
Alocação de recursos é um aspecto importante durante a execução de qualquer trabalho de spark. Se não for configurado corretamente, um spark job pode consumir recursos de cluster inteiros e fazer outras aplicações passarem fome de recursos.
Este blog ajuda a entender o fluxo básico em uma aplicação Spark e então como configurar o número de executores, configurações de memória de cada executor e o número de núcleos para um Spark Job. Há alguns fatores que precisamos considerar para decidir os números ótimos para os três acima, como por exemplo:
- A quantidade de dados
- O tempo em que um trabalho tem que completar
- Alocação estática ou dinâmica de recursos
- Aplicação a montante ou a jusante
- Introdução
- Passos envolvidos em modo cluster para um Spark Job
- Alocação estática
- Hardware do Caso 1 – 6 Nodos e cada nó tem 16 núcleos, 64 GB RAM
- Hardware do Caso 2 – 6 Núcleos e Cada nó tem 32 Núcleos, 64 GB
- Caso 3 – Quando mais memória não é necessária para os executores
- Tabela de Sumário
- Alocação Dinâmica
Introdução
Deixamos começar com algumas definições básicas dos termos usados no manuseio de aplicações Spark.
Partições : Uma partição é um pequeno pedaço de um grande conjunto de dados distribuídos. Spark gerencia dados usando partições que ajudam a paralelizar o processamento de dados com o mínimo de embaralhamento de dados através dos executores.
Task : Uma tarefa é uma unidade de trabalho que pode ser executada em uma partição de um conjunto de dados distribuído e é executada em um único executor. A unidade de execução paralela está no nível da tarefa. Todas as tarefas em um único estágio podem ser executadas em paralelo
Executor : Um executor é um único processo JVM que é lançado para uma aplicação em um nó de trabalho. O Executor executa tarefas e mantém os dados na memória ou armazenamento em disco através delas. Cada aplicação tem os seus próprios executores. Um único nó pode executar vários executores e os executores para uma aplicação podem abranger vários nós de trabalhadores. Um executor fica em cima para a duração da aplicação Spark e executa as tarefas em múltiplos threads. O número de executores para uma aplicação Spark pode ser especificado dentro da SparkConf ou através do flag -num-executors da linha de comando.
Cluster Manager : Um serviço externo para aquisição de recursos no cluster (por exemplo, gerenciador autônomo, Mesos, YARN). Spark é agnóstico para um gerenciador de cluster desde que ele possa adquirir processos executores e estes possam se comunicar uns com os outros. Um cluster de faísca pode rodar em modo cluster de fio ou modo fio-cliente:
modo fio-cliente – Um driver roda no processo cliente, Application Master só é usado para solicitar recursos do YARN.
modo cluster de fio – Um driver roda dentro do processo mestre da aplicação, cliente vai embora uma vez que a aplicação é inicializada
Cores : Um núcleo é uma unidade de computação básica da CPU e uma CPU pode ter um ou mais núcleos para executar tarefas em um determinado momento. Quanto mais núcleos tivermos, mais trabalho podemos fazer. Em spark, isto controla o número de tarefas paralelas que um executor pode executar.
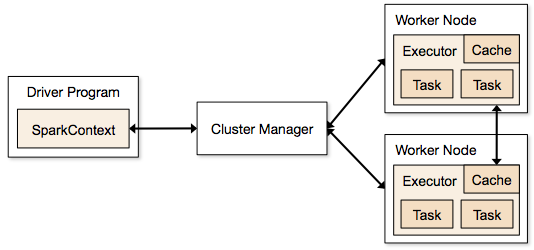
Passos envolvidos em modo cluster para um Spark Job
- Do código do driver, SparkContext se conecta ao gerenciador de cluster (standalone/Mesos/YARN).
- Cluster Manager aloca recursos entre as outras aplicações. Qualquer gerenciador de cluster pode ser usado desde que os processos do executor estejam em execução e eles se comuniquem entre si.
- Spark adquire executores em nós em cluster. Aqui cada aplicação irá obter seus próprios processos executores.
- Código da aplicação (jar/python files/python egg files) é enviado aos executores
- Tasks são enviadas pela SparkContext aos executores.
Dos passos acima, fica claro que o número de executores e sua configuração de memória desempenham um papel importante em um trabalho de spark. Executar executores com muita memória frequentemente resulta em atrasos excessivos na coleta de lixo
Agora tentamos entender, como configurar o melhor conjunto de valores para otimizar um spark job.
Existem duas formas de configurar o executor e os detalhes centrais para o spark job. Elas são:
- Alocação Estática – Os valores são dados como parte da spark-submit
- Alocação Dinâmica – Os valores são coletados com base no requerimento (tamanho dos dados, quantidade de cálculos necessários) e liberados após o uso. Isto ajuda os recursos a serem reutilizados para outras aplicações.
Alocação estática
Diferentes casos são discutidos variando diferentes parâmetros e chegando a diferentes combinações como por usuário/dados requeridos.
Hardware do Caso 1 – 6 Nodos e cada nó tem 16 núcleos, 64 GB RAM
Primeiro em cada nó, 1 núcleo e 1 GB é necessário para o Sistema Operacional e Daemons Hadoop, então temos 15 núcleos, 63 GB RAM para cada nó
Comecemos com como escolher o número de núcleos:
Número de núcleos = Tarefas simultâneas que um executor pode executar
Então podemos pensar, mais tarefas simultâneas para cada executor dará melhor desempenho. Mas pesquisas mostram que qualquer aplicação com mais de 5 tarefas simultâneas, levaria a um show ruim. Então o valor ótimo é 5.
Este número vem da habilidade de um executor de executar tarefas paralelas e não de quantos núcleos um sistema tem. Então o número 5 permanece o mesmo, mesmo que tenhamos núcleos duplos (32) na CPU
Número de executores:
Vindo para o próximo passo, com 5 como núcleos por executor, e 15 como total de núcleos disponíveis em um nó (CPU) – chegamos a 3 executores por nó que é 15/5. Precisamos calcular o número de executores em cada nó e então obter o número total para o trabalho.
Então com 6 nós, e 3 executores por nó – obtemos um total de 18 executores. De 18, precisamos de 1 executor (processo java) para o Application Master no YARN. Então o número final é 17 executores
Este 17 é o número que damos ao spark usando -num-executors enquanto rodando a partir do comando spark-submit shell
Memória para cada executor:
Do passo acima, temos 3 executores por nó. E a RAM disponível em cada nó é 63 GB
Então a memória para cada executor em cada nó é 63/3 = 21GB.
No entanto, também é necessária uma pequena sobrecarga de memória para determinar a requisição de memória completa ao YARN para cada executor.
A fórmula para essa sobrecarga é max(384, .07 * spark.executor.memory)
Calculando essa sobrecarga: .07 * 21 (Aqui 21 é calculado como acima de 63/3) = 1.47
Desde 1.47 GB > 384 MB, a sobrecarga é 1.47
Tirar o acima de cada 21 acima => 21 – 1.47 ~ 19 GB
Então memória do executor – 19 GB
Números finais – Executores – 17, Núcleos 5, Memória do Executor – 19 GB
Hardware do Caso 2 – 6 Núcleos e Cada nó tem 32 Núcleos, 64 GB
Número de núcleos de 5 é o mesmo para uma boa concorrência como explicado acima.
Número de executores para cada nó = 32/5 ~ 6
Então o total de executores = 6 * 6 Nodos = 36. Então o número final é 36 – 1(para AM) = 35
Memória do tutor:
6 executores para cada nó. 63/6 ~ 10. A sobretaxa é .07 * 10 = 700 MB. Então arredondando para 1GB como overhead, obtemos 10-1 = 9 GB
Números finais – Executors – 35, Cores 5, Memória do Executor – 9 GB
Caso 3 – Quando mais memória não é necessária para os executores
Os cenários acima começam com a aceitação do número de núcleos como fixos e passando para o número de executores e memória.
Agora para o primeiro caso, se acharmos que não precisamos de 19 GB, e apenas 10 GB é suficiente com base no tamanho dos dados e cálculos envolvidos, então seguem os números:
Cores: 5
Número de executores para cada nó = 3. Ainda 15/5 como calculado acima.
Nesta etapa, isto levaria a 21 GB, e depois 19, conforme nosso primeiro cálculo. Mas como pensamos que 10 é ok (suponha pouco overhead), então não podemos mudar o número de executores por nó para 6 (como 63/10). Porque com 6 executores por nó e 5 núcleos, ele se reduz a 30 núcleos por nó, quando temos apenas 16 núcleos. Então nós também precisamos mudar o número de núcleos para cada executor.
Então calculando novamente,
O número mágico 5 chega a 3 (qualquer número menor ou igual a 5). Então com 3 núcleos, e 15 núcleos disponíveis – obtemos 5 executores por nó, 29 executores ( que é (5*6 -1)) e a memória é 63/5 ~ 12.
Overhead é 12*.07=.84. Então a memória do executor é 12 – 1 GB = 11 GB
Números finais são 29 executores, 3 núcleos, a memória do executor é 11 GB
Tabela de Sumário
Alocação Dinâmica
Nota: Limite superior para o número de executores se a alocação dinâmica estiver habilitada é infinito. Então isto diz que a aplicação spark pode consumir todos os recursos, se necessário. Em um cluster onde temos outras aplicações rodando e elas também precisam de núcleos para executar as tarefas, precisamos ter certeza que atribuímos os núcleos em nível de cluster.
Isso significa que podemos alocar um número específico de núcleos para aplicações baseadas no YARN com base no acesso do usuário. Assim podemos criar um spark_user e depois dar núcleos (min/max) para esse utilizador. Estes limites são para compartilhamento entre spark e outras aplicações que rodam no YARN.
Para entender alocação dinâmica, precisamos ter conhecimento das seguintes propriedades:
spark.dynamicAllocation.enabled – quando isto é definido como verdadeiro não precisamos mencionar executores. A razão está abaixo:
Os números de parâmetros estáticos que damos no spark-submit é para toda a duração do trabalho. Entretanto se a alocação dinâmica entrar em cena, haverá diferentes estágios como os seguintes:
Qual é o número de executores para começar com:
Número inicial de executores (spark.dynamicAllocation.initialExecutors) para começar com
Controlar dinamicamente o número de executores:
Então baseado na carga (tarefas pendentes) quantos executores solicitar. Este seria eventualmente o número que nós damos no spark-submit de forma estática. Então uma vez que os números iniciais dos executores estão definidos, vamos para min (spark.dynamicAllocation.minExecutors) e max (spark.dynamicAllocation.maxExecutors) números.
Quando pedir novos executores ou dar executores atuais:
Quando pedir novos executores (spark.dynamicAllocation.schedulerBacklogTimeout) – Isto significa que tem havido tarefas pendentes por esta quantidade de tempo. Assim, a solicitação para o número de executores solicitados em cada rodada aumenta exponencialmente em relação à rodada anterior. Por exemplo, uma solicitação irá adicionar 1 executor na primeira rodada, e depois 2, 4, 8 e assim por diante, executores nas rodadas seguintes. Em um ponto específico, a propriedade max acima vem na figura.
Quando damos um executor é definido usando spark.dynamicAllocation.executorIdleTimeout.
Para concluir, se precisarmos de mais controle sobre o tempo de execução do trabalho, monitore o trabalho para um volume de dados inesperado, os números estáticos ajudariam. Ao passar para dinâmico, os recursos seriam usados em segundo plano e os trabalhos envolvendo volumes inesperados poderiam afetar outras aplicações.