
A primeira coisa que precisamos entender é a natureza das variáveis e como as variáveis são utilizadas no desenho de um estudo para responder às perguntas do estudo. Neste capítulo você aprenderá:
- diferentes tipos de variáveis em estudos quantitativos,
- questões envolvendo a unidade de questão de análise.
Entendendo Variáveis Quantitativas
A raiz da palavra variável está relacionada com a palavra “vary”, o que deve nos ajudar a entender quais variáveis podem ser. Variáveis são elementos, entidades ou fatores que podem mudar (variar); por exemplo, a temperatura exterior, o custo da gasolina por galão, o peso de uma pessoa e o humor das pessoas na sua família estendida são todas variáveis. Em outras palavras, elas podem ter valores diferentes sob condições diferentes ou para pessoas diferentes.
Utilizamos variáveis para descrever características ou fatores de interesse. Exemplos podem incluir o número de membros em diferentes famílias, a distância a fontes de alimentação saudável em diferentes bairros, a proporção de professores de trabalhos sociais em relação aos estudantes em um programa de BSW ou MSW, a proporção de pessoas de diferentes grupos raciais/étnicos encarcerados, o custo do transporte para receber serviços de um programa de trabalhos sociais, ou a taxa de mortalidade infantil em diferentes condados. Na pesquisa de intervenção de trabalho social, as variáveis podem incluir características da intervenção (intensidade, freqüência, duração) e resultados associados à intervenção.
Variáveis Demográficas. Os assistentes sociais estão muitas vezes interessados no que chamamos de variáveis demográficas. Variáveis demográficas são usadas para descrever características de uma população, grupo ou amostra da população. Exemplos de variáveis demográficas frequentemente aplicadas são
- idade,
- etnicidade,
- origem nacional,
- afiliação religiosa,
- gênero,
- orientação sexual,
- estado civil/de relacionamento,
- estado de emprego,
- afiliação política,
- localização geográfica,
- nível de educação,e
- rendimento.
Num nível mais macro, a demografia de uma comunidade ou organização frequentemente inclui o seu tamanho; as organizações são frequentemente medidas em termos do seu orçamento global.
Variáveis Independentes e Dependentes. Uma forma de os investigadores pensarem sobre as variáveis de estudo tem implicações importantes para o desenho de um estudo. Os investigadores tomam decisões sobre tê-las como variáveis independentes ou como variáveis dependentes. Esta distinção não é algo inerente a uma variável, ela é baseada em como o investigador escolhe definir cada variável. Variáveis independentes são aquelas que você pode pensar como as variáveis “input” manipuladas, enquanto as variáveis dependentes são aquelas onde o impacto ou “output” dessa variação de input seria observado.
A manipulação intencional da variável “input” (independente) nem sempre está envolvida. Considere o exemplo de um estudo realizado na Suécia examinando a relação entre ter sido vítima de maus-tratos infantis e o absenteísmo posterior na escola secundária: ninguém manipulou intencionalmente se as crianças seriam vítimas de maus-tratos infantis (Hagborg, Berglund, & Fahlke, 2017). Os investigadores supõem que as diferenças que ocorrem naturalmente na variável de entrada (histórico de maus-tratos infantis) estariam associadas à variação sistemática em uma variável de resultado específica (absenteísmo escolar). Neste caso, a variável independente era um histórico de ser vítima de maus-tratos à criança, e a variável dependente era o resultado do absenteísmo escolar. Em outras palavras, a variável independente é uma hipótese do investigador de causar variação ou mudança na variável dependente. Isto é o que poderia parecer em um diagrama onde “x” é a variável independente e “y” é a variável dependente (nota: você viu esta designação antes, no Capítulo 3, quando discutimos a lógica de causa e efeito):

Para outro exemplo, considere a pesquisa indicando que ser vítima de maus-tratos infantis está associado a um maior risco de uso de substâncias durante a adolescência (Yoon, Kobulsky, Yoon, & Kim, 2017). A variável independente neste modelo seria ter um histórico de maus-tratos infantis. A variável dependente seria o risco de uso de substâncias durante a adolescência. Este exemplo é ainda mais elaborado porque especifica o caminho pelo qual a variável independente (maus-tratos à criança) poderia impor seus efeitos sobre a variável dependente (uso de substância na adolescência). Os autores do estudo demonstraram que o estresse pós-traumático (STP) foi uma ligação entre o abuso infantil (físico e sexual) e o uso de substâncias durante a adolescência.

Tirar um momento para completar a seguinte atividade.
Tipos de Variáveis Quantitativas
Existem outras formas significativas de pensar sobre variáveis de interesse, também. Vamos considerar diferentes características de variáveis utilizadas em estudos de pesquisa quantitativa. Aqui exploramos as variáveis quantitativas como sendo categóricas, ordinais, ou de natureza intervalada. Estas características têm implicações tanto para medição quanto para análise de dados.
Variáveis categóricas. Algumas variáveis podem assumir valores que variam, mas não de uma forma numérica significativa. Em vez disso, elas podem ser definidas em termos das categorias que são possíveis. Logicamente, estas são chamadas variáveis categóricas. Software estatístico e livros de texto às vezes se referem a variáveis com categorias como variáveis nominais. Nominal pode ser pensado em termos da raiz latina “nom”, que significa “nome”, e não deve ser confundido com número. Nominal significa a mesma coisa que categórico na descrição de variáveis. Em outras palavras, as variáveis categóricas ou nominais são identificadas pelos nomes ou rótulos das categorias representadas. Por exemplo, a cor do último carro em que você montou seria uma variável categórica: azul, preto, prata, branco, vermelho, verde, amarelo ou outras são categorias da variável que poderíamos chamar de cor do carro.
O que é importante com as variáveis categóricas é que essas categorias não têm seqüência numérica ou ordem relevante. Não há diferença numérica entre as diferentes cores do carro, ou diferença entre “sim” ou “não” como as categorias na resposta, se você andou em um carro azul. Não há ordem ou hierarquia implícita para as categorias “Hispânico ou latino” e “Não hispânico ou latino” em uma variável de etnia; nem há qualquer ordem relevante para categorias de variáveis como sexo, estado ou região geográfica onde uma pessoa reside, ou se a residência de uma pessoa é própria ou alugada.
Se um pesquisador decidiu usar números como símbolos relacionados a categorias em tal variável, os números são arbitrários – cada número é essencialmente apenas um nome diferente e mais curto para cada categoria. Por exemplo, o gênero da variável poderia ser codificado das seguintes maneiras, e não faria diferença, desde que o código fosse aplicado de forma consistente.
| Opção de codificação A | Categorias Variáveis | Opção de codificação B |
|---|---|---|
| 1 | male | 2 |
| 2 | fêmea | 1 |
| 3 | outra que só homem ou mulher | 4 |
| 4 | prefere não responder | 3 |
Raça e etnia.Uma das variáveis categóricas mais comumente exploradas na pesquisa em trabalho social e ciências sociais é a demografia referente à origem racial e/ou étnica de uma pessoa. Muitos estudos utilizam as categorias especificadas em relatórios anteriores do U.S. Census Bureau. Aqui está o que o U.S. Census Bureau tem a dizer sobre as duas variáveis demográficas distintas, raça e etnia (https://www.census.gov/mso/www/training/pdf/race-ethnicity-onepager.pdf):
O que é raça? O Departamento do Censo define raça como a auto-identificação de uma pessoa com um ou mais grupos sociais. Um indivíduo pode relatar como branco, negro ou afro-americano, asiático, índio americano e nativo do Alasca, havaiano nativo e outras ilhas do Pacífico, ou alguma outra raça. Os entrevistados da pesquisa podem relatar múltiplas raças.
O que é etnia? A etnicidade determina se uma pessoa é de origem hispânica ou não. Por este motivo, a etnicidade é dividida em duas categorias, hispânica ou latina e não hispânica ou latina. Os hispânicos podem se apresentar como qualquer raça.
Em outras palavras, o Departamento do Censo define duas categorias para a variável chamada etnia (hispânica ou latina e não hispânica ou latina), e sete categorias para a variável chamada raça. Embora essas variáveis e categorias sejam frequentemente aplicadas em ciências sociais e pesquisa de trabalho social, elas não estão sem crítica.
Baseadas nessas categorias, aqui está o que se estima ser verdade para a população dos EUA em 2016:
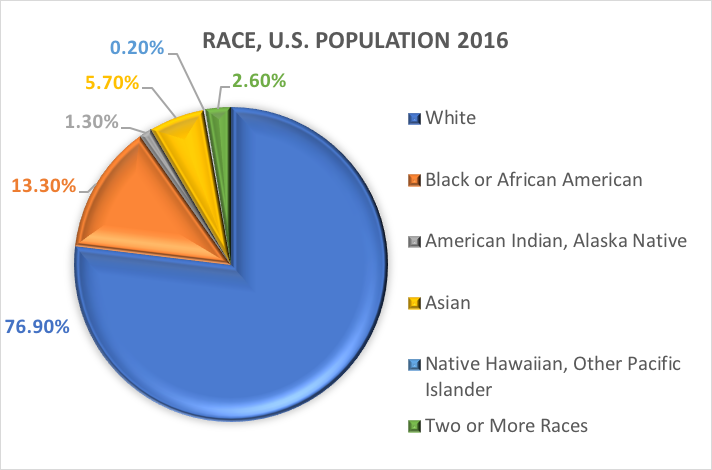
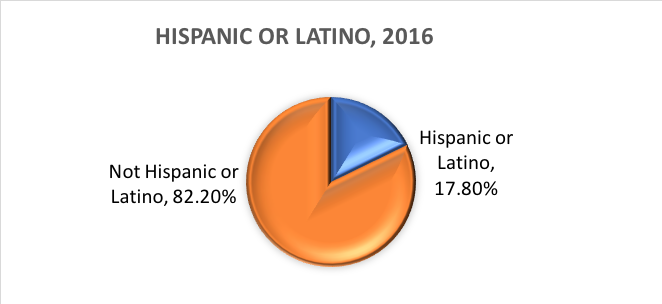
Variáveis dicotômicas.Existe uma categoria especial de variável categórica com implicações para certas análises estatísticas. As variáveis categóricas compostas de exatamente duas opções, nem mais nem menos são chamadas variáveis dicotômicas. Um exemplo foi a dicotomia do U.S. Census Bureau entre hispânicos/latinos e não hispânicos/não-latinos. Por outro exemplo, os investigadores podem querer comparar pessoas que completam o tratamento com aquelas que desistem antes de completar o tratamento. Com as duas categorias, completadas ou não, esta variável de conclusão do tratamento não é apenas categórica, é dicotómica. As variáveis onde os indivíduos respondem “sim” ou “não” também são dicotômicas por natureza.
A tradição passada de tratar o gênero como masculino ou feminino é outro exemplo de variável dicotômica. No entanto, existem argumentos muito fortes para não tratar mais o gênero desta forma dicotômica: uma maior variedade de identidades de gênero são comprovadamente relevantes no trabalho social para pessoas cuja identidade não se alinha com as categorias dicotômicas (também chamadas binárias) de homem/mulher ou masculino/feminino. Estas incluem categorias como agender, andrógino, bigender, cisgênero, expansivo de gênero, fluido de gênero, questionamento de gênero, queer, transgênero e outras.
Variáveis Ordinais. Ao contrário destas variáveis categóricas, às vezes as categorias de uma variável têm uma sequência ou ordem numérica lógica. Ordinal, por definição, refere-se a uma posição em uma série. Variáveis com categorias numericamente relevantes são chamadas variáveis ordinais. Por exemplo, há uma ordem implícita de categorias da menor para a maior parte com a variável chamada de nível de escolaridade. Os E.U.A. categorias de dados censitários para esta variável ordinal são:
- nenhuma
- 1º-4º grau
- 5º-6º grau
- 7º-8º grau
- 9º grau
- 10º grau
- 11º grau
- graduação do ensino superior
- algum ensino superior, no degree
- associate’s degree, profissional
- grau académico de associado
- grau de bacharelato
- grau de mestre
- grau profissional
- grau de doutoramento
>
>
No estudo do Gabinete do Censo de 2016, podemos ver que as fêmeas superaram os machos na categoria de ter atingido o grau de bacharel: das 47.718.000 pessoas nesta categoria, 22.485.000 eram homens e 25.234.000 eram mulheres. Embora este padrão de gênero tenha sido mantido para aqueles que receberam o mestrado, o padrão foi invertido para receber o doutorado: mais homens do que mulheres obtiveram este nível mais alto de educação. Também é interessante notar que as mulheres superaram em número os homens na parte baixa do espectro: 441.000 mulheres não relataram nenhuma educação em comparação com 374.000 homens.
Aqui está outro exemplo de uso de variáveis ordinais em pesquisa de trabalho social: quando os indivíduos buscam tratamento para um problema com o uso indevido de álcool, os assistentes sociais podem querer saber se esta é a sua primeira, segunda, terceira ou qualquer tentativa séria numerada de mudar seu comportamento de beber. Os participantes matriculados em um estudo comparando abordagens de tratamento para transtornos relacionados ao uso de álcool relataram que o estudo de intervenção foi em qualquer lugar da primeira à décima primeira tentativa de mudança significativa (Begun, Berger, Salm-Ward, 2011). Essa variável de tentativa de mudança tem implicações em como os assistentes sociais podem interpretar dados que avaliam uma intervenção que não foi a primeira tentativa para todos os envolvidos.
Escalas de avaliação. Considere um tipo diferente mas comumente usado de variável ordinal: escalas de classificação. Os investigadores de trabalhos sociais, comportamentais e de trabalho social frequentemente pedem aos participantes do estudo que apliquem uma escala de classificação para descrever seus conhecimentos, atitudes, crenças, opiniões, habilidades ou comportamento. Como as categorias em tal escala são sequenciadas (da maioria para a menor ou da menor para a maior parte), chamamos a estas variáveis ordinais.

Exemplos incluem ter os participantes avaliados:
- como eles concordam ou discordam de certas afirmações (não muito a muito);
- como eles frequentemente se envolvem em certos comportamentos (nunca a sempre);
- como eles frequentemente se envolvem em certos comportamentos (horários, diários, semanais, mensais, anuais, ou menos frequentemente);
- a qualidade do desempenho de alguém (pobre a excelente);
- como estavam satisfeitos com o seu tratamento (muito insatisfeitos a muito satisfeitos)
- o seu nível de confiança (muito baixo a muito alto).
Variáveis de Intervalo. Ainda outras variáveis assumem valores que variam de uma forma numérica significativa. Da nossa lista de variáveis demográficas, a idade é um exemplo comum. O valor numérico atribuído a uma pessoa individual indica o número de anos desde que a pessoa nasceu (no caso de bebês, o valor numérico pode indicar dias, semanas ou meses desde o nascimento). Aqui os valores possíveis para a variável são ordenados, como as variáveis ordinais, mas é introduzida uma grande diferença: a natureza dos intervalos entre os valores possíveis. Com as variáveis de intervalo, a “distância” entre os valores possíveis adjacentes é igual. Alguns pacotes de software estatísticos e livros de texto usam o termo variável de escala: isto é exatamente a mesma coisa que chamamos de variável de intervalo.
Por exemplo, no gráfico abaixo, a diferença de 1 onça entre esta pessoa consumindo 1 onça ou 2 onças de álcool (segunda, terça) é exatamente a mesma coisa que a diferença de 1 onça entre consumir 4 onças ou 5 onças (sexta, sábado). Se fossemos diagramar os pontos possíveis na escala, todos eles seriam equidistantes; o intervalo entre quaisquer dois pontos é medido em unidades padrão (onças, neste exemplo).
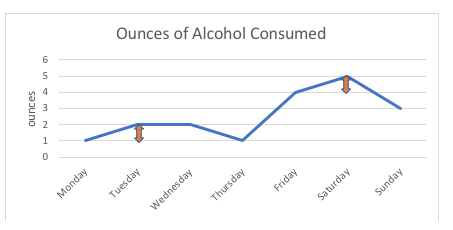
Com variáveis ordinais, tais como uma escala de classificação, ninguém pode dizer com certeza que a “distância” entre as opções de resposta de “nunca” e “às vezes” é a mesma que a “distância” entre “às vezes” e “frequentemente”, mesmo que utilizássemos números para sequenciar essas opções de resposta. Assim, a escala de classificação permanece ordinal, não intervalo.
O que pode se tornar um pouco confuso é que certos programas de software estatístico, como o SPSS, referem-se a uma variável de intervalo como uma variável de “escala”. Muitas variáveis usadas na pesquisa do trabalho social são ordenadas e têm distâncias iguais entre pontos. Considere, por exemplo, a variável de ordem de nascimento. Esta variável é intervalo porque:
- os valores possíveis são ordenados (por exemplo, o terceiro filho veio depois do primeiro e segundo nascimentos e antes do quarto nascimento), e
- as “distâncias” ou intervalos são medidos em unidades equivalentes de uma pessoa.
Variáveis contínuas. Existe um tipo especial de variável de intervalo numérico que chamamos variáveis contínuas. Uma variável como a idade pode ser tratada como uma variável contínua. A idade é ordinal por natureza, já que números mais altos significam algo em relação a números menores. A idade também atende ao nosso critério de ser uma variável de intervalo se a medirmos em anos (ou meses ou semanas ou dias) porque é ordinal e há a mesma “distância” entre os 15 e 30 anos que há entre os 40 e 55 anos (15 anos de calendário). O que torna isto uma variável contínua é que há também pontos de “fração” significativos entre quaisquer dois intervalos. Por exemplo, uma pessoa pode ser 20½ (20,5) ou 20¼ (20,25) ou 20¾ (20,75) anos de idade; não estamos limitados apenas aos números inteiros para a idade. Em contraste, quando olhamos para a ordem de nascimento, não podemos ter uma fração significativa de uma pessoa entre duas posições na escala.
O Caso Especial de Renda. Uma das variáveis mais abusadas na pesquisa em ciências sociais e trabalho social é a variável relacionada à renda. Considere um exemplo sobre o rendimento do agregado familiar (independentemente do número de pessoas no agregado familiar). Esta variável pode ser categórica (nominal), ordinal ou de intervalo (escala), dependendo de como é tratada.
Categorical Example: Dependendo da natureza das perguntas da pesquisa, um investigador pode simplesmente escolher usar as categorias dicotômicas de “recursos suficientes” e “recursos insuficientes” para classificar as famílias, com base em algum método de cálculo padrão. Estes podem ser chamados de “pobres” e “não pobres” se for usado um limiar de linha de pobreza para classificar as famílias. Estas categorias distintas de variáveis de rendimento não são sequenciadas de forma numérica, por isso é uma variável categórica.
Ordinal Example: As categorias para classificar os agregados familiares podem ser ordenadas de baixo para alto. Por exemplo, estas categorias para renda anual são comuns em pesquisa de mercado:
- Menos de $25.000,
- $25.000 a $34.999,
- $35.000 a $49.999,
- $50.000 a $74.999,
- $75.000 a $99.999.
- $100.000 a $149.999,999,
- $150.000 a $199.999,
- $200.000 ou mais.
Notem que as categorias não têm o mesmo tamanho – a “distância” entre pares de categorias nem sempre é a mesma. Elas começam em incrementos de cerca de $10.000, passam para incrementos de $25.000 e terminam em incrementos de cerca de $50.000.
Exemplo de Intervalo. Se um investigador pedisse aos participantes do estudo para relatar um valor real em dólares para a renda familiar, veríamos uma variável de intervalo. Os valores possíveis são ordenados e o intervalo entre quaisquer possíveis unidades adjacentes é de $1 (desde que não sejam usadas frações ou centavos de dólar). Assim, uma renda de $10.452 é a mesma distância em um contínuo de $9.452 e $11.452-$1.000 de qualquer forma.

O Caso Especial de Idade. Como a renda, “idade” pode significar coisas diferentes em diferentes estudos. A idade é normalmente um indicador de “tempo desde o nascimento”. Podemos calcular a idade de uma pessoa subtraindo uma variável de data de nascimento da data de medição (a data de hoje menos a data de nascimento). Para adultos, as idades são tipicamente medidas em anos em que valores adjacentes possíveis são distanciados em unidades de 1 ano: 18, 19, 20, 21, 22, e assim por diante. Assim, a variável idade pode ser um tipo contínuo de variável de intervalo.
No entanto, um investigador pode desejar colapsar dados de idade em categorias ou grupos de idade ordenados. Estas ainda seriam ordinais, mas poderiam não ser mais de intervalo se os incrementos entre os valores possíveis não fossem unidades equivalentes. Por exemplo, se estivermos mais interessados em que a idade represente períodos específicos do desenvolvimento humano, os intervalos de idade podem não ser iguais no intervalo entre os critérios de idade. Possivelmente, eles podem ser:
- Infância (nascimento aos 18 meses)
- Toddlerhood (18 meses a 2 ½ anos)
- Prescola (2 ½ a 5 anos)
- Idade escolar (6 a 11 anos)
- Adolescência (12 a 17 anos)
- Alternidade emergente (18 a 25 anos)
- Adulteria (26 a 45 anos)
- Adulteria média (46 a 60 anos)
- Young-Idade adulta (60 a 74 anos)
- Idade média (75 a 84 anos)
- Idade adulta (85 ou mais anos)
A idade pode até ser tratada como uma variável estritamente categórica (não ordinal). Por exemplo, se a variável de interesse é se alguém tem idade legal para beber (21 anos ou mais), ou não. Nós temos duas categorias – ou seja, se a idade legal de consumo de álcool nos Estados Unidos – e uma pode ser codificada com um “1” e a outra como um “0” ou “2” sem diferença no significado.
Qual é a resposta “certa” sobre como medir a idade (ou renda)? A resposta é “depende”. Do que depende é da natureza da questão da pesquisa: qual conceptualização de idade (ou renda) é mais relevante para o estudo que está sendo desenhado.
Variáveis alfanuméricas. Finalmente, existem dados que não se encaixam em nenhuma destas classificações. Às vezes a informação que conhecemos está na forma de um endereço ou número de telefone, um nome ou sobrenome, código postal ou outras frases. Este tipo de informação é às vezes chamado de variáveis alfanuméricas. Considere a variável “endereço”, por exemplo: o endereço de uma pessoa pode ser composto por caracteres numéricos (o número da casa) e letras (soletrando a rua, cidade e nomes de estado), como 1600 Pennsylvania Ave. NW, Washington, DC, 20500.

Atualmente, temos várias variáveis presentes neste exemplo de endereço:
- o endereço da rua: 1600 Pennsylvania Ave.
- a cidade (e “estado”): Washington, DC
- o código postal: 20500.
>
Este tipo de informação não representa categorias quantitativas específicas ou valores com significado sistemático nos dados. Estas também são por vezes chamadas variáveis “string” em certos pacotes de software porque são constituídas por uma string de símbolos. Para ser útil para um investigador, tal variável teria que ser convertida ou recodificada em valores significativos.
A Note about Unit of Analysis
Uma coisa importante a ter em mente ao pensar em variáveis é que os dados podem ser coletados em muitos níveis diferentes de observação. Os elementos estudados podem ser células individuais, sistemas de órgãos, ou pessoas. Ou, o nível de observação pode ser pares de indivíduos, tais como casais, irmãos e irmãs, ou díades pai-filho. Neste caso, o investigador pode coletar informações sobre o par de cada indivíduo, mas está olhando para os dados de cada par. Assim, diríamos que a unidade de análise é o par ou díada, não cada pessoa individualmente. A unidade de análise poderia ser um grupo maior, também: por exemplo, os dados poderiam ser coletados de cada um dos alunos em salas de aula inteiras onde a unidade de análise é a sala de aula de uma escola ou sistema escolar. Ou, a unidade de análise pode ser a nível de bairros, programas, organizações, condados, estados, ou mesmo nações. Por exemplo, muitas das variáveis usadas como indicadores de segurança alimentar ao nível das comunidades, tais como acessibilidade e acessibilidade, baseiam-se em dados recolhidos de famílias individuais (Kaiser, 2017). A unidade de análise nos estudos que usam estes indicadores seriam as comunidades a serem comparadas. Esta distinção tem implicações importantes na medição e análise de dados.
Um Lembrete sobre Variáveis versus Níveis Variáveis
Um estudo pode ser descrito em termos do número de categorias de variáveis, ou níveis, que estão a ser comparados. Por exemplo, você pode ver um estudo descrito como um desenho 2 X 2-pronunciado como um desenho dois a dois. Isto significa que existem 2 categorias possíveis para a primeira variável e 2 categorias possíveis para a outra variável – ambas são variáveis dicotômicas. Um estudo comparando 2 categorias da variável “transtorno do uso de álcool” (categorias para atender a critérios, sim ou não) com 2 categorias da variável “transtorno do uso de substâncias ilícitas” (categorias para atender a critérios, sim ou não) teria 4 resultados possíveis (matematicamente, 2 x 2=4) e poderia ser diagramado desta forma (dados baseados em proporções da pesquisa NSDUH 2016, apresentada em SAMHSA, 2017):
| Desordem do Uso de Substâncias Ilícitas (SUD) | ||||
|---|---|---|---|---|
|
Desordem do Uso de Álcool (AUD) |
> | > | Sim | |
| Não | 500 | 10 | ||
| Sim | 26 | 4 | ||
Lendo as 4 células desta tabela de 2 X 2, podemos ver que nesta pesquisa (hipotética) de 540 indivíduos, 500 não preenchiam os critérios para um transtorno de uso de álcool ou substâncias ilícitas (Não, Não); 26 preenchiam critérios para um transtorno relacionado ao uso de álcool apenas (Sim, Não); 10 preenchiam critérios para um transtorno relacionado ao uso de substâncias ilícitas apenas (Não, Sim), e 4 preenchiam critérios para um transtorno relacionado ao uso de álcool e de substâncias ilícitas (Sim, Sim). Além disso, com um pouco de matemática aplicada, podemos ver que um total de 30 tinham um transtorno do uso de álcool (26 + 4) e 14 tinham um transtorno do uso de substâncias ilícitas (10 + 4). E, podemos ver que 40 tinham algum tipo de transtorno de uso de substâncias (26 + 10 + 4).
 Para fazer essa distinção entre variáveis e níveis de variáveis ou categorias de forma cristalina, vamos considerar mais um exemplo: um desenho de estudo 2 X 3. Primeiro, fazendo as contas, devemos ver 6 resultados possíveis (células). Segundo, sabemos que a primeira variável (faixa etária) tem 2 categorias (menores de 30 anos, 30 ou mais) e a outra variável (status de emprego) tem 3 categorias (totalmente empregado, parcialmente empregado, desempregado). Desta vez, as 6 células do nosso desenho estão vazias porque estamos à espera dos dados.
Para fazer essa distinção entre variáveis e níveis de variáveis ou categorias de forma cristalina, vamos considerar mais um exemplo: um desenho de estudo 2 X 3. Primeiro, fazendo as contas, devemos ver 6 resultados possíveis (células). Segundo, sabemos que a primeira variável (faixa etária) tem 2 categorias (menores de 30 anos, 30 ou mais) e a outra variável (status de emprego) tem 3 categorias (totalmente empregado, parcialmente empregado, desempregado). Desta vez, as 6 células do nosso desenho estão vazias porque estamos à espera dos dados.
| Estado empregado | ||||
|---|---|---|---|---|
|
Grupo de idade |
Parcialmente empregado | Parcialmente empregado Empregado | Desempregado | |
| <30 | ||||
| ≥30 | ||||
Assim, quando você vê uma descrição de desenho de estudo que parece dois números sendo multiplicados, isso é essencialmente dizer-lhe quantas categorias ou níveis de cada variável existem e leva-o a compreender quantas células ou possíveis resultados existem. Um desenho de 3 X 3 tem 9 células, um desenho de 3 X 4 tem 12 células, e assim por diante. Esta questão torna-se importante mais uma vez quando discutimos o tamanho da amostra no Capítulo 6.
Completar a seguinte Actividade da Pasta de Trabalho:
- SWK 3401.3-4.1 Início da Entrada de Dados
Síntese do Capítulo
Em resumo, os investigadores desenham muitos dos seus estudos quantitativos para testar hipóteses sobre as relações entre as variáveis. A compreensão da natureza das variáveis envolvidas ajuda na compreensão e avaliação da pesquisa realizada. Entender as distinções entre diferentes tipos de variáveis, bem como entre variáveis e categorias, tem implicações importantes para o desenho do estudo, medição e amostras. Entre outros tópicos, o próximo capítulo explora a interseção entre a natureza das variáveis estudadas na pesquisa quantitativa e como os investigadores se estabelecem para medir essas variáveis.
Tirar um momento para completar a seguinte atividade.