Reconhecimento de Documentos com Base em Grade
>

Introduzido em 1998, A LeNet estabelece uma base para futuras pesquisas de classificação de imagens usando a Convolution Neural Network. Muitas técnicas clássicas da CNN, tais como camadas de pooling, camadas totalmente conectadas, acolchoamento e camadas de ativação são usadas para extrair recursos e fazer uma classificação. Com uma função de perda de erro quadrado médio e 20 épocas de treinamento, esta rede pode alcançar uma precisão de 99,05% no conjunto de testes MNIST. Mesmo depois de 20 anos, muitas redes de classificação de última geração ainda seguem este padrão em geral.
2012: AlexNet
>
Classificação da ImageNet com Redes Neurais Convolucionais Profundas

>
>
>
Embora LeNet tenha alcançado um grande resultado e mostrado o potencial da CNN, o desenvolvimento nesta área estagnou durante uma década devido ao limitado poder computacional e à quantidade de dados. Parecia que a CNN só podia resolver algumas tarefas fáceis como o reconhecimento de dígitos, mas para recursos mais complexos como rostos e objetos, um extrator de recursos HarrCascade ou SIFT com um classificador SVM era uma abordagem mais preferida.
No entanto, em 2012, no Desafio de Reconhecimento Visual em Grande Escala ImageNet, Alex Krizhevsky propôs uma solução baseada na CNN para este desafio e aumentou drasticamente a precisão do conjunto de testes ImageNet top-5 de 73,8% para 84,7%. Sua abordagem herda a idéia de multicamadas da CNN da LeNet, mas aumentou muito o tamanho da CNN. Como você pode ver no diagrama acima, a entrada agora é 224×224 em comparação com os 32×32 da LeNet, também muitos kernels Convolution têm 192 canais em comparação com os 6 da LeNet. Embora o design não seja muito alterado, com centenas de vezes mais parâmetros, a capacidade da rede de capturar e representar recursos complexos melhorou centenas de vezes também. Para treinar como um modelo grande, Alex usou duas GPUs GTX 580 com 3GB de RAM para cada uma, o que foi pioneiro em uma tendência de treinamento de GPU. Além disso, o uso da não-linearidade ReLU também ajudou a reduzir o custo de computação.
Além de trazer muito mais parâmetros para a rede, ele também explorou o problema de sobreajuste trazido por uma rede maior usando uma camada de Dropout. Seu método de normalização de resposta local não ganhou muita popularidade depois, mas inspirou outras técnicas de normalização importantes, como o BatchNorm, para combater o problema de saturação de gradiente. Para resumir, AlexNet definiu a estrutura de classificação de facto de rede para os próximos 10 anos: uma combinação de Convolution, ReLu activação não linear, MaxPooling, e Dense layer.
2014: VGG
>
Muitas Redes Convolucionais Profundas para Grandes…Escala de Reconhecimento de Imagem
Com tão grande sucesso no uso da CNN para reconhecimento visual, toda a comunidade de pesquisa explodiu e todos começaram a investigar porque é que esta rede neural funciona tão bem. Por exemplo, em “Visualizando e Entendendo Redes Convolucionais”, a partir de 2013, Matthew Zeiler discutiu como a CNN captou as características e visualizou as representações intermediárias. E de repente todos começaram a perceber que a CNN é o futuro da visão computacional desde 2014. Entre todos esses seguidores imediatos, a rede VGG do Visual Geometry Group é a que mais chama a atenção. Ela obteve um resultado notável de 93,2% de precisão top-5, e 76,3% de precisão top-1 no conjunto de testes da ImageNet.
Seguindo o design da AlexNet, a rede VGG tem duas grandes atualizações: 1) A VGG não só usou uma rede mais ampla como a AlexNet, mas também mais profunda. A VGG-19 tem 19 camadas de convolução, comparada com 5 da AlexNet. 2) O VGG também demonstrou que alguns pequenos filtros de convolução 3×3 podem substituir um único filtro 7×7 ou mesmo 11×11 da AlexNet, alcançando melhor desempenho enquanto reduz o custo de computação. Devido a este design elegante, VGG também se tornou a rede back-bone de muitas redes pioneiras em outras tarefas de visão computacional, como FCN para segmentação semântica, e Faster R-CNN para detecção de objetos.
Com uma rede mais profunda, o desaparecimento do gradiente da retropropagação de multicamadas se torna um problema maior. Para lidar com isso, VGG também discutiu a importância do pré-treinamento e inicialização de peso. Este problema limita os pesquisadores a continuar adicionando mais camadas, caso contrário, a rede será realmente difícil de convergir. Mas veremos uma solução melhor para isso após dois anos.
2014: GoogLeNet
>
Ir mais fundo com convoluções

>>
>
VGG tem uma estrutura de boa aparência e fácil de entender, mas o seu desempenho não é o melhor entre todos os finalistas das competições da ImageNet 2014. O GoogLeNet, também conhecido como InceptionV1, ganhou o prémio final. Tal como a VGG, uma das principais contribuições da GoogLeNet é aumentar o limite da profundidade da rede com uma estrutura de 22 camadas. Isto demonstrou novamente que ir mais fundo e mais longe é de facto a direcção certa para melhorar a precisão.
Não parecido com o VGG, GoogLeNet tentou abordar de frente os problemas de computação e de diminuição de gradiente, em vez de propor uma solução com um melhor esquema pré-treinado e inicialização de pesos.

Primeiro, explorou a ideia de desenho assimétrico de rede usando um módulo chamado Inception (ver diagrama acima). Idealmente, eles gostariam de perseguir convoluções esparsas ou camadas densas para melhorar a eficiência dos recursos, mas o design de hardware moderno não foi feito sob medida para este caso. Assim, eles acreditavam que uma esparsidade no nível de topologia de rede também poderia ajudar na fusão de recursos, ao mesmo tempo em que alavanca os recursos de hardware existentes.
Segundo, ele ataca o problema do alto custo de computação ao tomar emprestada uma idéia de um artigo chamado “Rede em Rede”. Basicamente, um filtro de convolução 1×1 é introduzido para reduzir as dimensões das funcionalidades antes de passar por uma operação de computação pesada como um kernel de convolução 5×5. Esta estrutura é chamada de “Bottleneck” mais tarde e amplamente utilizada em muitas redes seguintes. Similar a “Network in Network”, ela também usou uma camada média de pooling para substituir a camada final totalmente conectada para reduzir ainda mais o custo.
Terceiro, para ajudar gradientes a fluir para camadas mais profundas, o GoogLeNet também usou supervisão em algumas saídas de camadas intermediárias ou saídas auxiliares. Este design não é muito popular mais tarde na rede de classificação de imagens devido à complexidade, mas tornando-se mais popular em outras áreas da visão por computador, como a rede Hourglass em estimativa de pose.
Como seguimento, esta equipa do Google escreveu mais artigos para esta série Inception. “Batch Normalization”: Accelerating Deep Network Training by Reducing Internal Covariate Shift” significa InceptionV2. “Rethinking the Inception Architecture for Computer Vision” em 2015 significa InceptionV3. E “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning” em 2015 significa InceptionV4. Cada artigo adicionou mais melhorias em relação à rede Inception original e alcançou um resultado melhor.
2015: Batch Normalization
Batch Normalization: Acelerando o Treinamento Profundo da Rede através da Redução do Deslocamento Covariável Interno
A rede Inception ajudou os pesquisadores a alcançar uma precisão sobre-humana no conjunto de dados da ImageNet. Entretanto, como um método de aprendizado estatístico, a CNN está muito restrita à natureza estatística de um conjunto de dados de treinamento específico. Portanto, para alcançar uma melhor precisão, geralmente precisamos pré-calcular a média e o desvio padrão de todo o conjunto de dados e usá-los para normalizar nossas entradas primeiro para garantir que a maioria das entradas da camada na rede estejam próximas, o que se traduz em uma melhor reatividade de ativação. Esta abordagem aproximada é muito complicada e, por vezes, não funciona de todo para uma nova estrutura de rede ou um novo conjunto de dados, pelo que o modelo de aprendizagem profunda ainda é visto como difícil de treinar. Para resolver este problema, Sergey Ioffe e Chritian Szegedy, o cara que criou a GoogLeNet, decidiram inventar algo mais inteligente chamado Batch Normalization.
A ideia de normalização de lotes não é difícil: Podemos usar as estatísticas de uma série de mini-lotes para aproximar as estatísticas de todo o conjunto de dados, desde que treinemos por tempo suficiente. Além disso, ao invés de calcular manualmente as estatísticas, podemos introduzir mais dois parâmetros de aprendizagem “escala” e “shift” para que a rede aprenda como normalizar cada camada por si só.
O diagrama acima mostrou o processo de cálculo dos valores de normalização dos lotes. Como podemos ver, pegamos a média de todo o mini-batch e calculamos a variância também. A seguir, podemos normalizar a entrada com esta média e variância do mini-lote. Finalmente, com uma escala e um parâmetro de deslocamento, a rede aprenderá a adaptar o resultado normalizado do lote para melhor se ajustar às seguintes camadas, geralmente ReLU. Uma ressalva é que não temos informações de mini-lotes durante a inferência, então uma alternativa é calcular uma média móvel e uma variância durante o treinamento, e então usar essas médias móveis no caminho de inferência. Esta pequena inovação é tão impactante, e todas as redes posteriores começam a usá-la imediatamente.
2015: ResNet
Deep Residual Learning for Image Recognition
2015 pode ser o melhor ano para a visão por computador em uma década, temos visto tantas grandes idéias surgindo não só na classificação de imagens, mas todos os tipos de tarefas de visão por computador, tais como detecção de objetos, segmentação semântica, etc. O maior avanço do ano de 2015 pertence a uma nova rede chamada ResNet, ou redes residuais, proposta por um grupo de pesquisadores chineses da Microsoft Research Asia.

Como discutimos anteriormente para a rede VGG, o maior obstáculo para se aprofundar ainda mais é a questão do desaparecimento do gradiente, i.e, as derivadas se tornam cada vez menores quando retropropagam através de camadas mais profundas, e eventualmente chegam a um ponto que a arquitetura moderna de computadores não pode realmente representar de forma significativa. GoogLeNet tentou atacar isso usando supervisão auxiliar e módulo de início assimétrico, mas isso só alivia o problema em uma pequena medida. Se quisermos usar 50 ou mesmo 100 camadas, haverá uma forma melhor de o gradiente fluir através da rede? A resposta da ResNet é usar um módulo residual.

ResNet adicionou um atalho de identidade à saída, de modo que cada módulo residual não pode pelo menos prever o que quer que seja a entrada, sem se perder na natureza. Ainda mais importante é que, ao invés de esperar que cada camada se ajuste diretamente ao mapeamento de características desejado, o módulo residual tenta aprender a diferença entre saída e entrada, o que torna a tarefa muito mais fácil, pois o ganho de informação necessária é menor. Imagine que você está aprendendo matemática, para cada novo problema, você recebe uma solução de um problema similar, então tudo o que você precisa fazer é estender esta solução e tentar fazer com que ela funcione. Isto é muito mais fácil do que pensar numa solução completamente nova para cada problema com que se depara. Ou como Newton disse, nós podemos ficar nos ombros de gigantes, e a entrada de identidade é aquele gigante para o módulo residual.
Além do mapeamento de identidade, a ResNet também pegou emprestado o gargalo de gargalo e a normalização de lotes das redes Inception. Eventualmente, ele conseguiu construir uma rede com 152 camadas de convolução e alcançou 80,72% de precisão top-1 no ImageNet. A abordagem residual também se torna uma opção padrão para muitas outras redes posteriormente, como Xception, Darknet, etc. Além disso, graças ao seu design simples e bonito, ele ainda é amplamente utilizado em muitos sistemas de reconhecimento visual de produção atualmente.
Existem muitos mais invariantes que saíram seguindo o hype da rede residual. Em “Identity Mappings in Deep Residual Networks”, o autor original da ResNet tentou colocar a ativação antes do módulo residual e conseguiu um resultado melhor, e este design é chamado ResNetV2 depois. Também, em um trabalho de 2016 “Transformações Residuais Agregadas para Redes Neurais Profundas”, os pesquisadores propuseram o ResNeXt que adicionou ramos paralelos para módulos residuais para agregar saídas de diferentes transformações.
2016: Xception
Xception: Aprendizagem Profunda com Convoluções Separáveis em Profundidade

Com o lançamento do ResNet, parecia que a maioria dos frutos pendentes baixos no classificador de imagem já estavam agarrados. Os pesquisadores começaram a pensar sobre qual é o mecanismo interno da magia da CNN. Como a convolução entre canais geralmente introduz uma tonelada de parâmetros, a rede Xception optou por investigar esta operação para entender um quadro completo do seu efeito.
Como seu nome, Xception tem origem na rede Inception. No módulo Inception, múltiplas ramificações de diferentes transformações são agregadas para alcançar uma esparsidade topológica. Mas por que essa esparsidade funcionou? O autor de Xception, também o autor do framework Keras, estendeu esta idéia para um caso extremo onde um arquivo de convolução 3×3 corresponde a um canal de saída antes de uma concatenação final. Neste caso, estes kernels de convolução paralela formam na verdade uma nova operação chamada convolução profunda.

As shown in the diagram above, Ao contrário da convolução tradicional onde todos os canais são incluídos para um cálculo, a convolução em profundidade computa apenas a convolução para cada canal separadamente e depois concatenam a saída em conjunto. Isso corta a troca de características entre canais, mas também reduz muitas conexões, resultando em uma camada com menos parâmetros. No entanto, esta operação irá produzir o mesmo número de canais como entrada (ou um número menor de canais se você agrupar dois ou mais canais em conjunto). Portanto, uma vez que os canais de saída são fundidos, precisamos de outro filtro regular 1×1, ou convolução pontual, para aumentar ou reduzir o número de canais, assim como a convolução regular faz.
Esta idéia não é do Xception originalmente. Ela é descrita em um artigo chamado “Aprendendo representações visuais em escala” e também usada ocasionalmente no InceptionV2. Xception deu um passo adiante e substituiu quase todas as convoluções por este novo tipo. E o resultado da experiência revelou-se bastante bom. Ele supera a ResNet e InceptionV3 e se tornou um novo método SOTA para classificação de imagens. Isto também provou que o mapeamento de correlações entre canais e correlações espaciais na CNN pode ser totalmente desacoplado. Além disso, compartilhando a mesma virtude com a ResNet, o Xception também tem um design simples e bonito, por isso sua idéia é usada em muitas outras pesquisas seguintes, como MobileNet, DeepLabV3, etc.
2017: MobileNet
>
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
>
Xception alcançou 79% de precisão top-1 e 94,5% de precisão top-5 no ImageNet, mas isso é apenas 0,8% e 0,4% de melhoria, respectivamente, em comparação com o SOTA InceptionV3 anterior. O ganho marginal de uma nova rede de classificação de imagens está se tornando menor, portanto os pesquisadores começam a mudar seu foco para outras áreas. E a MobileNet liderou um impulso significativo da classificação de imagens em um ambiente com restrições de recursos.

Similiar ao Xception, MobileNet usou o mesmo módulo de convolução separável em profundidade como mostrado acima e teve uma ênfase na alta eficiência e menos parâmetros.
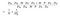
O numerador na fórmula acima é o número total de parâmetros requeridos por uma convolução separável em profundidade. E o denominador é o número total de parâmetros de uma convolução regular semelhante. Aqui D é o tamanho do kernel de convolução, D é o tamanho do mapa de características, M é o número de canais de entrada, N é o número de canais de saída. Como nós separamos o cálculo de canal e característica espacial, podemos transformar a multiplicação em uma adição, que é uma magnitude menor. Melhor ainda, como podemos ver por esta razão, quanto maior for o número de canais de saída, mais cálculo poupamos ao usar esta nova convolução.
Uma outra contribuição da MobileNet é o multiplicador de largura e resolução. A equipe da MobileNet queria encontrar uma forma canônica de diminuir o tamanho do modelo para dispositivos móveis, e a forma mais intuitiva é reduzir o número de canais de entrada e saída, assim como a resolução da imagem de entrada. Para controlar esse comportamento, uma relação alfa é multiplicada pelos canais, e uma relação rho é multiplicada pela resolução de entrada (que também afeta o tamanho do mapa de características). Assim, o número total de parâmetros pode ser representado na seguinte fórmula:

Embora essa mudança pareça ingênua em termos de inovação, ela tem grande valor de engenharia, pois é a primeira vez que os pesquisadores concluem uma abordagem canônica para ajustar a rede a diferentes restrições de recursos. Além disso, ela meio que resumiu a solução final de melhorar a rede neural: entrada mais ampla e de alta resolução leva a uma melhor precisão, entrada mais fina e de baixa resolução leva a uma menor precisão.
Later em 2018 e 2019, a equipe da MobiletNet também lançou “MobileNetV2″: Inverted Residuals and Linear Bottlenecks” e “Searching for MobileNetV3”. Na MobileNetV2, é utilizada uma estrutura de gargalo residual invertido. E na MobileNetV3, ela começou a procurar a combinação ideal de arquitetura usando a tecnologia de Busca de Arquitetura Neural, que iremos cobrir a seguir.
2017: NASNet
>
Aprendizagem de Arquitecturas Transferíveis para o Reconhecimento de Imagens Escaláveis
Apenas como a classificação de imagens para um ambiente com recursos limitados, a pesquisa da arquitectura neural é outro campo que surgiu por volta de 2017. Com ResNet, Inception e Xception, parece que alcançamos uma topologia de rede ideal que os humanos podem entender e projetar, mas e se houver uma combinação melhor e muito mais complexa que exceda de longe a imaginação humana? Um artigo em 2016 chamado “Neural Architecture Search with Reinforcement Learning” propôs uma idéia para buscar a combinação ideal dentro de um espaço de busca pré-definido, utilizando a aprendizagem de reforço. Como sabemos, a aprendizagem de reforço é um método para encontrar a melhor solução com um objetivo claro e uma recompensa para o agente de busca. Entretanto, limitado pelo poder computacional, este artigo discutiu a aplicação apenas em um pequeno conjunto de dados CIFAR.

Com o objetivo de encontrar uma estrutura ideal para um grande conjunto de dados como ImageNet, a NASNet fez um espaço de busca que é feito sob medida para ImageNet. Ele espera projetar um espaço de busca especial para que o resultado pesquisado no CIFAR também possa funcionar bem na ImageNet. Primeiro, a NASNet assume que um módulo artesanal comum em boas redes como a ResNet e a Xception ainda são úteis ao pesquisar. Assim, em vez de procurar por conexões e operações aleatórias, a NASNet procura a combinação desses módulos que já provaram ser úteis na ImageNet. Em segundo lugar, a busca real ainda é realizada no conjunto de dados CIFAR com resolução 32×32, portanto a NASNet só busca módulos que não são afetados pelo tamanho da entrada. A fim de fazer o segundo ponto funcionar, o NASNet predefiniu dois tipos de modelos de módulos: Redução e Normal. A célula de redução poderia ter um mapa de características reduzido em comparação com a entrada, e para a célula Normal seria a mesma.
Embora o NASNet tenha melhores métricas do que redes de desenho manual, ele também sofre de alguns inconvenientes. O custo da busca por uma estrutura ideal é muito alto, o que só é acessível por grandes empresas como Google e Facebook. Além disso, a estrutura final não faz muito sentido para os humanos, por isso é mais difícil de manter e melhorar em um ambiente de produção. Mais tarde, em 2018, “MnasNet: Platform-Aware Neural Architecture Search for Mobile” estende ainda mais esta ideia da NASNet, limitando a etapa de pesquisa com uma estrutura de blocos encadeados pré-definida. Além disso, ao definir um fator de peso, a mNASNet deu uma maneira mais sistemática de pesquisar o modelo com restrições específicas de recursos, ao invés de apenas avaliar com base em FLOPs.
2019: EfficientNet
EfficientNet: Repensando a escala do modelo para Redes Neurais Convolucionais
Em 2019, parece que não há mais idéias emocionantes para a classificação supervisionada de imagens com a CNN. Uma mudança drástica na estrutura da rede geralmente oferece apenas uma pequena melhoria na precisão. Pior ainda, quando a mesma rede se aplicava a diferentes conjuntos de dados e tarefas, os truques anteriormente reivindicados não parecem funcionar, o que levou a críticas de que se essas melhorias estão apenas se ajustando em excesso no conjunto de dados da ImageNet. Por outro lado, há um truque que nunca falha a nossa expectativa: usar uma entrada de maior resolução, adicionar mais canais para camadas de convolução, e adicionar mais camadas. Apesar da força muito brutal, parece que existe uma forma de princípio para dimensionar a rede sob demanda. A MobileNetV1 sugeriu isso em 2017, mas o foco foi mudado para um melhor design de rede mais tarde.

Após NASNet e mNASNet, os pesquisadores perceberam que mesmo com a ajuda de um computador, uma mudança na arquitetura não traz tantos benefícios. Assim, eles começam a cair de novo na escala da rede. A EfficientNet é apenas construída sobre esta suposição. Por um lado, ela usa o bloco de construção ideal da mNASNet para garantir uma boa base para começar. Por outro lado, ele definiu três parâmetros alfa, beta e rho para controlar a profundidade, largura e resolução da rede de forma correspondente. Ao fazer isso, mesmo sem um grande pool de GPUs para procurar uma estrutura ideal, os engenheiros ainda podem confiar nesses parâmetros de princípio para sintonizar a rede com base em seus diferentes requisitos. No final, a EfficientNet deu 8 variantes diferentes com diferentes rácios de largura, profundidade e resolução e obteve um bom desempenho tanto para modelos pequenos como grandes. Em outras palavras, se você deseja alta precisão, opte por um EfficientNet-B7 de 600×600 e 66M de parâmetros. Se você quer modelos de baixa latência e modelos menores, opte por um EfficientNet-B0 de 224×224 e 5,3M. Problema resolvido.
Se você terminar de ler acima de 10 trabalhos, você deve ter uma boa compreensão do histórico de classificação de imagens com CNN. Se você gosta de continuar aprendendo esta área, eu também listei alguns outros artigos interessantes para ler. Embora não estejam incluídos na lista dos top-10, estes trabalhos são todos famosos na sua própria área e inspiraram muitos outros pesquisadores no mundo.
2014: SPPNet
>
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPPNet toma emprestada a idéia da pirâmide de recursos da tradicional extração de recursos de visão por computador. Esta pirâmide forma um saco de palavras de características com escalas diferentes, de modo que ela pode se adaptar a diferentes tamanhos de entrada e se livrar da camada de tamanho fixo totalmente conectado. Esta idéia também inspirou o módulo ASPP do DeepLab, e também a FPN para detecção de objetos.
2016: DenseNet
>
Densely Connected Convolutional Networks
>
DenseNet from Cornell estende ainda mais a ideia da ResNet. Ela não só permite saltar a conexão entre camadas, mas também tem saltar conexões de todas as camadas anteriores.
2017: SENet
>
Rede de compressão e excitação
A rede Xception demonstrou que a correlação entre canais não tem muito a ver com a correlação espacial. No entanto, como campeão da última competição da ImageNet, SENet desenvolveu um bloco Squeeze-and-Excitation e contou uma história diferente. O bloco SE primeiro aperta todos os canais em menos canais usando o pooling global, aplica uma transformação totalmente conectada, e depois os “excita” de volta ao número original de canais usando outra camada totalmente conectada. Assim, essencialmente, a camada FC ajudou a rede a aprender atenções no mapa de características de entrada.
2017: ShuffleNet
ShuffleNet: Uma Rede Neural Convolucional Extremamente Eficiente para Dispositivos Móveis
Built on top of MobileNetV2’s inverted bottleneck module, ShuffleNet acredita que a convolução pontual em convolução separável em profundidade sacrifica a precisão em troca de menos computação. Para compensar isso, a ShuffleNet adicionou uma operação adicional de embaralhamento de canais para garantir que a convolução no sentido horário não será sempre aplicada ao mesmo “ponto”. E no ShuffleNetV2, esse mecanismo de embaralhamento de canais também é estendido para um ramo de mapeamento de identidade ResNet, de modo que parte do recurso de identidade também será usado para embaralhar.
2018: Bag of Tricks
Bag of Tricks for Image Classification with Convolutional Neural Networks
Bag of Tricks foca em truques comuns usados na área de classificação de imagens. Ele serve como uma boa referência para os engenheiros quando eles precisam melhorar o desempenho do benchmark. Curiosamente, esses truques como o aumento de mixup e taxa de aprendizagem cosseno podem, às vezes, alcançar melhorias muito melhores do que uma nova arquitetura de rede.
Conclusion
Com o lançamento da EfficientNet, parece que o benchmark de classificação da ImageNet chega ao fim. Com a abordagem de aprendizagem profunda existente, nunca haverá um dia em que possamos alcançar 99,999% de precisão na ImageNet, a menos que outra mudança de paradigma aconteça. Assim, os pesquisadores estão olhando ativamente para algumas áreas novas, como a aprendizagem auto ou semi-supervisionada para reconhecimento visual em larga escala. Entretanto, com os métodos existentes, tornou-se mais uma questão para engenheiros e empresários encontrarem a aplicação real desta tecnologia não-perfeita. No futuro, também vou escrever uma pesquisa para analisar essas aplicações de visão do mundo real por computador alimentadas por classificação de imagens, por isso, por favor, fique atento! Se você acha que também há outros trabalhos importantes para ler para classificação de imagens, por favor deixe um comentário abaixo e nos informe.
Publicado originalmente em http://yanjia.li em 31 de julho de 2020
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based Learning Applied to Document Recognition
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
- Sergey Ioffe, Christian Szegedy, Batch Normalization: Acelerando o Treinamento Profundo de Rede Reduzindo o Deslocamento Covariável Interno
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Aprendizagem Residual Profunda para Reconhecimento de Imagens
- François Chollet, Xception: Aprendizagem Profunda com Convoluções Separadas em Profundidade
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
- Mingxing Tan, Quoc V. Le, EfficientNet: Repensando a Escala de Modelos para Redes Neurais Convolucionais
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Convolutional Networks
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet: Uma Rede Neural Convolucional Extremamente Eficiente para Dispositivos Móveis
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Saco de Truques para Classificação de Imagens com Redes Neurais Convolucionais